《Java从入门到放弃》入门篇:hibernate查询——HQL
不知不觉又到了hibernate的最后一篇了,只感觉时光飞逝~,岁月如梭~!
转眼之间,我们就···························,好吧,想装个X,结果装不下去了,还是直接开始吧·
前面我们已经把hibernate中添加、删改、修改和根据ID得到对象的方法都学习了,但如何才能查询出多条记录呢?比如我想查询所有姓黄的作者,查询标题包含“中”字的博客等。这一篇就来介绍查询。
hibernate有两种检索(查询)数据的方式,分别是HQL(Hibernate Query Language)和QBC(Query By Criteria)。官方推荐使用HQL的方式,不要问我为什么,因为············就算你很诚恳的询问我,我也不会告诉你。反正用过HQL的人都说好。
HQL提供的语法与SQL非常相似,支持动态参数绑定、投影查询、分页查询、连接查询、分组查询、内置聚集函数、子查询等,可以说是数据库中常用的查询功能,HQL都可以实现。
当然,HQL并不是只能查询,其实也可以用来执行insert、delete和update语句(使用HQL语法),只不过我们今天不讲,大家有兴趣自己练习一下就OK了。
HQL使用步骤:
)获取Session对象
)编写HQL语句
)获得Query对象
)动态绑定参数
)调用执行方法
今天玩点花样,我们通过常用的查询功能来讲解每个语法吧。
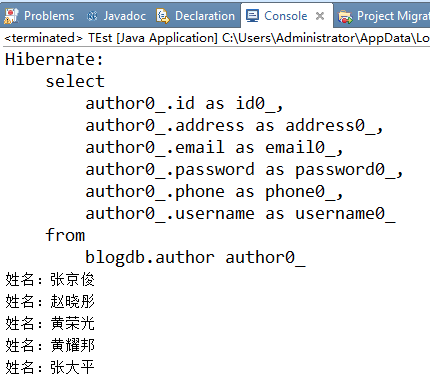
一、查询所有的作者
|
1
2
3
4
5
6
7
8
9
10
11
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有作者 String hql = "from Author"; Query query = session.createQuery(hql); List<Author> list = query.list(); for (Author author : list) { System.out.println("姓名:"+author.getUsername()); } HibernateSessionFactory.closeSession(); } |
注意:
1. 查询Author的所有属性时可以省略select部分
2. from后面的Author是Java中的实体类的类名,在HQL语句中 select或from之类的关键字不区别大小写,但类名、属性名必须和实体类大小写完全相同。
结果:
二、查询作者ID为2的所有博客
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询ID为2的作者的博客 Author author = (Author)session.get(Author.class, 2); //把作者对象当作参数进行查询 //String hql = "from Blog b where b.author=?"; //占位符方式 String hql = "from Blog b where b.author=:author"; //参数名方式 Query query = session.createQuery(hql); //添加参数 //query.setEntity(0, author); //占位符方式 query.setEntity("author", author); //参数名方式 //执行查询 List<Blog> list = query.list(); //遍历结果 for (Blog blog : list) { System.out.println("标题:"+blog.getTitle()); } HibernateSessionFactory.closeSession(); } |
注意:
这儿的条件,where后面的author是Blog实体类中的author属性,参数是什么类型就可以使用setxxx传对应的类型
参数有两种写法:一种是使用“?”,相当于占位符,另一种使用“:xxx”,相当于根据名字传值。
结果:

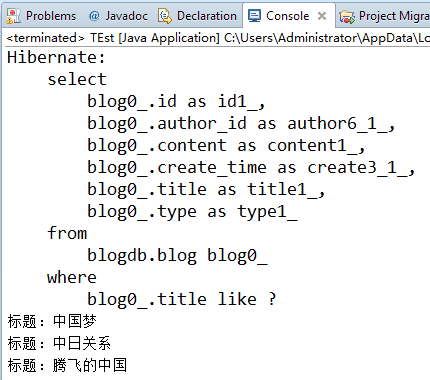
三、查询标题包含“中”字的所有博文
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询标题包含“中”字的所有博文 String hql = "from Blog b where b.title like ?"; Query query = session.createQuery(hql); //添加参数 query.setString(0, "%中%"); //参数名方式 //执行查询 List<Blog> list = query.list(); //遍历结果 for (Blog blog : list) { System.out.println("标题:"+blog.getTitle()); } HibernateSessionFactory.closeSession(); } |
注意:
like后面不能写成'%?%',这种写法是错误的。必须在外面拼接好前后的“%”,再作为参数传递给query对象。
结果:
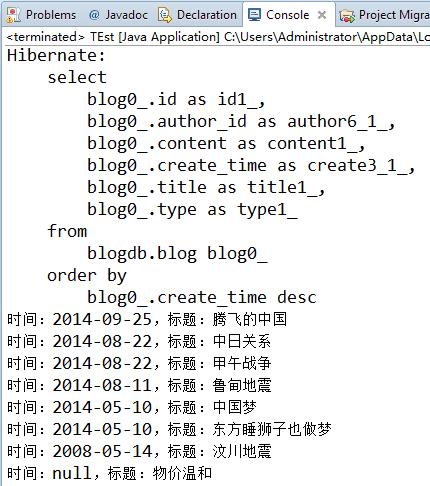
四、按博文创建日期倒序排列所有博文
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //按日期倒序排列所有博文 String hql = "from Blog b order by b.createTime desc"; Query query = session.createQuery(hql); //执行查询 List<Blog> list = query.list(); //遍历结果 for (Blog blog : list) { System.out.println("时间:"+blog.getCreateTime()+",标题:"+blog.getTitle()); } HibernateSessionFactory.closeSession(); } |
注意:
反复看了三遍,发现真的没有哪儿需要注意,我也很绝望啊!
