我的AI之路 —— OCR文字识别快速体验版
OCR的全称是Optical Character Recoginition,光学字符识别技术。目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别、交通路牌的识别、车牌的自动识别等等。本篇就先讲一下基于开源软件和大厂服务的文字识别效果,后续会陆续讲解一下机器学习和深度学习实现的方案和原理,敬请期待吧。
还记得前一阵某小盆友拿过来一个全是图片的ppt,让我把里面的文字给抠出来(我当时很震惊!!!),随后在网上随便找了个OCR的在线文档转换软件,就给转过来了——这里面用到的技术就是OCR文字识别,所以本篇就带大家宏观上了解一下文字识别的技术方案与实现过程。
更多内容参考——我的AI之路
实现方案 1 大厂调包
有需求的地方就有市场,文字识别也不例外,很多大厂都提供了对应的服务,按照调用次数进行收费。比如网上找了一个产品服务的定价

可以看到,倘若你的服务只是偶尔用一次,完全可以使用这种体验型的免费服务。如果一天需要调用一万次,那么一个月基本的花费在5w左右——成本还是很高的,所以很多商用的场景大多都采用自主研发的方式来做。
如果使用这种大厂(我这里使用的讯飞),流程基本如下:

#!/usr/bin/python
# -*- coding: UTF-8 -*-
import time
from urllib import request,parse
import json
import hashlib
import base64
import cv2
url = 'http://webapi.xfyun.cn/v1/service/v1/ocr/general'
x_appid = '5b4d9bbf'
api_key = 'a08332353b4df650842359129ffadb88'
param = {"language": "cn|en", "location": "true"}
x_param = str(base64.b64encode(bytes(json.dumps(param).replace(' ', ''),encoding='utf-8')),encoding = "utf8")
dict = {}
def main():
# 图片加载
f = open("名片.jpg", 'rb')
file_content = f.read()
body = parse.urlencode({'image': base64.b64encode(file_content)})
x_time = int(int(round(time.time() * 1000)) / 1000)
