爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫
通过Scrapy,我们可以轻松地完成一个站点爬虫的编写。但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码。
如果我们将各个站点的Spider的公共部分保留下来,不同的部分提取出来作为单独的配置,如爬取规则、页面解析方式等抽离出来做成一个配置文件,那么我们在新增一个爬虫的时候,只需要实现这些网站的爬取规则和提取规则即可。
这一章我们就来了解下Scrapy通用爬虫的实现方法。
1.1 CrawlSpider
在实现通用爬虫之前,我们需要先了解一下CrawlSpider,官方文档:https://scrapy.readthedocs.io/en/latest/topics/spiders.html#crawlspider。
CrawlSpider是Scrapy提供的一个通用Spider。在Spider里,我们可以指定一些爬取规则来实现页面的提取,这些爬取规则由一个专门的数据结构Rule表示。Rule里包含提取和跟进页面的配置,Spider会根据Rule来确定当前页面中的哪些链接需要继续爬取、哪些页面的爬取结果需要用哪个方法解析等。
CrawlSpider继承自Spider类。除了Spider类的所有方法和属性,它还提供了一个非常重要的属性和方法。
rules,它是爬取规则属性,是包含一个或多个Rule对象的列表。每个Rule对爬取网站的动作都做了定义,CrawlSpider会读取rules的每一个Rule并进行解析。
parse_start_url(),它是一个可重写的方法。当start_urls里对应的Request得到Response时,该方法被调用,它会分析Response并必须返回Item对象或者Request对象。
这里最重要的内容莫过于Rule的定义了:
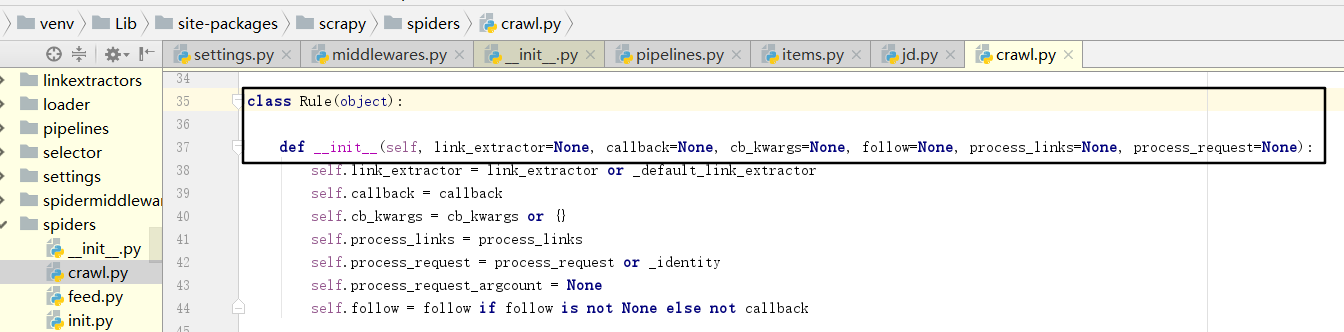
Rule参数:
- link_extractor:是Link Extractor对象。通过它,Spider可以知道从爬取的页面中提取哪些链接。提取出的链接会自动生成Request。它又是一个数据结构,一般常用LxmlLinkExtractor对象作为参数。
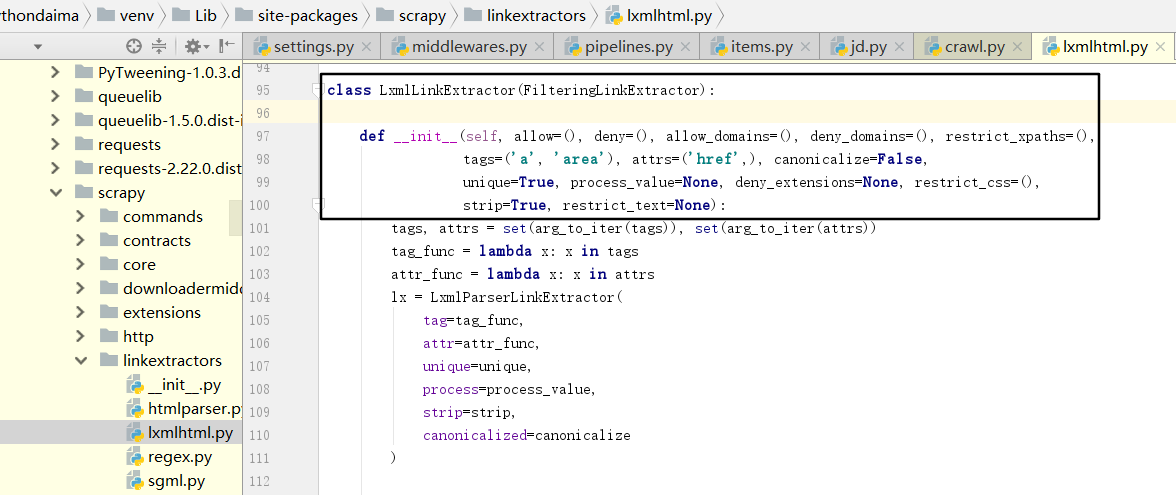
allow是一个正则表达式或正则表达式列表,它定义了从当前页面提取出的链接哪些是符合要求的,只有符合要求的链接才会被跟进。deny则相反。allow_domains定义了符合要求的域名,只有此域名的链接才会被跟进生成新的Request,它相当于域名向名单。deny_domains则相反,相当于域名黑名单。restrict_xpaths定义了从当前页面中XPath匹配的区域提取链接,其值是XPath表达式或XPath表达式列表。restrict_css定义了从当前页面中css选择器匹配的区域提取链接,其值是css选择器或css选择器列表还有一些其他参数代表了提取链接的标签、是否去重、链接的处理等内容,使用的频率不高。
- callback:即回调函数,和之前定义Request的callback有相同的意义。每次从link_extractor中获取到链接时,该函数将会调用。该回调函数接收一个response作为其第一个参数,并返回一个包含Item或Request对象的列表。注意,避免使用pars()作为回调函数。由于CrawlSpider使用parse()方法来实现其逻辑,如果parse()方法覆盖了,CrawlSpider将会运行失败。
- cb_kwargs:字典,它包含传递给回调函数的参数。
- follow:布尔值,即True或False,它指定根据该规则从response提取的链接是否需要跟进。如果 callback参数为None,follow默认设置为True,否则默认为False。
- process_links:指定处理函数,从link_extractor中获取到链接列表时,该函数将会调用, 它主要用于过滤。
- process_request:同样是指定处理函数,根据该Rule提取到每个Request时,该函数部会调用,对Request进行处理。该函数必须返回Request或者None。
以上内容便是CraefISpider中的核心Rule的基本用法。但这些内容可能还不足以完成一个CrawlSpider爬虫。下面我们利用CrawlSpider实现新闻网站的爬取实例,来更好地理解Rule的用法。
1.2 Item Loader
