《STL源码剖析》相关面试题总结
原文链接:http://www.cnblogs.com/raichen/p/5817158.html
一、STL简介
STL提供六大组件,彼此可以组合套用:
- 容器
容器就是各种数据结构,我就不多说,看看下面这张图回忆一下就好了,从实现角度看,STL容器是一种class template。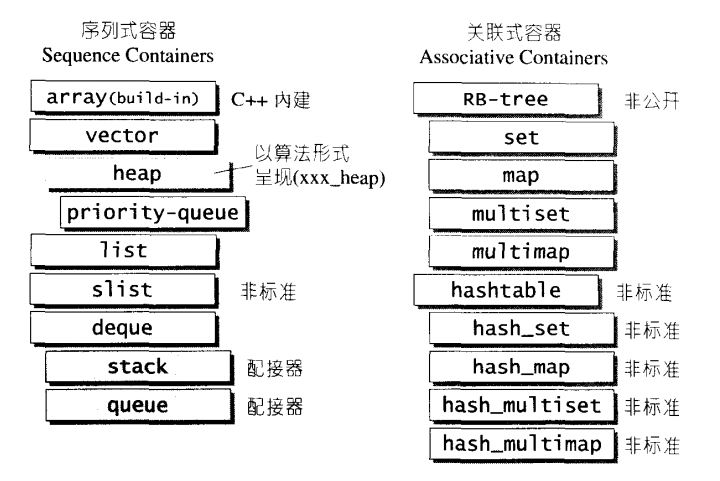
- 算法
各种常见算法,如sort,search,copy,erase等,我觉得其中比较值得学习的就是sort,next_permutation,partition,merge sort,从实现角度看,STL算法是一种function template。 - 迭代器
扮演容器与算法之间的胶合剂,是所谓的“泛型指针”。共有五种类型,从实现角度看,迭代器是一种将
operator*,operator->,operator++,operator--等指针相关操作予以重载的class
template。所有STL容器都附带有自己专属的迭代器,只有容器设计者才知道如何设计迭代器。原生指针也是一种迭代器。是设计模式的一种,所以被问
到了解的设计模式可以用来凑数。 - 仿函数
行为类函数,可作为算法的某种策略,从实现角度看,仿函数是一种重载了operator()的class或class template。一般函数指针可视为狭义的仿函数。 - 配接器
一种用来修饰容器或者仿函数或迭代器接口的东西。比如queue和stack,看着像容器,其实就是deque包了一层皮。 - 配置器
负责空间配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放额class template。
二、关于容器的一些问题
2.1 当vector的内存用完了,它是如何动态扩展内存的?它是怎么释放内存的?用clear可以释放掉内存吗?是不是线程安全的?
- vector内存用完了,会以当前size大小重新申请2*size的内存,然后把原来的元素复制过去,把新元素插上,然后释放原来的内存。
- 一般我们释放vector里的元素使用clear,其实它不能释放内存,要想释放内存要使用swap,这样:
vector<type> v;//.... 这里添加许多元素给v//.... 这里删除v中的许多元素vector<type>(v).swap(v);//此时v的容量已经尽可能的符合其当前包含的元素数量//对于string则可能像下面这样string(s).swap(s);
- 引用《effective stl》的第十二条:当涉及 STL容器和线程安全性时,你可以指望一个
STL库允许多个线程同时读一个容器,以及多个线程对不同的容器做写入操作。你不能指望
STL库会把你从手工同步控制中解脱出来,而且你不能依赖于任何线程支持。必须自己去写多线程安全措施。
2.2 map是怎么实现的?查找的复杂度是多少?能不能边遍历边插入?
红黑树和散列
O(logn)
不可以,map不像vector,它在对容器执行erase操作后不会返回后一个元素的迭代器,所以不能遍历地往后删除。
2.3 写多读少应该用什么容器?
私以为是链表,链表的插入操作时常数时间复杂度,访问操作是O(n),是最适合写多读少的容器。
2.4 vector每次insert或erase之后,以前保存的iterator会不会失效?
理论上会失效,理论上每次insert或者erase之后,所有的迭代器就重新计算的,所以都可以看作会失效,原则上是不能使用过期的内存
但是vector一般底层是用数组实现的,我们仔细考虑数组的特性,不难得出另一个结论,
insert时,假设insert位置在p,分两种情况:
a) 容器还有空余空间,不重新分配内存,那么p之前的迭代器都有效,p之后的迭代器都失效
b) 容器重新分配了内存,那么p之后的迭代器都无效咯erase时,假设erase位置在p,则p之前的迭代器都有效并且p指向下一个元素位置(如果之前p在尾巴上,则p指向无效尾end),p之后的迭代器都无效
2.5 hash_map和map的区别在哪里?
