Volcano火山:容器与批量计算的碰撞
【摘要】 Volcano是基于Kubernetes构建的一个通用批量计算系统,它弥补了Kubernetes在“高性能应用”方面的不足,支持TensorFlow、Spark、MindSpore等多个领域框架,帮助用户通过Kubernetes构建统一的容器平台。
Kubernetes 是当前非常流行的容器编排框架,在其发展早期重点以微服务类应用为主。随着Kuberentes的用户越来越多,更多的用户希望在Kubernetes上运行BigData和AI框架,如Spark、TensorFlow等以构建统一的容器平台。但在Kubernetes运行这些高性能应用时,Kubernetes的默认调度器无法满足高性能应用的需求,例如:公平调度、优先级、队列等高级调度功能。由于Kubernetes的默认调度器是基于Pod进行调度,虽然在1.17中引入了调度框架,但仍无法满足高性能应用对作业级调度的需求。
容器批量计算平台Volcano
针对云原生场景下的高性能应用场景,华为云容器团队推出了Volcano项目。Volcano是基于Kubernetes构建的一个通用批量计算系统,它弥补了Kubernetes在“高性能应用”方面的不足,支持TensorFlow、Spark、MindSpore等多个领域框架,帮助用户通过Kubernetes构建统一的容器平台。Volcano作为容器调度系统,不仅包括了作业调度,还包含了作业生命周期管理、多集群调度、命令行、数据管理、作业视图及硬件加速等功能。
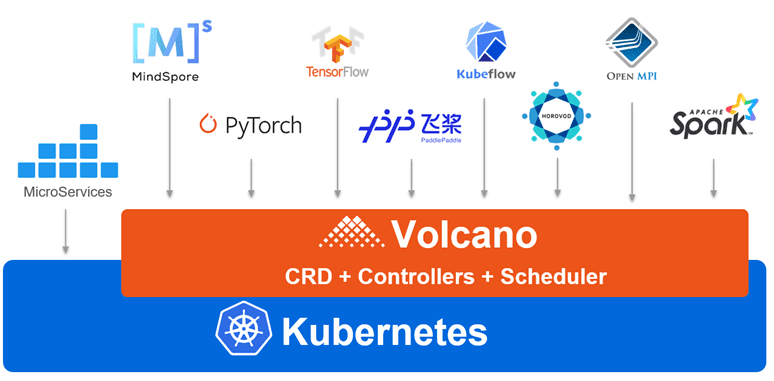
而在调度方面,Volcano 又对场景进行了细分、归类,并提供了相关的方案及算法;同时也为这些功能提供了调度框架,方便用户对调度器进行扩展。对于分布式计算或是并行计算来说,根据场景和作业属性的不同,也可以对其进行细分;在 《并行计算导论》 中将并行计算大致分为三类:
- 简单的并行
简单的并行指多个子任务(tasks)之间没有通信也不需要同步,可以完全的并行的执行。比较著名的例子应该就属MapReduce了,它的两个阶段都属于这种类型:mapper任务在执行时并不会彼此通信同步运行状态;另一个常见的例子是蒙特·卡罗方法 ,各个子任务在计算随机数时也无需彼此通信、同步。由于这种并行计算有比较广泛的应用,例如 数据处理、VatR 等,针对不同的场景也产生了不同的调度框架,例如 Hadoop、DataSynapse 和 Symphony。同时,由于子任务之间无需信息和同步,当其中某几个计算节点(workers)被驱逐后,虽然作业的执行时间可能会变长,但整个作业仍可以顺利完成;而当计算节点增加时,作业的执行时间一般都会缩短。因此,这种作业也常常被称作 Elastic Job。
- 复杂的并行
复杂的并行作业指多个子任务 (tasks) 之间需要同步信息来执行复杂的并行算法,单个子任务无法完成部分计算。最近比较有名的例子应该算是 Tensorflow 的 "ps-work模式" 和 ring all-reduce 了,各个子任务之间需要大量的数据交换和信息同步,单独的子任务无法独立完成。正是由于作业的这种属性,对作业调度平台也提出了相应的调度要求,比如 gang-scheduling、作业拓扑等。由于子任务之间需要彼此通信,因此作业在启动后无法动态扩展子任务,在没有checkpoint的情况下,任一子任务失败或驱逐,整个作业都需要重启,这种作业也常常被称作 Batch Job,传统的HPC场景多属于这种类型的并行作业,针对这种场景的调度平台为 Slurm/PBS/SGE/HTCondor 等。
- 流水线并行
