Hadoop(三)搭建Hadoop全分布式集群
阅读目录(Content)
- 一、搭建Hadoop全分布式集群前提
- 1.1、网络
- 1.2、安装jdk
- 1.3、安装hadoop
- 二、Hadoop全分布式集群搭建的配置
- 2.1、hadoop-env.sh
- 2.2、core-site.xml
- 2.3、hdfs-site.xml
- 2.4.mapred-site.xml
- 2.5、yarn-site.xml
- 2.6、创建上面配置的目录
- 三、全分布式集群搭建测试
- 3.1、运行环境
- 3.2、服务器集群的启动与关闭
- 3.3、效果
- 3.4、监控平台
- 四、Hadoop全分布式集群配置免密登录实现主节点控制从节点
- 4.1、配置主从节点之间的免密登录
- 五、配置集群中遇到的问题
前言
上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的。接下来我将给大家分享一下全分布式集群的搭建!
其实搭建最基本的全分布式集群和伪分布式集群基本没有什么区别,只有很小的区别
一、搭建Hadoop全分布式集群前提
1.1、网络
1)如果是在一台虚拟机中安装多个linux操作系统的话,可以使用NAT或桥接模式都是可以的。试一试可不可以相互ping通!
2)如果在一个局域网当中,自己的多台电脑(每台电脑安装相同版本的linux系统)搭建,将所要使用的Ubuntu操作系统的网络模式调整为桥接模式。
步骤:
一是:在要使用的虚拟机的标签上右键单击,选择设置,选择网络适配器,选择桥接模式,确定
二是:设置完成之后,重启一下虚拟机
三是:再设置桥接之前将固定的IP取消
桌面版:通过图形化界面设置的。
服务器版:在/etc/network/interfaces
iface ens33 inet dhcp
#address ...
四是:ifconfig获取IP。172.16.21.xxx
最后试一试能不能ping通
1.2、安装jdk
每一个要搭建集群的服务器都需要安装jdk,这里就不介绍了,可以查看上一篇
1.3、安装hadoop
每一个要搭建集群的服务器都需要安装hadoop,这里就不介绍了,可以查看上一篇。
二、Hadoop全分布式集群搭建的配置
配置/opt/hadoop/etc/hadoop相关文件

2.1、hadoop-env.sh
25行左右:export JAVA_HOME=${JAVA_HOME}
改成:export JAVA_HOME=/opt/jdk
2.2、core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mip:9000</value>
</property>
</configuration>
分析:
mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
9000:主节点和从节点配置的端口都是9000
2.3、hdfs-site.xml
注意:**:下面配置了几个目录。需要将/data目录使用-R给权限为777。

<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
</configuration>
分析:
dfs.nameservices:在一个全分布式集群大众集群当中这个的value要相同
dfs.replication:因为hadoop是具有可靠性的,它会备份多个文本,这里value就是指备份的数量(小于等于从节点的数量)
一个问题:
dfs.datanode.data.dir:这里我在配置的时候遇到一个问题,就是当使用的这个的时候从节点起不来。当改成fs.datanode.data.dir就有用了。
但是官方给出的文档确实就是这个呀!所以很邪乎。因为只有2.0版本之前是fs
2.4.mapred-site.xml
注意:如果在刚解压之后,是没有这个文件的,需要将mapred-site.xml.template复制为mapred-site.xml。
<configuration>
<property>
<!-指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.5、yarn-site.xml
<configuration>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mip</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data/hadoop/yarn/nm</value>
</property>
分析:
mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
2.6、创建上面配置的目录
sudo mkdir -p /data/hadoop/hdfs/nn
sudo mkdir -p /data/hadoop/hdfs/dn
sudo mkdir -p /data/hadoop/hdfs/snn
sudo mkdir -p /data/hadoop/yarn/nm
一定要设置成:sudo chmod -R 777 /data
三、全分布式集群搭建测试
3.1、运行环境
有三台ubuntu服务器(ubuntu 17.04):
主机名:udzyh1 IP:1.0.0.5 作为主节点(名字节点)
主机名:server1 IP:1.0.0.3 作为从节点(数据节点)
主机名:udzyh2 IP:1.0.0.7 作为从节点(数据节点)
jdk1.8.0_131
hadoop 2.8.1
3.2、服务器集群的启动与关闭

