【Java并发】详解 AbstractQueuedSynchronizer
前言
队列同步器 AbstractQueuedSynchronizer(以下简称 AQS),是用来构建锁或者其他同步组件的基础框架。它使用一个 int 成员变量来表示同步状态,通过 CAS 操作对同步状态进行修改,确保状态的改变是安全的。通过内置的 FIFO (First In First Out)队列来完成资源获取线程的排队工作。更多关于 Java 多线程的文章可以转到 这里
AQS 和 synchronized
在介绍 AQS 的使用之前,需要首先说明一点,AQS 同步和 synchronized 关键字同步(以下简称 synchronized 同步)是采用的两种不同的机制。首先看下 synchronized 同步,synchronized 关键字经过编译之后,会在同步块的前后分别形成 monitorenter 和 monitorexit 这两个字节码指令,这两个字节码需要关联到一个监视对象,当线程执行 monitorenter 指令时,需要首先获得获得监视对象的锁,这里监视对象锁就是进入同步块的凭证,只有获得了凭证才可以进入同步块,当线程离开同步块时,会执行 monitorexit 指令,释放对象锁。
在 AQS 同步中,使用一个 int 类型的变量 state 来表示当前同步块的状态。以独占式同步(一次只能有一个线程进入同步块)为例,state 的有效值有两个 0 和 1,其中 0 表示当前同步块中没有线程,1 表示同步块中已经有线程在执行。当线程要进入同步块时,需要首先判断 state 的值是否为 0,假设为 0,会尝试将 state 修改为 1,只有修改成功了之后,线程才可以进入同步块。注意上面提到的两个条件:
- state 为 0,证明当前同步块中没有线程在执行,所以当前线程可以尝试获得进入同步块的凭证,而这里的凭证就是是否成功将 state 修改为 1(在 synchronized 同步中,我们说的凭证是对象锁,但是对象锁的最终实现是否和这种方式类似,没有找到相关的资料)
- 成功将 state 修改为 1,通过使用 CAS 操作,我们可以确保即便有多个线程同时修改 state,也只有一个线程会修改成功。关于 CAS 的具体解释会在后面提到。
当线程离开同步块时,会修改 state 的值,将其设为 0,并唤醒等待的线程。所以在 AQS 同步中,我们说线程获得了锁,实际上是指线程成功修改了状态变量 state,而线程释放了锁,是指线程将状态变量置为了可修改的状态(在独占式同步中就是置为了 0),让其他线程可以再次尝试修改状态变量。在下面的表述中,我们说线程获得和释放了锁,就是上述含义, 这与 synchronized 同步中说的获得和释放锁的含义不同,需要区别理解。
基本使用
本节摘自 Java 并发编程的艺术
AQS 的设计是基于模板方法的,使用者需要继承 AQS 并重写指定的方法。在后续的流程中,AQS 提供的模板方法会调用重写的方法。一般来说,我们需要重写的方法主要有下面 5 个:
| 方法名称 | 描述 |
|---|---|
| protected boolean tryAcquire(int) | 独占式获取锁,实现该方法需要查询当前状态并判断同步状态是否和预期值相同,然后使用 CAS 操作设置同步状态 |
| protected boolean tryRelease(int) | 独占式释放锁,实际也是修改同步变量 |
| protected int tryAcquireShared(int) | 共享式获取锁,返回大于等于 0 的值,表示获取锁成功,反之获取失败 |
| protected boolean tryReleaseShared(int) | 共享式释放锁 |
| protected boolean isHeldExclusively() | 判断调用该方法的线程是否持有互斥锁 |
在自定义的同步组件中,我们一般会调用 AQS 提供的模板方法。AQS 提供的模板方法基本上分为 3 类: 独占式获取与释放锁、共享式获取与释放锁以及查询同步队列中的等待线程情况。下面是相关的模板方法:
| 方法名称 | 描述 |
|---|---|
| void acquire(int) | 独占式获取锁,如果当前线程成功获取锁,那么方法就返回,否则会将当前线程放入同步队列等待。该方法会调用重写的 tryAcquire(int arg) 方法判断是否可以获得锁 |
| void acquireInterruptibly(int) | 和 acquire(int) 相同,但是该方法响应中断,当线程在同步队列中等待时,如果线程被中断,会抛出 InterruptedException 异常并返回。 |
| boolean tryAcquireNanos(int, long) | 在 acquireInterruptibly(int) 基础上添加了超时控制,同时支持中断和超时,当在指定时间内没有获得锁时,会返回 false,获取到了返回 true |
| void acquireShared(int) | 共享式获得锁,如果成功获得锁就返回,否则将当前线程放入同步队列等待,与独占式获取锁的不同是,同一时刻可以有多个线程获得共享锁,该方法调用 tryAcquireShared(int) |
| acquireSharedInterruptibly(int) | 与 acquireShared(int) 相同,该方法响应中断 |
| tryAcquireSharedNanos(int, long) | 在 acquireSharedInterruptibly(int) 基础上添加了超时控制 |
| boolean release(int) | 独占式释放锁,该方法会在释放锁后,将同步队列中第一个等待节点唤醒 |
| boolean releaseShared(int) | 共享式释放锁 |
| Collection getQueuedThreads() | 获得同步队列中等待的线程集合 |
自定义组件通过使用同步器提供的模板方法来实现自己的同步语义。下面我们通过两个示例,看下如何借助于 AQS 来实现锁的同步语义。我们首先实现一个独占锁(排它锁),独占锁就是说在某个时刻内,只能有一个线程持有独占锁,只有持有锁的线程释放了独占锁,其他线程才可以获取独占锁。下面是具体实现:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/**
* Created by Jikai Zhang on 2017/4/6.
