Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark。由于MapReduce中间计算均需要写入磁盘,而Spark是放在内存中,所以总体来讲Spark比MapReduce快很多。默认情况下,Hive on Spark 在YARN模式下支持Spark。
因为本人在之前搭建的集群中,部署的环境为:
hadoop2.7.3
hive2.3.4
scala2.12.8
kafka2.12-2.10
jdk1.8_172
hbase1.3.3
sqoop1.4.7
zookeeper3.4.12
#java
export JAVA_HOME=/usr/java/jdk1..0_172-amd64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #hbase
export HBASE_HOME=/home/workspace/hbase-1.2.
export PATH=$HBASE_HOME/bin:$PATH #hadoop
export HADOOP_HOME=/home/workspace/hadoop-2.7.
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
###enable hadoop native library
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native #hive
export HIVE_HOME=/home/workspace/software/apache-hive-2.3.
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=.:$HIVE_HOME/bin:$PATH
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=$HCAT_HOME/bin:$PATH #Sqoop
export SQOOP_HOME=/home/workspace/software/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin # zookeeper
export ZK_HOME=/home/workspace/software/zookeeper-3.4.12
export PATH=$ZK_HOME/bin:$PATH #maven
export MAVEN_HOME=/home/workspace/software/apache-maven-3.6.0
export M2_HOME=$MAVEN_HOME
export PATH=$PATH:$MAVEN_HOME/bin #scala
export SCALA_HOME=/home/workspace/software/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH #kafka
export KAFKA_HOME=/home/workspace/software/kafka_2.11-2.1.0
export PATH=$KAFKA_HOME/bin:$PATH #kylin
export KYLIN_HOME=/home/workspace/software/apache-kylin-2.6.0
export KYLIN_CONF_HOME=$KYLIN_HOME/conf
export PATH=:$PATH:$KYLIN_HOME/bin:$CATALINE_HOME/bin
export tomcat_root=$KYLIN_HOME/tomcat #变量名小写
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.3.4.jar #变量名小写 #spark
export SPARK_HOME=/home/workspace/software/spark-2.0.0
export PATH=:$PATH:$SPARK_HOME/bin
现在想部署spark上去,鉴于hive2.3.4支持的spark版本为2.0.0,所以决定部署spark2.0.0,但是spark2.0.0,默认是基于scala2.11.8编译的,所以,决定基于scala2.12.8手动编译一下spark源码,然后进行部署。本文默认认为前面那些组件都已经安装好了,本篇只讲如何编译spark源码,如果其他的组件部署不清楚,请参见本人的相关博文。
1. 下载spark2.0.0源码
cd /home/workspace/software
wget http://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0.tgz
tar -xzf spark-2.0..tgz
cd spark-2.0.
2. 修改pom.xml改为用scala2.12.8编译
vim pom.xml
修改scala依赖版本为2.12.8(原来为2.11.8)
<scala.version>2.12.</scala.version>
<scala.binary.version>2.12</scala.binary.version>
3. 修改make-distribution.sh
cd /home/workspace/software/spark-2.0./dev
vim make-distribution.sh
修改其中的VERSION,SCALA_VERSION,SPARK_HADOOP_VERSION,SPARK_HIVE为对应的版本值
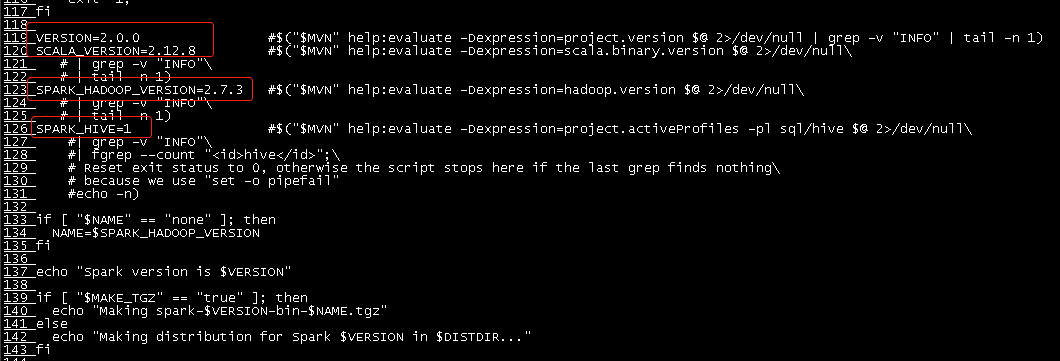
其中SPARK_HIVE=1表示打包hive,非1值为不打包hive。
此步非必须,若不给定,它也会从maven源中下载,为节省编译时间,直接给定;
4. 下载zinc0.3.9
Zinc is a long-running server version of SBT’s incremental compiler. When run locally as a background process, it speeds up builds of Scala-based projects like Spark. Developers who regularly recompile Spark with Maven will be the most interested in Zinc. The project site gives instructions for building and running zinc; OS X users can install it using brew install zinc.