名字节点、资源管理器:这是在主节点中启动或关闭的。
数据节点、节点管理器:这是在从节点中启动或关闭的。
MR作业日志管理器:这是在主节点中启动或关闭的。
3.3、效果
在主节点:udzyh1中
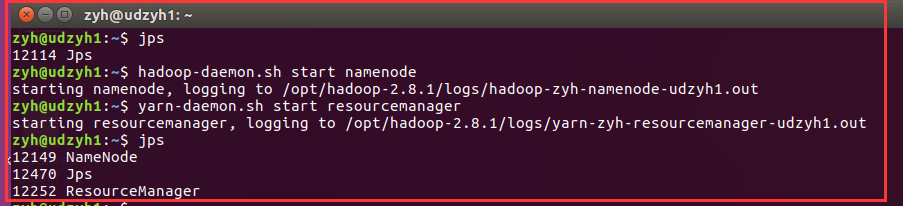
在从节点:server1中
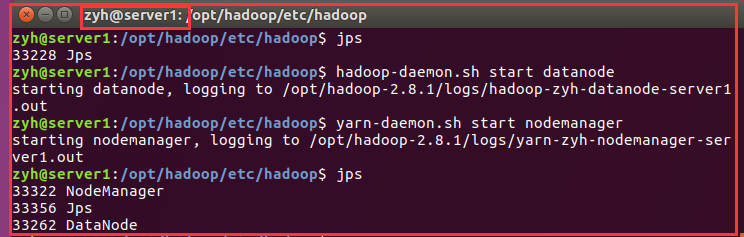
