分布式文件系统与HDFS
HDFS,它是一个虚拟文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
|
模块名称 |
模块介绍 |
|
Common |
其他组件的公共依赖模块 |
|
HDFS |
分布式存储模块提供高吞吐量的数据访问 |
|
Mapreduce |
分布式计算模块 |
|
Yarn |
作业调度和集群资源管理模块 |
思考!!!!!!!!! 什么是大数据? 为什么对于网络要求越来越高? 1.信息量越来越大 2.用网设备多 3.响应时间要短 01.web的响应时间 02.猜你喜欢 ==> 后台计算(大数据) 大数据技术是海量数据的处理和计算的技术 Nginx Tomcat 数据库 普通运维 大数据运维:特别的维护大数据组件(多、杂、难) 1、大数据组件的安装 2、大数据架构 3、大数据的配置文件及原理有一定的了解 Hadoop Zookeeper Hive Hbase Flume Kafka Spark Flink Mahout。。。 分布式原理 => 典型的是hadoop
Hadoop是大数据的基础组件。基本上所有的其他组件都依赖于Hadoop
简单的数据处理是直接将数据加载到内存,进行计算
然而数据量到内存瓶颈,会OOM(out of memory)
分布式存储:
将数据以块为单位切割,并发送到所有的分布式存储节点
但是,数据对于用户来说,显示为单一的文件
相当于raid1 + raid0,以软件形式实现的,不需要额外的硬件维护
分布式计算:
多台主机的算力,协同在一起,共同提供计算
大数据平台建设:
搭建的两个设想:
1、用桥接模式,每人贡献一个虚拟的节点。分组组成多个集群。
2、用NAT模式,每人都搭建一个虚拟的集群。
我们可以使用NAT模式,指定三台虚拟机,每台2G
环境搭建:
1、修改ip:
hadoop01 10.0.0.101 hadoop02 10.0.0.102 hadoop03 10.0.0.103
2、修改hosts文件
10.0.0.101 hadoop01 10.0.0.102 hadoop02 10.0.0.103 hadoop03
修改完之后记得分发 三台上都要
3、安装jdk(三台都要)
1)解压 /soft 2)环境变量 /etc/profile
export JAVA_HOME=/soft/jdk1.8.0_131 export PATH=$PATH:$JAVA_HOME/bin
3)source
source /etc/profile
4)验证
java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
5)将/soft和/etc/profile发送到其他节点
scp -r /soft/ 10.0.0.102:/ scp -r /soft/ 10.0.0.103:/ scp /etc/profile 10.0.0.102:/etc scp /etc/profile 10.0.0.103:/etc
4、Hadoop安装
1)分配节点:
master ==> hadoop01 slave节点 => hadoop01-hadoop03
2)安装
1、解压+环境变量
tar -xzvf ~/hadoop-2.7.3.tar.gz -C /soft/ export HADOOP_HOME=/soft/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2、配置四个配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
slaves
配置文件所在目录为/soft/hadoop-2.7.3/etc/hadoop
vi hadoop-env.sh
#第25行改为
export JAVA_HOME=/soft/jdk1.8.0_131
vi core-site.xml ###将之前的文件清空并粘贴如下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 这个配置意思是设置master节点信息 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 这个配置意思是设置hadoop的工作目录,包括索引数据和真实数据的存储位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/soft/hadoop-2.7.3/data/tmp</value>
</property>
</configuration>
vi hdfs-site.xml ### 将之前的文件清空并粘贴如下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置hdfs的块存储默认副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 配置2nn的节点位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
