[日志分析]Graylog2进阶 通过正则解析Nginx日志
之前分享的 [日志分析]Graylog2采集Nginx日志 主动方式 这篇文章介绍了Graylog如何通过Graylog Collector Sidecar来采集nginx日志。
由于日志是未经处理的,所以类似$remote_addr $request_time $upstream_addr $upstream_response_time的字段并没有解析出来,而是都显示在默认的message中,很不利于我们今后的分析工作。
为了解决这个问题,就引入了graylog另一个非常强大的功能 Extractors ,Extractors 翻译过来叫提取器,顾名思义,就是将原始日志的各个字段通过正则匹配的方式提取并保存到相对应的字段中。
针对这次nginx的字段提取,我着重讲一下Extractors的Grok pattern用法。这是日常生产处理原始日志 ,最常用的一种方式。
(1)先去查看nginx配置文件的log_format选项:
log_format access '$remote_addr - [$time_local] $request_time $upstream_addr $upstream_response_time "$request_method $scheme://$host$request_uri" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"';
(2)根据log_format的输出格式编写相应的正则表达式,简单讲解一下以^%{IP:remote_addr} 为例,^代表日志开头,大括号里面的IP代表名为IP的grok pattern,可以在System/Grok pattern中查到,冒号后边就是你要存储的字段名称为remote_addr 。
