Kaggle入门——泰坦尼克号生还者预测
前言
这个是Kaggle比赛中泰坦尼克号生存率的分析。强烈建议在做这个比赛的时候,再看一遍电源《泰坦尼克号》,可能会给你一些启发,比如妇女儿童先上船等。所以是否获救其实并非随机,而是基于一些背景有先后顺序的。
1,背景介绍
1912年4月15日,载着1316号乘客和891名船员的豪华巨轮泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员。虽然幸存下来有一些运气因素,但有一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。在本文中将对哪些人可能生存作出分析,特别是运用Python和机器学习的相关模型工具来预测哪些乘客幸免于难,最后提交结果。
其中训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。这是一个二分类的问题。
2,数据文件说明
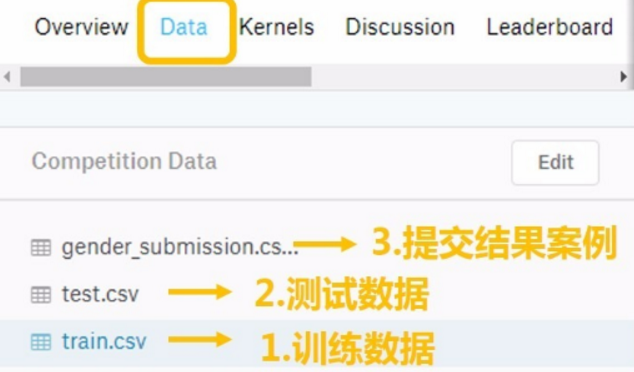
从Kaggle泰坦尼克号项目页面下载数据:https://www.kaggle.com/c/titanic
下面是问题的背景页:
下面是可下载Data的页面
下面是forum页面,我们会从中学到各种数据处理/建模想法:
3,数据变量说明
每个乘客有12个属性,其中PassengerID在这里只起到索引作用,而Survived是我们要预测的目标,因此我们要处理的数据总共有10个变量。

对于上述变量的说明:
- PassengerID(ID)
- Survived(存活与否)
- Pclass(客舱等级,在当时的英国阶级分层比较严重,较为重要)
- Name(姓名,可提取出更多信息)
- Sex(性别,较为重要)
- Age(年龄,较为重要)
- Parch(直系亲友,是指父母,孩子,其中1表示有一个,依次类推)
- SibSp(旁系,是指兄弟姐妹)
- Ticket(票编号,这个是个玄学问题)
- Fare(票价,可能票价贵的获救几率大)
- Cabin(客舱编号)
- Embarked(上船的港口编号,是指从不同的港口上船)
4,评估方法
将从基础的方法开始学习,然后预测结果,最后将准确率最高的模型预测的结果提交到Kaggle上,查看自己的结果如何。
5,完整代码,请移步小编的GitHub
传送门:请点击我
如果点不开,复制这个地址:https://github.com/LeBron-Jian/Kaggle-learn
数据预处理
数据的质量决定模型能达到的上限、所以对数据的预处理无比重要。机器学习的算法模型是用来挖掘数据中潜在模式的,但是若数据太过复杂,潜在的模式就很难找到,更糟糕的是,我们所收集的数据的特征和我们想预测的标签之间并没有太大关联,这时候这个特征就像噪音一样只会干扰我们的模型做出准确的预测。所以说,我们要对拿到手的数据集进行分析,并看看各个特征到底会不会显著影响到我们要预测的标签值。
1,总体预览
在Data下的我们的 train.csv 和 test.csv 两个文件分别存着官方给出的训练和测试数据。
train.info()
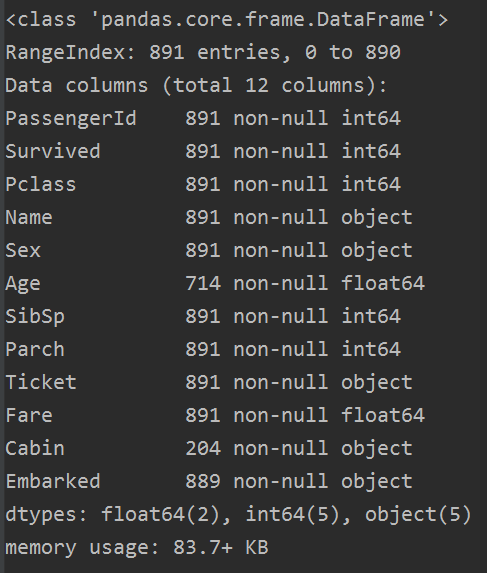
从数据中发现,总数为891个,那还有特征是有空值的,Cabin甚至只有一点数据(不着急,这里我们先看看)。而且有些数据是数值型的,一些是文本型的,还有一些是类目性的。这些我们用下面函数是看不到的。
res = all_data.describe()
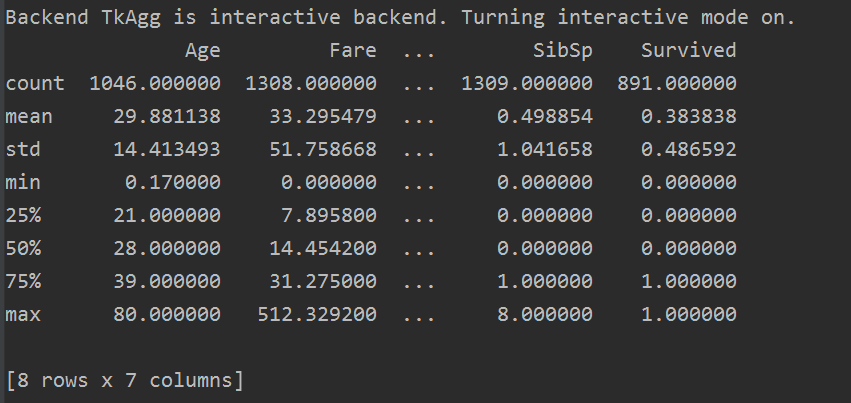
describe() 函数时查看数据的描述统计信息,只查看数值型数据,字符串型的数据,如姓名(name),客舱号(Cabin)等不可显示。
而上面信息告诉我们,大概有 0.383838的人最终获救了,平均乘客年龄大概是29.88岁等等。。
2,数据初步分析
每个乘客都有这么多属性,那我们咋知道哪些属性更有用,而又应该怎么用他们呢?说实话这会我也不知道,但是我们要知道,对数据的认识是非常重要的!所以我们要深入的看我们的数据,后面就会写到如何分析数据。
为什么要这样分析数据,我们可以先看看这个文章https://zhuanlan.zhihu.com/p/26663761。一个泰坦尼克号的生还者写下的回忆录,我这里粘贴几个重要的:
注意:面对沉船灾难,妇女和儿童先上救生艇,当然也有例外,不过很少。




这次分析分析以下几个方面:
- 1,性别与幸存率的关系
- 2,乘客社会等级与幸存率的关系
- 3,携带配偶及兄弟姐妹与幸存率的关系
- 4,携带父母及子女与幸存率的关系
- 5,年龄与幸存率的关系
- 6,登港港口与幸存率的关系
- 7,称呼(从姓名中提取乘客的称呼)与幸存率的关系
- 8,家庭总人数与幸存率的关系
- 9,不同船舱的乘客与幸存率的关系
(这些分析参考博客:https://www.jianshu.com/p/e79a8c41cb1a)
首先,我们看看得到的数据中,幸存的人与死亡人数的比重:
res = train['Survived'].value_counts()
print(res)
'''
0 549
1 342
Name: Survived, dtype: int64 '''
2.1 性别与生存率的关系
我们从上面知道,让妇女儿童上船,那么女性的幸存率到底如何呢?我们看图:
sns.barplot(x='Sex', y='Survived', data=train)
图如下:

我们可以看到,确实是女性幸存率远高于男性,那么性别Sex是一个很重要的特征。
2.2 乘客等级与生存率的关系
sns.barplot(x='Pclass', y='Survived', data=train)
图如下:
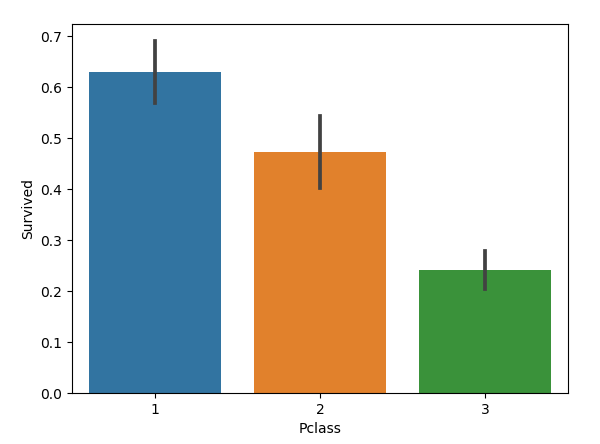
我们发现,乘客社会等级越高,幸存率越高,所以Pclass这个特征也比较重要。
2.3 携带配偶及兄弟姐妹与生存率的关系
sns.barplot(x='SibSp', y='Survived', data=train)
图如下:
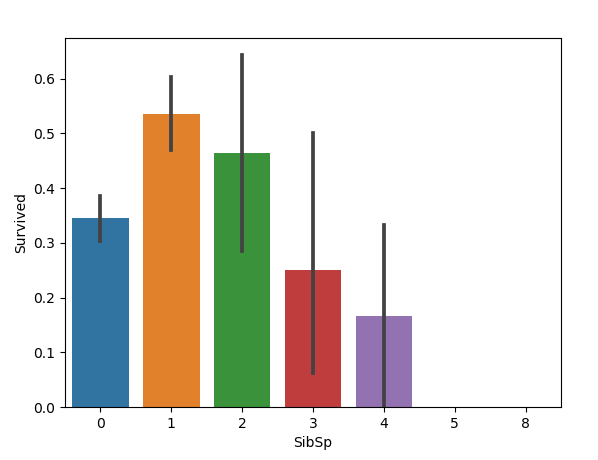
只能说:携带的配偶与兄弟姐妹适中的乘客幸存率更高,可能带个配偶幸存率最高。
2.4 携带父母与子女与生存率的关系
sns.barplot(x='Parch', y='Survived', data=train)
图如下:
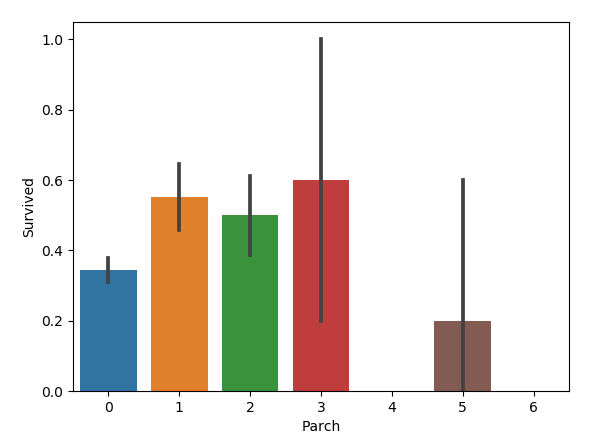
好像也是父母与子女适中的乘客幸存率更高。
2.5 年龄与幸存率的关系
facet = sns.FacetGrid(train, hue='Survived', aspect=2)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlabel('Age')
plt.ylabel('density')
图如下:
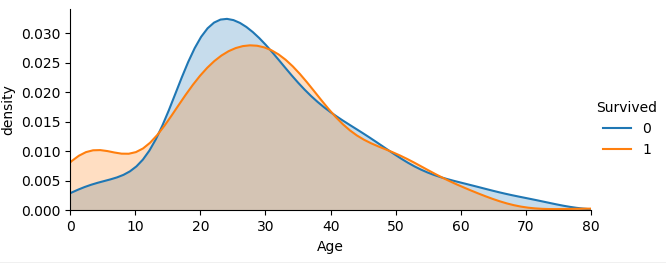
从不同生还情况的密度图可以看出,在年龄15岁的左侧,生还率有明显差别,密度图非交叉区域面积非常大,但在其他年龄段,则差别不是很明显,认为是随机所致,因此可以考虑将年龄偏小的区域分离出来。
2.6 登港港口与幸存率的关系
登船港口(Embarked):
- 出发地点:S = 英国南安普顿Southampton
- 途径地点1:C = 法国 瑟堡市Cherbourg
- 途径地点2:Q = 爱尔兰 昆士敦Queenstown
我们先按照登港港口与幸存率的关系画图,代码如下:
sns.countplot('Embarked',hue='Survived',data=train)
图如下:
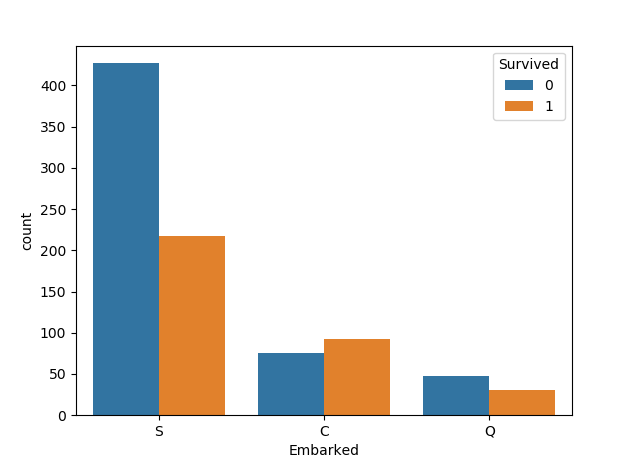
我们发现C地的生存率更高,这个应该保存为模型特征,最后我们再筛选嘛。
2.7 不同称呼与幸存率的关系