流水线并行是指作业的多个子任务之间存在依赖关系,但不需要前置任务完全结束后再开始后续的任务;比如 Hadoop 里有相应的研究:在 Map 没有完全结束的时候就部分开始 Reduce 阶段,从而提高任务的并行度,提高整体的运行性能。符合这种场景的应用相对来说比较少,一般都做为性能优化;因此没有针对这种场景的作业管理平台。需要区分一下工作流与流水线并行,工作流一般指作业之间的依赖关系,而流水线并行一般指作业内部多个任务之间的依赖。由于工作流中的作业差异比较大,很难提前开始后续步骤。
值得一提的是"二次调度"。由于简单并行的作业一般会有大量的子任务,而且每个子任务所需要的资源相对一致,子任务之间也没有通信和同步;使得资源的复用率相对比较高,因此二次调度在这种场景下能发挥比较大的作用;Hadoop的YARN,Symphony的EGO都属于这种类型。但是在面对复杂并行的作业时,二次调度就显得有也吃力;复杂并行作业一般并没有太多的子任务,子任务之间还经常需要同时启动,子任务之间的通信拓扑也可能不同 (e.g. ps/worker, mpi),而且作业与作业之间对资源的需求差异较大,因此导致了资源的复用率较低。
虽然针对两种不同并行作业类型有不同的作业、资源管理平台,但是根本的目标都是为作业寻找最优的资源;因此,Volcano一直以支持以多种类型的作业为目标进行设计。目前,Volcano可以同时支持 Spark、TensorFlow和MPI等多种类型的作业。
常见调度场景
1.组调度 (Gang-scheduling)
运行批处理作业(如Tensorflow/MPI)时,必须协调作业的所有任务才能一起启动;否则,将不会启动任何任务。如果有足够的资源并行运行作业的所有任务,则该作业将正确执行; 但是,在大多数情况下,尤其是在prem环境中,情况并非如此。在最坏的情况下,由于死锁,所有作业都挂起。其中每个作业只成功启动了部分任务,并等待其余任务启动。
2.作业级的公平调度 (Job-based Fair-share)
当运行多个弹性作业(如流媒体)时,需要公平地为每个作业分配资源,以满足多个作业竞争附加资源时的SLA/QoS要求。在最坏的情况下,单个作业可能会启动大量的pod资源利用率低, 从而阻止其他作业由于资源不足而运行。为了避免分配过小(例如,为每个作业启动一个Pod),弹性作业可以利用协同调度来定义应该启动的Pod的最小可用数量。 超过指定的最小可用量的任何pod都将公平地与其他作业共享集群资源。
3.队列 (Queue)
队列还广泛用于共享弹性工作负载和批处理工作负载的资源。队列的主要目的是:
- 在不同的“租户”或资源池之间共享资源
- 为不同的“租户”或资源池支持不同的调度策略或算法
这些功能可以通过层次队列进一步扩展,在层次队列中,项目被赋予额外的优先级,这将允许它们比队列中的其他项目“跳转”。在kube批处理中,队列被实现为集群范围的CRD。 这允许将在不同命名空间中创建的作业放置在共享队列中。队列资源根据其队列配置(kube batch#590)按比例划分。当前不支持分层队列,但正在进行开发。
集群应该能够在不减慢任何操作的情况下处理队列中的大量作业。其他的HPC系统可以处理成百上千个作业的队列,并随着时间的推移缓慢地处理它们。如何与库伯内特斯达成这样的行为是一个悬而未决的问题。支持跨越多个集群的队列可能也很有用,在这种情况下,这是一个关于数据应该放在哪里以及etcd是否适合存储队列中的所有作业或pod的问题。
4.面向用户的, 跨队列的公平调度 (Namespace-based fair-share Cross Queue)
在队列中,每个作业在调度循环期间有几乎相等的调度机会,这意味着拥有更多作业的用户有更大的机会安排他们的作业,这对其他用户不公平。 例如,有一个队列包含少量资源,有10个pod属于UserA,1000个pod属于UserB。在这种情况下,UserA的pod被绑定到节点的概率较小。