^%{IP:remote_addr} - \[%{HTTPDATE:time_local}\] %{DATA:request_time} %{DATA:upstream_addr} %{DATA:upstream_response_time} \"%{NOTSPACE:method} %{NOTSPACE:url}\" %{NOTSPACE:status} %{DATA:body_bytes_sent} %{DATA:http_referer} \"%{DATA:http_user_agent}\"\s+\"%{DATA:http_x_forwarded_for}\"
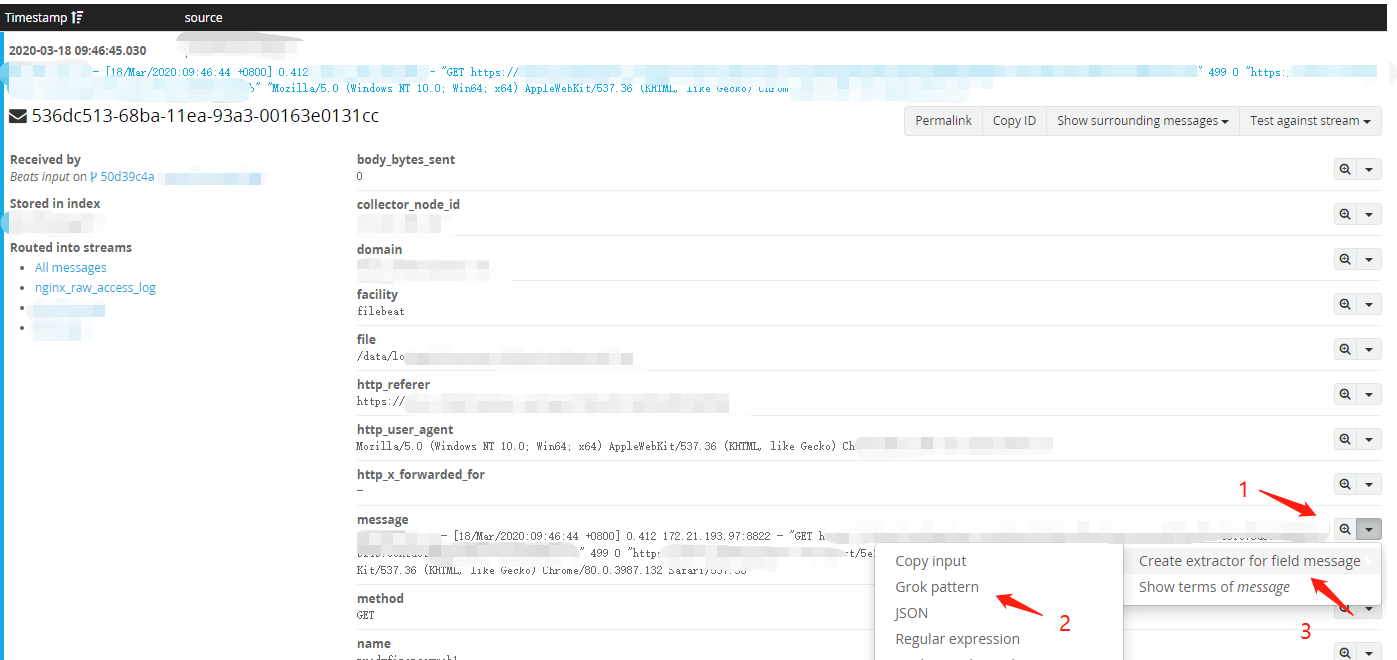
(3) 在导航栏Search 选择一条nginx日志,在message字段右边,点击小三角选择 Grok pattern -> Creat extractor for field message 到Extractors 页面。
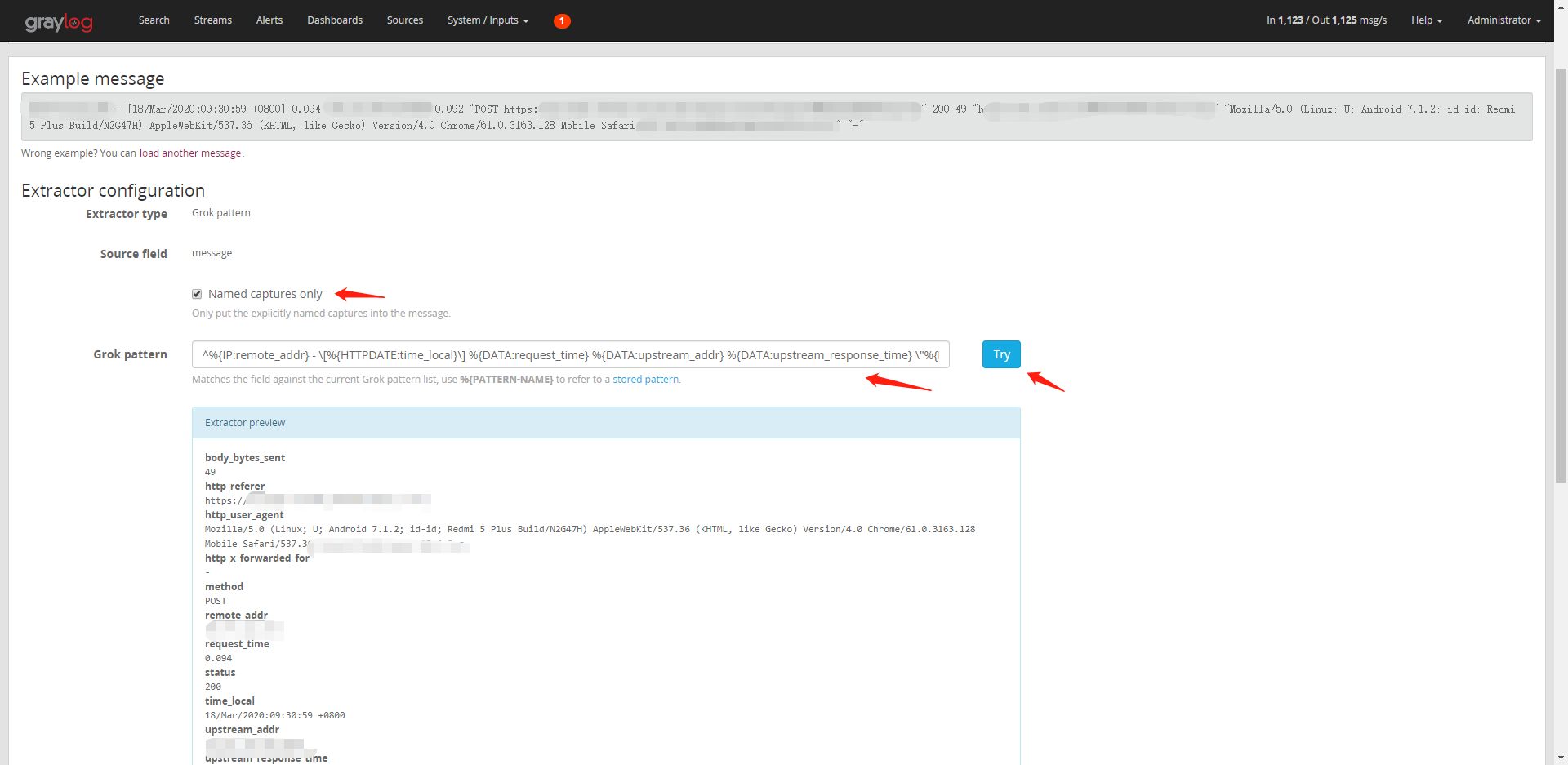
(2)选中Named captures only复选框,Grok pattern填入正则,点击Try可以看到解析后的笑果,相应的字段已经解析出来了。

[日志分析]Graylog2进阶 通过正则解析Nginx日志的更多相关文章
- [日志分析]Graylog2进阶之获取Nginx来源IP的地理位置信息
如果你们觉得graylog只是负责日志收集的一个管理工具,那就too young too naive .日志收集只是graylog的最最基础的用法,graylog有很多实用的数据清洗和处理的进阶用法. ...