* <p>
* 自定义独占锁
*/
public class Mutex implements Lock {
// 通过继承 AQS,自定义同步器
private static class Sync extends AbstractQueuedSynchronizer {
// 当前线程是否被独占
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 尝试获得锁
@Override
protected boolean tryAcquire(int arg) {
// 只有当 state 的值为 0,并且线程成功将 state 值修改为 1 之后,线程才可以获得独占锁
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
// state 为 0 说明当前同步块中没有锁了,无需释放
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
// 将独占的线程设为 null
setExclusiveOwnerThread(null);
// 将状态变量的值设为 0,以便其他线程可以成功修改状态变量从而获得锁
setState(0);
return true;
}
Condition newCondition() {
return new ConditionObject();
}
}
// 将操作代理到 Sync 上
private final Sync sync = new Sync();
@Override
public void lock() {
sync.acquire(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return sync.tryAcquire(1);
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
@Override
public void unlock() {
sync.release(1);
}
@Override
public Condition newCondition() {
return sync.newCondition();
}
public boolean hasQueuedThreads() {
return sync.hasQueuedThreads();
}
public boolean isLocked() {
return sync.isHeldExclusively();
}
public static void withoutMutex() throws InterruptedException {
System.out.println("Without mutex: ");
int threadCount = 2;
final Thread threads[] = new Thread[threadCount];
for (int i = 0; i < threads.length; i++) {
final int index = i;
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 100000; j++) {
if (j % 20000 == 0) {
System.out.println("Thread-" + index + ": j =" + j);
}
}
}
});
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
for (int i = 0; i < threads.length; i++) {
threads[i].join();
}
}
public static void withMutex() {
System.out.println("With mutex: ");
final Mutex mutex = new Mutex();
int threadCount = 2;
final Thread threads[] = new Thread[threadCount];
for (int i = 0; i < threads.length; i++) {
final int index = i;
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
mutex.lock();
try {
for (int j = 0; j < 100000; j++) {
if (j % 20000 == 0) {
System.out.println("Thread-" + index + ": j =" + j);
}
}
} finally {
mutex.unlock();
}
}
});
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
}
public static void main(String[] args) throws InterruptedException {
withoutMutex();
System.out.println();
withMutex();
}
}
程序的运行结果如下面所示。我们看到使用了 Mutex 之后,线程 0 和线程 1 不会再交替执行,而是当一个线程执行完,另外一个线程再执行。
Without mutex:
Thread-0: j =0
Thread-1: j =0
Thread-0: j =20000
Thread-1: j =20000
Thread-0: j =40000
Thread-1: j =40000
Thread-0: j =60000
Thread-1: j =60000
Thread-1: j =80000
Thread-0: j =80000
With mutex:
Thread-0: j =0
Thread-0: j =20000
Thread-0: j =40000
Thread-0: j =60000
Thread-0: j =80000
Thread-1: j =0
Thread-1: j =20000
Thread-1: j =40000
Thread-1: j =60000
Thread-1: j =80000
下面在看一个共享锁的示例。在该示例中,我们定义两个共享资源,即同一时间内允许两个线程同时执行。我们将同步变量的初始状态 state 设为 2,当一个线程获取了共享锁之后,将 state 减 1,线程释放了共享锁后,将 state 加 1。状态的合法范围是 0、1 和 2,其中 0 表示已经资源已经用光了,此时线程再要获得共享锁就需要进入同步序列等待。下面是具体实现:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/**
* Created by Jikai Zhang on 2017/4/9.
* <p>
* 自定义共享锁
*/
public class TwinsLock implements Lock {
private static class Sync extends AbstractQueuedSynchronizer {
public Sync(int resourceCount) {
if (resourceCount <= 0) {
throw new IllegalArgumentException("resourceCount must be larger than zero.");
}
// 设置可以共享的资源总数
setState(resourceCount);
}
@Override
protected int tryAcquireShared(int reduceCount) {
// 使用尝试获得资源,如果成功修改了状态变量(获得了资源)
// 或者资源的总量小于 0(没有资源了),则返回。
for (; ; ) {
int lastCount = getState();
int newCount = lastCount - reduceCount;
if (newCount < 0 || compareAndSetState(lastCount, newCount)) {
return newCount;
}
}
}
@Override
protected boolean tryReleaseShared(int returnCount) {
// 释放共享资源,因为可能有多个线程同时执行,所以需要使用 CAS 操作来修改资源总数。
for (; ; ) {
int lastCount = getState();
int newCount = lastCount + returnCount;
if (compareAndSetState(lastCount, newCount)) {
return true;
}
}
}
}
// 定义两个共享资源,说明同一时间内可以有两个线程同时运行
private final Sync sync = new Sync(2);
@Override
public void lock() {
sync.acquireShared(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return sync.tryAcquireShared(1) >= 0;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
@Override
public void unlock() {
sync.releaseShared(1);
}
@Override
public Condition newCondition() {
throw new UnsupportedOperationException();
}
public static void main(String[] args) {
final Lock lock = new TwinsLock();
int threadCounts = 10;
Thread threads[] = new Thread[threadCounts];
for (int i = 0; i < threadCounts; i++) {
final int index = i;
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
lock.lock();
try {
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
}
for (int i = 0; i < threadCounts; i++) {
threads[i].start();
}
}
}
运行程序,我们会发现程序每次都会同时打印两条语句,如下面的形式,证明同时有两个线程在执行。
Thread-0
Thread-1
Thread-3
Thread-2
Thread-8
Thread-4
Thread-3
Thread-6
CAS 操作
CAS(Compare and Swap),比较并交换,通过利用底层硬件平台的特性,实现原子性操作。CAS 操作涉及到3个操作数,内存值 V,旧的期望值 A,需要修改的新值 B。当且仅当预期值 A 和 内存值 V 相同时,才将内存值 V 修改为 B,否则什么都不做。CAS 操作类似于执行了下面流程
if(oldValue == memory[valueAddress]) {
memory[valueAddress] = newValue;
}
在上面的流程中,其实涉及到了两个操作,比较以及替换,为了确保程序正确,需要确保这两个操作的原子性(也就是说确保这两个操作同时进行,中间不会有其他线程干扰)。现在的 CPU 中,提供了相关的底层 CAS 指令,即 CPU 底层指令确保了比较和交换两个操作作为一个原子操作进行(其实在这一点上还是有排他锁的. 只是比起用synchronized, 这里的排他时间要短的多.),Java 中的 CAS 函数是借助于底层的 CAS 指令来实现的。更多关于 CPU 底层实现的原理可以参考 这篇文章。我们来看下 Java 中对于 CAS 函数的定义:
/**
* Atomically update Java variable to x if it is currently
* holding expected.