为了平衡同一队列中用户之间的资源使用,需要更细粒度的策略。考虑到Kubernetes中的多用户模型,使用名称空间来区分不同的用户, 每个命名空间都将配置一个权重,作为控制其资源使用优先级的手段。
5.基于时间的公平调度 (Fairness over time)
对于批处理工作负载,通常不要求在某个时间点公平地分配资源,而是要求在长期内公平地分配资源。例如,如果有用户提交大作业,则允许用户(或特定队列)在一定时间内使用整个集群的一半, 这是可以接受的,但在下一轮调度(可能是作业完成后数小时)中,应惩罚此用户(或队列)而不是其他用户(或队列)。在 HTCondor 中可以看到如何实现这种行为的好例子。
6.面向作业的优先级调度 (Job-based priority)
Pod优先级/抢占在1.14版本中被中断,它有助于确保高优先级的pod在低优先级的pod之前绑定。不过,在job/podgroup级别的优先级上仍有一些工作要做,例如高优先级job/podgroup应该尝试以较低优先级抢占整个job/podgroup,而不是从不同job/podgroup抢占几个pod。
7.抢占 (Preemption & Reclaim)
通过公平分享来支持借贷模型,一些作业/队列在空闲时会过度使用资源。但是,如果有任何进一步的资源请求,资源“所有者”将“收回”。 资源可以在队列或作业之间共享:回收用于队列之间的资源平衡,抢占用于作业之间的资源平衡。
8.预留与回填 (Reservation & Backfill)
当一个请求大量资源的“巨大”作业提交给kubernetes时,当有许多小作业在管道中时,该作业可能会饿死,并最终根据当前的调度策略/算法被杀死。为了避免饥饿, 应该有条件地为作业保留资源,例如超时。当资源被保留时,它们可能会处于空闲和未使用状态。为了提高资源利用率,调度程序将有条件地将“较小”作业回填到那些保留资源中。 保留和回填都是根据插件的反馈触发的:volcano调度器提供了几个回调接口,供开发人员或用户决定哪些作业应该被填充或保留。
Volcano 调度框架
Volcano调度器通过作业级的调度和多种插件机制来支持多种作业;Volcano的插件机制有效的支撑了针对不同场景算法的落地,从早期的gang-scheduling/co-scheduling,到后来各个级别的公平调度。下图展示了Volcano调度器的总体架构:
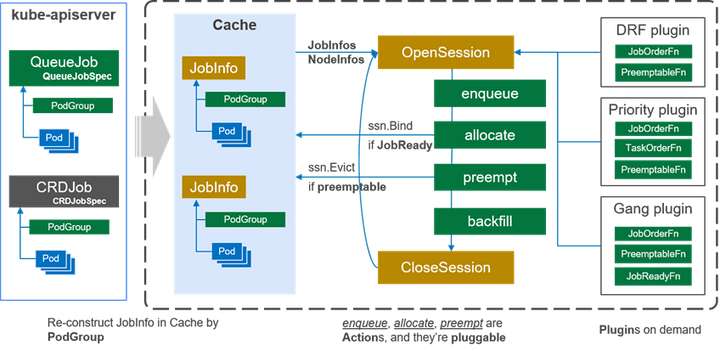
Cache 缓存了集群中Node和Pod信息,并根据PodGroup的信息重新构建 Job (PodGroup) 和 Task (Pod) 的关系。由于在分布式系统中很难保证信息的同步,因此调度器经常以某一时间点的集群快照进行调度;并保证每个调度周期的决定是一致的。在每个调度周期中,Volcano 通过以下几个步骤派发作业:
- 在每个调度周期都会创建一个Session对象,用来存储当前调度周期的所需的数据,例如,Cache 的一个快照。当前的调度器中仅创建了一个Session,并由一个调度线程执行;后续将会根据需要创建多个Session,并为每个Session分配一个线程进行调度;并由Cache来解决调度冲突。
- 在每个调度周期中,会按顺序执行 OpenSession, 配置的多个动作(action)和CloseSession。在 OpenSession中用户可以注册自定义的插件,例如gang、 drf,这些插件为action提供了相应算法;多个action根据配置顺序执行,调用注册的插件进行调度;最后,CloseSession负责清理中间数据。