我们了解了利用CrawlSpider的Rule来定义页面的爬取逻辑,这是可配置化的一部分内容。但是,Rule并没有对Item的提取方式做规则定义。对于Item的提取,我们需要借助另一个模块Item Loader来实现。
Item Loader提供一种便捷的机制来帮助我们方便地提取Item。它提供的一系列API可以分析原始数据对Item进行赋值。Item提供的是保存抓取数据的容器,而Item Loader提供的是填充容器的机制。有了它,数据的提取会变得更加规则化。
Item LoaderAPI参数:
item:它是Item对象,可以调用add_xpath()、add_css()或add_value()等方法来填充Item对象。
selector:它是Selector对象,用来提取填充数据的选择器。
response:它是Response对象,用于使用构造选择器的Response。
实例:
from scrapy.loader import ItemLoader
from scrapyDemo.items import Product
def parse(self, response):
loader = ItemLoader(item=Product(),response=response)
loader.add_xpath('name','//div[@class="product_name"]')
loader.add_xpath('name','//div[@class="product_title"]')
loader.add_xpath('price','//p[@id="price"]')
loader.add_css('stock','p#stock]')
loader.add_value('last_updated','today')
return loader.load_item()
这里首先声明一个Product Item,用该Item和Response对象实例化Item Loader,调用add_xpath()方法把来向两个不同位置的数据提取出来,分配给name属性,再用add_xpath()、add_css()、add_value()等方法对不同属性依次赋值,最后调用load_item()方法实现Item的解析。这种方式比较规则化,我们可以把一些参数和规则单独提取出来做成配置文件或存到数据库,即可实现可配置化。
另外,Item Loader每个字段中都包含了一个Input Processor(输入处理器)和一个Output Processor(输出处理器)。Input Processor收到数据时立刻提取数据,Input Processor的结果被收集起来并且保存在ltemLoader内,但是不分配给Item。收集到所有的数据后,load_item()方法被调用来填充再生成Item对象 。在调用时会先调用Output Processor来处理之前收集到的数据,然后再存入Item中,这样就生成了Item。
内置的Processor:
(1) Identity
Identity是最简单的Processor,不进行任何处理,直接返回原来的数据。
(2) TakeFirst
TakeFirst返回列表的第一个非空值,类似extract_first()的功能,常用作Output Processor。
from scrapy.loader.processors import TakeFirst
processor = TakeFirst()
print(processor(['',1,2,3]))
运行结果为1。
(3) Join
Join方法相当于字符串的join()方法,可以把列表并结成字符串,字符串默认使用空格分隔。
from scrapy.loader.processors import Join
processor = Join()
print(processor(['one','two','three']))
运行结果为one two three。
它也可以通过参数更改默认的分隔符,例如改成逗号:
from scrapy.loader.processors import Join
processor = Join(',')
print(processor(['one','two','three']))
运行结果为one,two,three。
(4) Compose
Compose是用给定的多个函数的组合而构造的Processor,每个输入值被传递到第一个函数,其输出再传递到第二个函数,依次类推,直到最后一个函数返回整个处理器的输出。
from scrapy.loader.processors import Compose
processor = Compose(str.upper,lambda s:s.strip())