x_checksum = hashlib.md5((api_key + str(x_time) + x_param).encode("utf8")).hexdigest()
x_header = {
'X-Appid': x_appid,
'X-CurTime': x_time,
'X-Param': x_param,
'X-CheckSum': x_checksum
}
req = request.Request(url, data=body.encode("utf-8"), headers=x_header)
result = request.urlopen(req).read()
body = json.loads(result, encoding='utf-8')
img = cv2.imread('名片.jpg')
for text_line in body['data']['block'][0]['line']:
word = text_line['word'][0]
x1 = word['location']['top_left']['x']
y1 = word['location']['top_left']['y']
x2 = word['location']['right_bottom']['x']
y2 = word['location']['right_bottom']['y']
# 绘制文本框
cv2.line(img, (x1, y1), (x2, y1), (255, 0, 0), 2)
cv2.line(img, (x1, y1), (x1, y2), (255, 0, 0), 2)
cv2.line(img, (x1, y2), (x2, y2), (255, 0, 0), 2)
cv2.line(img, (x2, y1), (x2, y2), (255, 0, 0), 2)
# 输出对应文本
text = word['content']
print(text)
cv2.imshow('result', img)
cv2.waitKey(0)
if __name__ == '__main__':
main()
实现方案 2 基于开源软件tesseract实现
有的时候我们在写爬虫会遇到验证码校验的问题,这个时候使用大厂的接口就不现实了。验证码一般是数字+字母,因此识别起来复杂度不高,采用一些开源软件就能应付。说到开源软件,最有名的就是tesseract了,它目前由Google在进行维护,官方提供了3.05版本,貌似使用的还是传统机器学习的方式。
安装
安装的过程很简单,以我的mac为例,如果你只是想体验一下,那么可以使用下面的命令安装:
