SQL基础教程(第2版)第8章 SQL高级处理:8-2 GROUPING运算符
第8章 SQL高级处理:8-2 GROUPING运算符
■ GROUPING SETS——取得期望的积木
● 只使用GROUP BY子句和聚合函数是无法同时得出小计和合计的。如果想要同时得到,可以使用GROUPING运算符。
● 理解GROUPING运算符中CUBE的关键在于形成“积木搭建出的立方体”的印象。
■同时计算出合计行

如果想要获得那样的结果,通常的做法是分别计算出合计行和按照商品种类进行汇总的结果,然后通过 UNION ALL 连接在一起。
代码清单8-11 分别计算出合计行和汇总结果再通过UNION ALL进行连接
SELECT '合计' AS product_type, SUM(sale_price)
FROM Product
UNION ALL
SELECT product_type, SUM(sale_price)
FROM Product
GROUP BY product_type;
这样一来,为了得到想要的结果,需要执行两次几乎相同的 SELECT语句,再将其结果进行连接,不但看上去十分繁琐,而且 DBMS 内部的处理成本也非常高。
GROUPING 运算符包含以下 3 种。
●ROLLUP
●CUBE
●GROUPING SETS
■ ROLLUP——同时得出合计和小计
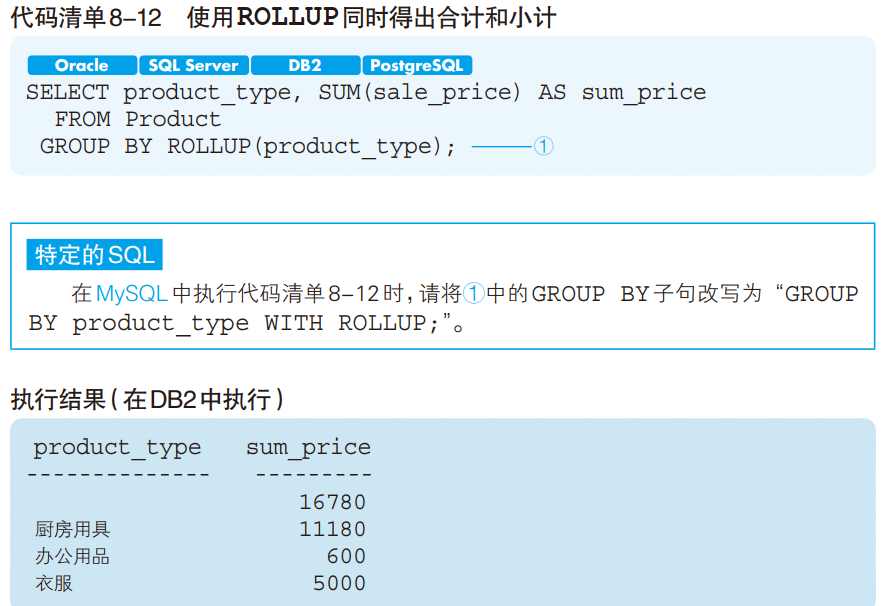
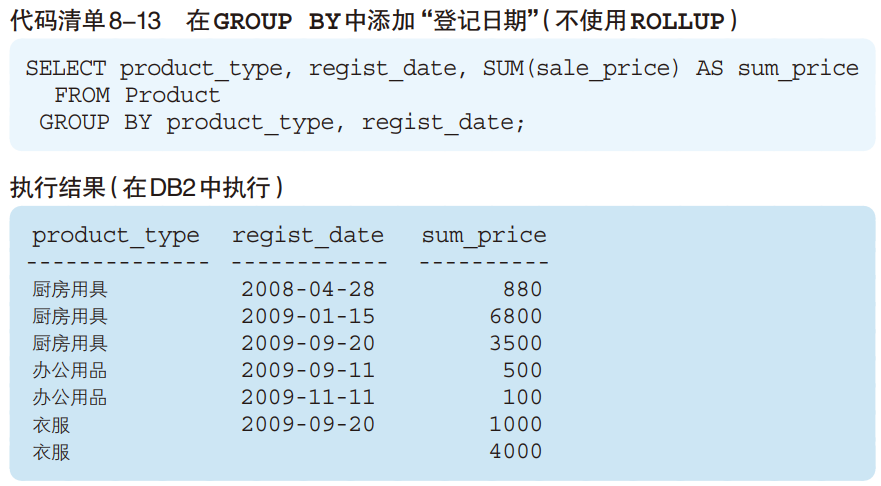
■将“登记日期”添加到聚合键当中
--Oracle, SQL Server, DB2
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
--Oracle, SQL Server, DB2
在上述 GROUP BY 子句中使用 ROLLUP 之后,结果会发生什么变化呢(代码清单 8-14) ?