print(processor('hello world'))
运行结果为HELLO WORLD。
在这里我们构造了一个Compose Processor,传入一个开头带有空格的字符串。Compose Processor的参数有两个:第一个是str.upper,它可以将字母全部转为大写;第二个是一个匿名函数,它调用strip()方法去除头尾空白字符。Compose会顺次调用两个参数,最后返回结果的字符串全部转化为大写并且去除了开头的空格。
(5) MapCompose
与Compose类似,MapCompose可以迭代处理一个列表输入值。
from scrapy.loader.processors import MapCompose
processor = MapCompose(str.upper,lambda s:s.strip())
print(processor(['Hello','World','Python']))
运行结果为['HELLO','WORLD','PYTHON']。
被处理的内容是一个可迭代对象,MapCompose会将该对象遍历然后依次处理。
(6) SelectJmes
SelectJmes可以查询JSON,传入Key,返回查询所得的Value。不过需要先安装jmespath库才可以使用它。
pip install jmespath
安装好jmespath之后,便可以使用这个Processor了。
from scrapy.loader.processors import SelectJmes
processor = SelectJmes('foo')
print(processor({'foo':'bar'}))
运行结果为:bar。
以上内容便是一些常用的Processor,在本节的实例中我们会使用Processor来进行数据的处理。接下来,我们用一个实例来了解Item Loader的用法。
1.3 通用爬虫案例
起点作为主流的小说网站,在防止数据采集反面还是做了准备的,其对主要的数字采用了自定义的编码映射取值,想直接通过页面来实现数据的获取,是无法实现的。
单独获取数字还是可以实现的,通过requests发送请求,用正则去匹配字符元素,并再次匹配其映射关系的url,获取到的数据通过font包工具解析成字典格式,再做编码匹配,起点返回的编码匹配英文数字,英文数字匹配阿拉伯数字,最后拼接,得到实际的数字字符串,但这样多次发送请求,爬取效率会大大降低。本次集中爬取舍弃了爬取数字,选择了较容易获取的评分数字。评分值默认为0 ,是从后台推送的js数据里取值更新的。
但是这太复杂了,我没空搞,现在写博客都是挤出时间来写。
1.3.1 新建项目
先新建Scrapy项目,名为qd。
scrapy startproject qd
创建一个CrawlSpider,需要先制定一个模板。我们可以先看看有哪些可用模版。
scrapy genspider -l
运行结果:

之前创建Spider的时候,我们默认使用了第一个模板basic。这次要创建CrawlSpider,就需要使用第二个模板crawl。
scrapy genspider -t crawl read qidian.com
运行之后便会生成一个CrawlSpider。
这次生成的Spider内容多了一个rules属性的定义。Rule第一个参数是LinkExtractor,就是上文所说的LxmllinkExtractor,只是名称不同。同时,默认的回调函数也不再是parse,而是parse_item。
1.3.2 定义Rule
要实现小说信息的爬取,我们需要做的就是定义好Rule,然后实现解析函数。下面我们就来一步步实现这个过程。
首先将start_urls修改为起始链接。
start_urls = ['https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=1']
之后,Spider爬取start_urls里面的每一个链接。所以这里第一个爬取的页面就是我们刚才所定义的链接。得到Response之后,Spider就会根据每一个Rule来提取这个页面内的超链接,去生成进一步的Request。接下来,我们就需要定义Rule来指定提取哪些链接。
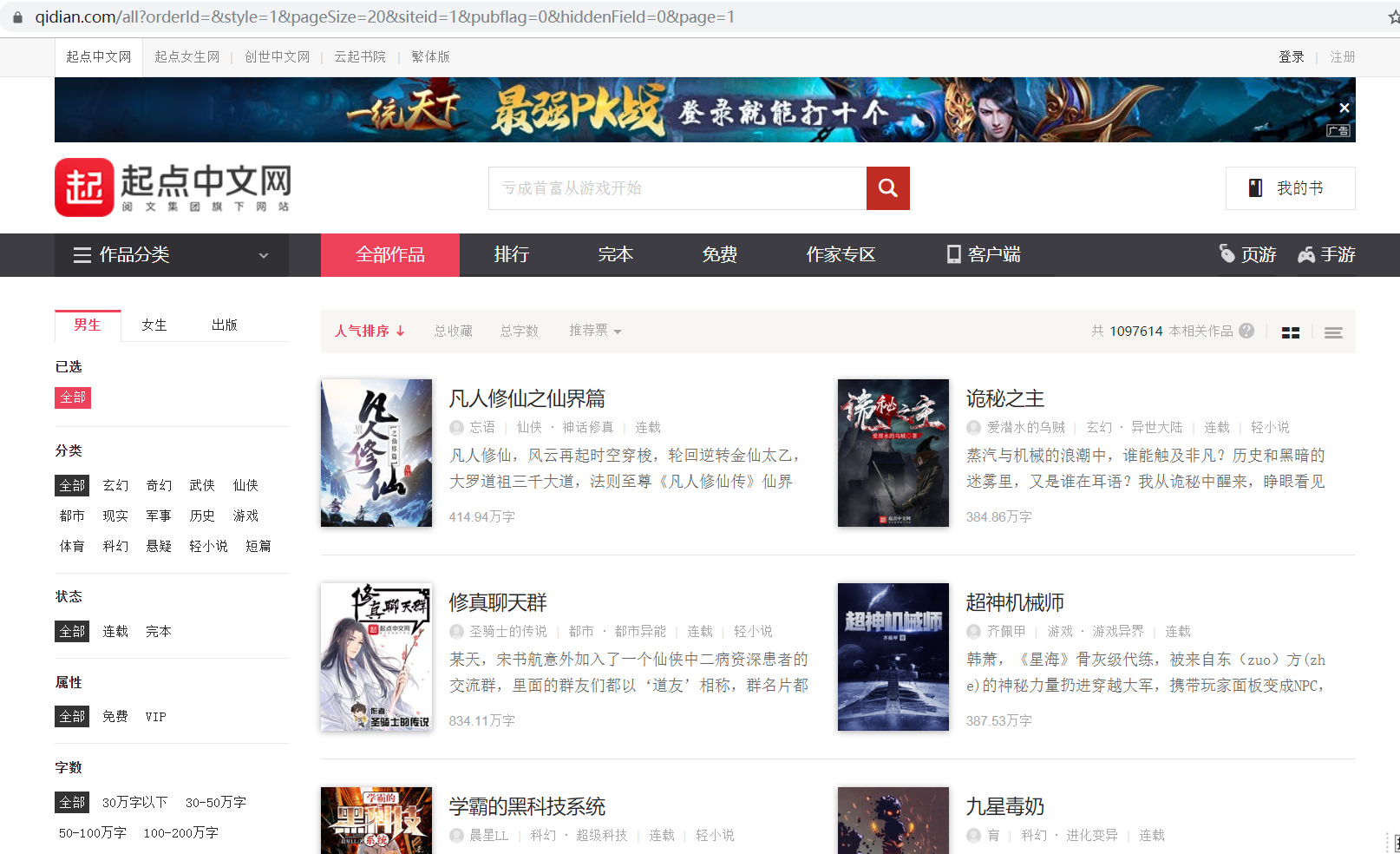
这是起点小说网的列表页,下一步自然就是将列表中的每一条小说详情的链接提取出来。这里直接指定这些链接所在区域即可。
rules:
rules = (
#匹配全部主页面的url规则 深度爬取子页面