brew install tesseract
如果还想未来针对自己的使用数据重新训练,可以使用下面的命令安装(强烈推荐):
brew install --with-training-tools tesseract
如果不介意时间长一点,可以直接安装的时候下载所有的语言版本(不建议,因为语言包真的很大):
brew install --all-languages --with-training-tools tesseract
然后配置环境变量,比如vi ~/.bash_profile 增加下面的内容:
# 增加tesseract环境变量
export TESSERACT=/usr/local/Cellar/tesseract/3.05.02
export TESSDATA_PREFIX=/usr/local/Cellar/tesseract/3.05.02/share/
export PATH=$PATH:$TESSERACT/bin
然后执行source ~/.bash_profile
在命令行就可以使用tesseract了:

支持中文版本
如果想要支持中文,官方提供了语言包,可以去直接下载:
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-304305
这里3.04和3.05是通用的,下载后使用-l命令切换语言版本即可。
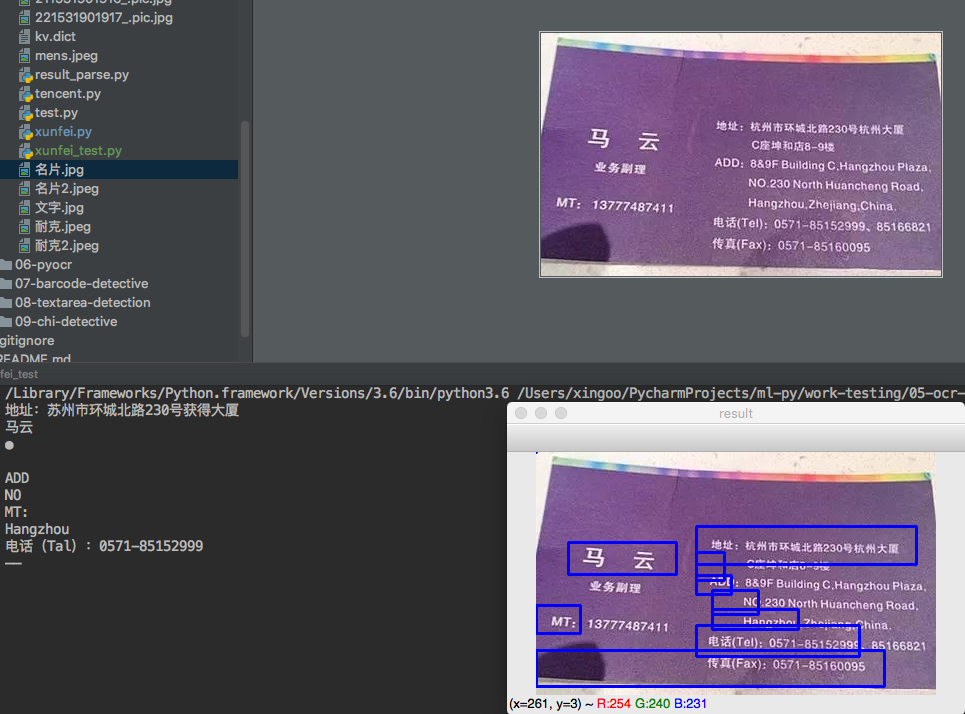
下面体验一下tesseract的效果,原图为

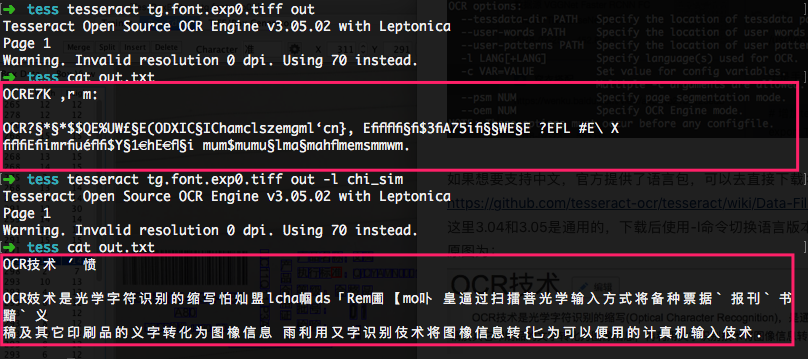
正常在使用tesseract的时候都会基于第三方的易用的接口来用
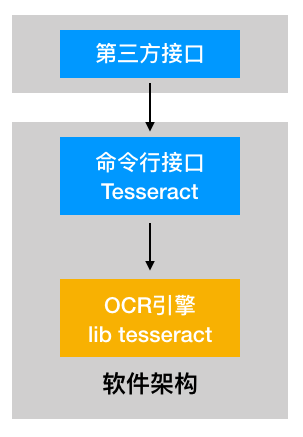
tesseract的自定义语言训练
另外tesseract对中文的支持还不是很好,如果想要优化可以使用jTessBoxEditor。
http://www.softpedia.com/get/Multimedia/Graphic/Graphic-Others/jTessBoxEditor.shtml
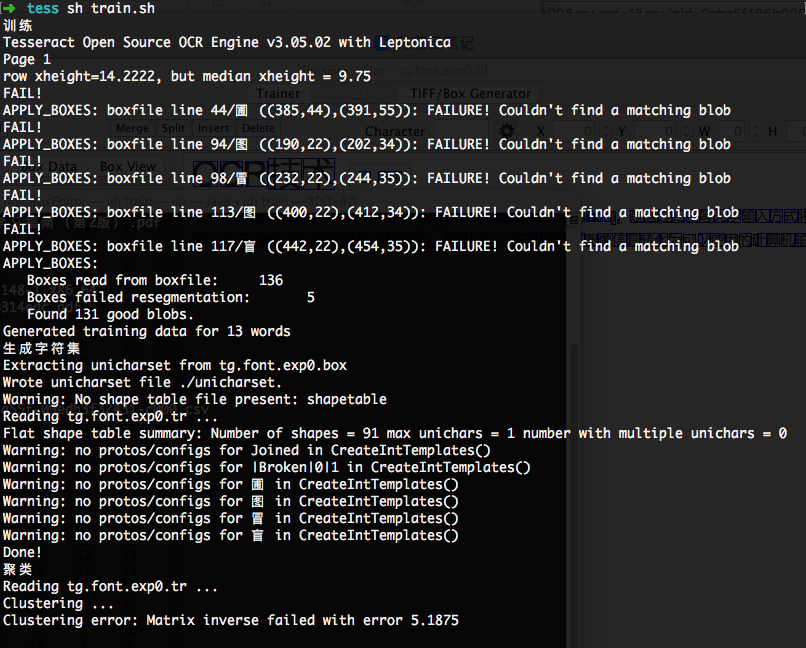
重新训练的流程为:
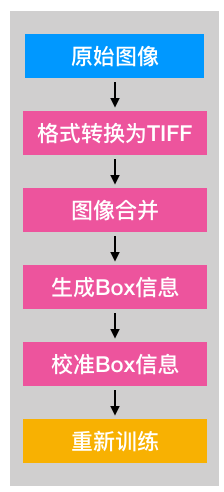
首先需要把图片转成tiff格式,这样它才能记录一些box的信息。

然后打开JTessBoxEditor对图片进行合并:

合并后得到一个新的tif图片

然后基于tesseract打上box信息
tesseract tg.font.exp0.tif tg.font.exp0 -l chi_sim batch.nochop makebox