(1) action是第一级插件,定义了调度周期内需要的各个动作;默认提供 enqueue、allocate、 preempt和backfill四个action。以allocate为例,它定义了调度中资源分配过程:根据 plugin 的 JobOrderFn 对作业进行排序,根据NodeOrderFn对节点进行排序,检测节点上的资源是否满足,满足作业的分配要求(JobReady)后提交分配决定。由于action也是基于插件机制,因此用户可以重新定义自己的分配动作,例如 基于图的调度算法firmament。
(2) plugin是第二级插件,定义了action需要的各个算法;以drf插件为例,为了根据dominant resource进行作业排序,drf插件实现了 JobOrderFn函数。JobOrderFn函数根据 drf 计算每个作业的share值,share值较低代表当前作业分配的资源较少,因此会为其优先分配资源;drf插件还实现了EventHandler回调函数,当作业被分配或抢占资源后,调度器会通知drf插件来更新share值。
- Cache 不仅提供了集群的快照,同时还提供了调度器与kube-apiserver的交互接口,调度器与kube-apiserver之间的通信也都通过Cache来完成,例如 Bind。
- 同时,为了支持上面这些场景,Volcano的调度器还增加了多个Pod状态以提高调度的性能:
- Pending: 当Pod被创建后就处于Pending状态,等待调度器对其进行调度;调度的主要目的也是为这些Pending的Pod寻找最优的资源
- Allocated: 当Pod被分配空闲资源,但是还没有向kube-apiserver发送调度决策时,Pod处于Allocated状态。 Allocated状态仅存在于调度周期内部,用于记录Pod和资源分配情况。当作业满足启动条件时 (e.g. 满足minMember),会向kube-apiserver提交调度决策。如果本轮调度周期内无法提交调度决策,由状态会回滚为Pending状态。
- Pipelined: 该状态与Allocated状态相似,区别在于处于该状态的Pod分配到的资源为正在被释放的资源 (Releasing)。该状态主要用于等待被抢占的资源释放。该状态是调度周期中的状态,不会更新到kube-apiserver以减少通信,节省kube-apiserver的qps。
- Binding: 当作业满足启动条件时,调度器会向kube-apiserver提交调度决策,在kube-apiserver返回最终状态之前,Pod一直处于Binding状态。该状态也保存在调度器的Cache之中,因此跨调度周期有效。
- Bound: 当作业的调度决策在kube-apiserver确认后,该Pod即为Bound状态。
- Releasing: Pod等待被删除时即为Releasing状态。
- Running, Failed, Succeeded, Unknown: 与Pod的现有含义一致。
状态之间根据不同的操作进行转换,见下图。
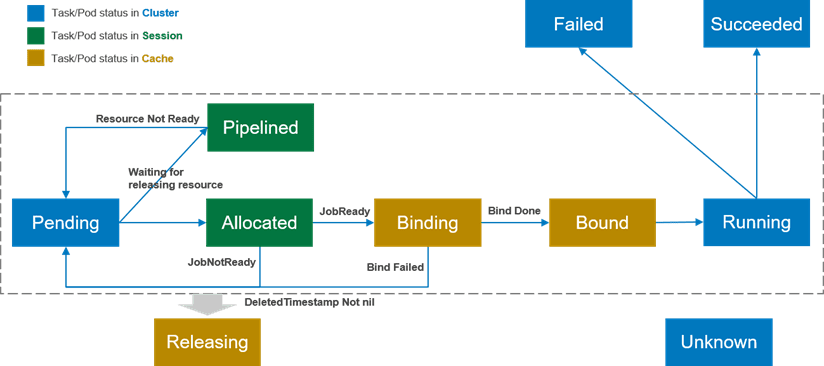
Pod的这些状态为调度器提供了更多优化的可能。例如,当进行Pod驱逐时,驱逐在Binding和Bound状态的Pod要比较驱逐Running状态的Pod的代价要小 (思考:还有其它状态的Pod可以驱逐吗?);并且状态都是记录在Volcano调度内部,减少了与kube-apiserver的通信。但目前Volcano调度器仅使用了状态的部分功能,比如现在的preemption/reclaim仅会驱逐Running状态下的Pod;这主要是由于分布式系统中很难做到完全的状态同步,在驱逐Binding和Bound状态的Pod会有很多的状态竞争。
Volcano调度实现
