LinkedList为什么增删快、查询慢
- ArrayList:长于随机访问元素,中间插入和移除元素比较慢,在插入时,必须创建空间并将它的所有引用向前移动,这会随着ArrayList的尺寸增加而产生高昂的代价,底层由数组支持。
- LinkedList:通过代价较低的在List中间进行插入和删除操作,只需要链接新的元素,而不必修改列表中剩余的元素,无论列表尺寸如何变化,其代价大致相同,提供了优化的顺序访问,随机访问相对较慢,特性较ArrayList更大,而且还添加了可以使其作为栈、队列或双端队列的方法,底层由双向链表实现。

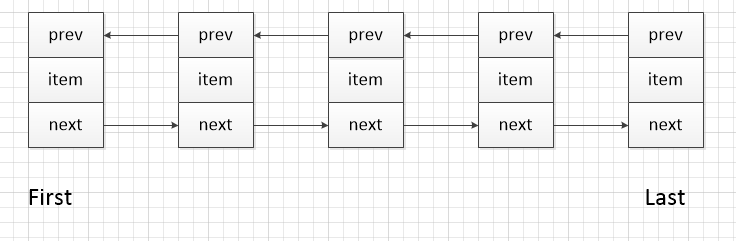
//关于Node构造函数
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev; Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//transient 保证以下几个属性不被序列化
/**
* The number of times this list has been <i>structurally modified</i>.
* 该字段表示list结构上被修改的次数。结构上的修改指的是那些改变了list的长度
* 大小或者使得遍历过程中产生不正确的结果的其它方式。
*
*/
protected transient int modCount = 0; transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- 获得最后一个节点last作为当前节点l
- 用当前节点l、添加参数e、null创建一个新的Node对象
- 将新创建的Node对象链接到最后节点,也就是last
- 如果当前的LinkedList为空,那么添加的node就是first,也是last
- 当前LinkedList的size+1,表示结构改变次数的对象modCount+1
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
LinkedList的删除中,会根据传递进来的参数进行null判断,因为在LinkedList的元素移除中,null和非null的处理不一样,对于nul使用==去判断是否匹配,对于非null使用.equals(Object o)去判断,至于==和equals的区别,读者自行百度。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
- 如果前一个节点prev为null,即第一个节点元素,则链表first = x下一个节点;
- 如果前一个节点prev不为null,即不是第一个节点元素,则将当前节点的next赋值给prev.next,x.prev置为null,也就是当前节点x的prev和next和当前链表中的其他元素不存在任何联系;
- 如果下一个节点next为null,即为最后一个元素,则链表last = x前一个节点;
- 如果下一个节点next不为null,即不为最后一个元素,则将当前节点的prev赋值给next.prev,同样当前节点x的prev和next和当前链表中的其他元素不存在任何联系;
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
- 根据传入的index去判断是否为LinkedList中的元素,判断逻辑为index是否在0和size之间,如果在则调用node(index)方法,否则抛出IndexOutOfBoundsException;
- 调用node(index)方法,将size右移1位,即size/2,判断传入的size在LinkedList的前半部分还是后半部分
- 如果在前半部分,即index < size/2,则从fisrt节点开始遍历匹配
- 如果在后半部分,即index > size/2,则从last节点开始遍历匹配
LinkedList为什么增删快、查询慢的更多相关文章
- 集合之LinkedList源码分析
转载请注明出处:http://www.cnblogs.com/qm-article/p/8903893.html 一.介绍 在介绍该源码之前,先来了解一下链表,接触过数据结构的都知道,有种结构叫链表, ...
- 数据结构-List接口-LinkedList类-Set接口-HashSet类-Collection总结
一.数据结构:4种--<需补充> 1.堆栈结构: 特点:LIFO(后进先出);栈的入口/出口都在顶端位置;压栈就是存元素/弹栈就是取元素; 代表类:Stack; 其 ...
