Pytest系列(9) - 参数化@pytest.mark.parametrize
如果你还想从头学起Pytest,可以看看这个系列的文章哦!
https://www.cnblogs.com/poloyy/category/1690628.html
前言
pytest允许在多个级别启用测试参数化:
- pytest.fixture() 允许fixture有参数化功能(后面讲解)
- @pytest.mark.parametrize 允许在测试函数或类中定义多组参数和fixtures
- pytest_generate_tests 允许定义自定义参数化方案或扩展(拓展)
参数化场景
只有测试数据和期望结果不一样,但操作步骤是一样的测试用例可以用上参数化;
可以看看下面的栗子
未参数化的代码
def test_1():
assert 3 + 5 == 9 def test_2():
assert 2 + 4 == 6 def test_3():
assert 6 * 9 == 42
可以看到,三个用例都是加法然后断言某个值,重复写三个类似的用例有点冗余
利用参数化优化之后的代码
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+4", 6), ("6*9", 42)])
def test_eval(test_input, expected):
print(f"测试数据{test_input},期望结果{expected}")
assert eval(test_input) == expected
执行结果
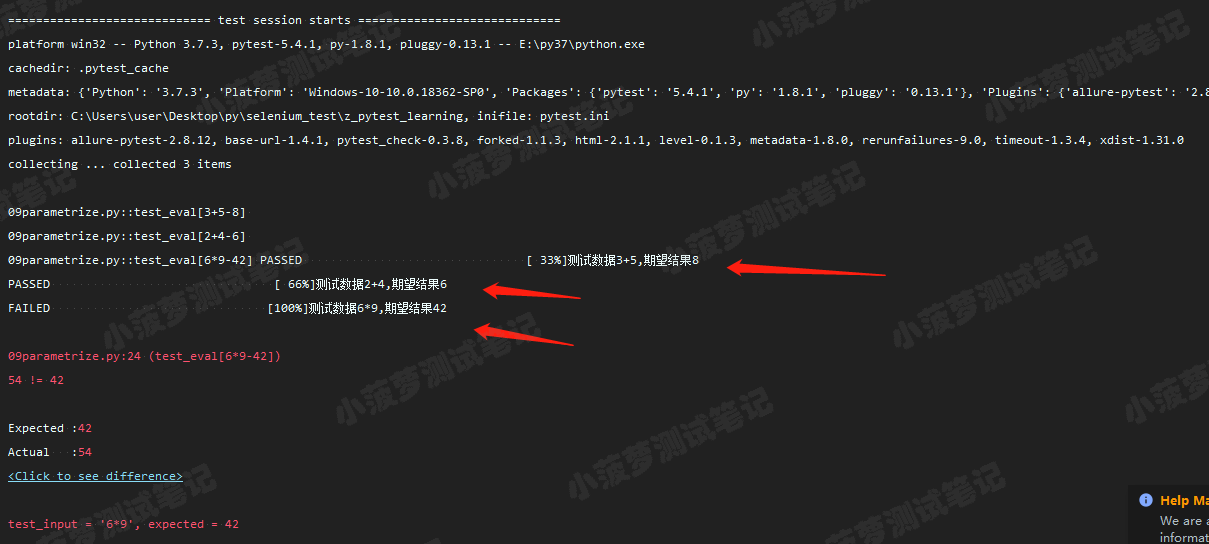
可以看到,只有一条用例,但是利用参数化输入三组不同的测试数据和期望结果,最终执行的测试用例数=3,可以节省很多代码
实际Web UI自动化中的开发场景,比如是一个登录框
- 你肯定需要测试账号空、密码空、账号密码都为空、账号不存在、密码错误、账号密码正确等情况
- 这些用例的区别就在于输入的测试数据和对应的交互结果
- 所以我们可以只写一条登录测试用例,然后把多组测试数据和期望结果参数化,节省很多代码量
源码分析
def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
argnames
源码解析:a comma-separated string denoting one or more argument names, or a list/tuple of argument strings.