结果:
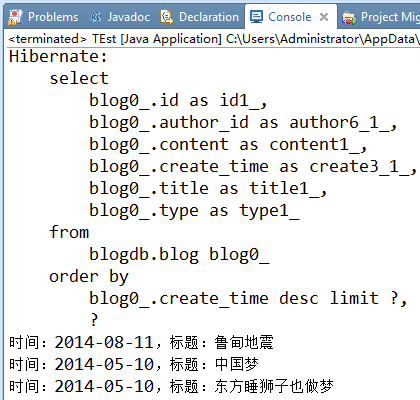
五、假如每页显示3篇博文,在上一查询的基础上,查询第2页的博文
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); int pageNO = 2; //页码 int pageCount = 3; //每页数量 //按日期倒序排列所有博文 String hql = "from Blog b order by b.createTime desc"; Query query = session.createQuery(hql); query.setFirstResult((pageNO-1)*pageCount); //起始位置 query.setMaxResults(pageCount); //记录数量 //执行查询 List<Blog> list = query.list(); //遍历结果 for (Blog blog : list) { System.out.println("时间:"+blog.getCreateTime()+",标题:"+blog.getTitle()); } HibernateSessionFactory.closeSession(); } |
注意:
setFirstResult表示查询的第一条记录的下标,setMaxResults表示查询几条记录,一般分页都是传递页码(第几页)过来。至于实际项目中的分页如何编写,等后面我们讲常用功能模块时再来说明吧。
结果:
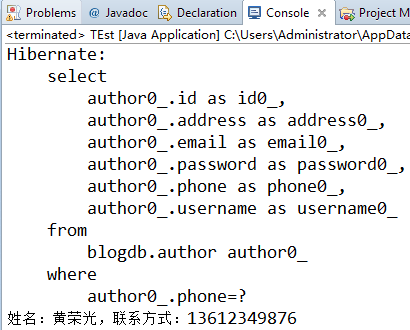
六、根据手机号查询作者(确定最多只有一条记录)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询手机号为13612349876的作者 String hql = "from Author a where a.phone=?"; Query query = session.createQuery(hql); //添加参数 query.setString(0, "13612349876"); //执行查询 Author author = (Author)query.uniqueResult(); System.out.println("姓名:"+author.getUsername()+",联系方式:"+author.getPhone()); HibernateSessionFactory.closeSession(); } |
注意:
确定查询结果最多只有一条记录时,可以使用uniqueResult()方法。
结果:
单表查询并且返回所有属性的查询语法,到这儿就告一段落。
接下来进行部分属性的查询、分组查询、多表查询和子查询。
查询语法加上select子句后,返回的结果有以下几种接收方式。
object[]数组
List集合
Map集合
自定义实体类
我们还是通过例子来学习吧:查询所有博文,只返回标题和内容。
|
1
2
3
4
5
6
7
8
9
10
11
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,返回标题和内容 String hql = "select title,content from Blog"; Query query = session.createQuery(hql); List<Blog> list = query.list(); for (Blog blog : list) { System.out.println("标题:"+blog.getTitle()); System.out.println("\t内容:"+blog.getContent()); } } |
运行会发现出现以下异常:

大概意思就是不能把Object转换成Blog类型。
接下来,我们使用上面所说的四种方式来解决这个问题,结果就不再一一展示了。
1、Object[]数组方式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,返回标题和内容 String hql = "select title,content from Blog"; Query query = session.createQuery(hql); //执行查询 List<Object[]> list = query.list(); for (Object[] objects : list) { System.out.println("标题:"+objects[0]); System.out.println("\t内容:"+objects[1]); } HibernateSessionFactory.closeSession(); } |
注意:如果只查询一个属性时,返回的就不再在数组,而是单个Object。
2、List集合方式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,返回标题和内容 String hql = "select new List(title,content) from Blog"; Query query = session.createQuery(hql); //执行查询 List<List> list = query.list(); for (List lst : list) { System.out.println("标题:"+lst.get(0)); System.out.println("\t内容:"+lst.get(1)); } HibernateSessionFactory.closeSession(); } |
注意:HQL语句中的select后面,使用new List()的方式来接受数据。