* @return true if successful
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
/**
* Atomically update Java variable to x if it is currently
* holding expected.
* @return true if successful
*/
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
/**
* Atomically update Java variable to x if it is currently
* holding expected.
* @return true if successful
*/
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long x);
上面三个函数定义在 sun.misc.Unsafe 类中,使用该类可以进行一些底层的操作,例如直接操作原生内存,更多关于 Unsafe 类的文章可以参考 这篇。以 compareAndSwapInt 为例,我们看下如何使用 CAS 函数:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
/**
* Created by Jikai Zhang on 2017/4/8.
*/
public class CASIntTest {
private volatile int count = 0;
private static final Unsafe unsafe = getUnsafe();
private static final long offset;
// 获得 count 属性在 CASIntTest 中的偏移量(内存地址偏移)
static {
try {
offset = unsafe.objectFieldOffset(CASIntTest.class.getDeclaredField("count"));
} catch (NoSuchFieldException e) {
throw new Error(e);
}
}
// 通过反射的方式获得 Unsafe 类
public static Unsafe getUnsafe() {
Unsafe unsafe = null;
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return unsafe;
}
public void increment() {
int previous = count;
unsafe.compareAndSwapInt(this, offset, previous, previous + 1);
}
public static void main(String[] args) {
CASIntTest casIntTest = new CASIntTest();
casIntTest.increment();
System.out.println(casIntTest.count);
}
}
在 CASIntTest 类中,我们定义一个 count 变量,其中 increment 方法是将 count 的值加 1。下面是 increase 方法的代码:
int previous = count;
unsafe.compareAndSwapInt(this, offset, previous, previous + 1);
在没有线程竞争的条件下,该代码执行的结果是将 count 变量的值加 1(多个线程竞争可能会有线程执行失败),但是在 compareAndSwapInt 函数中,我们并没有传入 count 变量,那么函数是如何修改的 count 变量值?其实我们往 compareAndSwapInt 函数中传入了 count 变量在堆内存中的地址,函数直接修改了 count 变量所在内存区域。count 属性在堆内存中的地址是由 CASIntTest 实例的起始内存地址和 count 属性相对于起始内存的偏移量决定的。其中对象属性在对象中的偏移量通过 objectFieldOffset 函数获得,函数原型如下所示。该函数接受一个 Filed 类型的参数,返回该 Filed 属性在对象中的偏移量。
/**
* Report the location of a given static field, in conjunction with {@link
* #staticFieldBase}.
* Do not expect to perform any sort of arithmetic on this offset;
* it is just a cookie which is passed to the unsafe heap memory accessors.
*
* Any given field will always have the same offset, and no two distinct
* fields of the same class will ever have the same offset.
*
* As of 1.4.1, offsets for fields are represented as long values,
* although the Sun JVM does not use the most significant 32 bits.
* It is hard to imagine a JVM technology which needs more than
* a few bits to encode an offset within a non-array object,
* However, for consistency with other methods in this class,
* this method reports its result as a long value.
*/
public native long objectFieldOffset(Field f);
下面我们再看一下 compareAndSwapInt 的函数原型。我们知道 CAS 操作需要知道 3 个信息:内存中的值,期望的旧值以及要修改的新值。通过前面的分析,我们知道通过 o 和 offset 我们可以确定属性在内存中的地址,也就是知道了属性在内存中的值。expected 对应期望的旧址,而 x 就是要修改的新值。
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
compareAndSwapInt 函数首先比较一下 expected 是否和内存中的值相同,如果不同证明其他线程修改了属性值,那么就不会执行更新操作,但是程序如果就此返回了,似乎不太符合我们的期望,我们是希望程序可以执行更新操作的,如果其他线程先进行了更新,那么就在更新后的值的基础上进行修改,所以我们一般使用循环配合 CAS 函数,使程序在更新操作完成之后再返回,如下所示:
long before = counter;
while (!unsafe.compareAndSwapLong(this, offset, before, before + 1)) {
before = counter;
}
下面是使用 CAS 函数实现计数器的一个实例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
/**
* Created by Jikai Zhang on 2017/4/8.