含义:参数名字
格式:字符串"arg1,arg2,arg3"【需要用逗号分隔】
备注:源码中写了可以是参数字符串的list或者tuple,但博主实操过是不行的,不知道是不是写的有问题,大家可以看看评论下
示例
@pytest.mark.parametrize(["name", "pwd"], [("yy1", ""), ("yy2", "")]) # 错的
@pytest.mark.parametrize(("name", "pwd"), [("yy1", ""), ("yy2", "")]) # 错的
@pytest.mark.parametrize("name,pwd", [("yy1", ""), ("yy2", "")])
argvalues
源码解析:
- The list of argvalues determines how often a test is invoked with different argument values.
- If only one argname was specified argvalues is a list of values.【只有一个参数,则是值列表】
- If N argnames were specified, argvalues must be a list of N-tuples, where each tuple-element specifies a value for its respective argname.【如果有多个参数,则用元组来存每一组值】
含义:参数值列表
格式:必须是列表,如:[ val1,val2,val3 ]
如果只有一个参数,里面则是值的列表如:@pytest.mark.parametrize("username", ["yy", "yy2", "yy3"])
如果有多个参数例,则需要用元组来存放值,一个元组对应一组参数的值,如:@pytest.mark.parametrize("name,pwd", [("yy1", "123"), ("yy2", "123"), ("yy3", "123")])
备注:虽然源码说需要list包含tuple,但我试了下,tuple包含list,list包含list也是可以的........
ids
含义:用例的ID
格式:传一个字符串列表
作用:可以标识每一个测试用例,自定义测试数据结果的显示,为了增加可读性
强调:ids的长度需要与测试数据列表的长度一致
indirect
作用:如果设置成True,则把传进来的参数当函数执行,而不是一个参数(下一篇博文即讲解)
讲完源码,对方法有更深入的了解了,我们就讲讲常用的场景
装饰测试类
@pytest.mark.parametrize('a, b, expect', data_1)
class TestParametrize:
