Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup
BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题)
此工具在搜索你想爬的数据匹配的方式就是html标签嵌套的顺序(html介绍在其它随笔内)
首先来聊聊BeautifulSoup的安装pip install python-bs4 包含BeautifulSoup方法
再来安装依赖工具requests和解析格式lxml下载安装包 解压进入目录 python setup.py install此方法是请求服务
先来写一个简单的网页解析代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*- from bs4 import BeautifulSoup
import requests headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
}
url = "http://www.jd.com/" wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
print(soup)
来简单说明下每行代码得作用:
from从bs4库里import导入BeautifulSoup方法
import导入requests方法
headers表示头文件,伪装成浏览器浏览网页,当然我这里写得简单还没写全
url网页地址
wb_data网页数据requests.get请求访问(url网页京东,headers伪装的头文件)
soup解析后的数据BeautifulSoup解析数据(wb_data网页数据,lxml解析的格式按这个要求解析)
print答应soup解析后的网页数据 也就是网页源代码如下 由于网页源代码很长所以这里截图只能显示一部分
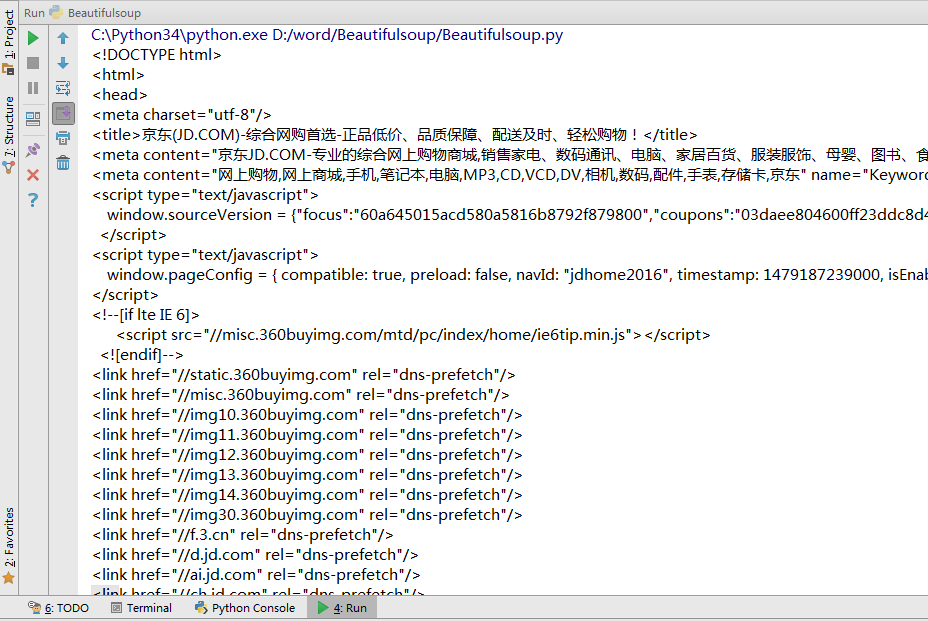
学好基础包括html的结构标签的嵌套还有CSS的名字在网页位置等后教你们怎么去抓电影等网站并且把内容归类好方便查阅
下面是我抓去某电影网站的数据及归类效果掩饰:

Python简单爬虫入门一的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- GJM : Python简单爬虫入门 (一) [转载]
版权声明:本文原创发表于 [请点击连接前往] ,未经作者同意必须保留此段声明!如有侵权请联系我删帖处理! 为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解 ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
随机推荐
- customErrors与错误页面
本配置节相对简单而且常用 <customErrors defaultRedirect="url" mode="On|Off|RemoteOnly"> ...
- 【C#进阶系列】25 线程基础
线程的概念 线程的职责是对CPU进行虚拟化. CPU为每个进程都提供了该进程专用的线程(功能相当于cpu),应用程序如果进入死循环,那么所处的进程会"冻结",但其他进程不会冻结,它 ...
- Hibernate插入数据后获得ID
很多表的主键都是自增型的,新增的记录使用save()方法保存以后,要获得ID,直接使用getId()就可以了,因为此时记录已经保存进数据库,已经有了ID. 另一种方法是使用MySQL的SELECT L ...
- 关于Spring/Hibernate 3.x升级4.x的小问题
情景: 之前版本 现在版本 JDK 1.7 1.8 Tomcat v7.0 v8.0 Spring 3.x 4.x Hibernate 3.x 4.x MySQL 忘了 5.1.53 分析: 如果 ...
- 使用插件实现一般处理程序导出excel
string sql = "select * from WJ_ProjectManager where" + WhereString ; DataTable dt = SqlHel ...
- 【英语学习】2016.09.11 Culture Insider: Teacher's Day in ancient China
Culture Insider: Teacher's Day in ancient China 2016-09-10 CHINADAILY Today is the 32nd Chinese Te ...
- ABP之模块
ABP的反射 为什么先讲反射,因为ABP的模块管理基本就是对所有程序集进行遍历,再筛选出AbpModule的派生类,再按照以来关系顺序加载. ABP对反射的封装着重于程序集(Assembly)与类(T ...
- mariadb 10.2.3支持oracle execute immediate语法
在之前的版本包括oracle mysql/percona server版本中,所有的动态SQL都需要通过prepare执行,如下: "; execute stmt; deallocate p ...
- 从CSS实现正片叠底看=>混合模式mix-blend-mode
兼容性:这个东西说多了也没意思,像HTML5和CSS3这种兼容性时刻变化的东东,我们最好在自己支持的设备上实验,不支持,就在想办法呗,这个东西就是为了方便和好玩 所有属性: mix-blend-mod ...
- Android Studio关于SVN的相关配置及从SVN检出项目
一.安装配置: 如图,安装时必须自定义选择 command line 否则不会安装的 安装完成后,打开 IDE 的 setting 配置面板: 如上图路径 Version Control 下的 Sub ...