Ng第十一课:机器学习系统的设计(Machine Learning System Design)
11.1 首先要做什么
11.2 误差分析
11.3 类偏斜的误差度量
11.4 查全率和查准率之间的权衡
11.5 机器学习的数据
11.1 首先要做什么
在接下来的视频将谈到机器学习系统的设计。这些视频将谈及在设计复杂的机器学习系统时,将遇到的主要问题。同时会试着给出一些关于如何巧妙构建一个复杂的机器学习系统的建议。下面的课程讲的东西数学性不强,但是非常有用的,可能在构建大型的机器学习系统时,节省大量的时间。
本周以一个垃圾邮件分类器算法为例进行讨论。
为了解决这样一个问题,首先要做的决定是如何选择并表达特征向量 x。我们可以选择一个由 100 个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为 1,不出现为 0),尺寸为 100×1。 为了构建这个分类器算法,我们可以做很多事,例如:
1. 收集更多的数据,使得有更多的垃圾邮件和非垃圾邮件的样本
2. 基于邮件的路由信息开发一系列复杂的特征
3. 基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
4. 为探测刻意的拼写错误(把 watch 写成 w4tch)开发复杂的算法
在上面这些选项中,非常难决定应该在哪一项上花费时间和精力,作出明智的选择比随着感觉走要更好。当使用机器学习时,总是可以“头脑风暴”一下,想出一堆方法来试试。实际上,当你需要通过头脑风暴来想出不同方法来尝试去提高精度的时候,你可能已经超越了很多人了。
11.2 误差分析
本次将会讲到误差分析(error analysis)的概念。这会帮助你更系统地做出决定。如果你准备研究机器学习的东西,或者构造机器学习应用程序,最好的实践方法 不是建立一个非常复杂的系统,拥有多么复杂的变量;而是构建一个简单的算法,这样你可以很快地实现它。
每当我研究机器学习的问题时,我最多只会花一天的时间,就是字面意义上的 24 小时,来试图很快的把结果搞出来,即便效果不好。坦白的说,就是根本没有用复杂的系统,但是只是很快的得到的结果。即便运行得不完美,但是也把它运行一遍,最后通过交叉验证来检 验数据。一旦做完,你可以画出学习曲线,通过画出学习曲线,以及检验误差,来找出你的算法是否有高偏差和高方差的问题,或者别的问题。
在这样分析之后,再来决定用更多的数据训练,或者加入更多的特征变量是否有用。这么做的原因是:这在你刚接触机器学习问题时是一个很好的方法,你并不能提前知道你是否需要复杂的特征变量,或者你是否需要更多的数据,还是别的什么。提前知道你应该做什么,是非常难的,因为你缺少证据,缺少学习曲线。因此,你很难知道你应该把时间花在什么地方来提高算法的表现。但是当你实践一个非常简单即便不完美的方法时,你可以通过画出学习曲线来做出进一步的选择。你可以用这种方式来避免一种电脑编程里的过早优化问题,这种理念是:我们必须用证据来领导我们的决策,怎样分配自己的时间来优化算法,而不是仅仅凭直觉,凭直觉得出的东西一般总是错误的。
除了画出学习曲线之外,一件非常有用的事是误差分析,我的意思是说:当我们在构 造垃圾邮件分类器时,我会看一看我的交叉验证数据集,然后亲自看一看哪些邮件被算法错误地分类。因此,通过这些被算法错误分类的垃圾邮件与非垃圾邮件,你可以发现某些系统性的规律:什么类型的邮件总是被错误分类。经常地这样做之后,这个过程能启发你构造新的特征变量,或者告诉你:现在这个系统的短处,然后启发你如何去提高它。
构建一个学习算法的推荐方法为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
2. 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
3. 进行误差分析:人工检查交叉验证集中算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势
以垃圾邮件过滤器为例,误差分析要做的既是检验交叉验证集中 算法产生错误预测的所有邮件,看是否能将这些邮件按照类分组。例如医药品垃圾邮件,仿冒品垃圾邮件或者密码窃取邮件等。然后看分类器对哪一组邮件的预测误差最大,并着手优化。思考怎样能改进分类器。例如,发现是否缺少某些特征,记下这些特征出现的次数。 例如记录下错误拼写出现了多少次,异常的邮件路由情况出现了多少次等等,然后从出现次数最多的情况开始着手优化。
误差分析并不总能帮助我们判断应该采取怎样的行动。有时我们需要尝试不同的模型,然后进行比较,在模型比较时,用数值来判断哪一个模型更好更有效,通常是看交叉验证集的误差。在垃圾邮件分类器例子中,对于“ 我 们是否应该将discount/discounts/discounted/discounting 处理成同一个词?”如果这样做可以改善我们算法,我们会采用一些截词软件。误差分析不能帮助我们做出这类判断,我们只能尝试采用和不采用截词软件这两种不同方案,然后根据数值检验的结果来判断哪一种更好。