--MySQL
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY product_type, regist_date WITH ROLLUP;
这 4 行就是我们所说的超级分组记录。也就是说,该SELECT 语句的结果相当于使用 UNION 对如下 3 种模式的聚合级的不同结果进行连接(图 8-5)。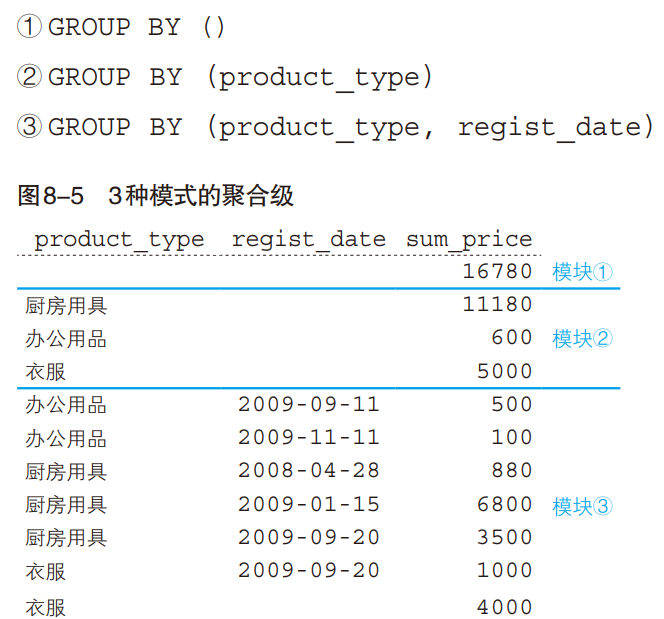
ROLLUP 是“卷起”的意思,可以同时得出合计和小计,是非常方便的工具。
■ GROUPING函数——让NULL更加容易分辨
为了避免混淆, SQL 提供了一个用来判断超级分组记录的 NULL 的
特定函数 —— GROUPING 函数。该函数在其参数列的值为超级分组记录
所产生的 NULL 时返回 1,其他情况返回 0(代码清单 8-15)。
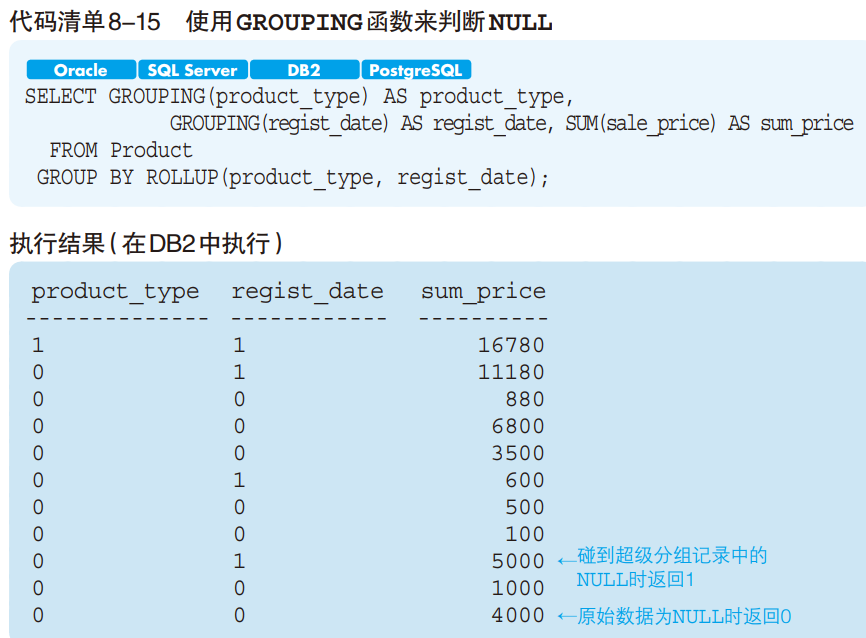
这样就能分辨超级分组记录中的 NULL 和原始数据本身的 NULL 了。
使用 GROUPING 函数还能在超级分组记录的键值中插入字符串。也就是说,
当 GROUPING 函数的返回值为 1 时,指定“合计”或者“小计”等字符串,其他情况返回通常的列的值。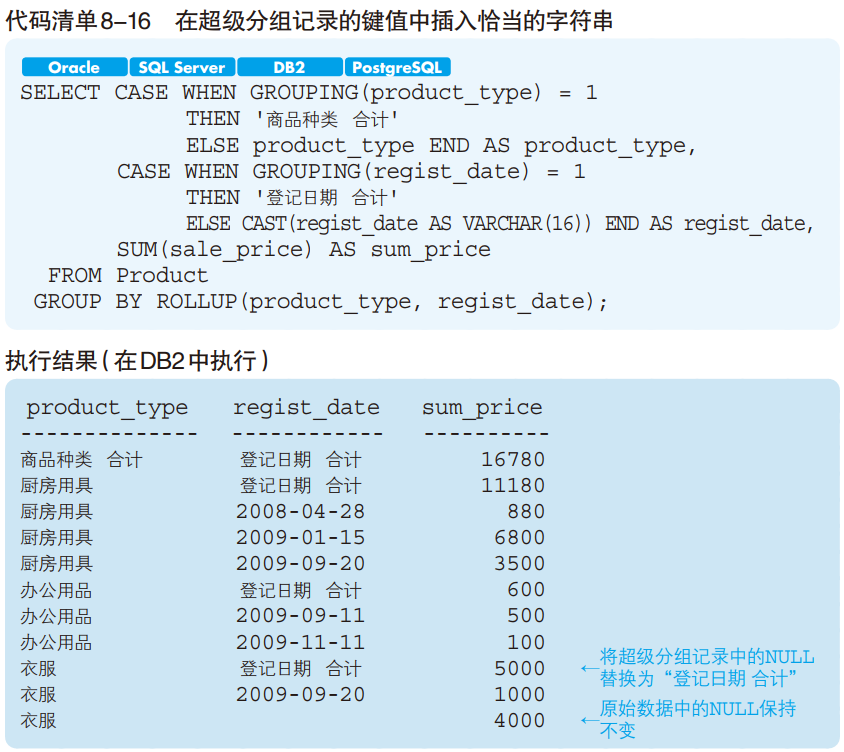