*/
public class CASCounter {
// 通过反射的方式获得 Unsafe 类
public static Unsafe getUnsafe() {
Unsafe unsafe = null;
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return unsafe;
}
private volatile long counter = 0;
private static final long offset;
private static final Unsafe unsafe = getUnsafe();
static {
try {
offset = unsafe.objectFieldOffset(CASCounter.class.getDeclaredField("counter"));
} catch (NoSuchFieldException e) {
throw new Error(e);
}
}
public void increment() {
long before = counter;
while (!unsafe.compareAndSwapLong(this, offset, before, before + 1)) {
before = counter;
}
}
public long getCounter() {
return counter;
}
private static long intCounter = 0;
public static void main(String[] args) throws InterruptedException {
int threadCount = 10;
Thread threads[] = new Thread[threadCount];
final CASCounter casCounter = new CASCounter();
for (int i = 0; i < threadCount; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
casCounter.increment();
intCounter++;
}
}
});
threads[i].start();
}
for(int i = 0; i < threadCount; i++) {
threads[i].join();
}
System.out.printf("CASCounter is %d \nintCounter is %d\n", casCounter.getCounter(), intCounter);
}
}
在 AQS 中,对原始的 CAS 函数封装了一下,省去了获得变量地址的步骤,如下面的形式:
private static final long waitStatusOffset;
static {
try {
waitStatusOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("waitStatus"));
} catch (Exception ex) {
throw new Error(ex);
}
}
private static final boolean compareAndSetWaitStatus(Node node, int expect, int update) {
return unsafe.compareAndSwapInt(node, waitStatusOffset, expect, update);
}
同步队列
AQS 依赖内部的同步队列(一个 FIFO的双向队列)来完成同步状态的管理,当前线程获取同步状态失败时,同步器会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,会把队列中第一个等待节点线程唤醒(下图中的 Node1),使其再次尝试获取同步状态。同步队列的结构如下所示:

图片来自 http://www.infoq.com/cn/articles/jdk1.8-abstractqueuedsynchronizer
Head 节点本身不保存等待线程的信息,它通过 next 变量指向第一个保存线程等待信息的节点(Node1)。当线程被唤醒之后,会删除 Head 节点,而唤醒线程所在的节点会设置为 Head 节点(Node1 被唤醒之后,Node1会被置为 Head 节点)。下面我们看下 JDK 中同步队列的实现。
Node 类
首先看在节点所对应的 Node 类:
static final class Node {
/**
* 标志是独占式模式还是共享模式
*/
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
/**
* 线程等待状态的有效值
*/
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
/**
* 线程状态,合法值为上面 4 个值中的一个
*/
volatile int waitStatus;
/**
* 当前节点的前置节点
*/
volatile Node prev;
/**
* 当前节点的后置节点
*/
volatile Node next;
/**
* 当前节点所关联的线程
*/
volatile Thread thread;
/**
* 指向下一个在某个条件上等待的节点,或者指向 SHARE 节点,表明当前处于共享模式
*/
Node nextWaiter;
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
在 Node 类中定义了四种等待状态:
- CANCELED: 1,因为等待超时 (timeout)或者中断(interrupt),节点会被置为取消状态。处于取消状态的节点不会再去竞争锁,也就是说不会再被阻塞。节点会一直保持取消状态,而不会转换为其他状态。处于 CANCELED 的节点会被移出队列,被 GC 回收。
- SIGNAL: -1,表明当前的后继结点正在或者将要被阻塞(通过使用 LockSupport.pack 方法),因此当前的节点被释放(release)或者被取消时(cancel)时,要唤醒它的后继结点(通过 LockSupport.unpark 方法)。
- CONDITION: -2,表明当前节点在条件队列中,因为等待某个条件而被阻塞。
- PROPAGATE: -3,在共享模式下,可以认为资源有多个,因此当前线程被唤醒之后,可能还有剩余的资源可以唤醒其他线程。该状态用来表明后续节点会传播唤醒的操作。需要注意的是只有头节点才可以设置为该状态(This is set (for head node only) in doReleaseShared to ensure propagation continues, even if other operations have since intervened.)。
- 0:新创建的节点会处于这种状态
独占锁的获取和释放
我们首先看下独占锁的获取和释放过程
