web scraper无法解决爬虫问题?通通可以交给python!
今天一位粉丝的需求所涉及的问题值得和大家分享分享~~~
背景问题
是这样的,他看了公号里的关于web scraper的系列文章后,希望用它来爬取一个网站搜索关键词后的文章标题和链接,如下图

按照教程,复制网页地址、写选择器、运行调试,发现无论怎样修改都无法提取到任何的信息。
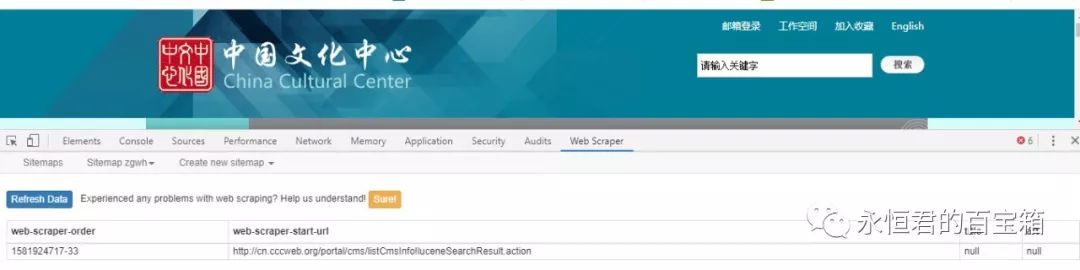
问题分析
这个网站网址是:
http://cn.cccweb.org/portal/cms/listCmsInfo!luceneSearchResult.action
通过观察发现一些特征:
1、无论你点击那一页,这个网址都是一样的。
2、当你把这个网址复制到新的标签页里打开是,发现是空白的内容。

也就意味着这个网址搜索的时候提交的关键词等参数不会在地址栏当中显示,通过burp抓包也证实了我的猜测,是post请求。

那这样的话,web scraper是无法处理、爬取这类网址不变的页面。
那就没法爬了吗?
No!!!这不是还有万能的python啊

问题解决
简单上手的话,就用python+selenium库来搞定好了。。之前也写过文章介绍过:python实现浏览器自动化操作
selenium是一个用来自动化测试的庞大家族。

python中的selenium库可以简单理解为借助计算机来模拟人工的一些操作,借助这个我们可以实现让浏览器模拟我们人类,打开浏览器和网址,搜索关键词,提取并保存数据。
基本用法如下:
from selenium import webdriverbrowser = webdriver.Chrome()browser.get('http://www.baidu.com/')#打开百度print(browser.title)#打印标题browser.quit() #退出
以及
browser.find_element_by_id("searchContents").click()#点击搜索栏browser.find_element_by_id("searchContents").send_keys("法国")#输入法国browser.find_element_by_name("submit1").click()#点击搜索browser.find_element_by_link_text("下一页>>").click()#点击下一页
使用效果如下:

最后保存的数据文件效果如下:

小结一下
1、web scraper爬虫工具小巧简单方便,但是功能有限,遇到像上面这种网址不变的情况,就不适用了。
2、python的selenium库,模拟操作浏览器、鼠标、键盘等爬取数据,简单直观。
3、爬虫入门python最适合不过了。
你可能还会想看:
欢迎交流!
web scraper无法解决爬虫问题?通通可以交给python!的更多相关文章
- web scraper插件爬虫进阶(能满足非技术人员的爬虫需求,建议收藏!!!!)
为了照顾更多的小伙伴,大家的学习能力及了解程度都不同,因此大家可以通过以下目录来有选择性的学习,节约大家的时间. 备注: 一定要实操!!! 一定要实操!!! ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
- 使用 Chrome 浏览器插件 Web Scraper 10分钟轻松实现网页数据的爬取
web scraper 下载:Web-Scraper_v0.2.0.10 使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬 ...
- 简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫
这是简易数据分析系列的第 6 篇文章. 上两期我们学习了如何通过 Web Scraper 批量抓取豆瓣电影 TOP250 的数据,内容都太干了,今天我们说些轻松的,讲讲 Web Scraper 如何导 ...
- 不写代码也能爬虫Web Scraper
https://www.jianshu.com/p/d0a730464e0c web scraper中文网 http://www.iwebscraper.com/category/%E6%95%99% ...
- web scraper 抓取分页数据和二级页面内容
如果是刚接触 web scraper 的,可以看第一篇文章. web scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据. ...
- Web Scraper 翻页——控制链接批量抓取数据
 这是简易数据分析系列的第 5 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
随机推荐
- 永久关闭windows更新步骤
在搜索“web和windows”框中输入“服务” 在搜索结果中点击第一个,那个图标像齿轮的那个!如下图. 在打开的“服务”窗口中,我们找到windows update 找到”windows upd ...
- python 比较常见的工具方法
下面是一些工作过程中比较常见的工具方法,但不代表最终答案.希望能对你有所帮助,如果您有更好更多的方法工具,欢迎推荐! 1. 按行读取带json字符串的文件 # -*- coding:utf-8 -*- ...
- [Python基础]006.IO操作
IO操作 输入输出 print raw_input input 文件 打开文件 关闭文件 读文件 写文件 文件指针 实例 输入输出 输入输出方法都是Python的内建函数,并且不需要导入任何的包就可以 ...
- nacos 配置
具体请访问 https://nacos.io/zh-cn/docs/what-is-nacos.html 网站查看文档,现在开始使用Nacos. 1. 下载Nacos源码 Nacos可以通过 http ...
- Rocket - util - HeterogeneousBag
https://mp.weixin.qq.com/s/5hNM4yeQjaLvAJzgMG9PGQ 介绍HeterogeneousBag的实现. 1. 基本介绍 一个口袋(bag ...
- Splay代码简化版
皆さん.こんにちは.上一篇文章,我们讲了Splay如何实现.这一篇我们来让我们的伸展树短一点. 上一篇Splay讲解的链接:リンク. 首先还是变量的定义,在这里呢,我把一些小函数也用Define来实现 ...
- Spring Cloud Ribbon 客户端负载均衡
Ribbon客户端组件提供一系列完善的配置选项,比如连接超时.重试.重试算法等,内置可插拔.可定制的负载均衡组件.下面是用到的一些负载均衡策略: 简单轮询负载均衡 加权轮询负载均衡 区域感知轮询负载均 ...
- Java实现 蓝桥杯VIP 算法训练 JAM计数法
题目描述 Jam是个喜欢标新立异的科学怪人.他不使用阿拉伯数字计数,而是使用小 写英文字母计数,他觉得这样做,会使世界更加丰富多彩.在他的计数法中,每个数字的位数都是相同的(使用相同个数的字母),英文 ...
- Java实现 蓝桥杯算法提高 求最大值
算法提高 求最大值 时间限制:1.0s 内存限制:256.0MB 问题描述 给n个有序整数对ai bi,你需要选择一些整数对 使得所有你选定的数的ai+bi的和最大.并且要求你选定的数对的ai之和非负 ...
- Java实现 LeetCode 567 字符串的排列(滑动窗口,处理区间内的字符数量)
567. 字符串的排列 给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列. 换句话说,第一个字符串的排列之一是第二个字符串的子串. 示例1: 输入: s1 = " ...