■ CUBE——用数据来搭积木
CUBE 是“立方体”的意思,这个名字和 ROLLUP 一样,都能形象地说明函数的动作。
CUBE 的语法和 ROLLUP 相同,只需要将 ROLLUP 替换为 CUBE 就可以了。

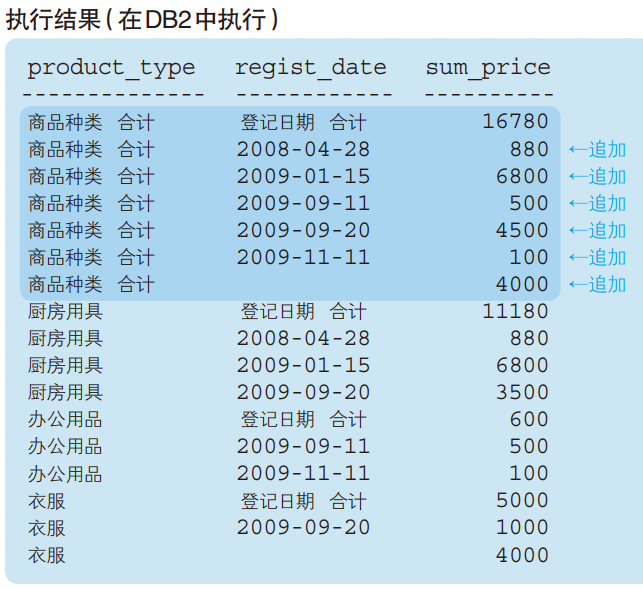
与 ROLLUP 的结果相比, CUBE 的结果中多出了几行记录。大家看一下应该就明白了,多出来的记录就是只把 regist_date 作为聚合键所得到的汇总结果。

顺带说一下, ROLLUP的结果一定包含在CUBE的结果之中。
所谓 CUBE,就是将 GROUP BY 子句中聚合键的“所有可能的组合”的汇总结果集中到一个结果中。
因此,组合的个数就是 2^n(n 是聚合键的个数)。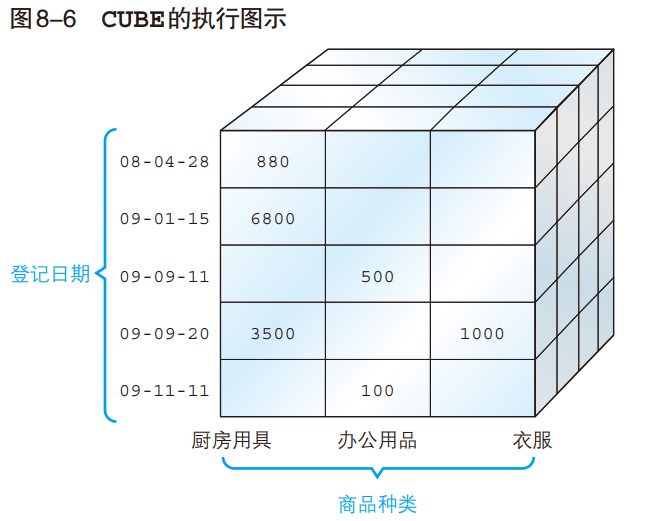
SQL基础教程(第2版)第8章 SQL高级处理:8-2 GROUPING运算符的更多相关文章
- 推荐《SQL基础教程(第2版)》中文PDF+源代码+习题答案
我认为<SQL基础教程(第2版)>非常适合数据库学习的初学者.论述的角度是读者的角度,会换位思考到读者在看到这一段时候会发出怎样的疑问,非常难得:原始数据的例题只有一道,但是可以反复从不同 ...
