使用pandas库实现csv行和列的获取
1、读取csv
import pandas as pd
df = pd.read_csv('路径/py.csv')
2、取行号
index_num = df.index
举个例子:
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8')
index_num = df.index
print(index_num)

3、取出行
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 获取行数
# index_num = df.index
# print(index_num)
# 取出某一行
# row_data_1 = df.iloc[0]
# row_data_2 = df.iloc[[0]]
# 取出连续的行
# row_data_3 = df.iloc[0:2]
# row_data_4 = df[0:2]
# 取出不连续的行
# row_data_5 = df.iloc[[0,2]]
# print(row_data_5)
只取一行
可以使用df.iloc[行号],得到的是series
也可以使用df.iloc[[行号]],得到的是dataframe
row_data_1 = df.iloc[0] # pandas series
row_data_2 = df.iloc[[0]] # dataframe
loc是显式的索引,默认第一行的行号为1,行号从1计数
iloc是隐式的索引,默认第一行的行号为0,行号从0计数
row_data_1
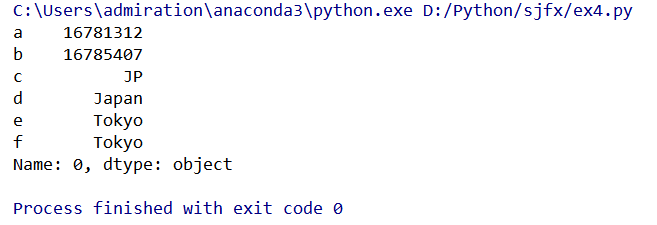
row_data_2

取连续的几行
可以用df.iloc[行号:行号],也可以用df[行号:行号],得到的都是dataframe
row_data_3 = df.iloc[0:2]
row_data_3 = df[0:2]
row_data_3

row_data_4

取出不连续的几行
使用df.iloc[[行号,行号]],特别注意是两个方括号,中间是逗号,得到的是dataframe
row_data_5 = df.iloc[[0,2]]
row_data_5

4、取出列
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 只取一列
# col_data_1 = df['a'] # 单独一列是个series
# col_data_2 = df.loc[:,'a'] # 同上,但比较复杂,一般不用
# col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
#
# col_data_4 = df[['a']] # 单独一列是个df
# col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用
# col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
# print(col_data_4)
# 获取指定的几列
# cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名
# cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用
# cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用
# print(cols_data_1)
# 获取指定的连续列
# cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名
# cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
# print(cols_data_4)
只取一列
col_data_1 = df['a']# 单独一列是个seriescol_data_2 = df.loc[:,'a']# 同上,但比较复杂,一般不用col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
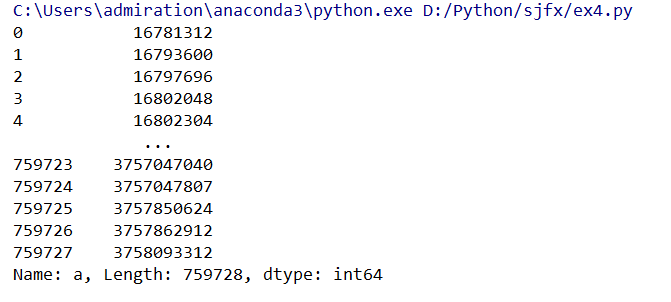
以上三种均为只取一列的操作,并且是等效的,获取的都是series类型
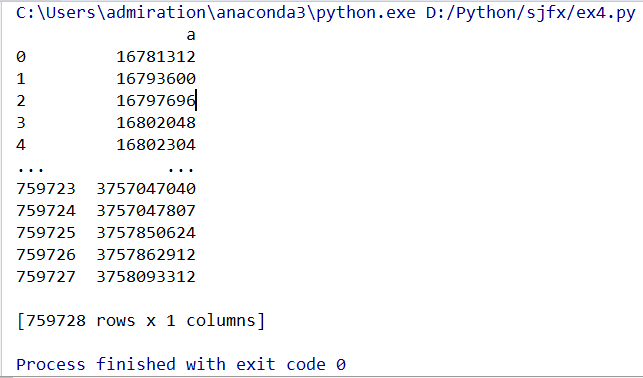
下面三种也是等效的,但是获取的是dataframe类型
col_data_4 = df[['a']] # 单独一列是个df
col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用
col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
取指定的某几列
cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名
cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用
cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用

获取指定的连续几列
cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名
cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
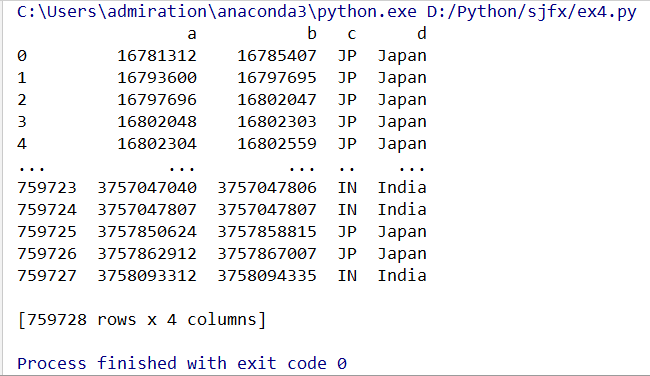
5、取指定行和列
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 获取指定行列
# 第一种,列索引用数字表示
# data_1 = df.iloc[[1,3],[0]]
# data_2 = df.iloc[[1,3],0]
# data_3 = df.iloc[[1,3],1:3]
# data_4 = df.iloc[[1,3],[1,3]]
# print(data_4)
# 第二种,列索引直接引用列名
# data_5 = df.loc[1,['a','d']]
# data_6 = df.loc[[1],['a','d']]
# data_7 = df.loc[[1,3],'a':'d']
# data_8 = df.loc[[1,3],['a','d']]
# print(data_8)
列索引用数字表示
第一种情况是列索引用数字表示, df.iloc[行索引表达,列索引表达],规则跟上面行索引一模一样。
data_1 = df.iloc[[1,3],[0]]