Rule(LinkExtractor(allow=(r'https://www.qidian.com/all\?orderId=\&style=1\&pageSize=20\&siteid=1\&pubflag=0\&hiddenField=0\&page=(\d+)')),follow=True),
#匹配详情页面 不作深度爬取
Rule(LinkExtractor(allow=r'https://book.qidian.com/info/(\d+)'), callback='parse_item', follow=False),
)
1.3.3 解析页面
接下来我们需要做的就是解析页面内容了,将书名、作者、状态、类型、简介、评分、故事、最新章节提取出来即可。首先定义一个Item。
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field,Item class QdItem(Item):
# define the fields for your item here like: book_name = Field() #书名
author=Field() #作者
state=Field() #状态
type=Field() #类型
about=Field() #简介
score=Field() #评分
story=Field() #故事
news=Field() #最新章节
然后我创建了很多方法,在分别获取这些信息。
def get_book_name(self,response):
book_name=response.xpath('//h1/em/text()').extract()[0]
if len(book_name)>0:
book_name=book_name.strip()
else:
book_name='NULL'
return book_name
def get_author(self,response):
author=response.xpath('//h1/span/a/text()').extract()[0]
if len(author)>0:
author=author.strip()
else:
author='NULL'
return author
def get_state(self,response):
state=response.xpath('//p[@class="tag"]/span/text()').extract()[0]
if len(state)>0:
state=state.strip()
else:
st='NULL'
return state
def get_type(self,response):
type=response.xpath('//p[@class="tag"]/a/text()').extract()
if len(type)>0:
t=""
for i in type:
t+=' '+i
type=t
else:
type='NULL'
return type
def get_about(self,response):
about=response.xpath('//p[@class="intro"]/text()').extract()[0]
if len(about)>0:
about=about.strip()
else:
about='NULL'
return about
def get_score(self,response):
def get_sc(id):
urll = 'https://book.qidian.com/ajax/comment/index?_csrfToken=ziKrBzt4NggZbkfyUMDwZvGH0X0wtrO5RdEGbI9w&bookId=' + id + '&pageSize=15'
rr = requests.get(urll)
# print(rr)
score = rr.text[16:19]
return score
bid=response.xpath('//a[@id="bookImg"]/@data-bid').extract()[0] #获取书的id
if len(bid)>0:
score=get_sc(bid) #调用方法获取评分 若是整数 可能返回 9,"
if score[1]==',':
score=score.replace(',"',".0")
else:
score=score
else:
score='NULL'
return score
def get_story(self,response):
story=response.xpath('//div[@class="book-intro"]/p/text()').extract()[0]
if len(story)>0:
story=story.strip()
else:
story='NULL'
return story
def get_news(self,response):
news=response.xpath('//div[@class="detail"]/p[@class="cf"]/a/text()').extract()[0]
if len(news)>0:
news=news.strip()
else:
news='NULL'
return news
其他部分就没什么变化了,就settings加入了请求头:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv 11.0) like Gecko',
}
1.3.4 运行程序
scrapy crawl read
运行结果:

1.3.5 完整代码
read.py:
# -*- coding: utf-8 -*- from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from qd.items import QdItem
import requests class ReadSpider(CrawlSpider):
name = 'read'
# allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=1'] rules = (
#匹配全部主页面的url规则 深度爬取子页面
Rule(LinkExtractor(allow=(r'https://www.qidian.com/all\?orderId=\&style=1\&pageSize=20\&siteid=1\&pubflag=0\&hiddenField=0\&page=(\d+)')),follow=True),
#匹配详情页面 不作深度爬取
Rule(LinkExtractor(allow=r'https://book.qidian.com/info/(\d+)'), callback='parse_item', follow=False),
) def parse_item(self, response):
item=QdItem()
item['book_name']=self.get_book_name(response)
item['author']=self.get_author(response)
item['state']=self.get_state(response)
item['type']=self.get_type(response)
item['about']=self.get_about(response)
item['score']=self.get_score(response)
item['story']=self.get_story(response)
item['news']=self.get_news(response)
yield item def get_book_name(self,response): book_name=response.xpath('//h1/em/text()').extract()[0]
if len(book_name)>0:
book_name=book_name.strip()
else:
book_name='NULL'
return book_name def get_author(self,response):
author=response.xpath('//h1/span/a/text()').extract()[0]
if len(author)>0:
author=author.strip()
else:
author='NULL'
return author def get_state(self,response):
state=response.xpath('//p[@class="tag"]/span/text()').extract()[0]
if len(state)>0:
state=state.strip()
else:
st='NULL'
return state def get_type(self,response):
type=response.xpath('//p[@class="tag"]/a/text()').extract()
if len(type)>0:
t=""
for i in type:
t+=' '+i
type=t
else:
type='NULL'
return type def get_about(self,response):