- 笔记-Python基础教程(第二版)第一章
第一章 快速改造:基础知识 01:整除.乘方 (Python3.0之前 如2.7版本) >>> 1/2 ==>0 1/2整除,普通除法: 解决办法1: 1.0/2.0 ==& ...
- [SQL基础教程] 5-1视图
[SQL基础教程] 5-1视图 视图和表 从SQL角度看视图就是一张表 视图与表的差别 表保存了实际的数据,视图保存的是SELECT语句: 视图的优点 节省存储空间: 将常用的Select 语句保存成 ...
- SQL Server2012 T-SQL基础教程--读书笔记(8 - 10章)
SQL Server2012 T-SQL基础教程--读书笔记(8 - 10章) 示例数据库:点我 CHAPTER 08 数据修改 8.1 插入数据 8.1.1 INSERT VALUES 语句 8.1 ...
- [SQL基础教程] 4-4 事务
[SQL基础教程] 4 数据更新 4-4 事务 事务 需要在同一处理单元中执行的一系列更新处理的集合 创建事务 事务开始语句; DML语句1; DML语句2; . . . 事务结束语句; 事务开始语句 ...
- [SQL基础教程] 4-3 数据的更新(UPDATE)
[SQL基础教程] C4 数据更新 4-3 数据的更新(UPDATE) UPDATE UPDATE <表名> SET <列名> = <表达式>; UPDATE &l ...
- [SQL基础教程] 4-2 数据删除(DELETE)
[SQL基础教程] C4 数据更新 4-2 数据删除(DELETE) DROP TABLE / DELETE DROP TABLE - 完全删除表 DELETE - 仅删除数据,保留表容器 DELET ...
- [SQL基础教程] 4-1 数据的插入(INSERT)
[SQL基础教程] C4 数据更新 4-1 数据的插入(INSERT) INSERT INSERT INTO <表名>(列1,列2...) VALUES(值1,值2...); 清单 用() ...
- [SQL基础教程] 3-4 对查询结果进行排序/ORDER BY
[SQL基础教程] 3-4 对查询结果进行排序/ORDER BY ORDER BY SELECT <列名1>,<列名2>,<列名2>... FROM ORDER B ...
随机推荐
- 前端性能优化----reflow(回流)和repaint(重绘)
什么是reflow和repaint(原文链接:http://www.cnblogs.com/Peng2014/p/4687218.html) reflow:例如某个子元素样式发生改变,直接影响到了其父 ...
- 使用conda创建虚拟环境
conda创建python虚拟环境 前言 conda常用的命令: conda list 查看安装了哪些包. conda env list 或 conda info -e 查看当前存在哪些虚拟环境 co ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
- python三大神器===》生成器
1. 认识生成器 利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成.但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一 ...
- Robot set variable if
${strid} Set Variable If '${row}' =='2' LFFD_TANK_RAMP ... '${row}' =='3' LFFD_TANK_LANDING
- 【pwnable.kr】cmd1
最近的pwnable都是linux操作系统层面的. ssh cmd1@pwnable.kr -p2222 (pw:guest) 首先还是下载源代码: #include <stdio.h> ...
- [LeetCode] 931. Minimum Falling Path Sum 下降路径最小和
Given a square array of integers A, we want the minimum sum of a falling path through A. A falling p ...
- 75.Python中ORM聚合函数详解:Sum
Sum:某个字段的总和. 1. 求图书的销售总额,示例代码如下: from django.http import HttpResponse from django.db import connecti ...
- pandas中na_values与keep_default_na
我们在使用pandas读取文件时,常会遇到某个字段为NaN. 一般情况下,这时因为文件中包含空值导致的,因为pandas默认会将 '-1.#IND', '1.#QNAN', '1.#IND', '-1 ...
- 020-PHP浏览目录
<?php // 使用表格浏览目录的结构 print("<TABLE BORDER= '1'>"); // 创建表格的头 print("<TR&g ...