mongodb_2
一、游标
在mongodb中,底层使用js引擎进行各种操作,所以我们在命令行窗口,可直接执行js代码。
#使用for循环,插入1000条数据。
> for (var i=0;i<1000;i++){ db.test.insertOne({_id:i,name:"erha"+i})}
{ "acknowledged" : true, "insertedId" : 999 }
> db.test.find()
#查询结果如下
{ "_id" : 0, "name" : "erha0" }
{ "_id" : 1, "name" : "erha1" }
{ "_id" : 2, "name" : "erha2" }
{ "_id" : 3, "name" : "erha3" }
{ "_id" : 4, "name" : "erha4" }
{ "_id" : 5, "name" : "erha5" }
{ "_id" : 6, "name" : "erha6" }
{ "_id" : 7, "name" : "erha7" }
{ "_id" : 8, "name" : "erha8" }
{ "_id" : 9, "name" : "erha9" }
我们使用find()方法查询时,他会将所有的数据都查询出来给我们,但是当数据量特别大的时候,这种操作并不是很好。我们希望就像python中生成器那样,我们需要数据,调用某些方法,就给我们返回数据。其实在MongoDB中也有类似生成器对象的东西,在mongo中叫做游标。
1.1、游标操作
我们将查询的结果,赋值给一个变量,则该变量就是一个游标。
> var con= db.test.find()
> con.next() #取出该游标下一个元素。
{ "_id" : 0, "name" : "erha0" }
> con.hasNext() #判断该游标是否有下一个元素。
true
#还可以进行循环打印
> while(mycusor.hasNext()){
... printjson(mycusor.next())
... }
{ "_id" : 0, "name" : "erha0" }
{ "_id" : 1, "name" : "erha1" }
{ "_id" : 2, "name" : "erha2" }
{ "_id" : 3, "name" : "erha3" }
{ "_id" : 4, "name" : "erha4" }
{ "_id" : 5, "name" : "erha5" }
{ "_id" : 6, "name" : "erha6" }
{ "_id" : 7, "name" : "erha7" }
{ "_id" : 8, "name" : "erha8" }
{ "_id" : 9, "name" : "erha9" }
#可将所有元素取出到一个数组内
> var mycusor = db.test.find().limit(2)
> mycusor.toArray()
[
{
"_id" : 0,
"name" : "erha0"
},
{
"_id" : 1,
"name" : "erha1"
}
]
1.2、forEach(回调函数)
> var mycusor = db.test.find().limit(10)
> var get_name=function(obj){ #定义一个函数,打印每个元素的name属性。
... print(obj.name)}
> mycusor.forEach(get_name)
erha0
erha1
erha2
erha3
erha4
erha5
erha6
erha7
erha8
erha9
1.3、游标在分页中的使用
#每页5个。
> var mycusor = db.test.find().skip(0).limit(5)
> var mycusor = db.test.find().skip(5).limit(5)
#总结如下
m:页码
n:每页元素
> var mycusor = db.test.find().skip((m-1)*n).limit(n)
> mycusor.toArray()
二、索引
- 索引提高查询速度,降低写入速度,一般在常用的查询字段建立索引。
- 在mongodb中,索引可以按字段升序/降序来创建,便于排序。
- 默认是用btree来组织索引文件,2.4版本以后,也允许建立hash索引。
2.1、常用命令
(1)查看当前索引状态:db.collection.getIndexes()
> db.test.getIndexes()
[
{
"v" : 2, #版本
"key" : {
"_id" : 1 #排序方式
},
"name" : "_id_", #索引名
"ns" : "test.test" #数据库.表
}
]
(2)创建普通单列索引:db.collection.ensureIndex({field:1/-1})//1为正序,-1为逆序
> db.test.ensureIndex({name:-1})
> db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.test"
},
{
"v" : 2,
"key" : {
"name" : -1
},
"name" : "name_-1",
"ns" : "test.test"
}
]
(3)删除单个索引:db.collection.dropIndex({field:1/-1})
> db.test.dropIndex({name:-1}) #这里的-1,跟设置时的保持一致。
{ "nIndexesWas" : 2, "ok" : 1 }
> db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.test"
}
]
(4)删除所有索引:db.collection.dropIndexes()