每个人都有自己的名字,而且每个名字都是独一无二的,名字和幸存与否看起来并没有直接关联,那怎么利用这个特征呢?有用的信息就隐藏在称呼当中,比如上面我们提到过女生优先,所以称呼为Mrs和 Miss 的就比称呼为Mr 的的更可能幸存,于是我们需要从Name中拿到其称呼并建立新的特征列Title。
我们注意在每一个name 中,有一个非常显著的特点:乘客头衔每个名字当中都包含了具体的称谓或者说是头衔,将这部分信息提取出来后可以作为非常有用的一个新变量,可以帮助我们进行预测。
例如:
Braund, Mr. Owen Harris
Heikkinen, Miss. Laina
Oliva y Ocana, Dona. Fermina
Peter, Master. Michael J
定义函数,从名字中获取头衔。
all_data['Title'] = all_data.Name.apply(lambda name: name.split(',')[1].split('.')[0].strip())
如果上面代码看不懂,可以看下面这个:
# get all the titles and print how often each one occurs
titles = all_data['Name'].apply(get_title)
print(pd.value_counts(titles)) # A function to get the title from a name
def get_title(name):
# use a regular expression to search for a title
title_search = re.search('([A-Za-z]+)\.', name)
# if the title exists, extract and return it
if title_search:
return title_search.group(1)
return ''
我们可以看看称呼的种类和数量:
all_data.Title.value_counts() out:
Mr 757
Miss 260
Mrs 197
Master 61
Rev 8
Dr 8
Col 4
Mlle 2
Ms 2
Major 2
Capt 1
Lady 1
Jonkheer 1
Don 1
Dona 1
the Countess 1
Mme 1
Sir 1
Name: Title, dtype: int64
我们将定义以下几种头衔类型
- Officer政府官员
- Royalty王室(皇室)
- Mr已婚男士
- Mrs已婚妇女
- Miss年轻未婚女子
- Master有技能的人/教师
大类可以分为六个:Mr,Miss,Mrs,Master,Royalty,Officer,姓名中头衔字符串与定义头衔类型的分类代码如下:
all_data = pd.concat([train, test], ignore_index=True)
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master')) all_data['Title'] = all_data['Title'].map(Title_Dict)
sns.barplot(x="Title", y="Survived", data=all_data)
上面的pandas不会使用,也可以使用下面代码:
# map each title to an integer some titles are very rare
# and are compressed into the same codes as other titles
title_mapping = {
'Mr': 1,
'Miss': 2,
'Mrs': 3,
'Master': 4,
'Rev': 5,
'Dr': 6,
'Col': 7,
'Mlle': 8,
'Ms': 9,
'Major': 10,
'Don': 11,
'Countess': 12,
'Mme': 13,
'Jonkheer ': 14,
'Sir': 15,
'Dona': 16,
'Capt': 17,
'Lady': 18,
}
for k, v in title_mapping.items():
titles[titles == k] = v
# print(k, v)
all_data['Title'] = titles
至于如何分类,就看自己的想法了,我这里只是将所有的称呼表示出来,你可以自己分。我按照上面的分类:
title_mapping = {
'Mr': 2,
'Miss': 3,
'Mrs': 4,
'Master': 1,
'Rev': 5,
'Dr': 5,
'Col': 5,
'Mlle': 3,
'Ms': 4,
'Major': 6,
'Don': 5,
'Countess': 5,
'Mme': 4,
'Jonkheer ': 1,
'Sir': 5,
'Dona': 5,
'Capt': 6,
'Lady': 5,
}
图如下:

2.8 家庭总人数与幸存率的关系
我们新增FamilyLabel特征,这个特征等于父母儿童+配偶兄弟姐妹+1,在文中就是 FamilyLabel=Parch+SibSp+1,然后将FamilySize分为三类:
all_data['FamilySize']=all_data['SibSp']+all_data['Parch']+1
sns.barplot(x="FamilySize", y="Survived", data=all_data)
图如下:
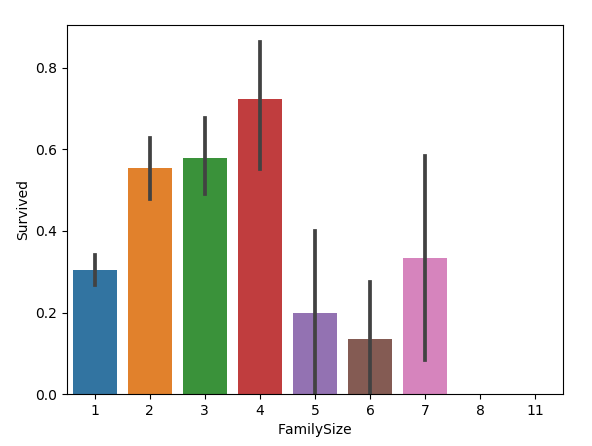
家庭类别:
- 小家庭Family_Single:家庭人数=1
- 中等家庭Family_Small: 2<=家庭人数<=4
- 大家庭Family_Large: 家庭人数>=5
我们按照生存率将FamilySize分为三类,构成FamilyLabel特征:
def Fam_label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 7)) | (s == 1):
return 1
elif (s > 7):
return 0 all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch'] + 1
all_data['FamilyLabel']=all_data['FamilySize'].apply(Fam_label)
sns.barplot(x="FamilyLabel", y="Survived", data=all_data)
结果图如下:
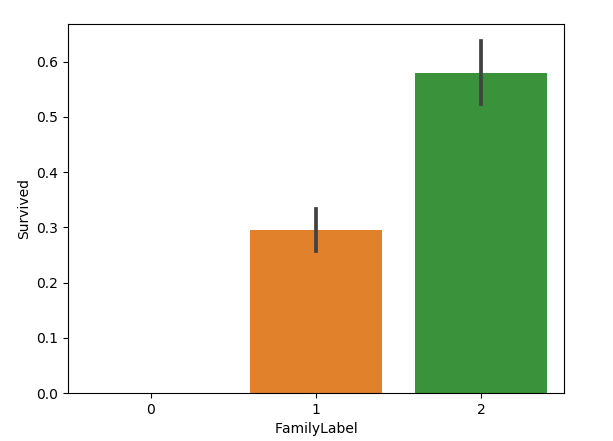
也可以提取名字长度的特征:
# generating a familysize column 是指所有的家庭成员
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch'] # the .apply method generates a new series
all_data['NameLength'] = all_data['Name'].apply(lambda x: len(x))
最后我们选择是否使用这些特征。
2.9 不同船舱的乘客与幸存率的关系
船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大。这注定是个棘手的问题。
当然船舱的数据并不是很多,但是乘客位于不同船舱,也就意味着身份不同,所以我们新增Deck特征,先把Cabin空白的填充为“Unknown”,再提取Cabin中的首字母构成乘客的甲板号。
all_data['Cabin'] = all_data['Cabin'].fillna('Unknown')