If using the build/mvn package zinc will automatically be downloaded and leveraged for all builds. This process will auto-start after the first time build/mvn is called and bind to port 3030 unless the ZINC_PORT environment variable is set. The zinc process can subsequently be shut down at any time by running build/zinc-<version>/bin/zinc -shutdown and will automatically restart whenever build/mvn is called.
wget https://downloads.typesafe.com/zinc/0.3.9/zinc-0.3.9.tgz #下载zinc-0.3.9.tgz,scala编译库,如果不事先下载,编译时会自动下载
将zinc-0.3.9.tgz解压到/home/workspace/software/spark-2.0.0/build目录下
tar -xzvf zinc-0.3..tgz -C /home/workspace/software/spark-2.0./build
5. 下载scala2.12.8 binary file
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz #下载scala-2.12.8.tgz,scala编译库,如果不事先下载,编译时会自动下载
tar -xzvf scala-2.12..tgz -C /home/workspace/software/spark-2.0./build
6. 编译spark
cd /home/workspace/software/spark-2.0./dev
./make-distribution.sh --name "hadoop2.7.3-with-hive" --tgz -Dhadoop.version=2.7. -Dscala-2.12 -Phadoop-2.7 -Pyarn -Phive -Phive-thriftserver -Pparquet-provided -DskipTests clean package
#或者
#./make-distribution.sh --name "hadoop2.7-with-hive" --tgz "-Pyarn,-Phive,-Phive-thriftserver,hadoop-provided,hadoop-2.7,parquet-provided,-Dscala-2.12,-Dhadoop.version=2.7.3,-DskipTests" clean package
####参数解释:
# -DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。
# -Dhadoop.version 和-Phadoop: Hadoop 版本号,不加此参数时hadoop 版本为1.0.4 。
# -Pyarn :是否支持Hadoop YARN ,不加参数时为不支持yarn 。
# -Phive和-Phive-thriftserver:是否在Spark SQL 中支持hive ,hive jdbc支持,不加此参数时为不支持hive 。
# –with-tachyon :是否支持内存文件系统Tachyon ,不加此参数时不支持tachyon 。
# –tgz :在根目录下生成 spark-$VERSION-bin.tgz ,不加此参数时不生成tgz 文件,只生成/dist 目录。
# –name :和–tgz结合可以生成spark-$VERSION-bin-$NAME.tgz的部署包,不加此参数时NAME为hadoop的版本号。
# -Phadoop-provided: 不包含hadoop生态的其他库文件,在yarn模式部署时,不包含此参数,可能会造成有些文件有多个不同的版本,加入此参数后,一些hadoop生态的工程将不会被包含进来,如ZooKeeper,Hadoop.
