cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning
讲课嘉宾是Song Han,个人主页 Stanford:https://stanford.edu/~songhan/;MIT:https://mtlsites.mit.edu/songhan/。
1. 深度学习面临的问题:
1)模型越来越大,很难在移动端部署,也很难网络更新。
2)训练时间越来越长,限制了研究人员的产量。
3)耗能太多,硬件成本昂贵。
解决的方法:联合设计算法和硬件。
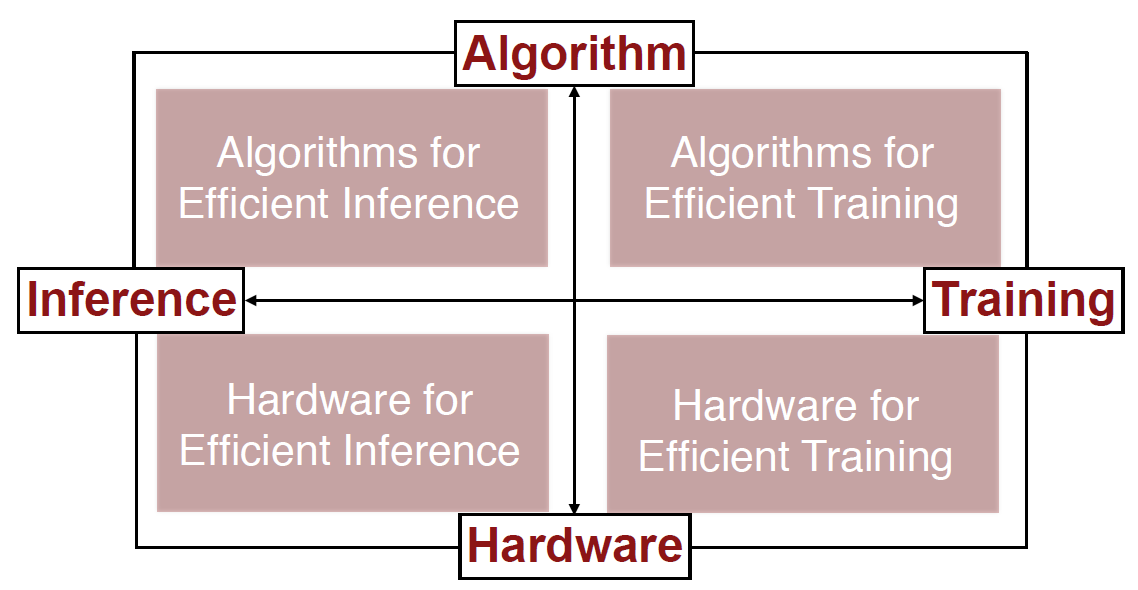
计算硬件可以分为通用和专用两大类。通用硬件又可以分为CPU和GPU。专用硬件可以分为(FPGA和ASIC,ASIC更高效,谷歌的TPU就是ASIC)。
2. Algorithms for Efficient Inference
1)Pruning,修剪掉不那么重要的神经元和连接。第一步,用原始的网络训练;第二步,修剪掉一部分网络;第三步,继续训练剩下的网络。不断重复第二步和第三步。在不损失精度的情况下,网络可以缩小到原来的十分之一(继续缩小精度会变差)。
2)Weight Sharing,权重并不需要那么精确,可以把一些近似的权重看成一样的(比如2.09、2.12、1.92、1.87可以全部看成2)。也是在原始训练基础上,用某种方式简化权重,然后不断训练调整简化权重的方式。在不损失精度的情况下,网络可以缩小到原来的八分之一。
前两种方法可以结合使用,网络可以缩小到原来的百分之几。有个名字Deep Compression。
3)Quantization,数据类型。TPU的设计主要就是优化这一部分。
4)Low Rank Approximation,把大网络拆成一系列小网络。
5)Binary(二元)/Ternary(三元) Net,很疯狂地把权重离散化成(-1,0,1)三种。
6)Winograd Transformation,一种更高效的求卷积的做法。
3. Hardware for Efficient Inference
这个方向各种硬件的共同目的是减少内存的读取(minimize memory access)。硬件需要能用压缩过的神经网络做预测。
EIE(Efficient Inference Engine)(Han et al. ISCA 2016):稀疏权重(扔掉为0的权重)、稀疏激活值(扔掉为0的激活值)、Weight Sharing(4-bit)。
4. Algorithms for Efficient Training
1)Parallelization。CPU按照摩尔定律发展,这些年单线程的性能已经提高的非常缓慢,而核的数量在不断提高。

2)Mixed Precision with FP16 and FP32,正常是用32位计算,但计算权重更新的时候用16位。
3)Model Distillation,用训练的很好的大网络的“软结果”(soft targets)作为标签提供给压缩过的小网络训练。这是Hinton的一篇论文提出的,里面解释了为什么软结果比ground truth更好。
4)DSD(Dense-Sparse-Dense Training),先对原始的稠密的网络做Pruning,训练稀疏的网络后,再Re-Dense出稠密的网络。Han说这是先学习树的枝干,再学习叶子。相比原来的稠密网络,Re-Dense出的精度更高。
5. Hardware for Efficient Training
Computation和Memory bandwidth是影响整体性能的两个因素。
Han对比Nvidia Pascal和Volta,猛吹了一波Volta。。。Volta有120个Tensor Core,非常擅长矩阵运算。
cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning的更多相关文章
- cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning 听课笔记
1. 深度学习面临的问题: 1)模型越来越大,很难在移动端部署,也很难网络更新. 2)训练时间越来越长,限制了研究人员的产量. 3)耗能太多,硬件成本昂贵. 解决的方法:联合设计算法和硬件. 计算硬件 ...