# _id所在的列的索引不能删除。
(5)创建多列索引:db.collection.ensureIndex({field1:1/-1,field2:1/-1})
> db.test.ensureIndex({_id:1,name:1})
> db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.test"
},
{
"v" : 2,
"key" : {
"_id" : 1,
"name" : 1
},
"name" : "_id_1_name_1",
"ns" : "test.test"
}
]
(6)创建多列索引:db.collection.dropIndex({field1:1/-1,field2:1/-1})
> db.test.dropIndex({"_id" : 1,"name" : 1})
> db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.test"
}
]
(7)创建hash索引
> db.test.ensureIndex({name:'hashed'})
> db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.test"
},
{
"v" : 2,
"key" : {
"name" : "hashed"
},
"name" : "name_hashed",
"ns" : "test.test"
}
]
(8)为子文档创建索引
#插入数据
db.goods. insert({name: 'N0kia' , SPC:{weight: 120 , area: ' taiwan ' } } )
db.goods. insert({name: 'sanxing ' , SPC:{weight: 100 , area: 'hanguo'} } )
#查询产地为韩国的产品名
> db.goods.find({'SPC.area':'hanguo'},{name:1,_id:0})
{ "name" : "sanxing " }
#创建索引
> db.goods.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.goods"
}
]
> db.goods.ensureIndex({'SPC.weight':1})
> db.goods.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.goods"
},
{
"v" : 2,
"key" : {
"SPC.weight" : 1
},
"name" : "SPC.weight_1",
"ns" : "test.goods"
}
]
(9)、唯一索引,设置了唯一索引的列,元素不能重复
> db.goods.ensureIndex({"SPC.weight":1},{unique:1})
#插入weight相同的数据
> db.goods. insert({name: 'N0kia' , SPC:{weight: 120 , area: ' taiwan ' } } )
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: test.goods index: SPC.weight_1 dup key: { SPC.weight: 120.0 }"
}
})
三、mongodb数据库的导出与导入
3.1、通用选项
--host host 主机
--port port 端口
-u username 用户名
-p passwd 密码
3.2、导出
-d 库名
-c 表名
-f field1,field2...列名
-q 查询条件
-o 导出的文件名。
--type csv 导出csv格式(便于和传统数据库交换数据),需要指定列名。
--skip 跳过多少个
--limit 指定导出多少个
-- sort: 导出时,可指定字段排序
示例1、导出json
mongoexport -d shop -c goods -o goods.json
示例2、导出指定字段为csv文件
mongoexport -d shop -c goods -f "goods_id","goods_name","shop_price" --type csv -o goods.csv
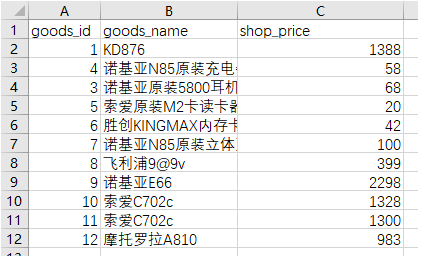
示例3、导出指定数量,并且按照价格从高到低排序
mongoexport -d shop -c goods --limit 5 --sort {shop_price:-1} --f "goods_id","goods_name","shop_price" --type csv -o goods.csv
3.3、导入
-d 待导入的数据库
-c 待导入的表(不存在会自己创建)
--file 备份文件路径
示例1、导入json
mongoimport -d douban -c top250 --file ./doubantop250.json
示例2、导入csv
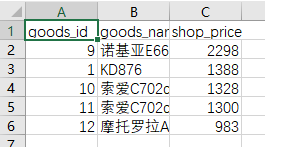
mongoimport -d test -c shop --type csv -f "goods_id","goods_name","shop_price" ./goods.csv
> use test
> db.shop.find()
{ "_id" : ObjectId("5e844e4d05ffa52ba53b45b4"), "goods_id" : 3, "goods_name" : "诺基亚原装5800耳机", "shop_price" : 68 }
{ "_id" : ObjectId("5e844e4d05ffa52ba53b45b5"), "goods_id" : 5, "goods_name" : "索爱原装M2卡读卡器", "shop_price" : 20 }
...