- ArrayList和LinkedList的共同点和区别
ArrayList和LinkedList的相同点和不同点 共同点:都是单列集合中List接口的实现类.存取有序,有索引,可重复 不同点: 1.底层实现不同: ArrayList底层实现是数组,Link ...
- List-ApI及详解
1.API : add(Object o) remove(Object o) clear() indexOf(Object o) get(int i) size() iterator() isEmpt ...
- javaList容器中容易忽略的知识点
在集合类框架中,List是使用比较多的一种 List |---Arraylist 内部维护的是一个数组,查找快增删慢 |---LinkedList 底层是链表,增删快查询慢. |---Vctor线程安 ...
- java_List集合及其实现类
第一章:List集合_List接口介绍 1).特点 1).有序的: 2).可以存储重复元素: 3).可以通过索引访问: List<String> list = new Arra ...
- java基础-day17
第06天 集合 今日内容介绍 u 集合&迭代器 u 增强for & 泛型 u 常见数据结构 u List子体系 第1章 集合&迭代器 1.1 集合体系结构 1.1 ...
- BAT面试必备——Java 集合类
本文首发于我的个人博客:尾尾部落 1. Iterator接口 Iterator接口,这是一个用于遍历集合中元素的接口,主要包含hashNext(),next(),remove()三种方法.它的一个子接 ...
- 集合之四:List接口
查阅API,看List的介绍.有序的 collection(也称为序列).此接口的用户可以对列表中每个元素的插入位置进行精确地控制.用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的 ...
随机推荐
- [译] React 16.3(.0-alpha) 新特性
原文地址:What's new in React 16.3(.0-alpha) 原文作者:Bartosz Szczeciński 译文出自:掘金翻译计划 本文永久链接:github.com/xitu/ ...
- Codeforces Round #618 (Div. 2)-B. Assigning to Classes
Reminder: the median of the array [a1,a2,-,a2k+1] of odd number of elements is defined as follows: l ...
- POJ - 3074 Sudoku (搜索)剪枝+位运算优化
In the game of Sudoku, you are given a large 9 × 9 grid divided into smaller 3 × 3 subgrids. For exa ...
- 2019 ICPC 银川网络赛 H. Fight Against Monsters
It is my great honour to introduce myself to you here. My name is Aloysius Benjy Cobweb Dartagnan Eg ...
- MySQL 增删改查(单表)
1.sql 新增语句 表中插入数据 insert into + 表名 values(字段1value1,字段2value1,字段3value1),(字段1value2,字段2value2,字段3val ...
- 在web项目中使用shiro(记住我功能)
第一步,添加“记住我”复选框,rememberMe要设置参数 第二步,配置shiro的主配置文件 注意 rememberMeCookie对应的bean中要声明 <constructor-arg ...
- GUI_DOWNLOAD 下载乱码
状况: 开发者打开正常,跨公司或跨企业打开异常. 跨App上传格式异常. 解决上述问题步骤: 1.用浏览器或可改变文件编码格式切换的软件打开文件(其他app上传正常文档格式,或跨公司打开正常文件)查看 ...
- 新书《OpenShift云原生架构:原理与实践》第一章第三节:企业级PaaS平台OpenShift
近十年来,信息技术领域在经历一场技术大变革,这场变革正将我们由传统IT架构及其所支撑的臃肿应用系统时代,迁移至云原生架构及其所支撑的敏捷应用系统时代.在这场变革中,新技术的出现.更新和淘汰之迅速,以及 ...
- Day_09【常用API】扩展案例1_程序中使用一个长度为3的对象数组,存储用户的登录名和密码……
需求说明:实现用户注册.登陆功能: 1.程序中使用一个长度为3的**对象数组**,存储用户的登录名和密码: 例如如下格式: 登录名 密码 生日 爱好 zhangsan 1111 1998-03-15 ...
- 永磁同步电机 spmsm 和 ipmsm 的区别总结
layout: post tags: [motor control] comments: true 永磁同步电机的分类 永磁同步电机根据转子上永磁体的位置不同,可以分为: 表贴式永磁同步电机--S-P ...