独占锁获取
下面是获取独占锁的流程图:
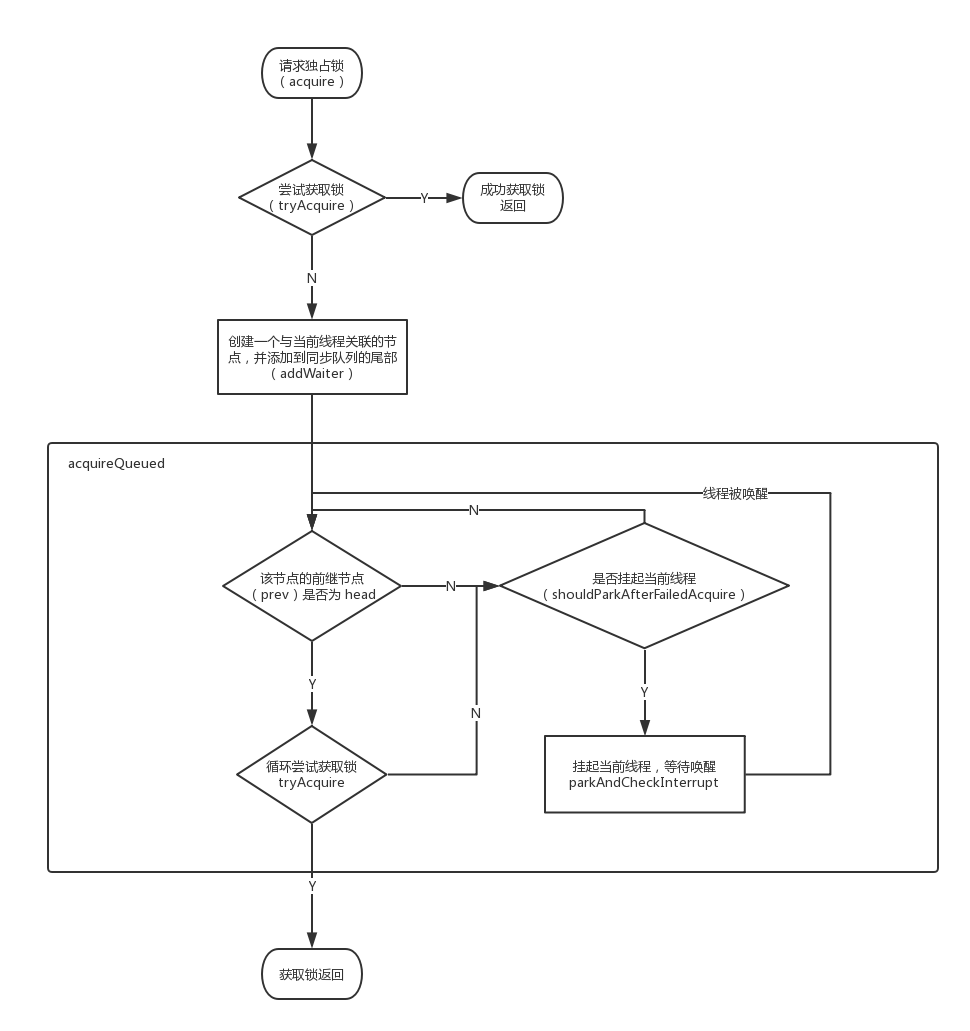
我们通过 acquire 方法来获取独占锁,下面是方法定义
public final void acquire(int arg) {
// 首先尝试获取锁,如果获取失败,会先调用 addWaiter 方法创建节点并追加到队列尾部
// 然后调用 acquireQueued 阻塞或者循环尝试获取锁
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)){
// 在 acquireQueued 中,如果线程是因为中断而退出的阻塞状态会返回 true
// 这里的 selfInterrupt 主要是为了恢复线程的中断状态
selfInterrupt();
}
}
acquire 会首先调用 tryAcquire 方法来获得锁,该方法需要我们来实现,这个在前面已经提过了。如果没有获取锁,会调用 addWaiter 方法创建一个和当前线程关联的节点追加到同步队列的尾部,我们调用 addWaiter 时传入的是 Node.EXCLUSIVE,表明当前是独占模式。下面是 addWaiter 的具体实现
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// tail 指向同步队列的尾节点
Node pred = tail;
// Try the fast path of enq; backup to full enq on failure
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
addWaiter 方法会首先调用 if 方法,来判断能否成功将节点添加到队列尾部,如果添加失败,再调用 enq 方法(使用循环不断重试)进行添加,下面是 enq 方法的实现:
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// 同步队列采用的懒初始化(lazily initialized)的方式,
// 初始时 head 和 tail 都会被设置为 null,当一次被访问时
// 才会创建 head 对象,并把尾指针指向 head。
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
addWaiter 仅仅是将节点加到了同步队列的末尾,并没有阻塞线程,线程阻塞的操作是在 acquireQueued 方法中完成的,下面是 acquireQueued 的实现:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
// 如果当前节点的前继节点是 head,就使用自旋(循环)的方式不断请求锁
if (p == head && tryAcquire(arg)) {
// 成功获得锁,将当前节点置为 head 节点,同时删除原 head 节点
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// shouldParkAfterFailedAcquire 检查是否可以挂起线程,
// 如果可以挂起进程,会调用 parkAndCheckInterrupt 挂起线程,
// 如果 parkAndCheckInterrupt 返回 true,表明当前线程是因为中断而退出挂起状态的,
// 所以要将 interrupted 设为 true,表明当前线程被中断过
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
acquireQueued 会首先检查当前节点的前继节点是否为 head,如果为 head,将使用自旋的方式不断的请求锁,如果不是 head,则调用 shouldParkAfterFailedAcquire 查看是否应该挂起当前节点关联的线程,下面是 shouldParkAfterFailedAcquire 的实现:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 当前节点的前继节点的等待状态
int ws = pred.waitStatus;
// 如果前继节点的等待状态为 SIGNAL 我们就可以将当前节点对应的线程挂起
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
// ws 大于 0,表明当前线程的前继节点处于 CANCELED 的状态,
// 所以我们需要从当前节点开始往前查找,直到找到第一个不为
// CAECELED 状态的节点
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
shouldParkAfterFailedAcquire 会检查前继节点的等待状态,如果前继节点状态为 SIGNAL,则可以将当前节点关联的线程挂起,如果不是 SIGNAL,会做一些其他的操作,在当前循环中不会挂起线程。如果确定了可以挂起线程,就调用 parkAndCheckInterrupt 方法对线程进行阻塞:
private final boolean parkAndCheckInterrupt() {
// 挂起当前线程
LockSupport.park(this);
// 可以通过调用 interrupt 方法使线程退出 park 状态,
// 为了使线程在后面的循环中还可以响应中断,会重置线程的中断状态。
// 这里使用 interrupted 会先返回线程当前的中断状态,然后将中断状态重置为 false,
// 线程的中断状态会返回给上层调用函数,在线程获得锁后,
// 如果发现线程曾被中断过,会将中断状态重新设为 true
return Thread.interrupted();
}
独占锁释放
下面是释放独占锁的流程:
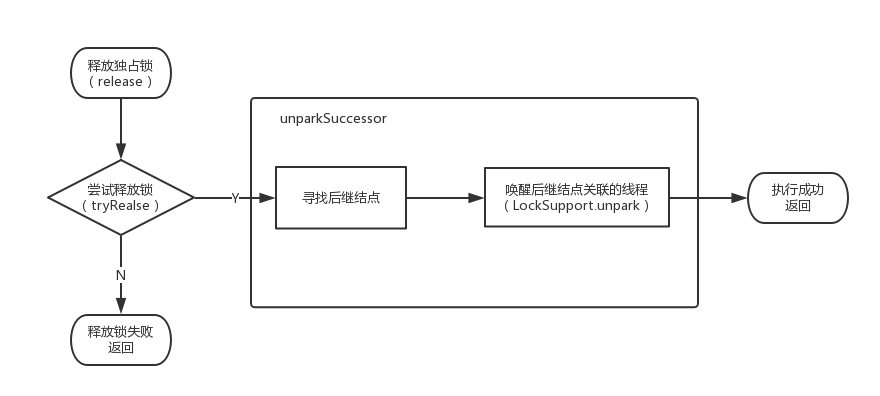
通过 release 方法,我们可以释放互斥锁。下面是 release 方法的实现:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
// waitStatus 为 0,证明是初始化的空队列或者后继结点已经被唤醒了
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
在独占模式下释放锁时,是没有其他线程竞争的,所以处理会简单一些。首先尝试释放锁,如果失败就直接返回(失败不是因为多线程竞争,而是线程本身就不拥有锁)。如果成功的话,会检查 h 的状态,然后调用 unparkSuccessor 方法来唤醒后续线程。下面是 unparkSuccessor 的实现:
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
// 将 head 节点的状态置为 0,表明当前节点的后续节点已经被唤醒了,
// 不需要再次唤醒,修改 ws 状态主要作用于 release 的判断