all_data['Deck'] = all_data['Cabin'].str.get(0)
sns.barplot(x="Deck", y="Survived", data=all_data)
图如下:
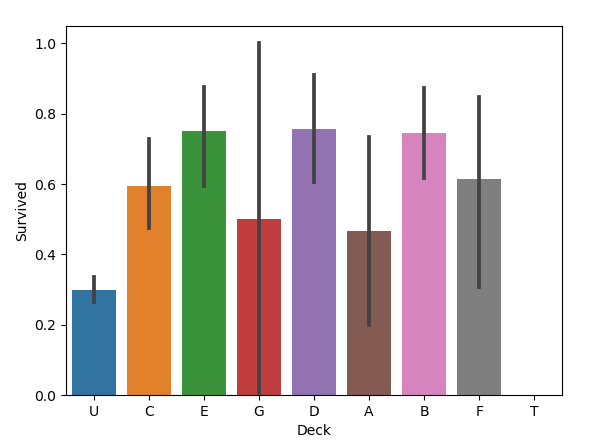
2.10 与二到四人共票号的乘客与幸存率的关系
新增了一个特征叫做 TicketGroup特征,这个特征是统计每个乘客的共票号数。代码如下:
Ticket_Count = dict(all_data['Ticket'].value_counts())
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x: Ticket_Count[x])
sns.barplot(x='TicketGroup', y='Survived', data=all_data)
图如下:
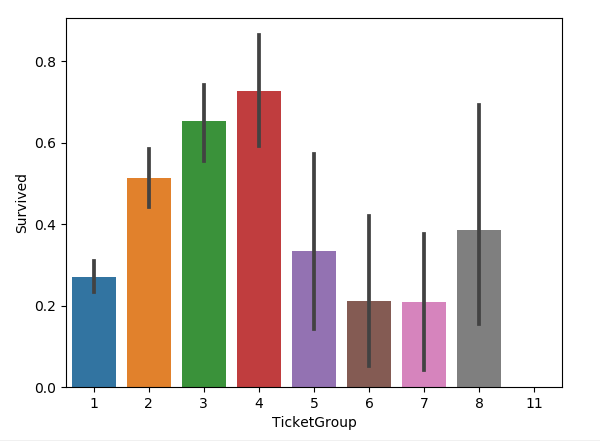
把生存率按照TicketGroup 分为三类:
Ticket_Count = dict(all_data['Ticket'].value_counts())
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x: Ticket_Count[x])
all_data['TicketGroup'] = all_data['TicketGroup'].apply(Ticket_Label)
sns.barplot(x='TicketGroup', y='Survived', data=all_data) def Ticket_Label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 8)) | (s == 1):
return 1
elif (s > 8):
return 0
图如下:
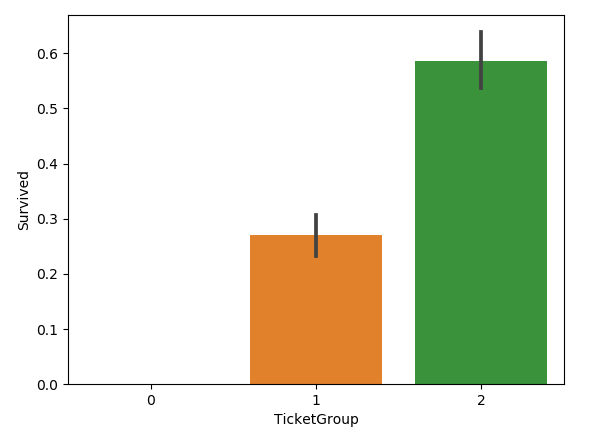
3,数据清洗
3.1 缺失值填充
上面我们从整体分析的时候,也发现了有着不少的缺失值,缺失量也有比较大的,所以我们如何填充缺失值,这是个问题。
很多机器学习算法为了训练模型,要求所传入的特征中不能有空值。一般做如下处理:
1,如果是数值类型,用平均值取代 .fillna(.mean())
2,如果是分类数据,用最常见的类别取代 .value_counts() + fillna.()
3,使用模型预测缺失值,例如KNN
具体可以参考我的博客:
Python机器学习笔记:使用sklearn做特征工程和数据挖掘
我们首先看看那些变量都有缺失值:
下面这个是train的数据,总共数据有891个,那么在训练的数据集中 Age,Cabin, Embarked 有缺失值。
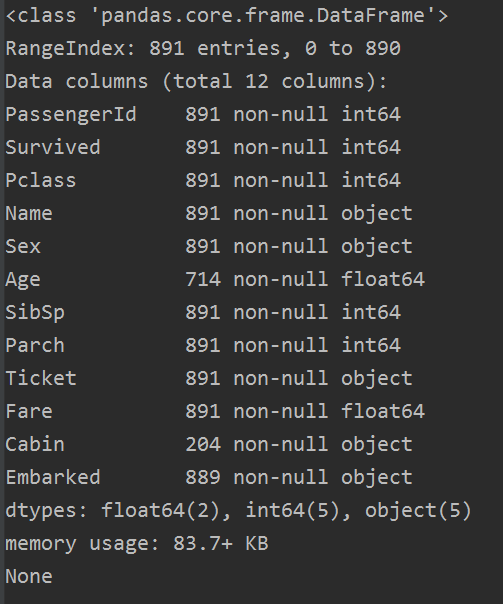
下面这个是test的数据,总共有418个数据,其中Age, Fare, Cabin 有缺失值。

这里对Age的缺失值处理方法是采用平均值:
traindata['Age'] = traindata['Age'].fillna(traindata['Age'].median()) test['Age'] = test['Age'].fillna(test['Age'].median())
当然平均值可能有些不妥,我百度,也有说按照称呼对Age的缺失值进行补全了,(上面我们不是对姓名做了处理:2.7 不同称呼与幸存率之间的关系),因为Miss用于未婚女子,通常其年龄比较小,Mrs则表示太太,夫人,一般年龄较大,因此利用称呼中隐含的信息去推断其年龄是比较合理的,下面可以根据title进行分组并对Age进行补全。
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
all_data = pd.concat([train, test], ignore_index=True)
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master')) all_data['Title'] = all_data['Title'].map(Title_Dict)
# sns.barplot(x="Title", y="Survived", data=all_data)
grouped = all_data.groupby(['Title'])
median = grouped.Age.median()
print(median) Title
Master 4.5
Miss 22.0
Mr 29.0
Mrs 35.0
Officer 49.5
Royalty 40.0
Name: Age, dtype: float64
可以看到,不同称呼的乘客其年龄的中位数有显著差异,因此我们只需要按称呼对缺失值进行补全即可,这里使用中位数(平均数也是可以的,在这个问题当中两者差异不大,而中位数看起来更整洁一些)。
代码如下:
all_data['Title'] = all_data['Title'].map(Title_Dict)
# sns.barplot(x="Title", y="Survived", data=all_data)
grouped = all_data.groupby(['Title'])
median = grouped.Age.median()
for i in range(len(all_data['Age'])):
if pd.isnull(all_data['Age'][i]):
all_data['Age'][i] = median[all_data['Title'][i]]
我们可以查看一下 all_data.info()
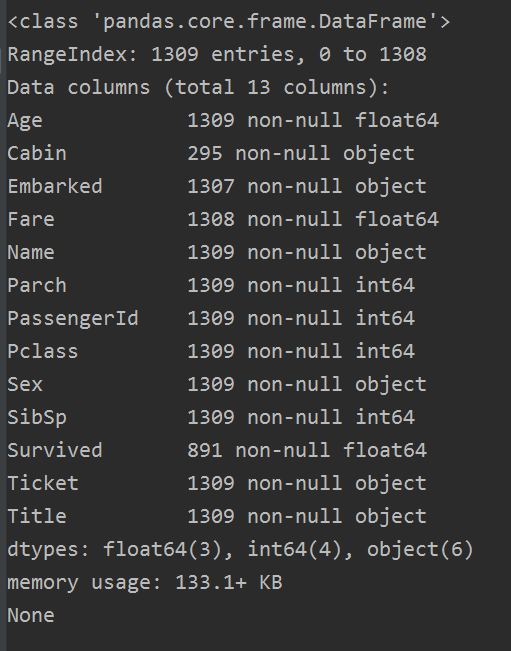
Age的缺失值已经补全了,下面我们对Cabin,Embarked 以及Fare进行补全。
而Embarked 缺失值只有两个,对结果影响不大,所以我们这里将缺失值补全为登船港口人数最多的港口(这里其实应用的是先验概率最大原则)。从结果来看(上面分析过),S地的登船人数最多,所以我们将缺失值填充为最频繁出现的值,S=英国安南普顿Southampton。
all_data['Embarked'] = all_data['Embarked'].fillna('S')
上面我们也提到过Cabin缺失数值比较多,所以我们把船舱号(Cabin)的缺失值填充为U,表示未知(Unknown)。
# 缺失数据比较多,船舱号(Cabin)缺失值填充为U,表示未知(Uknow)
all_data['Cabin'] = all_data['Cabin'].fillna('U')
Fare只有一个缺失值,所以我们可以用票价Fare的平均值补全。
all_data['Fare'] = all_data['Fare'].fillna(all_data.Fare.median())
至此,我们的缺失值就补全了,check一下:
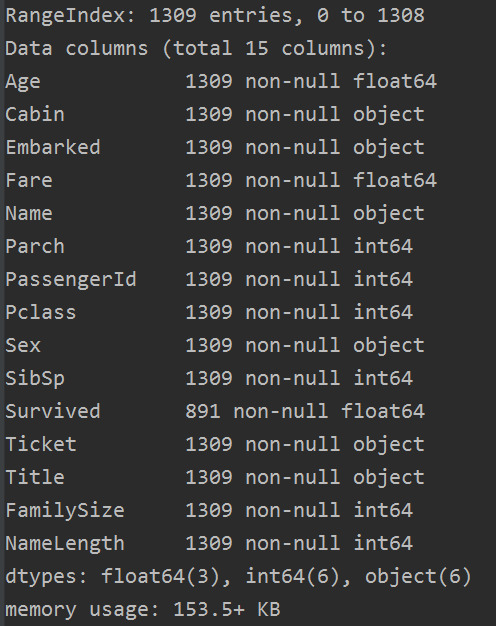
完整代码如下:
def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
# print(test.info())
all_data = pd.concat([train, test], ignore_index=True) titles = all_data['Name'].apply(get_title)
# print(pd.value_counts(titles))
# map each title to an integer some titles are very rare
# and are compressed into the same codes as other titles
title_mapping = {
'Mr': 2,
'Miss': 3,