- 韩松毕业论文笔记-第六章-EFFICIENT METHODS AND HARDWARE FOR DEEP LEARNING
难得跟了一次热点,从看到论文到现在已经过了快三周了,又安排了其他方向,觉得再不写又像之前读过的N多篇一样被遗忘在角落,还是先写吧,虽然有些地方还没琢磨透,但是paper总是这样吧,毕竟没有亲手实现一下 ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture7 Training Neural Networks II
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 Python/Numpy基础 (1)
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
- cs231n spring 2017 lecture13 Generative Models
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
随机推荐
- CMake工具总述
CMake是一个跨平台的安装工具,可以用简单的语句来描述所有平台的安装. CMake的文件为.cmake文件与CMakeLists.txt文件;通过编写上述两种文件就可以完成源程序的安装.
- Exchange 2016 CU3 安装失败解决方法
Exchange 2016 CU3 安装失败解决方法 1. 问题: 由于前期安装过Exchange 2010 ,服务器非正常删除,后期人员无法跟进,在新安装Exchange 2016时准备工作正常完成 ...
- Python批量重命名文件
批量替换文件名中重复字符: # -*- coding: UTF-8 -*- import os path = raw_input("请输入文件夹路径:") oldname = ra ...
- 安装使用离线版本的维基百科(Wikipedia)
1 相关背景 平常大家在上网查询一些基本概念的时候常常会参考维基百科上面的资料,但是由于方校长研制的GFW(长城防火墙系统)强大的屏蔽功能,好多链接打开以后,不出意外会出现著名的“404NOT FOU ...
- 第一个struts2框架
编写步骤: 1.导入有关的包. 2.编写web.xml文件 3.写Action类 4.编写jsp 5.编写struts.xml web.xml <?xml version="1.0&q ...
- VMware vSphere虚拟化-VMware ESXi 5.5组件添加本地磁盘--虚拟机扩容
本地存储器可以是位于ESXi主机内部的内部硬盘,也可以是位于主机之外并直接通过SAS或者SATA等协议连接在主机上的外部存储系统.本地存储不需要存储网络即可与主机进行通信,只需要一根连接到存储单元的电 ...
- 实体机安装Ubuntu系统
今天windows突然蓝屏了,索性安装个 Ubuntu 吧,这次就总结一下实体机安装 Ubuntu 的具体步骤 note: 本人实体机为笔记本 型号为:小米pro U盘为金士顿:8G 安装系统:Ubu ...
- android studio compile api implementation 区别
compile与api 二者等同,无区别 implementation与compile或implementation与api implementation编译的依赖只作用于当前的module.即APP ...
- JAVA--Mybatis-Spring-SpringMVC框架整合
------Mybatis-Spring-SpringMVC框架整合示例----- mybatis SQL映射文件 <?xml version="1.0" encoding= ...
- 中国文化产业基金越来越多,但IP变现难题为何仍未解决?
自始至终,中国商界领域的态势就有一个很明显的特征--哪里是风口.哪里是热点,企业就会蜂拥而至并集体掘金.一直到决出胜负,或者把整个风口"做烂"才罢休.很典型的案例就是电商领域已经呈 ...