hash_map底层是散列的所以理论上操作的平均复杂度是常数时间,map底层是红黑树,理论上平均复杂度是O(logn),下面是借鉴的网上的总结:
这
里总结一下,选用map还是hash_map,关键是看关键字查询操作次数,以及你所需要保证的是查询总体时间还是单个查询的时间。如果是要很多次操作,
要求其整体效率,那么使用hash_map,平均处理时间短。如果是少数次的操作,使用
hash_map可能造成不确定的O(N),那么使用平均处理时间相对较慢、单次处理时间恒定的map,考虑整体稳定性应该要高于整体效率,因为前提在操
作次数较少。如果在一次流程中,使用hash_map的少数操作产生一个最坏情况O(N),那么hash_map的优势也因此丧尽了。
2.6 为何map和set不能像vector一样有个reserve函数来预分配数据?
map和set内部存储的已经不是元素本身了,而是包含元素的节点。也就是说map内部使用的Alloc并不是map<key, data,="" compare,="" alloc="">声明的时候从参数中传入的Alloc。例如:
map<int, int,="" less<int="">, Alloc > intmap;
这时候在intmap中使用的allocator并不是Alloc, 而是通过了转换的Alloc,具体转换的方法时在内部通过
Alloc::rebind重新定义了新的节点分配器,详细的实现参看彻底学习STL中的Allocator。
其实你就记住一点,在map和set里面的分配器已经发生了变化,reserve方法你就不要奢望了。
2.7 当数据元素增多时(10000和20000个比较),map和set的插入和搜索速度变化如何?
算一下就知道了,首先你得知道map和set的底层都是红黑树,红黑树的搜索近似于二分查找,二分查找呢,平均时间复杂度是log2n,这里简写成logn,
狂按计算器:log(10000) = 13.3log(20000) = 14.3
看到了不,理论上平均就多了一次,所以你懂的,插起来。。。
2.8 auto_ptr可以做vector的元素呢?为什么?
不能。因为STL的标准容器规定它所容纳的元素必须是可以拷贝构造和可被转移赋值的。而auto_ptr不能,可以用shared_ptr智能指针代替。
三、关于迭代器的一些问题
3.1 traits技术原理及应用
这个问题还真不知咋讲,简单来说,在STL算法中用到迭代器时(肯定会用到),会用到迭代器所指之物的型别,假设算法中有必要声明一个变量,以迭代器所指之物为型别,但是C++只支持sizeof()、并未
支持typeof()。即使typeid(),也只能获得型别名称,不能拿来声明变量,所以这里就要用到作为”特性萃取机“的traits技术,当然,要让traits有效运作,每个迭代器设计的时候的遵守约定,自行以内嵌型别定义的方式定义出相应型别。
详情请看书或者移步Traits技术:类型的if-else-then(STL核心技术之一)
四、关于算法的一些问题
4.1 快排算法的枢轴位置是怎么选择的?
三点中值法,取整个序列的头、尾、中央三个位置的元素,以其中值作为枢轴。
4.2 简单说一下next_permutation和partition的实现?
next_permutation(下一个排列)
首先,从最尾端开始往前寻找两个相邻元素,另第一个元素为i,第二个元素为ii,且满足i<ii。找到这样一组相邻元素后,再从尾端开始往前检验,找出第一个大于i的元素j,将i,j元素对调,再将ii之后的所有元素颠倒排列。此即所求“下一个”排列组合。partition
令头端迭代器first向尾部移动,尾部迭代器last向头部移动。当first所指的值大于或等于枢轴时就停下来,当
last所指的值小于或等于枢轴时也停下来,然后检验两个迭代器是否交错。如果first仍然在last左边,就将连着元素互换,然后各自调整一个位置
(向中央逼近),再继续进行相同的行为。如果发现两个迭代器叫错了,表示整个序列已经调整完毕。
五、关于内存配置的一些问题
5.1 stl对于小内存块请求与释放的处理
STL考虑到小型内存区块的碎片问题,设计了双层级配置器,第一级配置直接使用malloc()和free();第二级配置器则视情况采用不同的策
略,当配置区大于128bytes时,直接调用第一级配置器;当配置区块小于128bytes时,便不借助第一级配置器,而使用一个memory
pool来实现。究竟是使用第一级配置器还是第二级配置器,由一个宏定义来控制。SGI STL中默认使用第二级配置器。
二级配置器会将任何小额
区块的内存需求量上调至8的倍数,(例如需求是30bytes,则自动调整为32bytes),并且在它内部会维护16个free-list,
各自管理大小分别为8, 16, 24,…,128bytes的小额区块,这样当有小额内存配置需求时,直接从对应的free
list中拔出对应大小的内存(8的倍数);当客户端归还内存时,将根据归还内存块的大小,将需要归还的内存插入到对应free list的最顶端。
小结:
STL中的内存分配器实际上是基于空闲列表(free list)的分配策略,最主要的特点是通过组织16个空闲列表,对小对象的分配做了优化。
1)小对象的快速分配和释放。当一次性预先分配好一块固定大小的内存池后,对小于128字节的小块内存分配和释放的操作只是一些基本的指针操作,相比于直接调用malloc/free,开销小。
2)避免内存碎片的产生。零乱的内存碎片不仅会浪费内存空间,而且会给OS的内存管理造成压力。
3)尽可能最大化内存的利用率。当内存池尚有的空闲区域不足以分配所需的大小时,分配算法会将其链入到对应的空闲列表中,然后会尝试从空闲列表中寻找是否有合适大小的区域,
但是,这种内存分配器局限于STL容器中使用,并不适合一个通用的内存分配。因为它要求在释放一个内存块时,必须提供这个内存块的大小,以便确定回收到哪个free list中,而STL容器是知道它所需分配的对象大小的,比如上述:
stl::vector array;
array是知道它需要分配的对象大小为sizeof(int)。一个通用的内存分配器是不需要知道待释放内存的大小的,类似于free(p)。
详情请看书或移步STL源码剖析---空间配置器
《STL源码剖析》相关面试题总结的更多相关文章
- 面试题总结(三)、《STL源码剖析》相关面试题总结
声明:本文主要探讨与STL实现相关的面试题,主要参考侯捷的<STL源码剖析>,每一个知识点讨论力求简洁,便于记忆,但讨论深度有限,如要深入研究可点击参考链接,希望对正在找工作的同学有点帮助 ...