about=response.xpath('//p[@class="intro"]/text()').extract()[0]
if len(about)>0:
about=about.strip()
else:
about='NULL'
return about def get_score(self,response): def get_sc(id):
urll = 'https://book.qidian.com/ajax/comment/index?_csrfToken=ziKrBzt4NggZbkfyUMDwZvGH0X0wtrO5RdEGbI9w&bookId=' + id + '&pageSize=15'
rr = requests.get(urll)
# print(rr)
score = rr.text[16:19]
return score bid=response.xpath('//a[@id="bookImg"]/@data-bid').extract()[0] #获取书的id
if len(bid)>0:
score=get_sc(bid) #调用方法获取评分 若是整数 可能返回 9,"
if score[1]==',':
score=score.replace(',"',".0")
else:
score=score else:
score='NULL'
return score def get_story(self,response):
story=response.xpath('//div[@class="book-intro"]/p/text()').extract()[0]
if len(story)>0:
story=story.strip()
else:
story='NULL'
return story def get_news(self,response):
news=response.xpath('//div[@class="detail"]/p[@class="cf"]/a/text()').extract()[0]
if len(news)>0:
news=news.strip()
else:
news='NULL'
return news
items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field,Item class QdItem(Item):
# define the fields for your item here like: book_name = Field() #书名
author=Field() #作者
state=Field() #状态
type=Field() #类型
about=Field() #简介
score=Field() #评分
story=Field() #故事
news=Field() #最新章节
settings.py:
# -*- coding: utf-8 -*- # Scrapy settings for qd project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'qd' SPIDER_MODULES = ['qd.spiders']
NEWSPIDER_MODULE = 'qd.spiders' DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv 11.0) like Gecko',
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'qd (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'qd.middlewares.QdSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'qd.middlewares.QdDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'qd.pipelines.QdPipeline': 300,
#} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
middlewares.py:
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals class qdSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider. # Should return None or raise an exception.