3、Map集合方式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,返回标题和内容 String hql = "select new Map(title as t,content as c) from Blog"; Query query = session.createQuery(hql); //执行查询 List<Map> list = query.list(); for (Map map : list) { System.out.println("标题:"+map.get("t")); System.out.println("\t内容:"+map.get("c")); } HibernateSessionFactory.closeSession(); } |
注意:如果new Map()中的属性没有取别名,则在for循环中通过get("下标")的形式来读取数据,特别注意,这儿是字符串"下标",而不是整数。
4、自定义实体类
4.1)在Blog实体类中添加包含标题和内容的构造方法
|
1
2
3
4
5
|
//新增构造方法 public Blog(String title, String content){ this.title = title; this.content = content; } |
4.2)测试类中的代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,返回标题和内容 String hql = "select new Blog(title,content) from Blog"; Query query = session.createQuery(hql); //执行查询 List<Blog> list = query.list(); for (Blog blog : list) { System.out.println("标题:"+blog.getTitle()); System.out.println("\t内容:"+blog.getContent()); } HibernateSessionFactory.closeSession(); } |
注意:HQL语句中查询几个属性,则在对应的实体类中必须的对应的构造方法。
四种方式到这儿就介绍完毕,至于哪种好哪种差,那就看个人习惯了。
继续后面的案例:
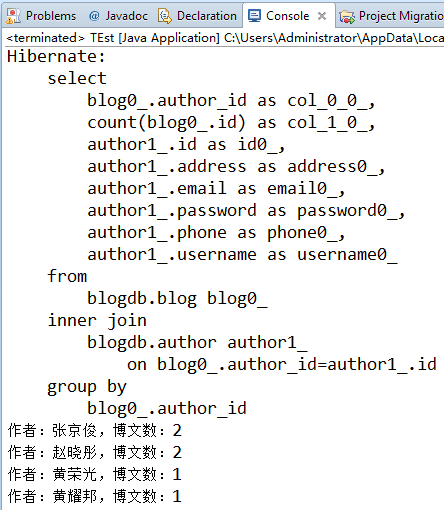
七、查询每个作者的博文数量(分组查询)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询每个作者的博文数 String hql = "select author, count(b) from Blog b group by b.author"; Query query = session.createQuery(hql); //执行查询 List<Object[]> list = query.list(); for (Object[] objects : list) { System.out.print("作者:"+((Author)objects[0]).getUsername()); System.out.println(",博文数:"+objects[1]); } HibernateSessionFactory.closeSession(); } |
注意:分组之后的统计数据没办法保存到实体类,所以只能使用前三种方式来接受数据。
结果:
八、查询所有的博文和作者(作者账号已经注销的不查(也就是博文表中作者ID为null的不查),多表联合查询)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,包括作者信息 String hql = "from Blog b inner join b.author a"; Query query = session.createQuery(hql); //执行查询 List<Object[]> list = query.list(); for (Object[] objs : list) { System.out.println("标题:"+((Blog)objs[0]).getTitle()); System.out.println("\t作者:"+((Author)objs[1]).getUsername()); } HibernateSessionFactory.closeSession(); } |
注意:inner join后面的是Blog类中的author属性,Ojbect[]数组中保存的是两个对象。左连接的功能,大家自己尝试吧。
结果:

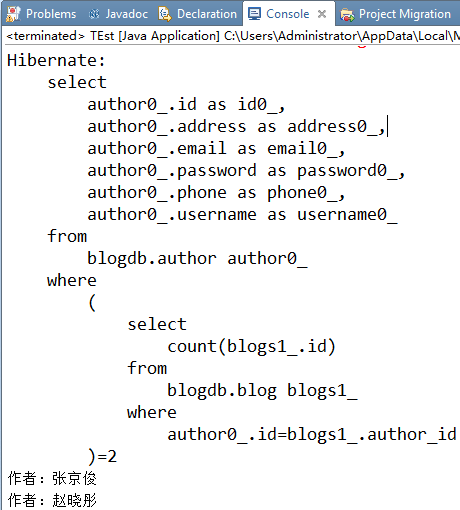
九、最后一个,查询博文数是2的所有作者(子查询)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void main(String[] args) { Session session = HibernateSessionFactory.getSession(); //查询所有博文,包括作者信息 String hql = "from Author a where (select count(b) from a.blogs b)=2"; Query query = session.createQuery(hql); //执行查询 List<Author> list = query.list(); for (Author author : list) { System.out.println("作者:"+author.getUsername()); } HibernateSessionFactory.closeSession(); } |
结果:
呼~~~~~~ ,想不到我也能写出这么长的文章。
,想不到我也能写出这么长的文章。
破了我30多年来的历史记录啊!!!激动得要了。
恳请大大给我加个推荐吧~~
“软件思维”博客地址:51CTO,博客园,感兴趣的小伙伴可以去看相关的其它博文。
《Java从入门到放弃》入门篇:hibernate查询——HQL的更多相关文章
- Java性能测试从入门到放弃-概述篇
Java性能测试从入门到放弃-概念篇 辅助工具 Jmeter: Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试.JMeter 可以用于对服务器.网络 ...