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
在 unparkSuccessor 方法中,如果发现头节点的后继结点为 null 或者处于 CANCELED 状态,会从尾部往前找(在节点存在的前提下,这样一定能找到)离头节点最近的需要唤醒的节点,然后唤醒该节点。
共享锁获取和释放
独占锁的流程和原理比较容易理解,因为只有一个锁,但是共享锁的处理就相对复杂一些了。在独占锁中,只有在释放锁之后,才能唤醒等待的线程,而在共享模式中,获取锁和释放锁之后,都有可能唤醒等待的线程。如果想要理清共享锁的工作过程,必须将共享锁的获取和释放结合起来看。这里我们先看一下共享锁的释放过程,只有明白了释放过程做了哪些工作,才能更好的理解获取锁的过程。
共享锁释放
下面是释放共享锁的流程:
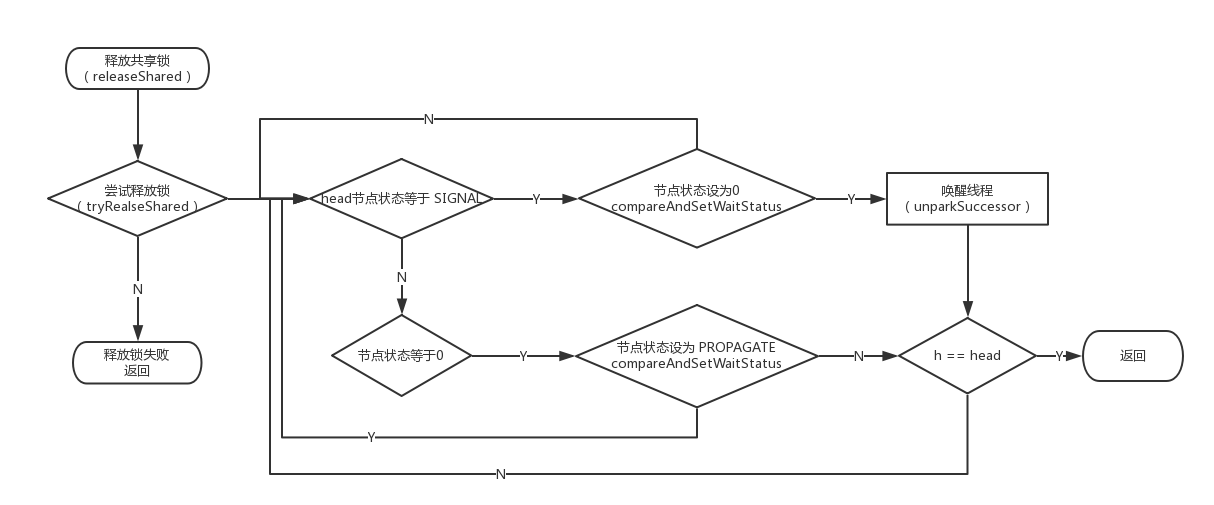
通过 releaseShared 方法会释放共享锁,下面是具体的实现:
public final boolean releaseShared(int releases) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
releases 是要释放的共享资源数量,其中 tryReleaseShared 的方法由我们自己重写,该方法的主要功能就是修改共享资源的数量(state + releases),因为可能会有多个线程同时释放资源,所以实现的时候,一般采用循环加 CAS 操作的方式,如下面的形式:
protected boolean tryReleaseShared(int releases) {
// 释放共享资源,因为可能有多个线程同时执行,所以需要使用 CAS 操作来修改资源总数。
for (;;) {
int lastCount = getState();
int newCount = lastCount + releases;
if (compareAndSetState(lastCount, newCount)) {
return true;
}
}
}
当共享资源数量修改了之后,会调用 doReleaseShared 方法,该方法主要唤醒同步队列中的第一个等待节点(head.next),下面是具体实现:
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
for (;;) {
Node h = head;
// head = null 说明没有初始化,head = tail 说明同步队列中没有等待节点
if (h != null && h != tail) {
// 查看当前节点的等待状态
int ws = h.waitStatus;
// 我们在前面说过,SIGNAL说明有后续节点需要唤醒
if (ws == Node.SIGNAL) {
/*
* 将当前节点的值设为 0,表明已经唤醒了后继节点
* 可能会有多个线程同时执行到这一步,所以使用 CAS 保证只有一个线程能修改成功,
* 从而执行 unparkSuccessor,其他的线程会执行 continue 操作
*/
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
} else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) {
/*
* ws 等于 0,说明无需唤醒后继结点(后续节点已经被唤醒或者当前节点没有被阻塞的后继结点),
* 也就是这一次的调用其实并没有执行唤醒后继结点的操作。就类似于我只需要一张优惠券,
* 但是我的两个朋友,他们分别给我了一张,因此我就剩余了一张。然后我就将这张剩余的优惠券
* 送(传播)给其他人使用,因此这里将节点置为可传播的状态(PROPAGATE)
*/
continue; // loop on failed CAS
}
}
if (h == head) // loop if head changed
break;
}
}
从上面的实现中,doReleaseShared 的主要作用是用来唤醒阻塞的节点并且一次只唤醒一个,让该节点关联的线程去重新竞争锁,它既不修改同步队列,也不修改共享资源。
当多个线程同时释放资源时,可以确保两件事:
- 共享资源的数量能正确的累加
- 至少有一个线程被唤醒,其实只要确保有一个线程被唤醒就可以了,即便唤醒了多个线程,在同一时刻,也只能有一个线程能得到竞争锁的资格,在下面我们会看到。
所以释放锁做的主要工作还是修改共享资源的数量。而有了多个共享资源后,如何确保同步队列中的多个节点可以获取锁,是由获取锁的逻辑完成的。下面看下共享锁的获取。
共享锁的获取
下面是获取共享锁的流程

通过 acquireShared 方法,我们可以申请共享锁,下面是具体的实现:
public final void acquireShared(int arg) {
// 如果返回结果小于 0,证明没有获取到共享资源
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
如果没有获取到共享资源,就会执行 doAcquireShared 方法,下面是该方法的具体实现:
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
从上面的代码中可以看到,只有前置节点为 head 的节点才有可能去竞争锁,这点和独占模式的处理是一样的,所以即便唤醒了多个线程,也只有一个线程能进入竞争锁的逻辑,其余线程会再次进入 park 状态,当线程获取到共享锁之后,会执行 setHeadAndPropagate 方法,下面是具体的实现:
private void setHeadAndPropagate(Node node, long propagate) {
// 备份一下头节点
Node h = head; // Record old head for check below
/*
* 移除头节点,并将当前节点置为头节点
* 当执行完这一步之后,其实队列的头节点已经发生改变,
* 其他被唤醒的线程就有机会去获取锁,从而并发的执行该方法,
* 所以上面备份头节点,以便下面的代码可以正确运行
*/
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
/*
* 判断是否需要唤醒后继结点,propagate > 0 说明共享资源有剩余,
* h.waitStatus < 0,表明当前节点状态可能为 SIGNAL,CONDITION,PROPAGATE
*/
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
// 只有 s 不处于独占模式时,才去唤醒后继结点
if (s == null || s.isShared())
doReleaseShared();
}
}
判断后继结点是否需要唤醒的条件是十分宽松的,也就是一定包含必要的唤醒,但是也有可能会包含不必要的唤醒。从前面我们可以知道 doReleaseShared 函数的主要作用是唤醒后继结点,它既不修改共享资源,也不修改同步队列,所以即便有不必要的唤醒也是不影响程序正确性的。如果没有共享资源,节点会再次进入等待状态。