或者使用maven编译
cd /home/workspace/software/spark-2.0.0
export MAVEN_OPTS="-Xmx6g -XX:MaxPermSize=2g -XX:ReservedCodeCacheSize=2g" #jdk .8不需要设置这个参数,但是1.8以下版本jdk需要设置这个参数
../build/mvn -Dscala-2.12. -Phadoop-provided -Pparquet-provided -Phadoop-2.7 -Dhadoop.version=2.7. -Pyarn -Phive -Phive-thriftserver -DskipTests clean package #也可以使用maven编译
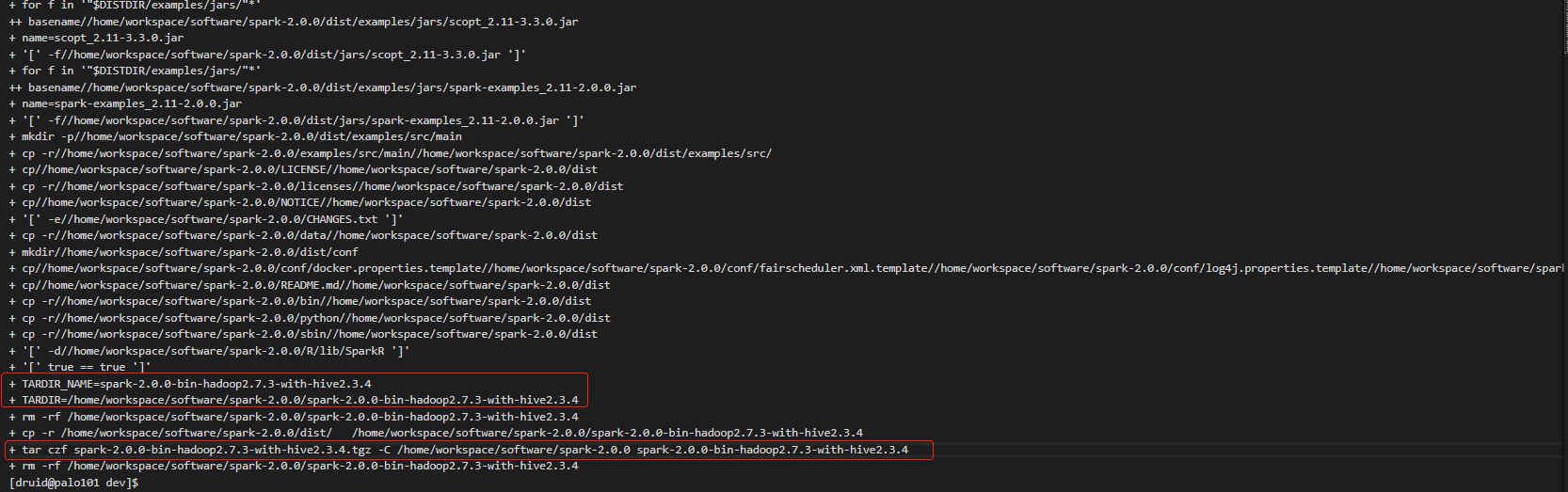
下面截图时使用/make-distribution.sh编译的截图

编译时间大概在半小时以上。
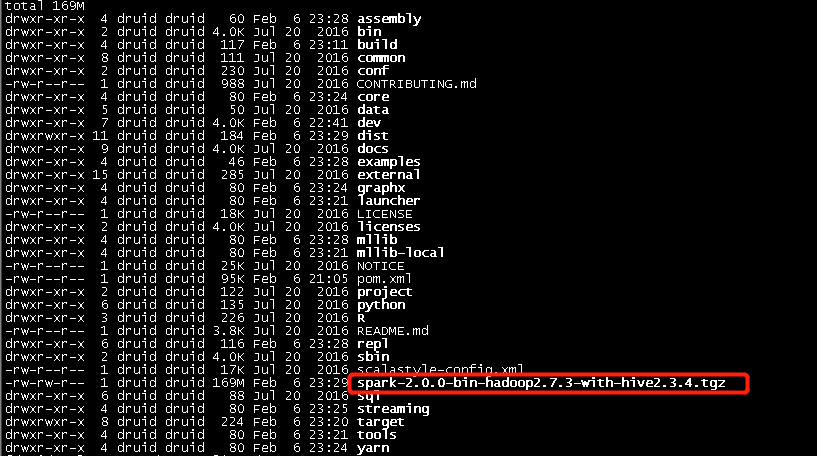
编译出来的二进制包在/home/workspace/software/spark-2.0.0根目录下
注:如果编译过程中出现类似
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.:testCompile (scala-test-compile-first) on project spark-core_2.: Execution scala-test-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.:testCompile failed. CompileFailed -> [Help ]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help ] http://cwiki.apache.org/confluence/display/MAVEN/PluginExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :spark-core_2.
这样的错误,先执行一下:
./change-scala-version.sh 2.11
ps -ef | grep zinc
kill -9 {zinc process id}
然后重新编译即可。
编译完成!
Spark2.0.0源码编译的更多相关文章
- spark2.1.0的源码编译
本文介绍spark2.1.0的源码编译 1.编译环境: Jdk1.8或以上 Hadoop2.7.3 Scala2.10.4 必要条件: Maven 3.3.9或以上(重要) 点这里下载 http:// ...