data_2 = df.iloc[[1,3],0] # series
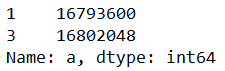
data_3 = df.iloc[[1,3],1:3]

data_4 = df.iloc[[1,3],[1,3]]
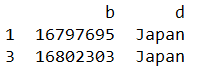
列索引直接引列名
第二种情况是列索引直接引列名(行索引不存在这个问题,因为pandas没有所谓'行名'),就要用df.loc[行索引,列名索引。
data_5 = df.loc[1,['a','d']] # series

data_6 = df.loc[[1],['a','d']]
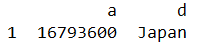
data_7 = df.loc[[1,3],'a':'d']

data_8 = df.loc[[1,3],['a','d']]

使用pandas库实现csv行和列的获取的更多相关文章
- POI教程之第二讲:创建一个时间格式的单元格,处理不同内容格式的单元格,遍历工作簿的行和列并获取单元格内容,文本提取
第二讲 1.创建一个时间格式的单元格 Workbook wb=new HSSFWorkbook(); // 定义一个新的工作簿 Sheet sheet=wb.createSheet("第一个 ...
- python的pandas库读取csv
首先建立test.csv原始数据,内容如下 时间,地点 一月,北京 二月,上海 三月,广东 四月,深圳 五月,河南 六月,郑州 七月,新密 八月,大连 九月,盘锦 十月,沈阳 十一月,武汉 十二月,南 ...
- 用pandas库对csv文件中的文本数据进行分析处理
#数据分析 import pandas import csv old_path = r'd:\2000W\200W-400W.csv' f = open(old_path,'r',encoding=' ...
- Python之文件读写(csv文件,CSV库,Pandas库)
前言 一.Python文件读取 二.读取CSV文件 一.Python文件读取 1. open函数是内置函数之with操作 - 关于路径设置的问题斜杠设置成D:\\文件夹\\文件或是D:/文件夹/文件 ...
- Python之使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识. ORM技术 对象关系映射技术,即ORM(Object-Relational ...
- python做数据分析pandas库介绍之DataFrame基本操作
怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 这一部分主要学习pandas中基于前面两种数据结构的基本操作. 设有DataF ...
- Pandas库常用函数和操作
1. DataFrame 处理缺失值 dropna() df2.dropna(axis=0, how='any', subset=[u'ToC'], inplace=True) 把在ToC列有缺失值 ...
- python pandas库——pivot使用心得
python pandas库——pivot使用心得 2017年12月14日 17:07:06 阅读数:364 最近在做基于python的数据分析工作,引用第三方数据分析库——pandas(versio ...
- 建议42:使用pandas处理大型CSV文件
# -*- coding:utf-8 -*- ''' CSV 常用API 1)reader(csvfile[, dialect='excel'][, fmtparam]),主要用于CSV 文件的读取, ...
随机推荐
- 关于小程序中textarea内的字体浮动问题
因为map.canvas.video.textarea 是由客户端创建的原生组件,原生组件的层级是最高的,所以页面中的其他组件无论设置 z-index 为多少,都无法盖在原生组件上. 原生组件暂时还无 ...
- 作业九——DFA最小化,语法分析初步
- jdbc批量插入数据
//插入很多书(批量插入用法) public void insertBooks(List<Book> book) { final List<Book> tempBook=b ...
- OOM的起点到终点
前言 1.问题及现象 线上日志反馈内存溢出问题.根据用户反馈,客户操作一段时间之后,APP 内存溢出崩溃. 2.分析过程 (1) 分析线上日志,发现主要分两种: 第一种如下,可能是某个死循环导致内存不 ...
- inotify-tools的inotifywait工具用exclude 和 fromfile 排除指定后缀文件
今天打算使用 inotify-tool 来对线上程序文件进行监控, 因为有些目录是缓存目录, 所以要进行排除, 同时还要排除一些指定的后缀的文件, 比如 .swp 等 需要递归监控的目录为: /tmp ...
- CF1288C-Two Arrays (DP)
You are given two integers n and m. Calculate the number of pairs of arrays (a,b) such that: the len ...
- 2019-2020 ICPC, Asia Jakarta Regional Contest A. Copying Homework (思维)
Danang and Darto are classmates. They are given homework to create a permutation of N integers from ...
- spring注入bean的几种策略模式
上篇文章Spring IOC的核心机制:实例化与注入我们提到在有多个实现类的情况下,spring是如何选择特定的bean将其注入到代码片段中,我们讨论了按照名称注入和使用@Qualifier 注解输入 ...
- 【MIT6.828】centos7下使用Qemu搭建xv6运行环境
title:[MIT6.828]centos7下使用Qemu搭建xv6运行环境 date: "2020-05-05" [MIT6.828]centos7下搭建xv6运行环境 1. ...
- High Card Low Card G(田忌赛马进阶!!)
传送门 \(首先一定要明确一个观点,不然会完全没有思路\) \(\bullet\)\(由于前半段大的更优,后半段小的更优.\) \(\bullet\)\(所以,\)Bessie\(一定会在前(n/2) ...