HashMap 学习笔记
先摆上JDK1.8中HashMap的类注释;我翻译了一下
/**
* Hash table based implementation of the <tt>Map</tt> interface. This
* implementation provides all of the optional map operations, and permits
* <tt>null</tt> values and the <tt>null</tt> key. (The <tt>HashMap</tt>
* class is roughly equivalent to <tt>Hashtable</tt>, except that it is
* unsynchronized and permits nulls.) This class makes no guarantees as to
* the order of the map; in particular, it does not guarantee that the order
* will remain constant over time.
* 哈希表实现了Map接口.哈希表允许空的键和值.HashMap相当于Hashtable,只是它是线程不同步的且允许空值.
* 这个实现类不保证映射的顺序,尤其是随着时间变化不保证映射的顺序不发生变化.
*
* <p>This implementation provides constant-time performance for the basic
* operations (<tt>get</tt> and <tt>put</tt>), assuming the hash function
* disperses the elements properly among the buckets. Iteration over
* collection views requires time proportional to the "capacity" of the
* <tt>HashMap</tt> instance (the number of buckets) plus its size (the number
* of key-value mappings). Thus, it's very important not to set the initial
* capacity too high (or the load factor too low) if iteration performance is
* important.
* 当哈希表中的元素都是正常分布的,get,put操作时间复杂度都是O(1).迭代一个哈希表所需要的时间与哈希表的容量成正比,
* 因此如果迭代性能不是很重要,不要将初始容量设置太高(或负载因子太低).
*
* <p>An instance of <tt>HashMap</tt> has two parameters that affect its
* performance: <i>initial capacity</i> and <i>load factor</i>. The
* <i>capacity</i> is the number of buckets in the hash table, and the initial
* capacity is simply the capacity at the time the hash table is created. The
* <i>load factor</i> is a measure of how full the hash table is allowed to
* get before its capacity is automatically increased. When the number of
* entries in the hash table exceeds the product of the load factor and the
* current capacity, the hash table is <i>rehashed</i> (that is, internal data
* structures are rebuilt) so that the hash table has approximately twice the
* number of buckets.
* 一个HashMap两个参数会影响它的性能,初始容量和负载因子.容量是哈希表中的数据量,初始容量只是创建哈希表时的指定的哈希表容量.
* 负载因子loadFactor= HashMap中的数据量/HashMap中的总容量(initial capacity),map中的数据量达到 总容量*负载因子时,
* HashMap的总容量就会自动扩张一倍.
* 注:HashMap的三个构造函数能帮助理解,见本人博客 "HashMap构造函数"
*
*
* <p>As a general rule, the default load factor (.75) offers a good
* tradeoff between time and space costs. Higher values decrease the
* space overhead but increase the lookup cost (reflected in most of
* the operations of the <tt>HashMap</tt> class, including
* <tt>get</tt> and <tt>put</tt>). The expected number of entries in
* the map and its load factor should be taken into account when
* setting its initial capacity, so as to minimize the number of
* rehash operations. If the initial capacity is greater than the
* maximum number of entries divided by the load factor, no rehash
* operations will ever occur.
* 作为一般规则,默认负载因子是0.75,这在时间成本和空间成本之间提供了一个比较好的平衡.
* 较高的值会降低空间开销,但增加查找成本(大部分体现在对HashMap的操作上,比如get,put).
* 在设置初始容量时,应当考虑map中的数据量和负载因子,以便最小化重新对map结构进行扩容的操作.
* 注:这和ArrayList的ensureCapaciry(int size)有点类似.
*
*
* <p>If many mappings are to be stored in a <tt>HashMap</tt>
* instance, creating it with a sufficiently large capacity will allow
* the mappings to be stored more efficiently than letting it perform
* automatic rehashing as needed to grow the table. Note that using
* many keys with the same {@code hashCode()} is a sure way to slow
* down performance of any hash table. To ameliorate impact, when keys
* are {@link Comparable}, this class may use comparison order among
* keys to help break ties.
* 如果许多映射要存储在HashMap实例中,那么将实例的初始容量设置比较大要比按需要自动扩容效率要高.
* 请注意,使用相同的键(hashCode)是降低任何哈希表的一个可靠方法,为了改善这种性能问题,使用
* 连续的键.
* 注:hashMap允许相同的key,只是值会被覆盖.
*
* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a hash map concurrently, and at least one of
* the threads modifies the map structurally, it <i>must</i> be
* synchronized externally. (A structural modification is any operation
* that adds or deletes one or more mappings; merely changing the value
* associated with a key that an instance already contains is not a
* structural modification.) This is typically accomplished by
* synchronizing on some object that naturally encapsulates the map.
* 注意,此实现线程不同步.如果多个线程同时访问hashMap,其中有一个线程修改了hashMap的结构.那么必须在
* 外部进行线程同步处理.这通常是对hashMap的操作上进行同步处理封装
*
* If no such object exists, the map should be "wrapped" using the
* {@link Collections#synchronizedMap Collections.synchronizedMap}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the map:<pre>
* Map m = Collections.synchronizedMap(new HashMap(...));</pre>
* 因为线程同步问题,可以调用Collections.synchronizedMap来(Map<K,V> m)来返回一个线程安全的hashMap.