随后再打开jTessBoxEditor,点击Box Editor,加载tif文件
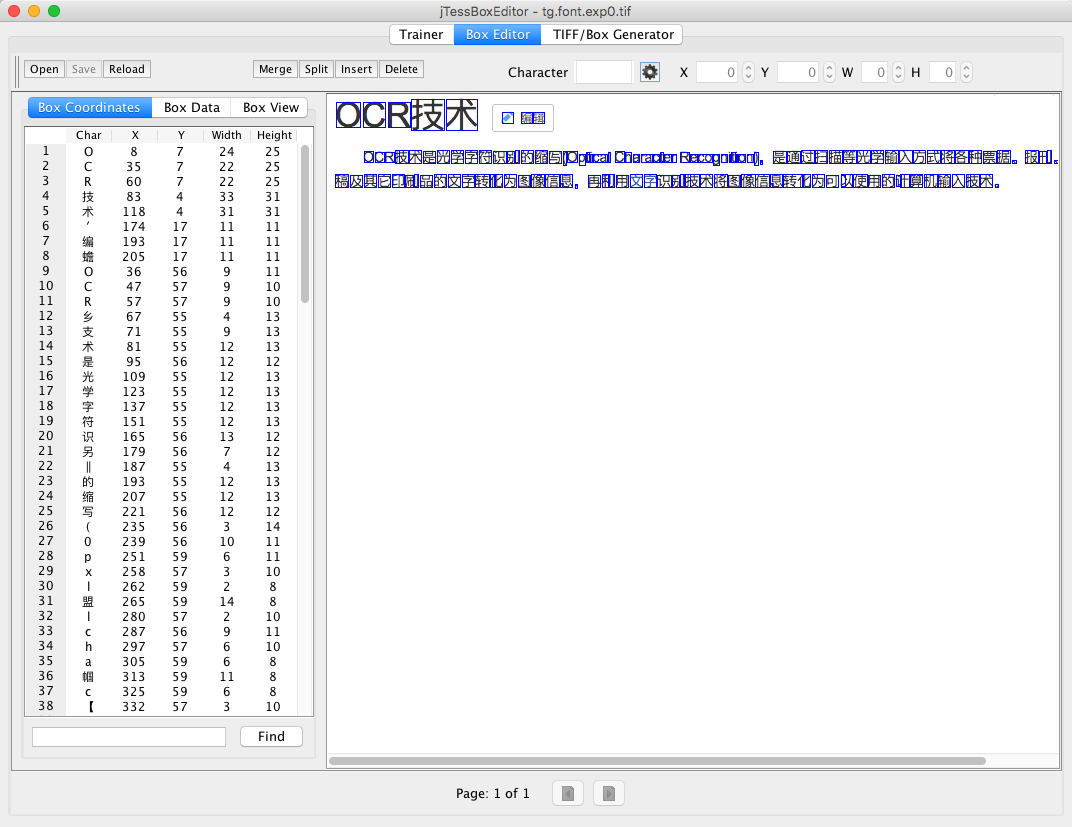
针对生成的结果进行文字的重新编辑和调整。然后在图片目录下创建一个font_properties的字体文件,里面的内容为:
>cat font_properties
font 0 0 0 0 0
然后执行重新训练脚本,脚本的内容为:
echo "训练"
tesseract tg.font.exp0.tif tg.font.exp0 nobatch box.train
echo "生成字符集"
unicharset_extractor tg.font.exp0.box
mftraining -F font_properties -U unicharset -O tg.unicharset tg.font.exp0.tr
echo "聚类"
cntraining tg.font.exp0.tr
echo "重命名"
cp normproto tg.normproto
cp inttemp tg.inttemp
cp pffmtable tg.pffmtable
cp shapetable tg.shapetable
cp unicharset tg.unicharset
echo "创建tessdata"
combine_tessdata tg.
echo "拷贝traineddata"
cp tg.traineddata /usr/local/Cellar/tesseract/3.05.02/share/tessdata/tg.traineddata

然后重新进行文字识别,可以看到刚才识别错误的 “辑”字正确了:
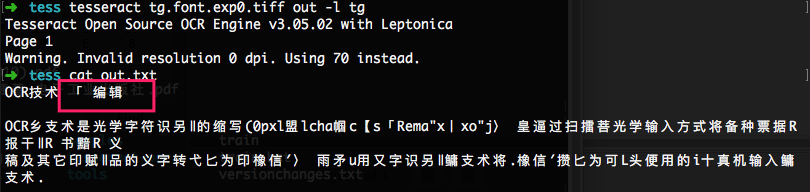
本地搭建好tesseract,可以使用一些第三方的工具包来调用,还是很方便的。
我的AI之路 —— OCR文字识别快速体验版的更多相关文章
- 如何精准实现OCR文字识别?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由云计算基础发表于云+社区专栏 前言 2018年3月27日腾讯云云+社区联合腾讯云智能图像团队共同在客户群举办了腾讯云OCR文字识别-- ...
- 小白学Python——用 百度AI 实现 OCR 文字识别
百度AI功能还是很强大的,百度AI开放平台真的是测试接口的天堂,免费接口很多,当然有量的限制,但个人使用是完全够用的,什么人脸识别.MQTT服务器.语音识别等等,应有尽有. 看看OCR识别免费的量 快 ...