'Mrs': 4,
'Master': 1,
'Rev': 5,
'Dr': 5,
'Col': 5,
'Mlle': 3,
'Ms': 4,
'Major': 6,
'Don': 5,
'Countess': 5,
'Mme': 4,
'Jonkheer': 1,
'Sir': 5,
'Dona': 5,
'Capt': 6,
'Lady': 5,
}
for k, v in title_mapping.items():
titles[titles == k] = v
# print(k, v)
all_data['Title'] = titles grouped = all_data.groupby(['Title'])
median = grouped.Age.median()
for i in range(len(all_data['Age'])):
if pd.isnull(all_data['Age'][i]):
all_data['Age'][i] = median[all_data['Title'][i]]
# print(all_data['Age']) # generating a familysize column 是指所有的家庭成员
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch'] # the .apply method generates a new series
all_data['NameLength'] = all_data['Name'].apply(lambda x: len(x))
# print(all_data['NameLength']) all_data['Embarked'] = all_data['Embarked'].fillna('S')
# 缺失数据比较多,船舱号(Cabin)缺失值填充为U,表示未知(Uknow)
all_data['Cabin'] = all_data['Cabin'].fillna('U')
all_data['Fare'] = all_data['Fare'].fillna(all_data.Fare.median()) all_data.loc[all_data['Embarked'] == 'S', 'Embarked'] = 0
all_data.loc[all_data['Embarked'] == 'C', 'Embarked'] = 1
all_data.loc[all_data['Embarked'] == 'Q', 'Embarked'] = 2 all_data.loc[all_data['Sex'] == 'male', 'Sex'] = 0
all_data.loc[all_data['Sex'] == 'female', 'Sex'] = 1 traindata, testdata = all_data[:891], all_data[891:]
# print(traindata.shape, testdata.shape, all_data.shape) # (891, 15) (418, 15) (1309, 15)
traindata, trainlabel = traindata.drop('Survived', axis=1), traindata['Survived'] # train.pop('Survived')
testdata = testdata
corrDf = all_data.corr()
'''
查看各个特征与生成情况(Survived)的相关系数,
ascending=False表示按降序排列
'''
res = corrDf['Survived'].sort_values(ascending=False)
print(res)
return traindata, trainlabel, testdata # A function to get the title from a name
def get_title(name):
# use a regular expression to search for a title
title_search = re.search('([A-Za-z]+)\.', name)
# if the title exists, extract and return it
if title_search:
return title_search.group(1)
return ''
OK,下一步,我们就需要进行特征工程对补全后的特征做进一步处理。
3.2 特征处理
当补全数据后,我们查看了数据类型,总共有三种数据类型。有整形 int, 有浮点型 float, 有object。我们需要用数值替代类别。有些动作我们前面已经做过了,但是这里总体再过一遍。
- 1,乘客性别(Sex):男性male,女性 female male=0,female=1
- 2,登船港口(Embarked):S,C,Q S=0, C=1, Q=2
- 3,乘客姓名(Name):我们分为六类(具体见前面2.7 不同称呼与幸存率的关系)
代码如下(其实上面都有):
all_data.loc[all_data['Embarked'] == 'S', 'Embarked'] = 0
all_data.loc[all_data['Embarked'] == 'C', 'Embarked'] = 1
all_data.loc[all_data['Embarked'] == 'Q', 'Embarked'] = 2 all_data.loc[all_data['Sex'] == 'male', 'Sex'] = 0
all_data.loc[all_data['Sex'] == 'female', 'Sex'] = 1 titles = all_data['Name'].apply(get_title)
# print(pd.value_counts(titles))
# map each title to an integer some titles are very rare
# and are compressed into the same codes as other titles
title_mapping = {
'Mr': 2,
'Miss': 3,
'Mrs': 4,
'Master': 1,
'Rev': 5,
'Dr': 5,
'Col': 5,
'Mlle': 3,
'Ms': 4,
'Major': 6,
'Don': 5,
'Countess': 5,
'Mme': 4,
'Jonkheer': 1,
'Sir': 5,
'Dona': 5,
'Capt': 6,
'Lady': 5,
}
for k, v in title_mapping.items():
titles[titles == k] = v
# print(k, v)
all_data['Title'] = titles
4,特征提取
一般来说,一个比较真实的项目,也就是说数据挖掘工程需要建立特征工程,我们需要看看如何提取新的特征,使得我们的准确率更高。这个怎么说呢,其实我们上面对数据分析了那么多,肯定是有原因的。下面一一阐述。
4.1 随机森林寻找重要特征
上面我们将数据缺失值填充完后,然后进行了概述,总共有14个特征,1个结果(Survived),其中四个特征是object类型,我们去掉,剩下了10个特征,我们做重要特征提取
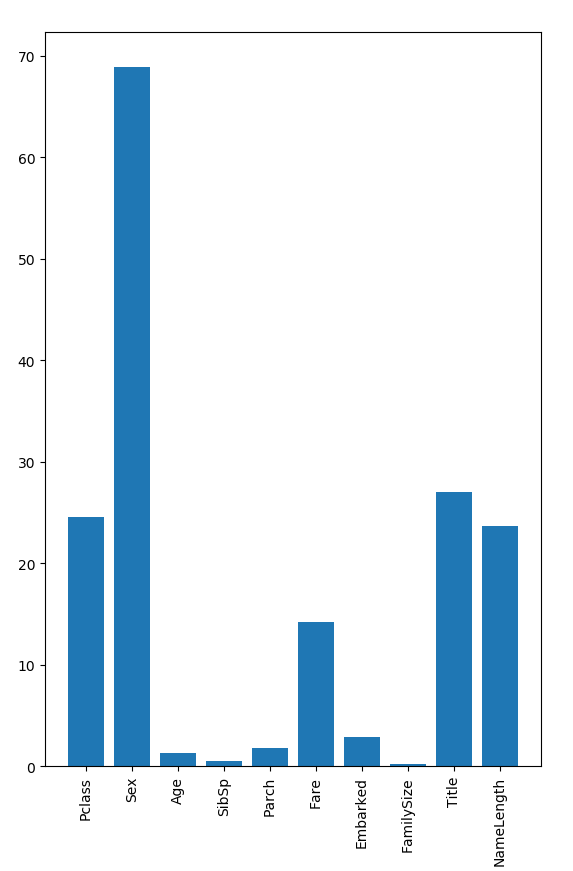
我们使用上面五个比较重要的特征:Pclass,Sex,Fare,Title, NameLength 做随机森林模型训练。
def random_forestclassifier_train(traindata, trainlabel, testdata):
# predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilySize', 'Title', 'NameLength']
predictors =['Pclass', 'Sex', 'Fare', 'Title', 'NameLength', ]
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正确率为 %s%%" % test_accuracy) # 正确率为 80.44692737430168%
准确率还没有不提取特征的高。。。。这就有点尴尬哈。
4.2 相关系数法
相关系数法:计算各个特征的相关系数
# 相关性矩阵
corrDf = all_data.corr()
'''
查看各个特征与生成情况(Survived)的相关系数,
ascending=False表示按降序排列
'''
res = corrDf['Survived'].sort_values(ascending=False)
print(res)
结果如下:
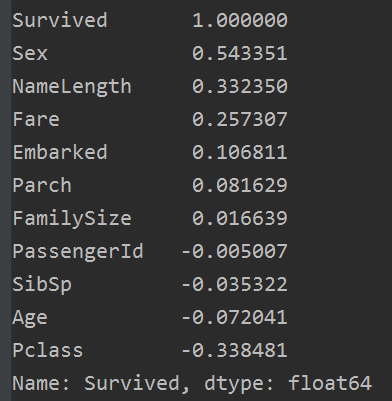
我们使用上面六个正相关的特征:Sex,NameLength, Fare,Embarked,Parch, FamiySize, 做随机森林模型训练。
def random_forestclassifier_train(traindata, trainlabel, testdata):
# predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilySize', 'Title', 'NameLength']
predictors = ['Sex', 'Fare', 'Embarked', 'NameLength', 'Parch', 'FamilySize']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正确率为 %s%%" % test_accuracy) # 正确率为 81.56424581005587%
相比于上个随机森林,效果好了不少,准确率提高了1个百分点。
4.3 尝试用所有特征做随机森林模型训练
def random_forestclassifier_train(traindata, trainlabel, testdata):
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilySize', 'Title', 'NameLength'] traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正确率为 %s%%" % test_accuracy) # 正确率为 83.79888268156425%
准确率进一步提高,这次提高了两个百分点。
这可能是目前效果最好的吧。。。。。。
所以下一步进行集成学习各种尝试,然后调参。。。。。。over
模型训练及其结果展示
1,线性回归模型
这里展示两种线性回归的方式,但是不知道为什么我的线性回归模型准确率低的可怕,都没有蒙的多,只有37.63003367180264%。具体原因不知道,希望细心的网友帮我发现。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier warnings.filterwarnings('ignore') def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 为数据填充函数 用括号里面的东西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata def linear_regression_test(traindata, trainlabel, testdata):
traindata = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
traindata['Age'] = traindata['Age'].fillna(traindata['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
traindata.loc[traindata['Sex'] == 'male', 'Sex'] = 0
traindata.loc[traindata['Sex'] == 'female', 'Sex'] = 1
# .fillna() 为数据填充函数 用括号里面的东西填充
traindata['Embarked'] = traindata['Embarked'].fillna('S')
traindata.loc[traindata['Embarked'] == 'S', 'Embarked'] = 0
traindata.loc[traindata['Embarked'] == 'C', 'Embarked'] = 1
traindata.loc[traindata['Embarked'] == 'Q', 'Embarked'] = 2
# the columns we'll use to predict the target
all_variables = ['PassengerID', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked']
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
# traindata, testdata = traindata[predictors], testdata[predictors]
alg = LinearRegression()
kf = KFold(n_splits=3, random_state=1)
predictions = []
for train_index, test_index in kf.split(traindata):
# print(train_index, test_index)
train_predictors = (traindata[predictors].iloc[train_index, :])
train_target = traindata['Survived'].iloc[train_index]
alg.fit(train_predictors, train_target)
test_predictions = alg.predict(traindata[predictors].iloc[test_index, :])
predictions.append(test_predictions)
# print(type(predictions))
predictions = np.concatenate(predictions, axis=0) #<class 'numpy.ndarray'>
# print(type(predictions))
predictions[predictions > 0.5] = 1
predictions[predictions < 0.5] = 1
accuracy = sum(predictions[predictions == traindata['Survived']]/len(predictions))
print(accuracy) # 0.3838383838383825 def linear_regression_train(traindata, trainlabel, testdata):
# the columns we'll use to predict the target
all_variables = ['PassengerID', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked']
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