- Flink从入门到放弃(入门篇1)-Flink是什么
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇2)-本地环境搭建&构建第一个Flink应用
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇3)-DataSetAPI
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Flink从入门到放弃(入门篇4) DataStreamAPI
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Vue.js2.0从入门到放弃---入门实例
最近,vue.js越来越火.在这样的大浪潮下,我也开始进入vue的学习行列中,在网上也搜了很多教程,按着教程来做,也总会出现这样那样的问题(坑啊,由于网上那些教程都是Vue.js 1.x版本的,现在用 ...
- 转-Vue.js2.0从入门到放弃---入门实例(一)
http://blog.csdn.net/u013182762/article/details/53021374 标签: Vue.jsVue.js 2.0Vue.js入门实例Vue.js 2.0教程 ...
- NodeJs 入门到放弃 — 入门基本介绍(一)
码文不易啊,转载请带上本文链接呀,感谢感谢 https://www.cnblogs.com/echoyya/p/14450905.html 目录 码文不易啊,转载请带上本文链接呀,感谢感谢 https ...
- mysql从入门到放弃-入门知识介绍
数据库在互联网网站的重要性 简单地说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构来组织和存储的,我们可以通过数据库提供的多种方法来管理数据库里的数据.由于数据库不易扩展,所以,在一个互 ...
随机推荐
- java 邮件发送工具类
首先需要下载mail.jar文件,我个人通常是使用maven中心库的那个: <dependency> <groupId>javax.mail</groupId> & ...
- java constructor 在构造子类时,一定会调用到父类的构造方法 “ 私有属性被继承了?”问题
” Error:Implicit super constructor Pet() is undefined. Must explicitly invoke another constructor “ ...
- Spring ContentNegotiatingViewResolver
1. Spring 返回视图采用了ViewResolver,如果一般是jsp的话,可以采用InternalResourceViewResolver. 2.还可以通过ContentNegotiating ...
- 解决win10系统以太网适配器的驱动程序可能出现问题
插上网线显示未连接-连接可用,连上无线显示未连接-连接不可用,右下角显示感叹号 ,以太网和无线属性显示ipv4未连接详细信息为空,在设备管理器里卸载网卡驱动重装上仍然没有,通过windoes自带的网络 ...
- C#.NET 中visual studio生成的.pdb/ .vshost.exe/ .vshost.exe.manifest文件是什么
pdb文件: 英文全称:Program Database File 中文全称:程序数据库 文件 Debug里的PDB是full,保存着调试和项目状态信息.有断言.堆栈检查等代码.可以对程序的调试配 ...
- visual studio错误中断处理
点击将错误黏贴到剪贴板,复制到文本文件中.具体错误原因即可查出.
- webstrom一键上传github及使用
对于webstrom是我参加it修真园时就推荐使用的,其他编辑器我也没什么使用过.读大学的时候还是比较喜欢 Notepad++. 现在说一下webstrom主要的关键点吧! 一.实现一键上传githu ...
- 运行shell脚本时报错"[[ : not found"解决方法
问题描述 在运行shell脚本时报错,命令为: sh test.sh 报错如图: 脚本代码如下: #!/bin/bash # file:test.sh # author:13 # date:2017- ...
- (转) 使用jdk的xjc命令由schema文件生成相应的实体类
背景:在webservice的开发过程中涉及到这一知识点,又必要来学习一下. 1 根据编写的schema来生成对应的java实体 1.1 实战 xcj命令有schema文件生成Java实体类 1.使用 ...
- 【highchart】经典问题
摘要 记录遇到的一些问题和解决方案 时差 数据容量 多表联动 1. 时差 问题描述 highcharts 默认是标准 UTC 时间,而国内默认是东八区时间,所以会有8个小时的时差 解决方法 使用hig ...