因此,当你在构造学习算法的时候,你总是会去尝试很多新的想法,实现出很多版本的学习算法,如果每一次你实践新想法的时候,你都要手动地检测这些例子,去看看是表现差还是表现好,那么这很难让你做出决定。到底是否使用词干提取,是否区分大小写。但是通过一个量化的数值评估,你可以看看这个数字,误差是变大还是变小了。你可以通过它更快地实践你的新想法,它基本上非常直观地告诉你:你的想法是提高了算法表现,还是让它变得更坏,这会大大提高你实践算法时的速度。所以我强烈推荐在交叉验证集上来实施误差分析,而不是在测试集上。
总结一下,当你在研究一个新的机器学习问题时,我总是推荐你实现一个较为简单快速、 即便不是那么完美的算法。当你有了初始的实现之后,它会变成一个非常有力的工具,来帮助你决定下一步的做法。通过误差分析,来看看他犯了什么错,然后来决定优化的方式。
另一件事是:假设你有了一个快速而不完美的算法实现,又有一个数值的评估数据,这会帮助你尝试新的想法,快速地发现你尝试的这些想法是否能够提高算法的表现,从而你会更快地做出决定,在算法中放弃什么,吸收什么
误差分析可以帮助我们系统化地选择该做什么。
11.3 类偏斜的误差度量
在前面的课程中提到了误差分析,以及设定误差度量值的重要性。那就是,设定某个实数来评估你的学习算法,并衡量它的表现,有了算法的评估和误差度量值。有一件重要的事情要注意,就是使用一个合适的误差度量值,这有时会对于你的学习算法造成非常微妙的影响,这件重要的事情就是偏斜类(skewed classes)的问题。
类偏斜情况表现为训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例。 例如用算法来预测癌症是否是恶性的,在我们的训练集中,只有0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有 0.5%。然而我们通过训练而得到的神经网络算法却有 1%的误差。这时,误差的大小是不能视为评判算法效果的依据的。
查准率(Precision)和查全率(Recall) 可以将算法预测的结果分成四种情况:
1. 正确肯定(True Positive,TP):预测为真,实际为真
2. 正确否定(True Negative,TN):预测为假,实际为真
3. 错误肯定(False Positive,FP):预测为真,实际为假
4. 错误否定(False Negative,FN):预测为假,实际为假 则:
查准率=TP/(TP+FP)例,在所有预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病 人的百分比,越高越好。
查全率=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的 病人的百分比,越高越好。
这样,对于我们刚才那个总是预测病人肿瘤为良性的算法,其查全率是 0。
11.4 查全率和查准率之间的权衡
在之前谈到查准率和召回率,作为遇到偏斜类问题的评估度量值。在多应用中,我们希望能够保证查准率和召回率的相对平衡。在这节课中,我将告诉你应该怎么做,同时也向你展示一些查准率和召回率作为算法评估度量值的更有效的方式。继续沿用刚才预测肿瘤性质的例子。假使,我们的算法输出的结 果在 0-1 之间,我们使用阀值 0.5 来预测真和假。

如果希望只在非常确信的情况下预测为真(肿瘤为恶性),即希望更高的查准率,可以使用比 0.5 更大的阀值,如 0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比 0.5更小的阀值,如 0.3。
可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数据的不同而不同:
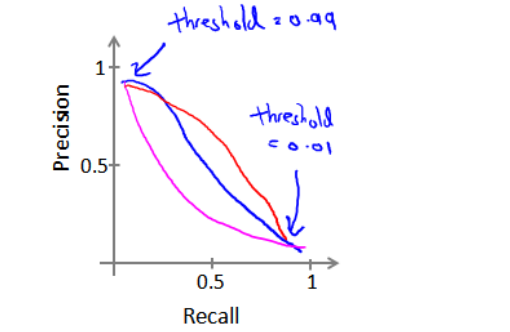
我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算 F1 值(F1 Score),其计算公式为:
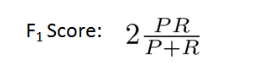
选择使得 F1 值最高的阀值。
11.5 机器学习的数据
之前讨论了评价指标。在这个视频中要稍微转换一下,讨论一下机器学习系统设计中另一个重要的方面,这往往涉及到用来训练的数据有多少。在之前的一些视频中,我曾告诫大家不要盲目地开始,而是花大量的时间来收集大量的数据,因为数据有时是唯一能实际起到作用的。但事实证明,在一定条件下,我会在这个视频里讲到这些条件是什么。得到大量的数据并在某种类型的学习算法中进行训练,可以是一种有效的方法来获得一个具有良好性能的学习算法。而这种情况往往出现在 这些条件对于你的问题都成立 并且你能够得到大量数据的情况下。这可以是一个很好的方式来获得非常高性能的学习算法。
什么时候我们会希望获得更多数据,而非修改算法。这个问题值得讨论。

如果算法是高偏差的,且代价函数很小,那么增加训练集的数据量不太可能导致过拟合,可使得交叉验证误差和训练误差之间差距更小。这种情况下,考虑获得更多数据。
也可以这样来认识,我们希望算法低方差,低偏差,通过选择更多的特征来降低方差,再通过增加数据量来降低偏差。