traindata, testdata = traindata[predictors], testdata[predictors]
print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = LinearRegression()
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正确率为 %s%%" % test_accuracy) # 正确率为 37.63003367180264%
# res = clf.predict(testdata) if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
# print(traindata.shape[1]) # 11
linear_regression_train(traindata, trainlabel, testdata)
# linear_regression_test(traindata, trainlabel, testdata)
2,逻辑回归模型
逻辑回归也是只选择了几个比较全的特征,准确率还好,达到了: 81.56424581005587%。代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier warnings.filterwarnings('ignore') def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 为数据填充函数 用括号里面的东西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata def logistic_regression_train(traindata, trainlabel, testdata):
# the columns we'll use to predict the target
all_variables = ['PassengerID', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked']
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = LogisticRegression()
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正确率为 %s%%" % test_accuracy) # 正确率为 81.56424581005587%
# res = clf.predict(testdata) if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
logistic_regression_train(traindata, trainlabel, testdata)
3,随机森林模型
我们依旧选择和上面相同的特征,使用随机森林来做,准确率为:81.56424581005587%。效果还行,不过也只是和逻辑回归一样,代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier warnings.filterwarnings('ignore') def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 为数据填充函数 用括号里面的东西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata def random_forestclassifier_train(traindata, trainlabel, testdata):
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
traindata, testdata = traindata[predictors], testdata[predictors]
# print(traindata.shape, trainlabel.shape, testdata.shape) # (891, 7) (891,) (418, 7)
# print(testdata.info())
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf = RandomForestClassifier(random_state=1, n_estimators=100,
min_samples_split=4, min_samples_leaf=2)
# training the algorithm using the predictors and target
clf.fit(trainSet, trainlabel)
test_accuracy = clf.score(testSet, testlabel) * 100
print("正确率为 %s%%" % test_accuracy) # 正确率为 81.56424581005587% if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
random_forestclassifier_train(traindata, trainlabel, testdata)
4,集成学习模型
这里简单的集成GradientBoostingClassifier和LogisticRegression 两种算法。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import KFold, train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.ensemble import GradientBoostingClassifier
import re warnings.filterwarnings('ignore') # A function to get the title from a name
def get_title(name):
# use a regular expression to search for a title
title_search = re.search('([A-Za-z]+)\.', name)
# if the title exists, extract and return it
if title_search:
return title_search.group(1)
return '' def load_dataset(trainfile, testfile):
train = pd.read_csv(trainfile)
test = pd.read_csv(testfile)
train['Age'] = train['Age'].fillna(train['Age'].median())
test['Age'] = test['Age'].fillna(test['Age'].median())
# replace all the occurences of male with the number 0
train.loc[train['Sex'] == 'male', 'Sex'] = 0
train.loc[train['Sex'] == 'female', 'Sex'] = 1
test.loc[test['Sex'] == 'male', 'Sex'] = 0
test.loc[test['Sex'] == 'female', 'Sex'] = 1
# .fillna() 为数据填充函数 用括号里面的东西填充
train['Embarked'] = train['Embarked'].fillna('S')