*
* <p>The iterators returned by all of this class's "collection view methods"
* are <i>fail-fast</i>: if the map is structurally modified at any time after
* the iterator is created, in any way except through the iterator's own
* <tt>remove</tt> method, the iterator will throw a
* {@link ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than risking
* arbitrary, non-deterministic behavior at an undetermined time in the
* future.
* hashMap同样是快速失败机制.参考我的博客 "Iterator fail-fast"
*
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw <tt>ConcurrentModificationException</tt> on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>the fail-fast behavior of iterators
* should be used only to detect bugs.</i>
* 快速失败机制,是一种错误检测机制.它只能被用来检测错误,JDK并不保证fail-fast一定会发生.
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
*
* @author Doug Lea
* @author Josh Bloch
* @author Arthur van Hoff
* @author Neal Gafter
* @see Object#hashCode()
* @see Collection
* @see Map
* @see TreeMap
* @see Hashtable
* @since 1.2
*/ public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
总结
1.数据结构
初始化一个HashMap<String,String>,存储了一些测试数据,
Map map = new HashMap();
map.put("What", "chenyz");
map.put("You", "chenyz");
map.put("Don't", "chenyz");
map.put("Know", "chenyz");
map.put("About", "chenyz");
map.put("Geo", "chenyz");
map.put("APIs", "chenyz");
map.put("Can't", "chenyz");
map.put("Hurt", "chenyz");
map.put("you", "chenyz");
map.put("google", "chenyz");
map.put("map", "chenyz");
map.put("hello", "chenyz");
// 每个<k,v>的hash(key)如下:
// What-->hash值:8
// You-->hash值:3
// Don't-->hash值:7
// Know-->hash值:13
// About-->hash值:11
// Geo-->hash值:12
// APIs-->hash值:1
// Can't-->hash值:7
// Hurt-->hash值:1
// you-->hash值:10
// google-->hash值:3
// map-->hash值:8
// hello-->hash值:0
此时HashMap的内部如 图1:
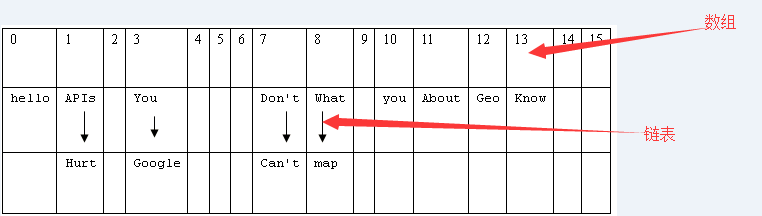
在Java中,最基础的数据类型是数组和链表,HashMap是两者结合体。所以在数据结构中被称作“链表散列”。每创建一个HashMap,就初始化一个数组。
关于这个数组源码是这样定义的:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
* 该表首先使用初始化,并根据需要调整大小.分配时长度总是2的幂.
* (这个数组的长度有些时候也允许为0)
*/
transient Node<K,V>[] table; static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
所以,数组中存储的是一个Map.Entry<K,V>,它由hash,key,value,next组成。next是指向下一个元素的引用,这就形成了链表。
2.存储元素
源码如下 :
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} /**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
不难理解,首先hash(key)得到key的哈希值,这些值就是“数据结构”中数组的元素。根据hash值确定当前元素的存储格子,如果当前格子已经存储了元素,那么就以链表形式
存到这个格子中,新加入的放在链表的头部,所以最早加入的就被排在了链尾部。如图1中hash值为1的位置,就以链表的形式存储了两个值。
每一次添加元素都会修改modCount全局变量,这是是用来检测HashMap在迭代的过程中是否发生了结构变化
同时这里还会设计到扩容resize().详见“HashMap负载因子”
3.索引元素
源码如下:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
首先计算出key的hash值,找到数组中对应的下标,然后通过key的equals方法匹配出对应位置的链表中的元素,这就完成了元素get的操作。这也是为什么要成对复写hashCode
和equals方法的原因。由此可知HashMap的get操作,效率会有瓶颈,如果一个位置存放了大量的元素,由于是链表存储的,就需要挨个比对,才能找到匹配的值。
所以让HashMap中的元素均匀的分布,每个位置上的链表只存储一个元素那么HashMap的效率就会很高。
4.性能因素
创建一个HashMap时,有initialCapacity和loadFactor这两个初始化参数,初始容量和负载因子。
这两个参数的设置会决定一个HashMap结构是否合理。详见“HashMap 负载因子”
5.hash算法
这是整个HashMap最核心的方法了,因为get(),put()操作都会用到这个方法,用于定位。确定新元素的存放位置。这关系着元素分布是否合理。
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这与以往jdk中有些区别,至于为什么这样计算,目前还在学习中。
6.安全问题
HashMap线程不同步,采用fail-fast机制。多线程下,在迭代器中,如果有线程修改了HashMap结构,会抛出 Java.util.ConcurrentModificationException异常
学海无涯,学习是苦涩的.坚持,看了两天了,还有很多不明白的地方,不放弃,持续更新。
谢谢一下同仁的分享
参考资料:
深入浅出 Java Concurrency (17): 并发容器 part 2 ConcurrentMap (2)
HashMap 学习笔记的更多相关文章
- HashMap学习笔记
概述 HashMap是Map接口的一个哈希表的实现,内部是一个数组表示的.数组中的元素叫做一个Node,一个Node可以一个是一个简单的表示键值对的二元组,也可以是一个复杂的TreeNod ...