- STL"源码"剖析-重点知识总结
STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略多 :) 1.STL概述 STL提供六大组件,彼此可以组合 ...
- 【转载】STL"源码"剖析-重点知识总结
原文:STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点 ...
- (原创滴~)STL源码剖析读书总结1——GP和内存管理
读完侯捷先生的<STL源码剖析>,感觉真如他本人所说的"庖丁解牛,恢恢乎游刃有余",STL底层的实现一览无余,给人一种自己的C++水平又提升了一个level的幻觉,呵呵 ...
- 《STL源码剖析》环境配置
首先,去侯捷网站下载相关文档:http://jjhou.boolan.com/jjwbooks-tass.htm. 这本书采用的是Cygnus C++ 2.91 for windows.下载地址:ht ...
- STL"源码"剖析
STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略 ...
- STL源码剖析 — 空间配置器(allocator)
前言 以STL的实现角度而言,第一个需要介绍的就是空间配置器,因为整个STL的操作对象都存放在容器之中. 你完全可以实现一个直接向硬件存取空间的allocator. 下面介绍的是SGI STL提供的配 ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
- STL源码剖析 迭代器(iterator)概念与编程技法(三)
1 STL迭代器原理 1.1 迭代器(iterator)是一中检查容器内元素并遍历元素的数据类型,STL设计的精髓在于,把容器(Containers)和算法(Algorithms)分开,而迭代器(i ...
随机推荐
- servlet+jsp update修改页面的实现,整整搞了两个小时才搞定
package DAO; public class books { private int bid; private String bname; private int booksl; private ...
- 原生ajax封装,数据初始化,
var ajaxTool = { setting : { method : 'get', url : location.href, data : '', callback : function(){a ...
- voa 2015 / 4 / 14
Even with falling oil prices and strong U.S. growth, the head of the International Monetary Fund sai ...
- Mysql连接出错问题
1.java 提示:java.lang.ClassNotFoundException: com.mysql.jdbc.Driver 处理:导入mysql-connector-java-5.1.7-bi ...
- 腾讯云centos7服务器环境搭建,tomcat+jdk+mysql+nginx
软件:jdk 1.8.0_45 tomcat 8.5.8 mysql 5.6.36 nginx 1.10.x或以上 其中tomcat在centos6.8中没问题,centos7中会出现卡在启动那里 I ...
- Eclipse中配置约束(DTD,XSD)
在Eclipse中本地配置schema约束(xsd): 1.比如配置spring的applicationContext.xml中的约束条件: 复制applicationContext.xml中如图: ...
- docker~学习笔记索引
回到占占推荐博客索引 使用docker也有段时间了,写了不少文章与总结,下面把它整理个目录出来,方便大家去学习与检索! docker~学习笔记索引 docker~linux下的部署和基本命令(2017 ...
- Android 应用退到后台
Android 应用退到后台 2016-4-21 10:29:26 Android L moveTaskToBack(boolean nonRoot) 把包含这个Activity的任务转到后台.并不是 ...
- .Net Core 系列:2、ADO.Net 基础
目录: 1.环境搭建 2.ADO.Net 基础 3.ASP.Net Core 基础 4.MD5.Sha256.AES 加密 5.实现登录注册功能 6.实现目录管理功能 7.实现文章发布.编辑.阅览和删 ...
- 发票OCR识别/票据OCR自动识别
对于一些大的集团公司来说,分散式财务管理模式管理效率不高,管理成本相对较高,同时也制约了集团企业发展战略的实施,因而需要建设财务共享中心.一个企业想建造财务共享中心,面临的难题是大量的数据采集和信息处 ...