def test_parametrize_1(self, a, b, expect):
print('\n测试函数11111 测试数据为\n{}-{}'.format(a, b))
assert a + b == expect
def test_parametrize_2(self, a, b, expect):
print('\n测试函数22222 测试数据为\n{}-{}'.format(a, b))
assert a + b == expect
执行结果
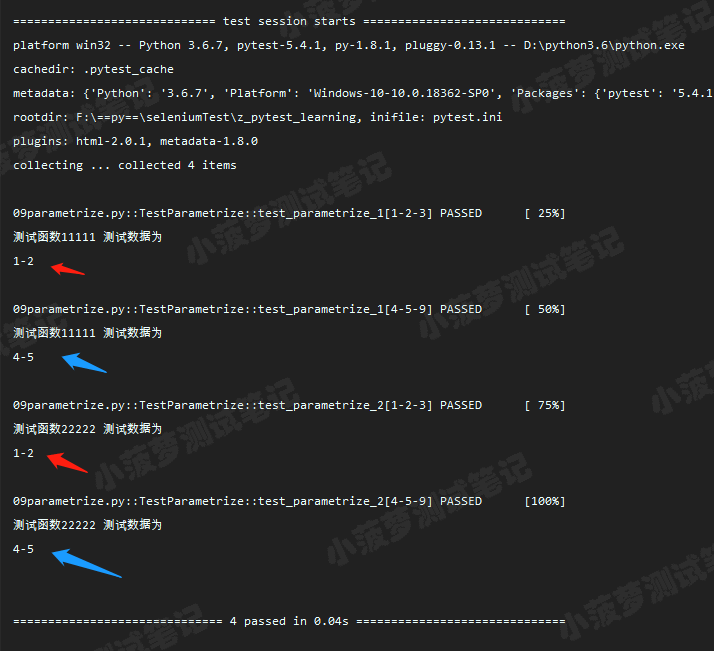
重点
当装饰器 @pytest.mark.parametrize 装饰测试类时,会将数据集合传递给类的所有测试用例方法
“笛卡尔积”,多个参数化装饰器
# 笛卡尔积,组合数据
data_1 = [1, 2, 3]
data_2 = ['a', 'b'] @pytest.mark.parametrize('a', data_1)
@pytest.mark.parametrize('b', data_2)
def test_parametrize_1(a, b):
print(f'笛卡尔积 测试数据为 : {a},{b}')
执行结果
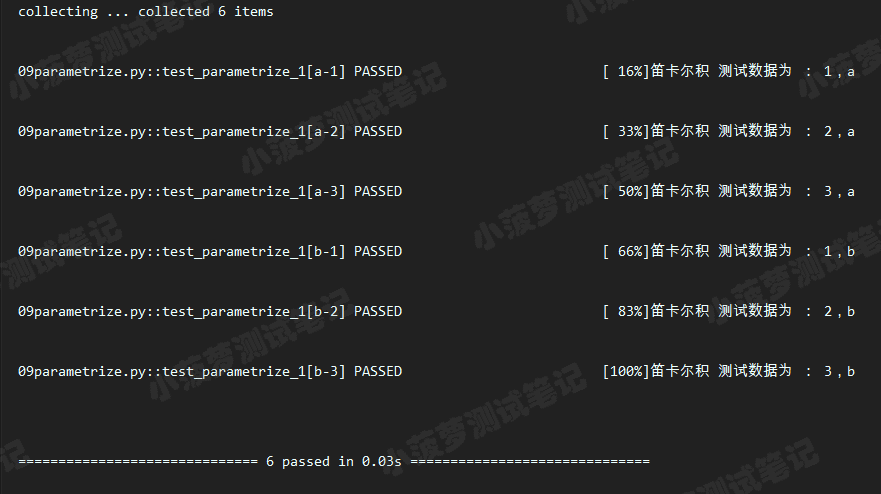
重点知识
- 一个函数或一个类可以装饰多个 @pytest.mark.parametrize
- 这种方式,最终生成的用例数是n*m,比如上面的代码就是:参数a的数据有3个,参数b的数据有2个,所以最终的用例数有3*2=6条
- 当参数化装饰器有很多个的时候,用例数都等于n*n*n*n*....
参数化 ,传入字典数据
# 字典
data_1 = (
{
'user': 1,
'pwd': 2
},
{
'user': 3,
'pwd': 4
}
) @pytest.mark.parametrize('dic', data_1)
def test_parametrize_1(dic):
print(f'测试数据为\n{dic}')
print(f'user:{dic["user"]},pwd{dic["pwd"]}')
没啥特别的,只是数据类型是常见的dict而已
执行结果
09parametrize.py::test_parametrize_1[dic0] PASSED [ 50%]测试数据为
{'user': 1, 'pwd': 2}
user:1,pwd2 09parametrize.py::test_parametrize_1[dic1] PASSED [100%]测试数据为
{'user': 3, 'pwd': 4}
user:3,pwd4
参数化,标记数据
# 标记参数化
@pytest.mark.parametrize("test_input,expected", [
("3+5", 8),
("2+4", 6),