到了这里,脉络就比较清晰了,当一个节点获取到共享锁之后,它除了将自身设为 head 节点之外,还会判断一下是否满足唤醒后继结点的条件,如果满足,就唤醒后继结点,后继结点获取到锁之后,会重复这个过程,直到判断条件不成立。就类似于考试时从第一排往最后一排传卷子,第一排先留下一份,然后将剩余的传给后一排,后一排会重复这个过程。如果传到某一排卷子没了,那么位于这排的人就要等待,直到老师又给了他新的卷子。
中断
在获取锁时还可以设置响应中断,独占锁和共享锁的处理逻辑类似,这里我们以独占锁为例。使用 acquireInterruptibly 方法,在获取独占锁时可以响应中断,下面是具体的实现:
public final void acquireInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
private void doAcquireInterruptibly(int arg) throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) {
// 这里会抛出异常
throw new InterruptedException();
}
}
} finally {
if (failed)
cancelAcquire(node);
}
}
从上面的代码中我们可以看出,acquireInterruptibly 和 acquire 的逻辑类似,只是在下面的代码处有所不同:当线程因为中断而退出阻塞状态时,会直接抛出 InterruptedException 异常。
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) {
// 这里会抛出异常
throw new InterruptedException();
}
我们知道,不管是抛出异常还是方法返回,程序都会执行 finally 代码,而 failed 肯定为 true,所以抛出异常之后会执行 cancelAcquire 方法,cancelAcquire 方法主要将节点从同步队列中移除。下面是具体的实现:
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
if (node == null)
return;
node.thread = null;
// 跳过前面的已经取消的节点
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// 保存下 pred 的后继结点,以便 CAS 操作使用
// 因为可能存在已经取消的节点,所以 pred.next 不一等于 node
Node predNext = pred.next;
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
// 将节点状态设为 CANCELED
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
从上面的代码可以看出,节点的删除分为三种情况:
- 删除节点为尾节点,直接将该节点的第一个有效前置节点置为尾节点
- 删除节点的前置节点为头节点,则对该节点执行 unparkSuccessor 操作
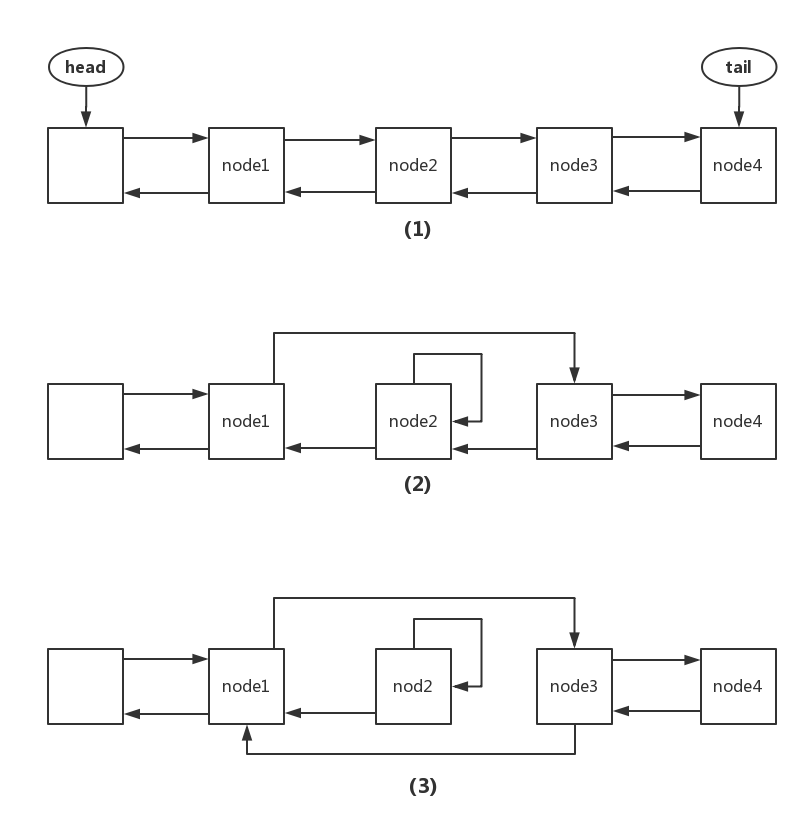
- 删除节点为中间节点,结果如下图所示。下图中(1)表示同步队列的初始状态,假设删除 node2, node1 是正常节点(非 CANCELED),(2)就是删除 node2 后同步队列的状态,此时 node1 节点的后继已经变为 node3,也就是说当 node1 变为 head 之后,会直接唤醒 node3。当另外的一个节点中断之后再次执行 cancelAcquire,在执行下面的代码时,会使同步队列的状态由(2)变为(3),此时 node2 已经没有外界指针了,可以被回收了。如果一直没有另外一个节点中断,也就是同步队列一直处于(2)状态,那么需要等 node3 被回收之后,node2 才可以被回收。
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
超时
超时是在中断的基础上加了一层时间的判断,这里我们还是以独占锁为例。 tryAcquireNanos 支持获取锁的超时处理,下面是具体实现:
public final boolean tryAcquireNanos(int arg, long nanosTimeout) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) || doAcquireNanos(arg, nanosTimeout);
}
当获取锁失败之后,会执行 doAcquireNanos 方法,下面是具体实现:
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException {
if (nanosTimeout <= 0 L)
return false;
// 线程最晚结束时间
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
// 判断是否超时,如果超时就返回
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0 L)
return false;
// 这里如果设定了一个阈值,如果超时的时间比阈值小,就认为
// 当前线程没必要阻塞,再执行几次 for 循环估计就超时了
if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
当线程超时返回时,还是会执行 cancelAcquire 方法,cancelAcquire 的逻辑已经在前面说过了,这里不再赘述。
参考文章
- Java 并发编程的艺术
- Java Magic. Part 4: sun.misc.Unsafe
- Java里的CompareAndSet(CAS)
- ReentrantLock的lock-unlock流程详解
- 深入JVM锁机制2-Lock
- 深度解析Java 8:JDK1.8 AbstractQueuedSynchronizer的实现分析(上)
- AbstractQueuedSynchronizer源码分析
- 聊聊并发(十二)—AQS分析
- AbstractQueuedSynchronizer (AQS)
- 并发编程实践二:AbstractQueuedSynchronizer
【Java并发】详解 AbstractQueuedSynchronizer的更多相关文章
- java 并发 详解
1 普通线程和 守护线程的区别. 守护线程会跟随主线程的结束而结束,普通线程不会. 2 线程的 stop 和 interrupted 的区别. stop 会停止线程,但是不会释放锁之类的资源? in ...