train.loc[train['Embarked'] == 'S', 'Embarked'] = 0
train.loc[train['Embarked'] == 'C', 'Embarked'] = 1
train.loc[train['Embarked'] == 'Q', 'Embarked'] = 2
test['Embarked'] = test['Embarked'].fillna('S')
test.loc[test['Embarked'] == 'S', 'Embarked'] = 0
test.loc[test['Embarked'] == 'C', 'Embarked'] = 1
test.loc[test['Embarked'] == 'Q', 'Embarked'] = 2
test['Fare'] = test['Fare'].fillna(test['Fare'].median())
# generating a familysize column 是指所有的家庭成员
train['FamilySize'] = train['SibSp'] + train['Parch']
test['FamilySize'] = test['SibSp'] + test['Parch'] # the .apply method generates a new series
train['NameLength'] = train['Name'].apply(lambda x: len(x))
test['NameLength'] = test['Name'].apply(lambda x: len(x)) titles_train = train['Name'].apply(get_title)
titles_test = test['Name'].apply(get_title)
title_mapping = {
'Mr': 1,
'Miss': 2,
'Mrs': 3,
'Master': 4,
'Rev': 6,
'Dr': 5,
'Col': 7,
'Mlle': 8,
'Ms': 2,
'Major': 7,
'Don': 9,
'Countess': 10,
'Mme': 8,
'Jonkheer': 10,
'Sir': 9,
'Dona': 9,
'Capt': 7,
'Lady': 10,
}
for k, v in title_mapping.items():
titles_train[titles_train == k] = v
train['Title'] = titles_train
for k, v in title_mapping.items():
titles_test[titles_test == k] = v
test['Title'] = titles_test
# print(pd.value_counts(titles_train))
traindata, trainlabel = train.drop('Survived', axis=1), train['Survived'] # train.pop('Survived')
testdata = test
print(traindata.shape, trainlabel.shape, testdata.shape)
# (891, 11) (891,) (418, 11)
return traindata, trainlabel, testdata def emsemble_model_train(traindata, trainlabel, testdata):
# the algorithms we want to ensemble
# we're using the more linear predictors for the logistic regression,
# and everything with the gradient boosting classifier
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3),
['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked', ]],
[LogisticRegression(random_state=1),
['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked', ]]
]
# initialize the cross validation folds
kf = KFold(n_splits=3, random_state=1)
predictions = []
for train_index, test_index in kf.split(traindata):
# print(train_index, test_index)
full_test_predictions = []
for alg, predictors in algorithms:
train_predictors = (traindata[predictors].iloc[train_index, :])
train_target = trainlabel.iloc[train_index]
alg.fit(train_predictors, train_target)
test_predictions = alg.predict(traindata[predictors].iloc[test_index, :])
full_test_predictions.append(test_predictions)
# use a simple ensembling scheme
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
test_predictions[test_predictions <= 0.5] = 0
test_predictions[test_predictions >= 0.5] = 1
predictions.append(test_predictions)
predictions = np.concatenate(predictions, axis=0)
# compute accuracy bu comparing to the training data
accuracy = sum(predictions[predictions == trainlabel]) / len(predictions)
print(accuracy) def emsemble_model_train(traindata, trainlabel, testdata):
# the algorithms we want to ensemble
# we're using the more linear predictors for the logistic regression,
# and everything with the gradient boosting classifier
predictors = ['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked', ]
traindata, testdata = traindata[predictors], testdata[predictors]
trainSet, testSet, trainlabel, testlabel = train_test_split(traindata, trainlabel,
test_size=0.2, random_state=12345)
# initialize our algorithm class
clf1 = GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3)