</configuration>
vi slaves ### 将之前的文件清空并粘贴如下内容
hadoop01
hadoop02
hadoop03
3、分发hadoop包和环境变量将hadoop01上的hadoop整个文件夹所有文件复制到其他两台机子上 4、在保证之前配置文件全部ok的前提下,格式化文件系统
格式化hdfs文件系统(只需一次) [centos@hadoop01 ~]$ hdfs namenode -format
5 配置hadoop01到hadoop[01-03]的免密登录
ssh-keygen -t rsa ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03
6、在hadoop01上启动所有进程
start-dfs.sh
7、正常条件下 用jps查看进程
[hadoop01] 18946 DataNode 18843 NameNode 19196 Jps [hadoop02] 10194 Jps 10125 DataNode [hadoop03] 17680 SecondaryNameNode 17603 DataNode 17742 Jps
关闭防火墙
systemctl stop firewalld systemctl disable firewalld
HDFS相关命令
启动hdfs //在master启动 start-dfs.sh 在hdfs上创建数据(文件夹) hdfs dfs -mkdir xxx hdfs dfs -touchz 1.txt 改:hdfs文件不支持随意改动,但是文件可以追加 hdfs dfs -appendToFile slaves /1.txt 本地文件上传到hdfs hdfs dfs -put slaves / hdfs文件下载到本地 hdfs dfs -get /slaves . 查看hdfs数据 hdfs dfs -ls / hdfs dfs -cat /slaves
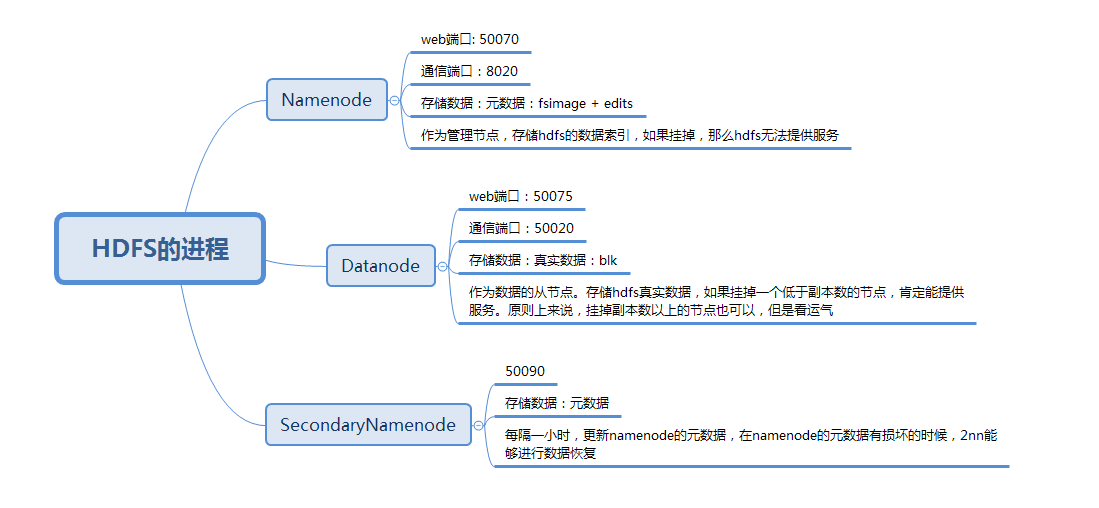
HDFS进程:
Namenode //名称节点 //存放元数据(索引数据):fsimage + edits
//web端口 50070
//集群通信端口 8020
Datanode //数据节点 //存放真实的块数据:128M一次切割
//web端口 50075
//集群通信端口 50020
Seondarynamenode //辅助名称节点 //辅助namenode进行元数据的更新
//web端口 50090
//集群通信端口 50090
在存储时候,真实数据存储在datanode上
注意: hdfs进程详解
|
进程名称 |
进程详解 |
|
Namenode |
是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。 |
|
Datanode |
提供真实文件数据的存储服务。 |
|
SecondaryNamenode |
辅助Namenode保存元数据,提供元数据的恢复 |
hdfs相关端口说明
hadoop守护进程一般同时运行RPC和HTTP两个服务器,RPC服务器支持守护进程进的通信, HTTP服务器则提供与用户交互的Web页面
|
进程名称 |
RPC端口 |
HTTP端口 |
|
Namenode |
8020 |
50070 |
|
Datanode |
50020 |
50075 |
|
SecondaryNamenode |
50090 |
50090 |
小要求:把jdk安装包(.tar.gz)传到hdfs上,并查看块数据(分了几个块?一个块多大?)
hdfs dfs mkdir / hdfs dfs put jdk-8u131-linux-x64.tar.gz / 得出结论,数据是按照128M进行切块存储,每个块单独作为存储单位
HDFS中的真实数据:
镜像数据:以fsimage开头,存放其中包含 HDFS文件系统的所有目录和文件信息 编辑日志:以edits开头,存放用户对文件的写操作 所以,一个文件,在经历过编辑日志里面记录的所有操作后才会形成fsimage里面的一个inode 在默认条件下,edits和fsimage会周期性的每一小时,进行一次更新,形成最新的数据,保证hdfs的元数据的最新
回收站:
生产环境下务必要配置(后悔药)
<!-- 在core-site.xml中添加配置 -->
<property>
<!-- 配置回收站的存储超时时长 -->
<name>fs.trash.interval</name>
<value>1440</value>
</property>
清除回收站超时未删除的文件
[centos@hadoop01 ~]$ hdfs dfs -expunge
HDFS中的不成文规定:
1M数据 = 1x1024x1024 = 1048576个 ====> 对应namenode内存1000M 禁止存储大量小文件 如果生成了,怎么处理?