- Java虚拟机详解----JVM常见问题总结
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- Java面向对象详解
Java面向对象详解 前言:接触项目开发也有很长一段时间了,最近开始萌发出想回过头来写写以前学 过的基础知识的想法.一是原来刚开始学习接触编程,一个人跌跌撞撞摸索着往前走,初学的时候很多东西理解的也懵 ...
- Java synchronized 详解
Java synchronized 详解 Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码. 1.当两个并发线程访问同一个对象object ...
- Java集合详解3:Iterator,fail-fast机制与比较器
Java集合详解3:Iterator,fail-fast机制与比较器 今天我们来探索一下LIterator,fail-fast机制与比较器的源码. 具体代码在我的GitHub中可以找到 https:/ ...
- Java集合详解4:一文读懂HashMap和HashTable的区别以及常见面试题
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解3:一文读懂Iterator,fail-fast机制与比较器
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java 集合详解 | 一篇文章解决Java 三大集合
更好阅读体验:Java 集合详解 | 一篇文章搞定Java 三大集合 好看的皮囊像是一个个容器,有趣的灵魂像是容器里的数据.接下来讲解Java集合数据容器. 文章篇幅有点长,还请耐心阅读.如只是为了解 ...
- Java内部类详解
Java内部类详解 说起内部类这个词,想必很多人都不陌生,但是又会觉得不熟悉.原因是平时编写代码时可能用到的场景不多,用得最多的是在有事件监听的情况下,并且即使用到也很少去总结内部类的用法.今天我们就 ...
- 黑马----JAVA迭代器详解
JAVA迭代器详解 1.Interable.Iterator和ListIterator 1)迭代器生成接口Interable,用于生成一个具体迭代器 public interface Iterable ...
随机推荐
- 「征文」在 cordova 中使用极光统计服务
写在前面:年前的时候,极光社区组织了一场征文活动 ,收到不少好的文章.现在打算和大家一起分享一下这些优秀的作品 :) 作者:Wilhan - 极光 原文:在 cordova 中使用极光统计服务 正文 ...
- Java设计模式之《代理模式》及应用场景
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6525527.html 代理模式算是我接触较早的模式,代理就是中介,中间人.法律上也有代理, ...
- 【JS】JavaScript中的参数传递
ECMAScript中所有函数的参数都是按值传递的,简单讲就是函数外部的值 复制给函数内部的参数,就和把值从一个变量复制到另一个变量一样.切记访问变量有按值访问和按引用访问,而参数只能按值传递. 在向 ...
- HTTPS 为什么更安全,先了解一下密码学的这些原理
HTTPS 是建立在密码学基础之上的一种安全通信协议,严格来说是基于 HTTP 协议和 SSL/TLS 的组合.理解 HTTPS 之前有必要弄清楚一些密码学的相关基础概念,比如:明文.密文.密码.密钥 ...
- ASP.NET脚本过滤-防止跨站脚本攻击(收集别人的)
ASP.Net 1.1后引入了对提交表单自动检查是否存在XSS(跨站脚本攻击)的能力.当用户试图用<xxxx>之类的输入影响页面返回结果的时候,ASP.Net的引擎会引发一个 HttpRe ...
- Bootsrap 的 Carousel
一.简介 Carousel 就是指轮播图,这里 有完整的代码例子.它可以很简单的就构造出来,结构如下: div.carousel.slide[data-ride="carousel" ...
- (21)IO流之对象的序列化和反序列化流ObjectOutputStream和ObjectInputStream
当创建对象时,程序运行时它就会存在,但是程序停止时,对象也就消失了.但是如果希望对象在程序不运行的情况下仍能存在并保存其信息,将会非常有用,对象将被重建并且拥有与程序上次运行时拥有的信息相同.可以使用 ...
- yii2.0自带email
大部分框架都有自带的email邮件发送类,yii的邮件发送也很简单,代码如下: 修改配置文件,普通版在(config/web.php).高级版默认配置在/common/config/main-loca ...
- 【Unity优化】如何实现Unity编辑器中的协程
Unity编辑器中何时需要协程 当我们定制Unity编辑器的时候,往往需要启动额外的协程或者线程进行处理.比如当执行一些界面更新的时候,需要大量计算,如果用户在不断修正一个参数,比如从1变化到2,这种 ...
- 一场完美的“秒杀”:API加速的业务逻辑
清晨,我被一个客户电话惊醒,客户异常焦急,寻问CDN能不能帮助他们解决“秒杀”的问题,他们昨天刚刚进行了“整点秒杀活动”,结果并发量过大,导致服务宕机,用户投诉. 为了理清思路,我问了对方三个问题: ...