Ng第十一课:机器学习系统的设计(Machine Learning System Design)的更多相关文章
- 斯坦福第十一课:机器学习系统的设计(Machine Learning System Design)
11.1 首先要做什么 11.2 误差分析 11.3 类偏斜的误差度量 11.4 查全率和查准率之间的权衡 11.5 机器学习的数据 11.1 首先要做什么 在接下来的视频中,我将谈到机器 ...
- 11、 机器学习系统的设计(Machine Learning System Design)
11.1 首先要做什么 在接下来的视频中,我将谈到机器学习系统的设计.这些视频将谈及在设计复杂的机器学习系统时,你将遇到的主要问题.同时我们会试着给出一些关于如何巧妙构建一个复杂的机器学习系统的建议. ...
- Machine Learning - XI. Machine Learning System Design机器学习系统的设计(Week 6)
http://blog.csdn.net/pipisorry/article/details/44119187 机器学习Machine Learning - Andrew NG courses学习笔记 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- Stanford机器学习笔记-7. Machine Learning System Design
7 Machine Learning System Design Content 7 Machine Learning System Design 7.1 Prioritizing What to W ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
- Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记
Machine Learning System Design下面会讨论机器学习系统的设计.分析在设计复杂机器学习系统时将会遇到的主要问题,给出如何巧妙构造一个复杂的机器学习系统的建议.6.4 Buil ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
随机推荐
- Memcached使用与纠错(附代码和相关dll)
今天没事研究一下,谁想到遇到了几个dll找不到,网上也不好找到,索性功夫不负有心人.贴出代码和相关的dll Memcached代码:(网上都是的,很多人都保存了这个代码) using Memcache ...
- scrapy 安装流程和启动
#Windows平台 1. pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pyt ...
- sqlserver 2008 还原数据库时,提示有用户正在使用,无法取得使用占有权
sqlserver 2008 还原数据库时,提示有用户正在使用,无法取得使用占有权 这个时候,只需要把数据库分离出去,再附加,然后还原即可 分离数据库的时候能看到有几个数据连接
- accept与epoll惊群 转载
今天打开 OneNote,发现里面躺着一篇很久以前写的笔记,现在将它贴出来. 1. 什么叫惊群现象 首先,我们看看维基百科对惊群的定义: The thundering herd problem occ ...
- jQuery的节点选择
jQuery.parent(expr) 找父亲节点,可以传入expr进行过滤,比如$("span").parent()或者$("span").parent(&q ...
- a[i++]
今天才知道,a[i++]到底是什么意思:: 其实也很简单了,就是a[i]的值还是a[i],然后i自增1: 把这篇博客当作平常各种错题博客吧,把各种从网上抄的代码不懂的地方写到这个地方算了 ====== ...
- c sharp multithreading
1. 静态方法 using System; using System.Threading; namespace PlusThread { class Program { static void Ma ...
- Moving Average from Data Stream LT346
Given a stream of integers and a window size, calculate the moving average of all integers in the sl ...
- install virtualenv
$ [sudo] pip install virtualenv $ mkdir ~/envs $ virtualenv ~/envs/lsbaws/ $ cd ~/envs/lsbaws/ $ ls ...
- Python 中Lambda 表达式 实例解析
Lambda 表达式 lambda表达式是一种简洁格式的函数.该表达式不是正常的函数结构,而是属于表达式的类型.而且它可以调用其它函数. 1.基本格式: lambda 参数,参数...:函数功能代码 ...