3.4、导出为二进制
-d 库名
-c 表名
#默认导出到执行命令位置dump目录下
#导出的文件放在以database命名的目录下
#每个表导出2个文件,分别是bson结构的数据文件, json的索引信息
#如果不声明表名, 导出所有的表。
示例1、导出一个数据库下的所有表。
mongodump -d test
示例2、导出指定表
mongodump -d shop -c goods

3.5、导入二进制文件
mongorestore -d shop1 -c goods --dir ./dump/shop/goods.bson
> use shop1
switched to db shop1
> show tables
goods
四、mongo复制集,类似于 redis( 主从+哨兵),以下操作都在windows上。
4.1、目录准备
#创建数据库目录
C:\Users\28295\Desktop>md data1
C:\Users\28295\Desktop>md data2
C:\Users\28295\Desktop>md data3
#创建日志目录,及日志文件
C:\Users\28295\Desktop>md log1
C:\Users\28295\Desktop>md log2
C:\Users\28295\Desktop>md log3
C:\Users\28295\Desktop>echo >>log3\\log.log
C:\Users\28295\Desktop>echo >>log2\\log.log
C:\Users\28295\Desktop>echo >>log1\\log.log
4.2、启动服务
#关闭mongodb服务(没有配置服务自启,请忽略。),启动三个服务端。
PS C:\Users\28295\Desktop\spider> net stop MongoDB #注意要用管理员权限打开命令窗口。
MongoDB 服务正在停止.
MongoDB 服务已成功停止。
#--replSet 代表复制集的名称,必须要一致。
mongod --dbpath C:\Users\28295\Desktop\data1 --logpath C:\Users\28295\Desktop\log1\log.log --port 27017 --replSet db
mongod --dbpath C:\Users\28295\Desktop\data2 --logpath C:\Users\28295\Desktop\log2\log.log --port 27018 --replSet db
mongod --dbpath C:\Users\28295\Desktop\data3 --logpath C:\Users\28295\Desktop\log3\log.log --port 27019 --replSet db

4.3、用客户端连接其中一台服务器,进行配置。
var rsconf = {
_id:'db',
members:[
{_id:0,host:'127.0.0.1:27017'},
{_id:1,host:'127.0.0.1:27018'},
{_id:2,host:'127.0.0.1:27019'}
]
}
rs.initiate(rsconf) #初始化,主服务端随机分配。
初始化完成后,主服务端会变成如下样子(27018).
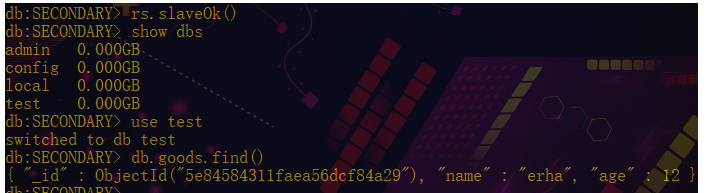
从服务端下(27017,127019)

主服务端插入数据后,从服务端必须输入rs.slaveOk()之后才能被允许查看数据,不然会报错。
db:PRIMARY> db.goods.insert({name:'erha',age:12})
WriteResult({ "nInserted" : 1 })
假如主服务器死亡(27018),则在剩下的mongodb服务器中选出一台作为主服务器。
rs.status() #该命令可以查看具体的复制集信息
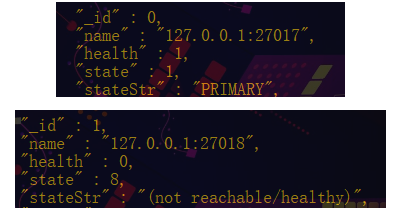
有上图可知,在我强制关闭(27018)主服务器后,(27017)此时变为了主服务器。
mongodb_2的更多相关文章
- c#简单操作MongoDB_2.4
一.MongoDB的安装 MongoDb在windows下的安装与以auth方式启用服务 二.下载驱动 使用nuget搜索“mongodb”,下载“MongoDB.Driver”(这是官方推荐的一个驱 ...
- 进程监控工具supervisor 启动Mongodb
进程监控工具supervisor 启动Mongodb 一什么是supervisor Superviosr是一个UNIX-like系统上的进程监控工具. Supervisor是一个Python开发的cl ...