- OCR文字识别笔记总结
OCR的全称是Optical Character Recognition,光学字符识别技术.目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别,交通路牌的识别,车牌的自动识别等等.本 ...
- PHP:基于百度大脑api实现OCR文字识别
有个项目要用到文字识别,网上找了很多资料,效果不是很好,偶然的机会,接触到百度大脑.百度大脑提供了很多解决方案,其中一个就是文字识别,百度提供了三种文字识别,分别是银行卡识别.身份证识别和通用文字识别 ...
- 云+社区分享——腾讯云OCR文字识别
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由云+社区运营团队发布在腾讯云+社区 前言 2018年3月27日腾讯云云+社区联合腾讯云智能图像团队共同在客户群举办了腾讯云OCR文字识 ...
- 百度Ocr文字识别
简述 最近开发一个项目需要用到Ocr文字识别技术来识别手写文字,在评估过程中体验了百度的文字识别和腾讯的文字识别.查找官方开发文档,发现它们都有印刷体和手写体两种符合项目需求的识别模式,但是腾讯的手写 ...
- 百度OCR 文字识别 Android安全校验
百度OCR接口使用总结: 之前总结一下关于百度OCR文字识别接口的使用步骤(Android版本 不带包名配置 安全性弱).这边博客主要介绍,百度OCR文字识别接口,官方推荐使用方式,授权文件(安全模式 ...
- 华为云OCR文字识别 免费在线体验!
嘿,华为云OCR文字识别了解一下,免费在线体验! 物流行业快速提取运单信息.医疗/保险行业单据快速录入.政务办事人证检验,你知道这些都是如何实现的么? 答案就是:OCR文字识别! 作为AI时代效率倍增 ...
- 百度OCR文字识别-Android安全校验
本文转载自好基友upuptop:https://blog.csdn.net/pyfysf/article/details/86438769 效果图: 如下为文章正文: 百度OCR接口使用总结:之前总结 ...
随机推荐
- canvas 实现掉落效果
var canvas = document.getElementById('canvas'); var cxt = canvas.getContext('2d'); cxt.strokeStyle = ...
- MySQL查找SQL耗时瓶颈 SHOW profiles
http://blog.csdn.net/k_scott/article/details/8804384 1.首先查看是否开启profiling功能 SHOW VARIABLES LIKE '%pro ...
- socketserver实例化过程
一.创建server对象时__init__的执行 找继承中的__init__ 这是ThreadingMixIn类中的方法 这是TCPServer类中的方法(父类BaserServer中还会用到fini ...
- vbs解析 JSON格式数据
Function jsonParser(str,jsonKey) Set sc = CreateObject("MSScriptControl.ScriptControl") sc ...
- UVa 10163 Storage Keepers (二分 + DP)
题意:有n个仓库,m个管理员,每个管理员有一个能力值P,每个仓库只能由一个管理员看管,但是每个管理员可以看管k个仓库(但是这个仓库分配到的安全值只有p/k,k=0,1,...),雇用的管理员的工资即为 ...
- HDU1864 最大报销额
Description 现有一笔经费可以报销一定额度的发票.允许报销的发票类型包括买图书(A类).文具(B类).差旅(C类),要求每张发票的总额不得超过1000元,每张发票上,单项物品的价值不得超过6 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...
- 20155205 《Java程序设计》实验四 Android程序设计
20155205 <Java程序设计>实验四 Android程序设计 一.实验内容及步骤 (一) Android Stuidio的安装测试 参考<Java和Android开发学习指南 ...
- 微信接入时tomcat的端口调整
必须以http://或https://开头,分别支持80端口和443端口. www.xx.com 等同于 www.xx.com:80 但tomcat默认端口是8080,需要修改为80 修改方法: TO ...
- 实战--利用Lloyd算法进行酵母基因表达数据的聚类分析
背景:酵母会在一定的时期发生diauxic shift,有一些基因的表达上升,有一些基因表达被抑制,通过聚类算法,将基因表达的变化模式聚成6类. ORF Name R1.Ratio R2.Ratio ...