- 英蓓特Mars board的android4.0.3源码编译过程
英蓓特Mars board的android4.0.3源码编译过程 作者:StephenZhu(大桥++) 2013年8月22日 若要转载,请注明出处 一.编译环境搭建及要点: 1. 虚拟机软件virt ...
- 非寻常方式学习ApacheTomcat架构及10.0.12源码编译
概述 开启博客分享已近三个月,感谢所有花时间精力和小编一路学习和成长的伙伴们,有你们的支持,我们继续再接再厉 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Tomcat官 ...
- 解决Tomcat10.0.12源码编译问题进而剖析其优秀分层设计架构
概述 Tomcat.Jetty.Undertow这几个都是非常有名实现Servlet规范的应用服务器,Tomcat本身也是业界上非常优秀的中间件,简单可将Tomcat看成是一个Http服务器+Serv ...
- Spark-2.0.2源码编译
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6813925210731840013/ Spark官网下载地址: http://spark.apache.org/d ...
- android 5.0 (lollipop)源码编译环境搭建(Mac OS X)
硬件环境:MacBook Pro Retina, 13-inch, Late 2013 处理器 2.4 GHz Intel Core i5 内存 8 GB 1600 MHz DDR3 硬盘60G以 ...
- hadoop2.0 eclipse 源码编译
在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/archive/2013/07/05/3172889.html hadoop cdh4编 ...
- kafka 0.11.0.3 源码编译
首先下载 kafka 0.11.0.3 版本 源码: http://mirrors.hust.edu.cn/apache/kafka/0.11.0.3/ 下载源码 首先安装 gradle,不再说明 1 ...
- anroid 6.0.1_r77源码编译
一.源码下载(基本类似4.4.4_r1) 二.必须使用openjdk1.7 sudo add-apt-repository ppa:openjdk-r/ppa sudo apt-get update ...
- [odroid-pc] ubuntu12.04 64bit Android4.0.3 源码编译报错及解决的方法
第一个错误: host Executable: cmu2nuance (out/host/linux-x86/obj/EXECUTABLES/cmu2nuance_intermedia ...
随机推荐
- 数学 它的内容,方法和意义 第二卷 (A. D. 亚历山大洛夫 著)
第五章 常微分方程 1. 绪论 2. 常系数线性微分方程 3. 微分方程的解及应注意的几个方面 4. 微分方程积分问题的几何解释.问题的推广 5. 微分方程解的存在性与唯一性方程的近似解 6. 奇点 ...
- oracle-scn
在2012年第一季度的CPU补丁中,包含了一个关于SCN修正的重要变更,这个补丁提示,在异常情况下,Oracle的SCN可能出现异常增长,使得数据库的一切事务停止,由于SCN不能后退,所以数据库必须重 ...
- MySQL 有用的查询语句
查看指定数据库 db_name 的字符集和排序规则 USE db_name; SELECT @@character_set_database, @@collation_database; 显示索引信息 ...
- CF 666E Forensic Examination——广义后缀自动机+线段树合并
题目:http://codeforces.com/contest/666/problem/E 对模式串建广义后缀自动机,询问的时候把询问子串对应到广义后缀自动机的节点上,就处理了“区间”询问. 还要处 ...
- java 泛型与通配符(?)
泛型应用于泛型类或泛型方法的声明. 如类GenericTest public class GenericTest<T> { private T item; public void set( ...
- JS 判断IE(转)
一.: 之前,js判断的方式都是利用浏览器的useragent字段.通过判断useragent字段里面是否包含有MSIE字段来判断是否是IE系列浏览器,屡试不爽. 但是在IE11之后,微软把自家的IE ...
- PostgreSQL的下载安装
下载地址:http://www.postgres.cn/download 下载地址:http://www.filehorse.com/download-postgresql-64/ 下载地址2:htt ...
- 字符串CRC校验
字符串CRC校验 <pre name="code" class="python"><span style="font-family: ...
- influxDB硬件配置指南
原地址:https://docs.influxdata.com/influxdb/v1.6/guides/hardware_sizing/ 警告!此页面记录了不再积极开发的InfluxDB的早期版本. ...
- Winfrom Chart实现数据统计
简介 Chart图标根据实际使用情况,部分图表适用于多组数据的数据分析统计功能,例如柱状图:部分图表适用于单组数据的数据分析统计,例如饼状图. 主要属性 注意使用: Chart图表的如下属性:Lege ...