return None def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response. # Must return an iterable of Request, dict or Item objects.
for i in result:
yield i def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception. # Should return either None or an iterable of Request, dict
# or Item objects.
pass def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated. # Must return only requests (not items).
for r in start_requests:
yield r def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name) class qdDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
pipelines.py:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html class QdPipeline(object):
def process_item(self, item, spider):
return item
爬虫(十八):Scrapy框架(五) Scrapy通用爬虫的更多相关文章
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- Scrapy框架实战-妹子图爬虫
Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难.即便是在一些小型的项目上,用scrapy甚至比用requests.urllib.urllib2更方便,简单,效率也更高.废话不多说, ...
- 爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
什么是Scrapy 基于Twisted的异步处理框架 纯python实现的爬虫框架 基本结构:5+2框架,5个组件,2个中间件 5个组件: Scrapy Engine:引擎,负责其他部件通信 进行信号 ...
- scrapy框架解读--深入理解爬虫原理
scrapy框架结构图: 组成部分介绍: Scrapy Engine: 负责组件之间数据的流转,当某个动作发生时触发事件 Scheduler: 接收requests,并把他们入队,以便后续的调度 Do ...
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- [Python][Scrapy 框架] Python3 Scrapy的安装
1.方法(只介绍 pip 方式安装) PS.不清楚 pip(easy_install) 可以百度或留言. cmd命令: (直接可以 pip,而不用跳转到 pip.exe目录下,是因为把所在目录加入 P ...
- 转: 【Java并发编程】之十八:第五篇中volatile意外问题的正确分析解答(含代码)
转载请注明出处:http://blog.csdn.net/ns_code/article/details/17382679 在<Java并发编程学习笔记之五:volatile变量修饰符-意料之外 ...
随机推荐
- python 阶乘函数
def num(n): if n == 1: return n return n*num(n-1) print(num(10)) 输出 3628800 该函数使用了递归函数的规则.return 后面为 ...
- Uboot 命令行 介绍
背景 基本上,本文转载自:<ARM板移植Linux系统启动(五)Uboot命令行> 上次说到uboot的启动方式,最后会使用autoboot(自主模式)尝试引导kernel,如果失败或者被 ...
- Manjaro Linux 添加源及输入法
生成可用的中国镜像站列表 sudo pacman-mirrors -i -c China -m rank 勾选相应的镜像站 ,看自己的喜好 如中科大:http://mirrors.ustc.edu.c ...
- 03.swoole学习笔记--web服务器
<?php //创建web服务器 $serv=); //获取请求 /* * $request:请求信息 * $response:响应信息 */ $serv->on('request',fu ...
- Microsoft Windows 实用程序 Sysinternals Utilities Index
最新页面时间:2017年5月16日 Sysinternals被MS收购--windows internals共近70多个工具集 Sysinternals套件 整套Sysinternals Utilit ...
- B. Yet Another Crosses Problem
B. Yet Another Crosses Problem time limit per test 2 seconds memory limit per test 256 megabytes inp ...
- php 和 文本编辑器火狐的配置
个人比较习惯的编辑器和浏览器配置 Sublime Ctrl+Shitf+P 输入 install 安装扩展: 点开菜单 -> view -> showConsole (或者按住 Ctrkl ...
- Linux学习《第五章 用户身份与文件权限》
- ffmpeg “inttypes.h”: No such file or directory
编译过程:错误一:无法打开包括文件:“inttypes.h”: No such file or directory解决方法:删除之,并在其之前添加如下代码: #if defined(WIN32) &a ...
- Java8 Stream分组
//根据排课id分组 Map<Integer, List<Schedule4Homework>> idSchedule4HomeworksMap = schedule4Home ...