- [日志分析]Graylog2采集Nginx日志 主动方式
这次聊一下Graylog如何主动采集Nginx日志,分成两部分: 介绍一下 Graylog Collector Sidecar 是什么 如何配置 Graylog Collector Sidecar 采 ...
- [日志分析]Graylog2采集Nginx日志 被动方式
graylog可以通过两种方式采集nginx日志,一种是通过Graylog Collector Sidecar进行采集(主动方式),另外是通过修改nginx配置文件的方式进行收集(被动方式). 这次说 ...
- [日志分析]Graylog2采集mysql慢日志
之前聊了一下graylog如何采集nginx日志,为此我介绍了两种采集方法(主动和被动),让大家对graylog日志采集有了一个大致的了解. 从日志收集这个角度,graylog提供了多样性和灵活性,大 ...
- Logstash使用grok插件解析Nginx日志
grok表达式的打印复制格式的完整语法是下面这样的: %{PATTERN_NAME:capture_name:data_type}data_type 目前只支持两个值:int 和 float. 在线g ...
- ELK+Redis 解析Nginx日志
一.ELK简介 Elk是指logstash,elasticsearch,kibana三件套,我们一般使用它们做日志分析. ELK工作原理图: 简单来讲ELK具体的工作流程就是客户端的logstash ...
- Goaccess解析nginx日志备忘
参考 http://nginx.org/en/docs/http/ngx_http_log_module.html?&_ga=1.92028562.949762386.1481787781#l ...
- 我的日志分析之道:简单的Web日志分析脚本
前言 长话短说,事情的起因是这样的,由于工作原因需要分析网站日志,服务器是windows,iis日志,在网上找了找,github找了找,居然没找到,看来只有自己动手丰衣足食. 那么分析方法我大致可分为 ...
- python 解析nginx 日志 url
>>> import os>>> os.chdir('e:/')>>> log=open('access.log')//这两行是获取日志流> ...
随机推荐
- 吴裕雄--天生自然 python开发学习笔记:一劳永逸解决绘图出现中文乱码问题方法
import numpy as np import matplotlib.pyplot as plt x = np.random.randint(0,20,10) y = np.random.rand ...
- 关于angular2跳路由防止页面刷新的做法(Angular2路由重载)
simpleReuseStrategy.ts // 创建重用策略 import { ActivatedRouteSnapshot, DetachedRouteHandle, RouteReuseStr ...
- ionic3 生命周期钩子
ionViewDidLoad 页面加载完成触发,这里的"加载完成"指的是页面所需的资源已经加载完成,但还没进入这个页面的状态(用户看到的还是上一个页面). 需要注意的是它是一个很傲 ...
- 一个类似ThinkPHP的Node.js框架——QuickNode
QuickNode Node.js从QuickNode开始,让restful接口开发更简单! PHP的MVC 作为一名曾经的PHP开发者,我也有过三年多的thinkphp使用经验,那是我学习PHP接触 ...
- 写了个通作的分页存储过程,top,加入了排序
USE [WebDB_TradeOrder]GO/****** Object: StoredProcedure [dbo].[Boss_Proc_PagingWithOrder] Script ...
- 关于Synchornized,Lock,AtomicBoolean和volatile的区别介绍
1. volatile 变量可以被看作是一种 "程度较轻的 synchronized". 2. Lock 实现提供了比使用 synchronized 方法和语句可获得的更广泛的 ...
- linux服务器项目部署
重启服务器 :reboot C:\Users\maple>mysql -u root -pEnter password: ******mysql> use test;Database ch ...
- 吴裕雄--天生自然python编程:turtle模块绘图(4)
import turtle bob = turtle.Turtle() for i in range(1,5): bob.fd(100) bob.lt(90) turtle.mainloop() im ...
- Java 关于线程的面试题及答案
一.职场可能碰到的关于线程的面试题: 1. 什么是线程? 线程是程序中一个单一的顺序控制流程.进程内有一个相对独立的.可调度的执行单元,是系统独立调度和分派CPU的基本单位指令运行时的程序的调度单位. ...
- Jennifer Chayes: 生活始终在你手中
Jennifer Chayes 听到Mark Kac.Freeman J. Dyson.林家翘,或者是David I. Gottlie.BerndSturmfels和Sir John Ball等 ...