分布式文件系统与HDFS的更多相关文章
- 大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
分布式文件系统即是网络中多台计算机组合在一起提供一个统一存储及管理的系统. Hadoop提供了一个文件系统接口和多个分布式文件系统实现,其中比较重要的就是HDFS(Hadoop Distributed ...
- 初识hadoop之分布式文件系统(HDFS)
Hadoop常用发行版: Apache Hadoop CDH Cloudera Distributed Hadoop HDP Hortonworks Data Platfrom 分布式文件系统(H ...
- Hadoop分布式文件系统(HDFS)详解
HDFS简介: 当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区 (partition)并存储到若干台单独的计算机上.管理网络中跨多台计算机存储的文件系统成为分布式文件系统 (D ...
- Hadoop分布式文件系统(HDFS)设计
Hadoop分布式文件系统是设计初衷是可靠的存储大数据集,并且使应用程序高带宽的流式处理存储的大数据集.在一个成千个server的大集群中,每个server不仅要管理存储的这些数据,而且可以执行应用程 ...
- 分布式文件系统:HDFS
学习Hadoop,两个东西肯定是绕不过,MapReduce和HDFS,上一篇博客介绍了MapReduce的处理流程,这一篇博客就来学习一下HDFS. HDFS是一个分布式的文件系统,就是将多台机器的存 ...
- Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上.管理着跨计算机网络存储的文件系统称为分布式文件系统.Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Spark环境搭建(一)-----------HDFS分布式文件系统搭建
下载的压缩文件放在~/software/ 解压安装在~/app/ 一:分布式文件系统搭建HDFS 1,下载Hadoop HDFS环境搭建 使用版本:hadoop-2.6.0-cdh5.7. ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
随机推荐
- 吴裕雄--天生自然GPU配置:查看本机显卡是否支持GPU
NVIDIA的GF8级别以上的显卡才能支持physx物理加速(即GPU加速),ATI的显卡不支持. 打开:设备管理器,点击:显示适配器
- Python程序中的线程操作(线程池)-concurrent模块
目录 Python程序中的线程操作(线程池)-concurrent模块 一.Python标准模块--concurrent.futures 二.介绍 三.基本方法 四.ProcessPoolExecut ...
- 题解-------CF1304E 1-Trees and Queries
传送门 题目大意 给你一棵无根树,然后询问Q次,每次把点$x$和点$y$连接,问你从点$a$到点$b$是否有一条长度为$k$的简单路径,每次询问完后会把新添加的边删除. 思路:树上LCA 题目跟201 ...
- android仿网易云音乐引导页、仿书旗小说Flutter版、ViewPager切换、爆炸菜单、风扇叶片效果等源码
Android精选源码 复现网易云音乐引导页效果 高仿书旗小说 Flutter版,支持iOS.Android Android Srt和Ass字幕解析器 Material Design ViewPage ...
- 4. 监控利器nagios手把手企业级实战第三部
1.nagios图形监控显示和管理服务器 虽然能显示,能报警.但是我们企业工作中需要一个历史趋势图. nagios只开放核心,插件是单独的形式,图像也一样,是插件或者整合的方式.所以可能看起来很多,这 ...
- screen 用法
登陆Linux服务器跑程序, 担心ssh连接被中断后,导致跑了一半的任务被强制终止. 一个比较好的办法是使用 screen 命令, 下面是使用说明 类型 命令 备注 创建 screen 查看 scre ...
- 理解Java中的对象,变量和方法
1.对象的创建和销毁 1.1 对象的创建 这里只介绍创建对象与构造方法的关系 (1).每实例化一个对象就会自动调用一次构造方法,实质上这个过程就是创建对象的过程,准确的说,在Java语言中使用new操 ...
- SpringMVC访问出错No converter found for return value of type
在使用SSM整合的时候,spring mvc 添加@ResponseBody的时候,正常情况下都会返回json的.但是又的时候如果没有配置好的话,如果想要返回Map的json对象会报:No conve ...
- 爬虫笔记(二)——浏览器的模拟(Headers属性)
有的时候,我们无法爬取一些网页,会出现403错误,因为这些网页为了防止别人恶意采集其信息所以进行了一些反爬虫的设置.那么如果我们向爬取这些网页的信息,应该怎么办呢? 可以设置一些Headers信息,模 ...
- mysql免安装版 win10
1.在官网中下载免安装版:https://dev.mysql.com/downloads/mysql/ 2.解压下载后的文件,新建 data 文件夹和 my.ini 文件 3.打开 my.ini 文 ...