在从节点:udzyh2中
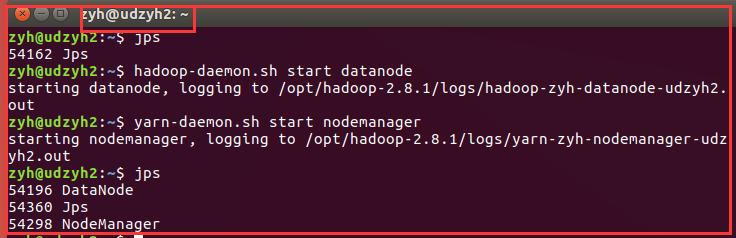
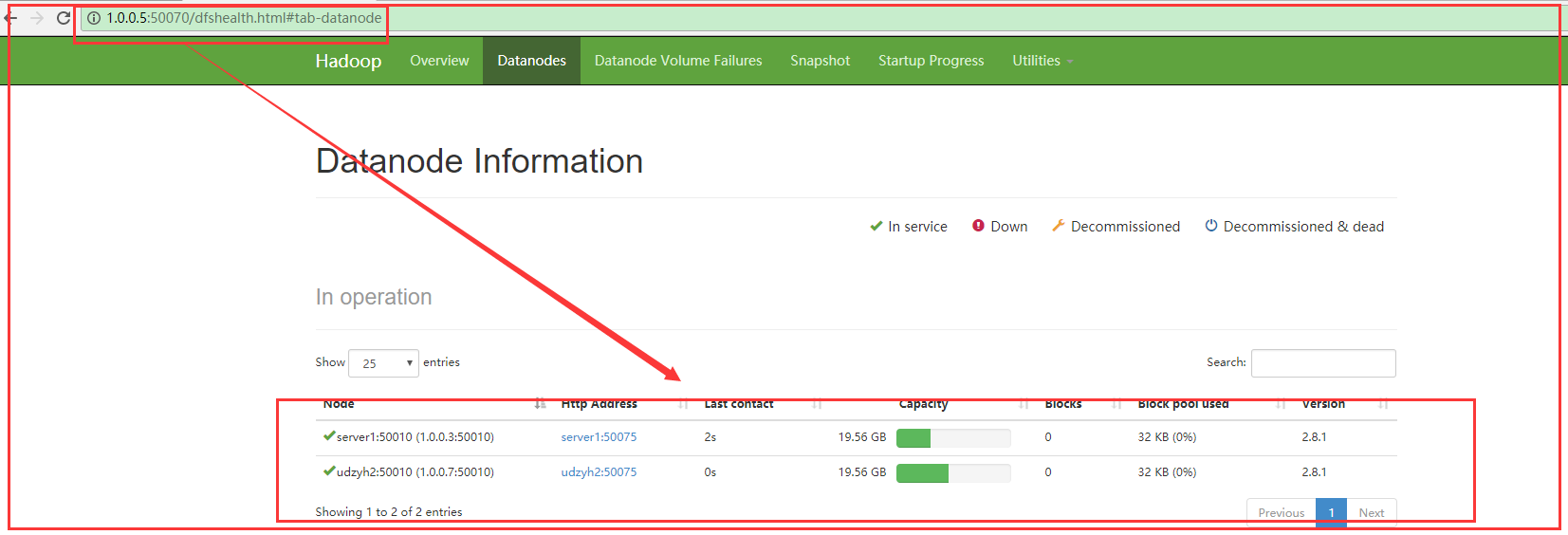
我们在主节点的web控制页面中:http:1.0.0.5:50070中查看到两个从节点
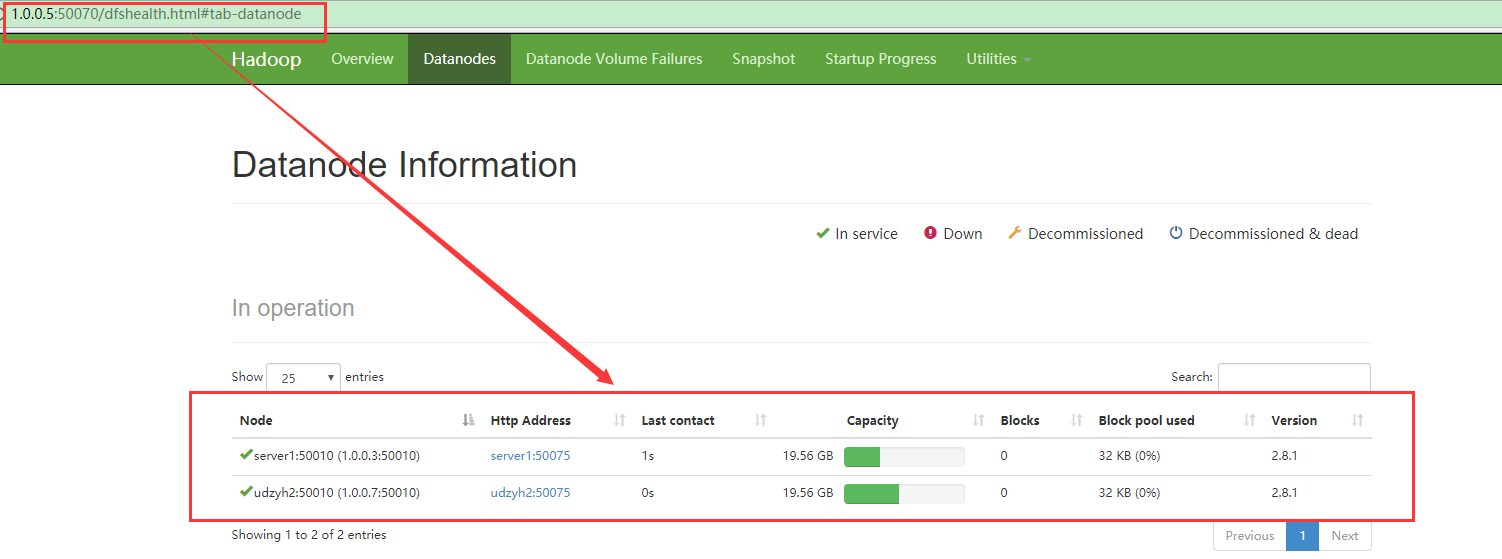
说明配置成功
3.4、监控平台