Volcano调度器在支持上面这些主要场景时,分别使用了action和plugin两级插件。总体来讲,带有动作属性的功能,一般需要引入 action 插件;带有选择 (包括排序) 属性的功能,一般使用 plugin 插件。因此,这些常见场景中,fair-sharing、queue、co-scheduling都通过plugin机制来实现:都带有选择属性,比如“哪些作业应该被优先调度”;而preemption、reclaim、backfill、reserve 则通过 action 机制来实现:都带有动作属性,比如“作业A 抢占 作业B”。这里需要注意的是,action 与 plugin 一定是一同工作的;fair-sharing 这些 plugin 是借助 allocate 发展作用,而 preemption 在创建新的 action 后,同样需要 plugin 来选择哪些作业应该被抢占。这里通过job-based fairness (DRF) 和 preempt 两个功能的实现来介绍action 和 plugin 两种插件机制的使用,其它功能类似:
- Job-based Fairness (DRF): 目前的公平调度是基于DRF,并通过 plugin 插件来实现。在 OpenSession 中会先计算每个作业的 dominant resource和每个作业share的初始值;然后注册 JobOrderFn回调函数,JobOrderFn 中接收两个作业对象,并根据对像的 dominant resource 的 share值对作业进行排序;同时注册EventHandler, 当Pod被分配或抢占资源时,drf根据相应的作业及资源信息动态更新share值。
其它插件的实现方案也基本相似,在OpenSession中注册相应的回调,例如 JobOrderFn, TaskOrderFn,调度器会根据回调函数的结果决定如何分配资源,并通过EventHandler来更新插件内的调度数。
- Preemption: preempt是在allocate之后的一个action,它会为“高”优先级的Pending作业选取一个或多个“低”优先级的作业进行驱逐。由于抢占的动作与分配的动作不一致,因此新创建了preempt action来处理相应的逻辑;同时,在选取高低优先级的作业时,preempt action还是依赖相应的plugin插件来实现。其它动作插件的实现方式也类似,即根据需要创建整体的流程;将带有选择属性的问题转换为算法插件。
6月4日晚20:00-21:00,Volcano/kube-batch 创始人在线授课,不仅传授Volcano架构原理,还告诉你更多应用落地场景,戳链接免费观看。

Volcano火山:容器与批量计算的碰撞的更多相关文章
- 未来云原生世界的“领头羊”:容器批量计算项目Volcano 1.0版本发布
在刚刚结束的CLOUD NATIVE+ OPEN SOURCE Virtual Summit China 2020上,由华为云云原生团队主导的容器批量计算项目Volcano正式发布1.0版本,标志着V ...
- 重磅!业界首个云原生批量计算项目Volcano正式晋级为CNCF孵化项目
摘要:4月7日,云原生计算基金会(CNCF)宣布,由华为云捐献的业界首个云原生批量计算项目Volcano正式晋级为CNCF孵化项目. 4月7日,云原生计算基金会(CNCF)宣布,由华为云捐献的业界首个 ...
- 【转】Alchemy的使用和多项式批量计算的优化
原文:http://www.cnblogs.com/flash3d/archive/2012/01/30/2332158.html ================================== ...