- supervisor简介
一什么是supervisor Superviosr是一个UNIX-like系统上的进程监控工具. Supervisor是一个Python开发的client/server系统,可以管理和监控*nix上面 ...
- docker创建镜像的几个命令
docker create -it --name mongodb mongo/myubuntu1. docker start mongodbdocker exec -it mongodb bash i ...
- MongDB篇,第四章:数据库知识4
MongDB 数据库知识4 GridFS 大文件存储 文件的数据库存储 1,在数据库中以 字符串的方式 存储文件在本地的路径: 优点: 节省数据库空间 缺点: 当数据库或者文件位置发生变化时则无 ...
- mongodb replica set 配置高性能多服务器详解
mongodb的多服务器配置,以前写过一篇文章,是master-slave模式的,请参考:详解mongodb 主从配置.master-slave模式,不能自动实现故障转移和恢复.所以推荐大家使用mon ...
- MongoDB4.2 副本集扫盲说明
说明: 在扫盲MongoDB相关的一些知识的时候,顺手做下笔记.本文将说明副本集相关的内容.在比较早之前已经对这些有过说明,可以看MongoDB 副本集的原理.搭建.应用.MongoDB中的副本集是一 ...
- MongoDB4.2 分片扫盲说明
说明: 在扫盲MongoDB相关的一些知识的时候,顺手做下笔记.本文将说明分片相关的内容.在比较早之前已经对这些有过说明,可以看MongoDB 分片的原理.搭建.应用.分片(sharding)是指将数 ...
随机推荐
- Docker实战之MySQL主从复制
前言 曾几何时,看着高大上的架构和各位前辈高超的炫技,有没有怦然心动,也想一窥究竟?每当面试的时候,拿着单应用的架构,吹着分库分表的牛X,有没有心里慌的一批? 其实很多时候,我们所缺少的只是对高大上的 ...
- Android中使用AsyncTask
>##今天写作业用到了AnsyncTask,记录一下自己的使用情况 >###1.Android.os.AsyncTask类 > 1.AsyncTask类对线程间通讯进行了包装,我们 ...
- Solr查询配置及优化【eDisMax查询解析器】
一.简介 Lucene查询解析器语法支持创建任意复杂的布尔查询,但还有一些缺点,它不是用户查询处理的理想解决方案.这里面最大的问题是Lucene查询解析器的语法要求严格,一旦破坏就会抛出异常.指望用户 ...
- python中if __name__ == '__main__'是什么?
__name__和__main__认识 作用:一般用于测试程序的功能,if __name__ == '__main__':下面的代码会被执行,但当前.py文件被当做模块导入的时候,main下面的代码就 ...
- 7-2 jmu-python-九九乘法表(矩形) (10 分)
本题目要求输出如下图所示的九九乘法表 注:乘积要求做格式控制,占4个位置的宽度 输入样例: 无 输出样例: 1*1=1 1*2=2 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8= ...
- 关于Js的那些面试题
1.javascript的typeof返回哪些数据类型 number string boolean Object function underfind 2.例举3种强制类型转换和2种隐式类型转换?强制 ...
- 微服务优化之使用gRPC做微服务的内部通信
使用gRPC做微服务的内部通信 gRPC是一个由Google开源的远程服务调用框架,具有多路复用和双向流式通信的特性. 大家好,在本文中将为大家介绍为什么我们应该使用gRPC代替RESTful或JSO ...
- SpringBoot1.5.10.RELEASE整合druid
1.先在pom文件中导入druid的jar包 <dependency> <groupId>com.alibaba</groupId> <artifactId& ...
- 解决 unable to lock the administration directory (/var/lib/dpkg/) 问题
阿里开源镜像站提供了raspbian的软件包镜像,国内的用户可以选择改用阿里镜像站作为更新源. 但是在更换源之后,执行 sudo apt-get update && apt-get u ...
- Django中update和save()同时作用
数据更新操作,对单条记录,可以使用save或者是update两种方式. save() 默认保存后会看到sql语句中更新了所有字段,而save的值是之前获取时候的字段值,是缓存下来的,并不一定最新,可能 ...