四、Hadoop全分布式集群配置免密登录实现主节点控制从节点
配置这个是为了实现主节点管理(开启和关闭)从节点的功能:

我们只需要在主节点中使用start-dfs.sh/stop-dfs.sh就能开启或关闭namenode和所有的datanode,使用start-yarn.sh/stop-yarn.sh就能开启或关闭resourcemanager和所有的nodemanager。
4.1、配置主从节点之间的免密登录
1)在所有的主从节点中执行
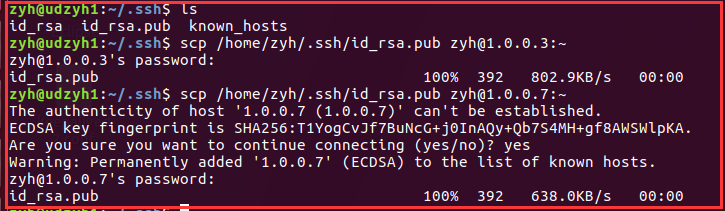
3)在所有的从节点中执行

在从节点1.0.0.7
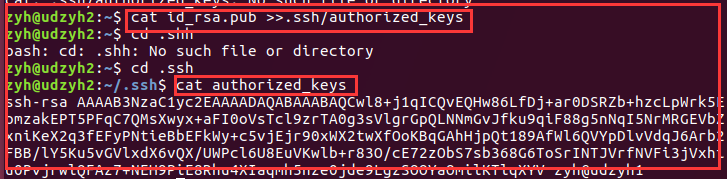
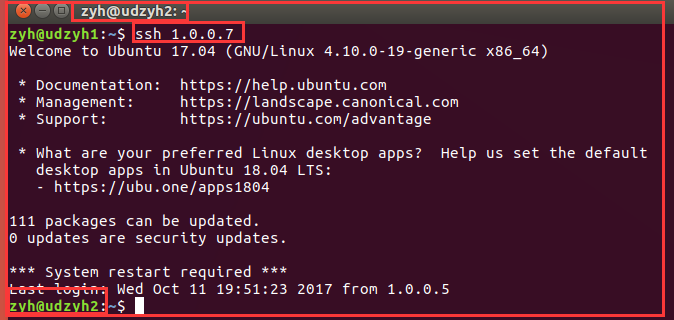
4)测试

我们可以查看他们是用户名相同的,所以可以直接使用ssh 1.0.0.3远程连接
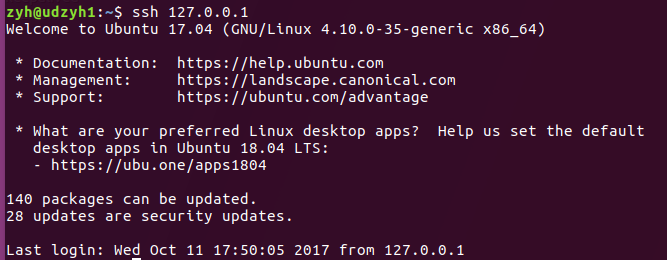
4.2、实现主节点控制从节点
1)在主节点中
打开vi /opt/hadoop/etc/hadoop/slaves