- Java HashMap学习笔记
1.HashMap数据结构 在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外.HashMap实际 ...
- 基于jdk1.8的HashMap源码学习笔记
作为一种最为常用的容器,同时也是效率比较高的容器,HashMap当之无愧.所以自己这次jdk源码学习,就从HashMap开始吧,当然水平有限,有不正确的地方,欢迎指正,促进共同学习进步,就是喜欢程序员 ...
- java集合类学习笔记之HashMap
1.简述 HashMap是java语言中非常典型的数据结构,也是我们平常用的最多的的集合类之一.它的底层是通过一个单向链表(Node<k,v>)数组(也称之为桶bucket,数组的长度也叫 ...
- HashMap源码剖析及实现原理分析(学习笔记)
一.需求 最近开发中,总是需要使用HashMap,而为了更好的开发以及理解HashMap:因此特定重新去看HashMap的源码并写下学习笔记,以便以后查阅. 二.HashMap的学习理解 1.我们首先 ...
- Redis学习笔记4-Redis配置详解
在Redis中直接启动redis-server服务时, 采用的是默认的配置文件.采用redis-server xxx.conf 这样的方式可以按照指定的配置文件来运行Redis服务.按照本Redi ...
- 《Java学习笔记(第8版)》学习指导
<Java学习笔记(第8版)>学习指导 目录 图书简况 学习指导 第一章 Java平台概论 第二章 从JDK到IDE 第三章 基础语法 第四章 认识对象 第五章 对象封装 第六章 继承与多 ...
- [原创]java WEB学习笔记109:Spring学习---spring对JDBC的支持:使用 JdbcTemplate 查询数据库,简化 JDBC 模板查询,在 JDBC 模板中使用具名参数两种实现
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
随机推荐
- Visual Studio 2017正式版安装
Visual Studio号称宇宙第一IDE, 2017年3月7日强大的微软帝国时隔两年多终于发布新一代IDE Visual Studio 2017.支持的功能简直不能太多,详情移步:https:// ...
- Spring+SpringMVC+MyBatis+easyUI整合基础篇(十二)阶段总结
不知不觉,已经到了基础篇的收尾阶段了,看着前面的十几篇文章,真的有点不敢相信,自己竟然真的坚持了下来,虽然过程中也有过懒散和焦虑,不过结果还是自己所希望的,克服了很多的问题,将自己的作品展现出来,也发 ...
- Django HTTP处理流程(自我总结)
Django中由wsgi模块接管http请求,核心处理方法为get_wsgi_application,其定义如下: def get_wsgi_application(): ""&q ...
- 学学简单的-------------javaScript基础
首先知道什么是JavaScript? JavaScript是一种描述性语言,也是一种基于对象和事件驱动的.并具有安全性的脚本语言. 2.JavaScript由三部分组成:①ecmascript ②Bo ...
- 《连载 | 物联网框架ServerSuperIO教程》- 16.OPC Server的使用步骤。附:3.3 发布与版本更新说明。
1.C#跨平台物联网通讯框架ServerSuperIO(SSIO)介绍 <连载 | 物联网框架ServerSuperIO教程>1.4种通讯模式机制. <连载 | 物联网框架Serve ...
- USB PE
To put WinPE on a USB Stick, you must first make it bootable. Warning: This will destroy all the dat ...
- 零件库管理信息系统设计--part03:管理员登录部分设计
兄弟们,我又回来啦! 上次我把表建完了.今天来点干货,我们用ssm框架来先简单实现一下管理员的登录功能. 在实现之前,我对user表(管理员表)做了些简单的修改,先来看看: 忽略哪些蓝色的马赛克和乱输 ...
- vueJS 获取后台数据 绑定data
//vue 环境安装http://blog.csdn.net/u013182762/article/details/53021374 一开始使用安装环境配置一些东西 ,后来发现太麻烦了 . 直接CD ...
- PHP和js实时倒计时
<?php //这是t.php页面 header('content-type:text/html;charset=utf-8'); date_default_timezone_set('PRC' ...
- PMBOK 和 PRINCE2的技术不同的地方是什么
首先,PMBOK是一个框架指导,PRINCE2是一种实现方法. PMBOK是一种建议及最佳实践的集锦.PMBOK包含项目管理的工具和技术并且是一个指导,告诉我们如何做事情,在一种环境中怎样处理问题;而 ...