pytest.param("6 * 9", 42, marks=pytest.mark.xfail),
pytest.param("6*6", 42, marks=pytest.mark.skip)
])
def test_mark(test_input, expected):
assert eval(test_input) == expected
执行结果
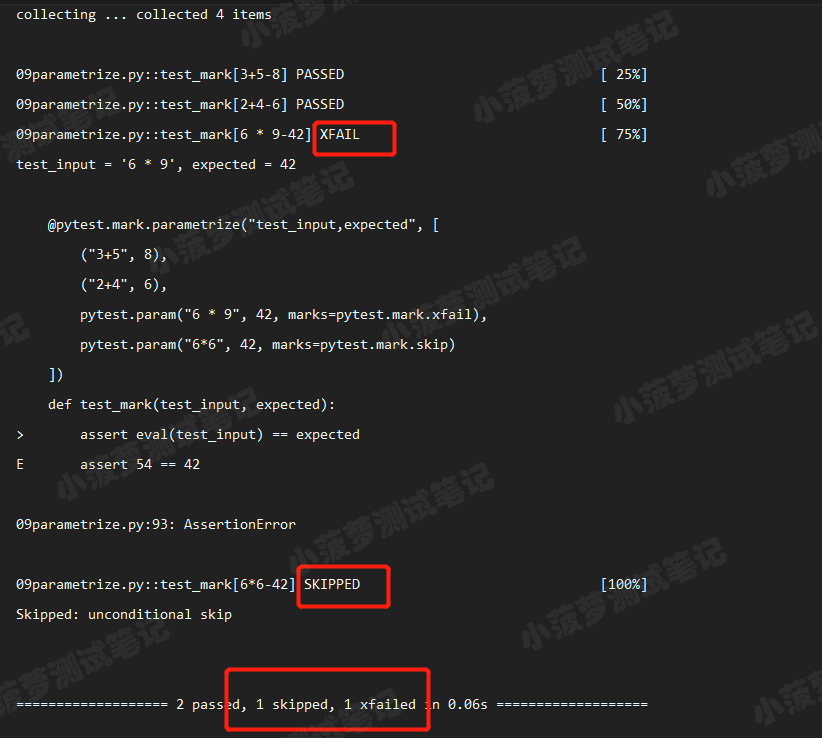
参数化,增加可读性
# 增加可读性
data_1 = [
(1, 2, 3),
(4, 5, 9)
] # ids
ids = ["a:{} + b:{} = expect:{}".format(a, b, expect) for a, b, expect in data_1] @pytest.mark.parametrize('a, b, expect', data_1, ids=ids)
class TestParametrize(object): def test_parametrize_1(self, a, b, expect):
print('测试函数1测试数据为{}-{}'.format(a, b))
assert a + b == expect def test_parametrize_2(self, a, b, expect):
print('测试函数2数据为{}-{}'.format(a, b))
assert a + b == expect
执行结果
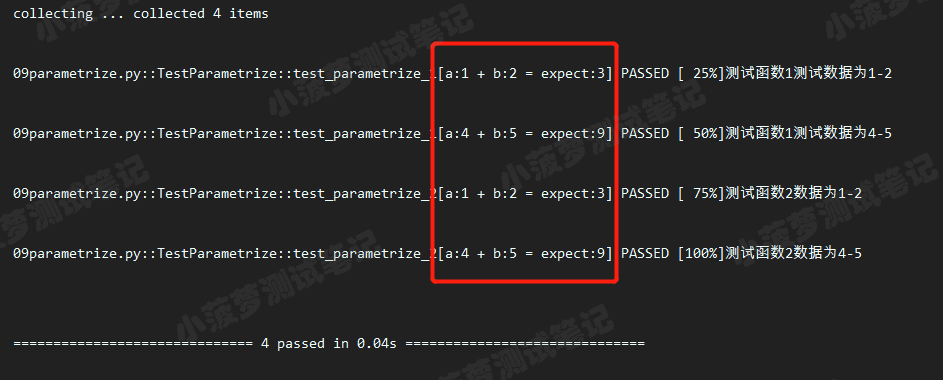
知识点
多少组数据,就要有多少个id,然后组成一个id的列表
作用:主要是为了更加清晰看到用例的含义
Pytest系列(9) - 参数化@pytest.mark.parametrize的更多相关文章
- Pytest 系列(28)- 参数化 parametrize + @allure.title() 动态生成标题
如果你还想从头学起Pytest,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1690628.html 前言 参数化 @pytest.ma ...
- pytest自动化6:pytest.mark.parametrize装饰器--测试用例参数化
前言:pytest.mark.parametrize装饰器可以实现测试用例参数化. parametrizing 1. 下面是一个简单是实例,检查一定的输入和期望输出测试功能的典型例子 2. 标记单 ...
- pytest.mark.parametrize()参数化应用二,读取json文件
class TestEnorll(): def get_data(self): """ 读取json文件 :return: """ data ...
