MySQL JOIN原理
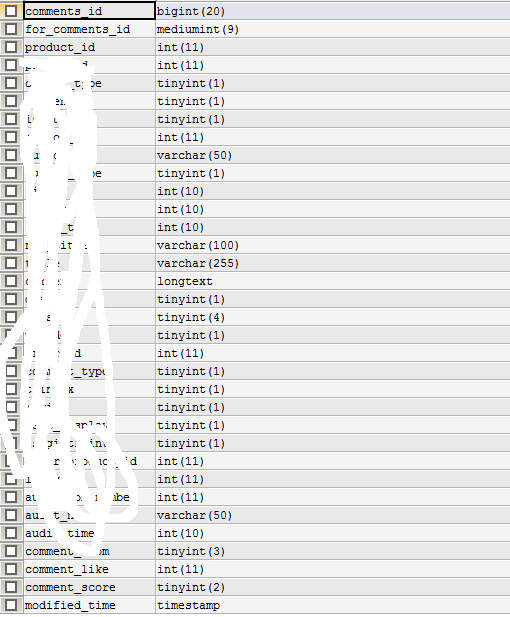
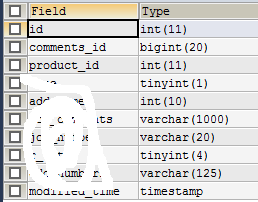
先看一下实验的两张表:
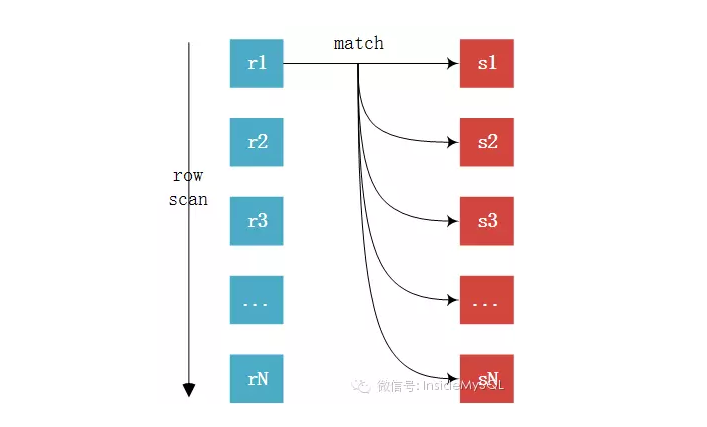
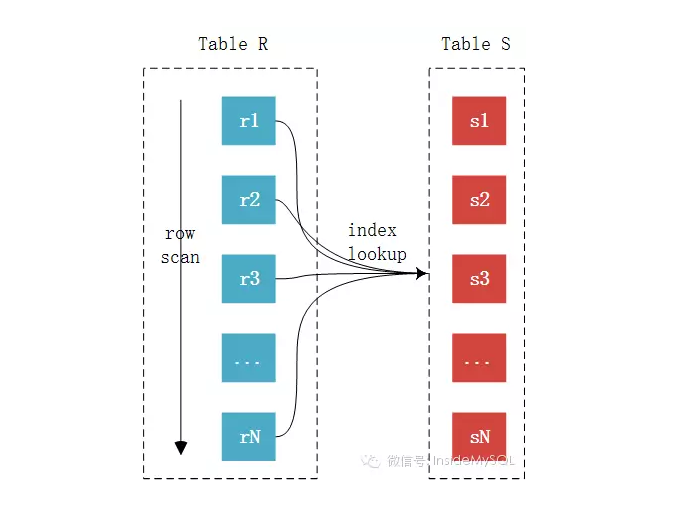
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。MySQL JOIN原理的更多相关文章
- MySQL JOIN原理(转)
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- 由一个场景分析Mysql的join原理
背景 这几天同事写报表,sql语句如下 select * from `sail_marketing`.`mk_coupon_log` a left join `cp0`.`coupon` c on c ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL查询原理及其慢查询优化案例分享(转)
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更 好的使用它,已经成为开发工程师的必修课,我们经常会从职 ...
- MySQL索引原理与慢查询优化
索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才 ...
随机推荐
- BZOJ4036 HAOI2015按位或(概率期望+容斥原理)
考虑min-max容斥,改为求位集合内第一次有位变成1的期望时间.求出一次操作选择了S中的任意1的概率P[S],期望时间即为1/P[S]. 考虑怎么求P[S].P[S]=∑p[s] (s&S& ...
- linux、windows搭建nginx出现问题集锦
1.启动提示端口被占用(linux) 启动ninx出现nginx: [emerg] bind() to0.0.0.0:80 failed (98: Address already in use) ne ...
- 如何用React, Webcam和JS Barcode SDK创建Web扫码App
这篇文章分享下如何结合React Webcam和Dynamsoft JavaScript Barcode SDK来创建Web扫码App. Web实时扫码 从GitHub上下载react-webcam. ...
- Java中public、private、protect对数据成员或成员函数的访问限制
Java类中对数据成员.成员函数的访问限制修饰有:public.protect.private.friendly(包访问限制) public修饰的数据成员或成员函数是对所有用户开放的,所有用户可以直接 ...
- webpack插件自动加css3前缀
想要webpack帮忙自动加上“-webkit-”之类的css前缀,我们需要用到postcss-loader和它的插件autoprefixer 1.安装 npm i postcss-loader au ...
- 【转载】SQL注入原理讲解
这几篇文章讲的都很不错,我看了大概清除了sql注入是怎么一回事,打算细细研究一下这个知识,另写一篇博客: 原文地址:http://www.cnblogs.com/rush/archive/2011/1 ...
- Swift学习笔记1
1.Swift 的String类型是值类型. 如果您创建了一个新的字符串,那么当其进行常量.变量赋值操作,或在函数/方法中传递时,会进行值拷贝. 任何情况下,都会对已有字符串值创建新副本,并对该新副本 ...
- webstorm去掉vue错误提示
- ReactJS -- 初学入门
<!DOCTYPE html> <html> <head> <script src="build/react.js"></sc ...
- Angular 下的 directive (part 2)
ngCloak ngCloak指令被使用在,阻止angular模板从浏览器加载的时候出现闪烁的时候.使用它可以避免闪烁问题的出现. 该指令可以应用于<body>元素,但首选使用多个ng ...