- kaks calculator批量计算多个基因的选择压力kaks值
欢迎来到"bio生物信息"的世界 今天给大家带来"批量计算kaks值"的技能. 关于kaks的背景知识我就不介绍了,感兴趣的自行搜索,这里直接开始讲怎么批量计算 ...
- docker 镜像和容器的批量清理
镜像和容器的清理 删除所有运行中的容器 $ docker kill $(docker ps -q) 删除所有停止的容器 $ docker rm $(docker ps -a -q) 删除所有没有tag ...
- ArcPy批量计算Mean Center的两个实例
很久没用arcpy了,碰了好几次壁,把这次做的贴上来,以备下次可以跳过这些简单的问题 import arcpy arcpy.env.workspace = 'C:\Users\Qian\Documen ...
- shell 批量计算MD5值
#!/bin/sh #需要计算MD5文件列表 # list=`ls` list="file list" for file in $list do file1=`` echo &qu ...
- 在Excel中,已知身份证号码,如何批量计算其实际年龄?
昨天,上司问我:..,你会在Excel中计算年龄吗?当时,一下促住了.说真的,还真不会.今天研究了一下,写下来,方便日后查看. 首先,得有一张已知姓名和相应身份证号的原表吧. 在这张表上再加上三列:出 ...
- 华为云Volcano:让企业AI算力像火山一样爆发
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),输入关键字"加群",加入华为云线上技术讨论群:输入关键字"最新活动",获取华 ...
随机推荐
- java开发常见单词(复习整理)
开发中基本都能碰到,不止以下单词,后续会添加,javascript.html.mysql.spring.Linux中常用单词于此合并分类,特殊不常见不添加 访问修饰符4个--------------- ...
- 高性能MySQL之索引深入原理分析
一.背景 我们工作中经常打交道的就是索引,那么到底什么是索引呢?例如,当一个SQL查询比较慢的时候,你可能会说给“某个字段加个索引吧”之类的解决方案. 总的来说索引的出现其实就是为了提高数据查询的效率 ...
- docker 容器核心技术
容器的数据卷(volume)也是占用磁盘空间,可以通过以下命令删除失效的volume: [root@localhost]# sudo docker volume rm $(docker volume ...
- easyui API
http://www.jeasyuicn.com/api/docTtml/index.htm
- LightOJ1030 Discovering Gold
题目链接:https://vjudge.net/problem/LightOJ-1030 知识点: 概率与期望 解题思路: 设某一个点 \(i\) 能到达的点的个数为 \(x\),其上有金 \(g\) ...
- Create First Application
Node.js创建第一个应用 Node.js开发的目的就是为了用JavaScript编写Web服务器程序, 在使用Node.js时,不仅仅是在实现一个应用,同时还实现了整个HTTP服务器.在创建Nod ...
- PHP 获取当前目录下的所有文件
我们有时候会想拿到当前目录下的所有文件名,以下就是我写的一个方法,请大家参考 // 获取当前文件的上级目录 $con = dirname(__FILE__); // 扫描$con目录下的所有文件 $f ...
- PHP cookie基本操作
PHP中Cookie的使用---添加/更新/删除/获取Cookie 及 自动填写该用户的用户名和密码和判断是否第一次登陆 什么是cookie 服务器在客户端保存用户的信息,比如登录名,密码等 这些数据 ...
- Kubernetes学习笔记(六):使用ConfigMap和Secret配置应用程序
概述 本文的核心是:如何处理应用程序的数据配置. 配置应用程序可以使用以下几种途径: 向容器传递命令行参数 为每个容器配置环境变量 通过特殊的卷将配置文件挂载到容器中 向容器传递命令行参数 在Kube ...
- Redis学习笔记(4)
一.Redis主从复制 1. 概念 为了避免服务的单点故障,会把数据复制到多个副本放在不同的服务器上,且这些拥有数据副本的服务器可以用于处理客户端的读请求,扩展整体的性能.我们把这种机制称之为主从复制 ...