- pytest.mark.parametrize()参数化的应用一
from page.LoginPage import Loginpage import os, sys, pytest base_dir = os.path.dirname(os.path.dirna ...
- pytest系列(二):筛选用例新姿势,mark 一下,你就知道。
pytest系列(一)中给大家介绍了pytest的特性,以及它的编写用例的简单至极. 那么在实际工作当中呢,我们要写的自动化用例会比较多,不会都放在一个py文件里. 如下图所示,我们编写的用例存放在不 ...
- 5.@pytest.mark.parametrize()数据驱动
简介: pytest.mark.parametrize 是 pytest 的内置装饰器,它允许你在 function 或者 class 上定义多组参数和 fixture 来实现数据驱动. @pytes ...
- pytest文档9-参数化parametrize
前言 pytest.mark.parametrize装饰器可以实现测试用例参数化. parametrizing 1.这里是一个实现检查一定的输入和期望输出测试功能的典型例子 # content of ...
- Pytest进阶之参数化
前言 unittest单元测试框架使用DDT进行数据驱动测试,那么身为功能更加强大且更加灵活的Pytest框架怎么可能没有数据驱动的概念呢?其实Pytest是使用@pytest.mark.parame ...
- 11、pytest -- 测试的参数化
目录 1. @pytest.mark.parametrize标记 1.1. empty_parameter_set_mark选项 1.2. 多个标记组合 1.3. 标记测试模块 2. pytest_g ...
随机推荐
- 大数据学习之scala-环境搭建
scala 下载网站 https://www.scala-lang.org/download/ 安装scala要先安装java,并且配置java环境,官网也有说明 不过国内的网站下载不下来可以访问: ...
- LeetCode#15 | Three Sum 三数之和
一.题目 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组. 注意:答案中不可以包含 ...
- 前端工程师眼中的Docker
笔者最近在整理 Node.js 操作各数据库的方法,却不料遇到一个很棘手的问题:很多数据库,都需要同时下载 Server 端和 Client 端,并进行相应的配置,着实是麻烦.那有没有方法可以省去这些 ...
- Java 创建、编辑、删除Excel命名区域
Excel命名区域,即对指定单元格区域进行命名,以便对单元格区域引用,如在公式运用中可以引用指定命名区域进行公式操作.在创建命名区域时,可针对整个工作簿来创建,即workbook.getNameRan ...
- OPENGL图形渲染管线图解
OPENGL固定图形渲染管线可以粗略地认为由下面的阶段衔接而成: 顶点颜色,光照,材质三个输入在光栅化前控制绘制管线的操作.光照和材质不能单独使用.顶点颜色,光源颜色,材质颜色都有alpha值,它们的 ...
- 【Weiss】【第03章】练习3.11:比较单链表递归与非递归查找元素
[练习3.11] 编写查找一个单链表特定元素的程序.分别用递归和非递归实现,并比较它们的运行时间. 链表必须达到多大才能使得使用递归的程序崩溃? Answer: 实现都是比较容易的,但是实际上查找链表 ...
- 将SublimeText加入右键菜单
将SublimeText加入右键菜单 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\*\shell\SublimeText] @=&q ...
- 欢乐水杯(happy glass)中流体的一种实现!图文视频讲解 ! Cocos Creator!
使用cocos creator v2.2.2 实现流体效果 ! 图文+视频讲解! 效果预览 实现原理 整体思路是参考论坛中的一个帖子 这款游戏中水的粘连效果在Construct3中利用图层很容易实现, ...
- 从ISTIO熔断说起-轻舟网关熔断
最近大家经常被熔断洗脑,股市的动荡,让熔断再次出现在大家眼前.微服务中的熔断即服务提供方在一定时间内,因为访问压力太大或依赖异常等原因,而出现异常返回或慢响应,熔断即停止该服务的访问,防止发生雪崩效应 ...
- python win32com
要使用Python控制MS Word,您需要先安裝win32com套件,這個套件可以到 http://sourceforge.net/projects/pywin32/ 找到.本文假設您已經正確安裝w ...