4.3、测试实现主节点控制从节点
1)在主节点的服务器中执行start-dfs.sh

2)在web监控平台查询
3)在主节点的服务器中执行stop-dfs.sh
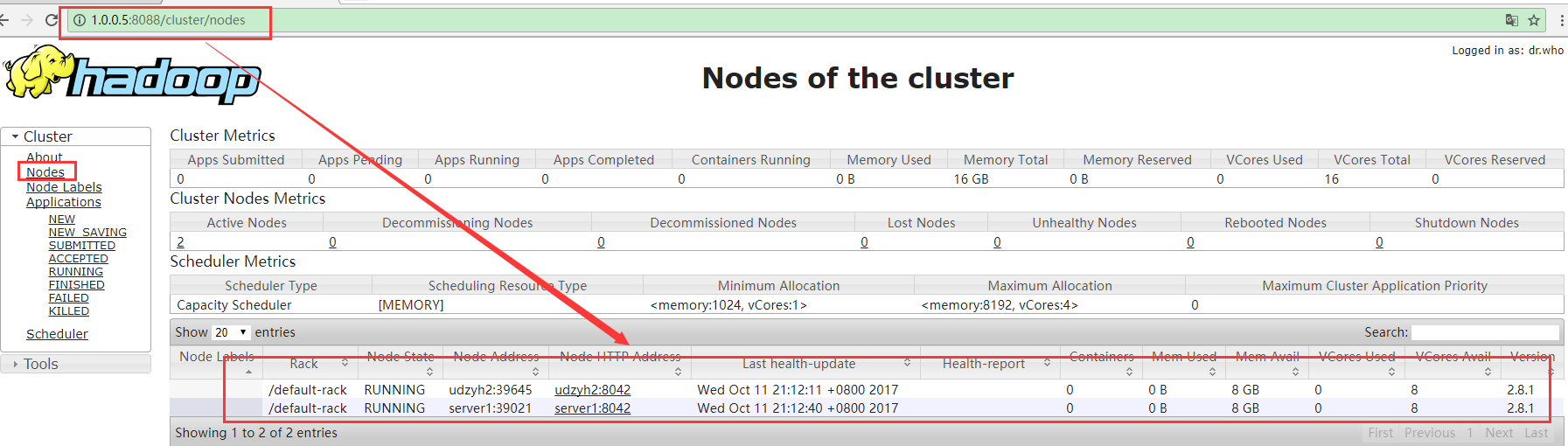
3)在主节点的服务器中执行start-yarn.sh

4)在web监控平台查询到
5)在主节点的服务器中执行stop-yarn.sh

五、配置集群中遇到的问题
2)主节点和从节点启动了,但是在主节点的web控制页面查找不到从节点(linux系统安装在不同的物理机上面)
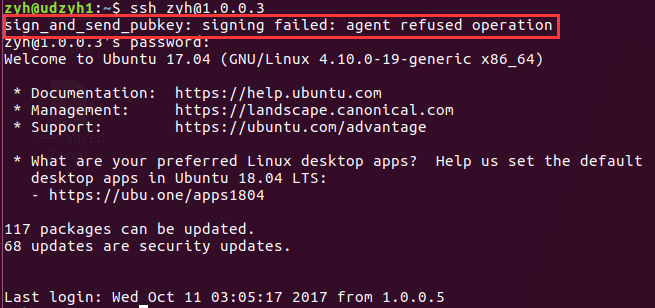
解决方案:
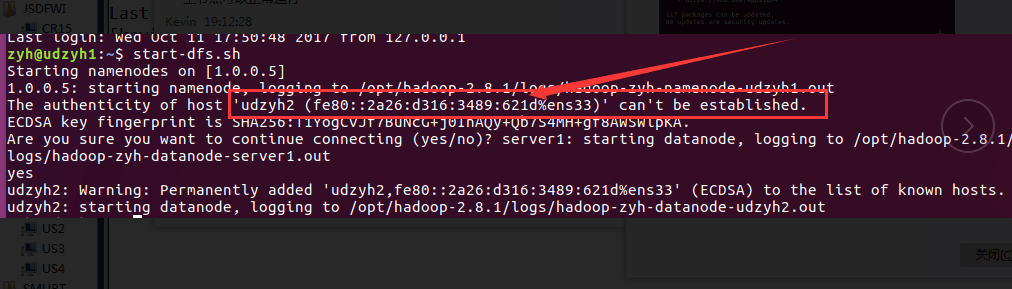
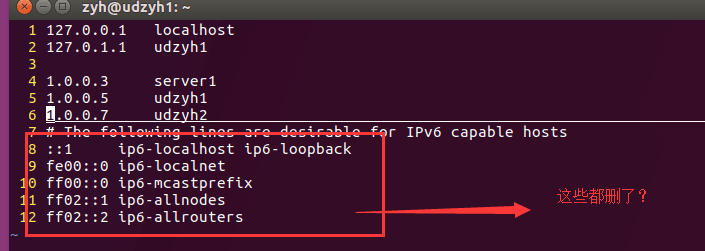
它不能建立IPv6的连接,所以删除了IPv6之后系统会使用IPv4(在主节点上添加从节点的标识的)
4)在主节点的web控制页面查询不到从节点信息(但是使用jps可以查询到)
-END-