clf2 = LogisticRegression(random_state=1)
# training the algorithm using the predictors and target
clf1.fit(trainSet, trainlabel)
clf2.fit(trainSet, trainlabel)
test_accuracy1 = clf1.score(testSet, testlabel) * 100
test_accuracy2 = clf2.score(testSet, testlabel) * 100
print(test_accuracy1, test_accuracy2) # 78.77094972067039 80.44692737430168
print("正确率为 %s%%" % ((test_accuracy1+test_accuracy2)/2)) # 正确率为 79.60893854748603% if __name__ == '__main__':
trainfile = 'data/titanic_train.csv'
testfile = 'data/test.csv'
traindata, trainlabel, testdata = load_dataset(trainfile, testfile)
emsemble_model_train(traindata, trainlabel, testdata)
当然,对于集成学习中,集成集中算法,也可以使用赋予权重比的方式。具体可以参考:
Python机器学习笔记 集成学习总结
这里不再多赘述。
我的GitHub地址:https://github.com/LeBron-Jian/Kaggle-learn
参考文献:
https://www.jianshu.com/p/ee91d8880bbd
https://www.jianshu.com/p/e79a8c41cb1a
https://www.cnblogs.com/python-1807/p/10645170.html
https://blog.csdn.net/han_xiaoyang/article/details/49797143
Kaggle入门——泰坦尼克号生还者预测的更多相关文章
- kaggle入门--泰坦尼克号之灾(手把手教你)
作者:炼己者 具体操作请看这里-- https://www.jianshu.com/p/e79a8c41cb1a 大家也可以看PDF版,用jupyter notebook写的,视觉效果上感觉会更棒 链 ...
- 数据挖掘竞赛kaggle初战——泰坦尼克号生还预测
1.题目 这道题目的地址在https://www.kaggle.com/c/titanic,题目要求大致是给出一部分泰坦尼克号乘船人员的信息与最后生还情况,利用这些数据,使用机器学习的算法,来分析预测 ...
- Kaggle之泰坦尼克号幸存预测估计
上次已经讲了怎么下载数据,这次就不说废话了,直接开始.首先导入相应的模块,然后检视一下数据情况.对数据有一个大致的了解之后,开始进行下一步操作. 一.分析数据 1.Survived 的情况 train ...
- kaggle入门项目:Titanic存亡预测 (一)比赛简介
自从入了数据挖掘的坑,就在不停的看视频刷书,但是总觉得实在太过抽象,在结束了coursera上Andrew Ng 教授的机器学习课程还有刷完一整本集体智慧编程后更加迷茫了,所以需要一个实践项目来扎实之 ...
- Kaggle入门
Kaggle入门 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中 ...
- Kaggle入门——使用scikit-learn解决DigitRecognition问题
Kaggle入门--使用scikit-learn解决DigitRecognition问题 @author: wepon @blog: http://blog.csdn.net/u012162613 1 ...
- Survival on the Titanic (泰坦尼克号生存预测)
>> Score 最近用随机森林玩了 Kaggle 的泰坦尼克号项目,顺便记录一下. Kaggle - Titanic: Machine Learning from Disaster On ...
- Kaggle 入门资料
kaggle入门之如何使用 - CSDN博客 http://blog.csdn.net/mdjxy63/article/details/78221955 kaggle比赛之路(一) -- 新手注册账号 ...
- Kaggle 入门题-泰坦尼克号灾难存活预测
这个题目的背景概况来讲就是基于泰坦尼克号这个事件,然后大量的人员不幸淹没在这个海难中,也有少部分人员在这次事件之中存活,然后这个问题提供了一些人员的信息如姓名.年龄.性别.票价,所在客舱等等一些信息, ...
随机推荐
- springboot创建
1.点击File----->New----->Project... 2.输入MAVEN,组名.包名等相关参数 3.选择SpringBoot版本,选择项目需要依赖的相关骨架包 4.设置 ...
- C# 基础知识系列- 6 Lambda表达式和Linq简单介绍
前言 C#的lambda和Linq可以说是一大亮点,C#的Lambda无处不在,Linq在数据查询上也有着举足轻重的地位. 那么什么是Linq呢,Linq是 Language Intergrated ...
- thinkphp5源码剖析系列1-类的自动加载机制
前言 tp5想必大家都不陌生,但是大部分人都停留在应用的层面,我将开启系列随笔,深入剖析tp5源码,以供大家顺利进阶.本章将从类的自动加载讲起,自动加载是tp框架的灵魂所在,也是成熟php框架的必备功 ...
- 在操作Git Bash时出现的问题
参考博客:https://blog.csdn.net/weixin_44394753/article/details/91410463 1.问题1 $ git remote add origin gi ...
- 3-1. 基于epoll架构的视频采集端设计
精通epoll架构 epoll:Linux中最优秀的多路复用机制! 与select .poll区别 1.select和poll没有太大区别,除了select有文件描述符限制(1024个).select ...
- Three中的动画实现-[three.js]
Table Of Content 动画原理 js中动画实现原理setInterval js中动画实现新方法requestAnimationFrame 一个示例 动画原理 动画的本质实际上就是快速地不断 ...
- 记录一次简单的springboot发送邮件功能
场景:经常在我们系统中有通过邮件功能找回密码,或者发送生日祝福等功能,今天记录下springboot发送邮件的简单功能 1.引入maven <!-- 邮件开发--><dependen ...
- 如何优雅的将文件转换为字符串(环绕执行模式&行为参数化&函数式接口|Lambda表达式)
首先我们讲几个概念: 环绕执行模式: 简单的讲,就是对于OI,JDBC等类似资源,在用完之后需要关闭的,资源处理时常见的一个模式是打开一个资源,做一些处理,然后关闭资源,这个设置和清理阶段类似,并且会 ...
- djangoRestFrameWork的小知识
djangoRestFrameWork的小知识 重写序列化器的save方法 有时候,.create()和.update()方法名称可能没有意义.例如,在联系表格中,我们可能没有创建新实例,而是发送了电 ...
- go中的面向对象总结
我们总结一下前面看到的:Go 没有类,而是松耦合的类型.方法对接口的实现. OO 语言最重要的三个方面分别是:封装,继承和多态,在 Go 中它们是怎样表现的呢? 封装(数据隐藏):和别的 OO 语言有 ...