Hadoop(三)搭建Hadoop全分布式集群的更多相关文章
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
- 【web】 亿级Web系统搭建——单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架 ...
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- 使用Cloudera Manager搭建HDFS完全分布式集群
使用Cloudera Manager搭建HDFS完全分布式集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 关于Cloudera Manager的搭建我这里就不再赘述了,可以参考 ...
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- Hadoop实战4:MapR分布式集群的安装配置及shell自动化脚本
MapR的分布式集群安装过程还是很艰难的,远远没有计划中的简单.本人总结安装配置,由于集群有很多机器,手动每台配置是很累的,编写了一个自动化配置脚本,下面以脚本为主线叙述(脚本并不完善,后续继续完善中 ...
随机推荐
- 20155205 《Java程序设计》0510课上实践博客
20155205 <Java程序设计>0510课上实践博客 一.教材代码检查-p98 未提交成功原因: 一开始在iterm中运行,但是结果出错,没有时间提交了.这个提交其实很简单,没有提交 ...
- P750 内存插槽
查看p750内存插槽占用情况 lscfg -vp | grep -p DIMM Memory DIMM: Record Name.................VINI Flag Field.... ...
- leetcode - [4]Sort List
Sort a linked list in O(n log n) time using constant space complexity. 思路:采用归并排序或者快速排序 #include < ...
- webservice之helloword(web)rs
spring整合webservice 1.pom.xml文件 <dependencies> <!-- cxf 进行rs开发 必须导入 --> <dependency> ...
- struts2马士兵笔记
Struts2 学习笔记 目录 01 Struts2-Action 一. Struts作用: 二. 搭建Struts2的运行环境: 三. Namespa ...
- RMQ算法区间最值
问题类型:是多次询问一个大区间里子区间的最值问题 dp + 位运算的思想处理 rmax[i][j]表示从i开始到i + 2^j - 1的区间里的最大值dp[i][j] ==== (i,i + 2^j ...
- ASP.NET Web API 框架研究 Web Host模式路由及将请求转出到消息处理管道
Web Host 模式下的路由本质上还是通过ASP.NET 路由系统来进行路由的,只是通过继承和组合的方式对ASP.NET路由系统的内部的类进行了一些封装,产生自己专用一套类结构,功能逻辑基本都是一样 ...
- jsp中文乱码解决办法
一.JSP页面显示乱码 二.表单提交中文时出现乱码 三.数据库连接 大家在JSP的开发过程中,经常出现中文乱码的问题,可能一至困扰着您,我现在把我在JSP开发中遇到 的中文乱码的问题及解决办法写出来供 ...
- JS中图片飞飞效果
当鼠标在界面上移动的时候,后面有一连串的图片跟随者一起飘动,效果如下: 实现的基本思想:准备五个img标签,为了方便控制都放在一个div里面,设置div的定位方式为 fixed,设置成这中定位方式主要 ...
- jQuery获取Table某列的值
在写此篇博文时,发现在以前曾写过<获取DataTable选择第一行某一列值>http://www.cnblogs.com/insus/p/5434062.html . 但是与此篇所说的完全 ...