Grid search in the tidyverse
@drsimonj here to share a tidyverse method of grid search for optimizing a model’s hyperparameters.
Grid Search
For anyone who’s unfamiliar with the term, grid search involves running a model many times with combinations of various hyperparameters. The point is to identify which hyperparameters are likely to work best. A more technical definition from Wikipedia, grid search is:
an exhaustive searching through a manually specified subset of the hyperparameter space of a learning algorithm
What this post isn’t about
To keep the focus on grid search, this post does NOT cover…
- k-fold cross-validation. Although a practically essential addition to grid search, I’ll save the combination of these techniques for a future post. If you can’t wait, check out my last post for some inspiration.
- Complex learning models. We’ll stick to a simple decision tree.
- Getting a great model fit. I’ve deliberately chosen input variables and hyperparameters that highlight the approach.
Decision tree example
Say we want to run a simple decision tree to predict cars’ transmission type (am) based on their miles per gallon (mpg) and horsepower (hp) using themtcars data set. Let’s prep the data:
library(tidyverse)
d <- mtcars %>%
# Convert `am` to factor and select relevant variables
mutate(am = factor(am, labels = c("Automatic", "Manual"))) %>%
select(am, mpg, hp)
ggplot(d, aes(mpg, hp, color = am)) +
geom_point()
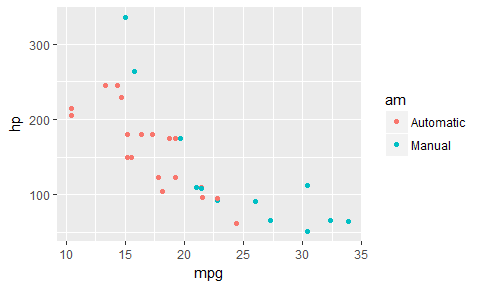
For a decision tree, it looks like a step-wise function until mpg > 25, at which point it’s all Manual cars. Let’s grow a full decision tree on this data:
library(rpart)
library(rpart.plot)
# Set minsplit = 2 to fit every data point
full_fit <- rpart(am ~ mpg + hp, data = d, minsplit = 2)
prp(full_fit)
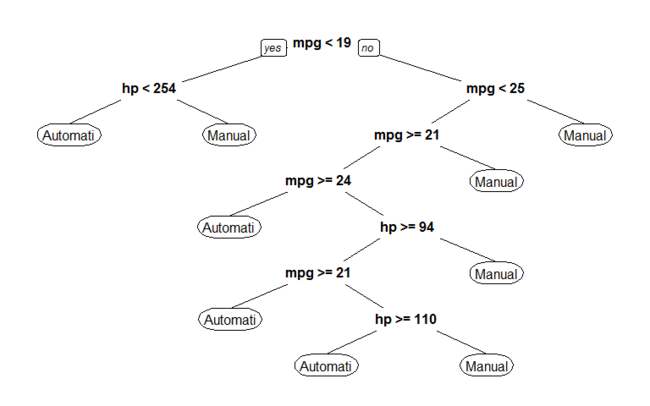
We don’t want a model like this, as it almost certainly has overfitting problems. So the question becomes, which hyperparameter specifications would work best for our model to generalize?
Training-Test Split
To help validate our hyperparameter combinations, we’ll split our data into training and test sets (in an 80/20 split):
set.seed(245)
n <- nrow(d)
train_rows <- sample(seq(n), size = .8 * n)
train <- d[ train_rows, ]
test <- d[-train_rows, ]
Create the Grid
Step one for grid search is to define our hyperparameter combinations. Say we want to test a few values for minsplit and maxdepth. I like to setup the grid of their combinations in a tidy data frame with a list and cross_d as follows:
# Define a named list of parameter values
gs <- list(minsplit = c(2, 5, 10),
maxdepth = c(1, 3, 8)) %>%
cross_d() # Convert to data frame grid
gs
#> # A tibble: 9 × 2
#> minsplit maxdepth
#> <dbl> <dbl>
#> 1 2 1
#> 2 5 1
#> 3 10 1
#> 4 2 3
#> 5 5 3
#> 6 10 3
#> 7 2 8
#> 8 5 8
#> 9 10 8
Note that the list names are the names of the hyperparameters that we want to adjust in our model function.
Create a model function
We’ll be iterating down the gs data frame to use the hyperparameter values in a rpart model. The easiest way to handle this is to define a function that accepts a row of our data frame values and passes them correctly to our model. Here’s what I’ll use:
mod <- function(...) {
rpart(am ~ hp + mpg, data = train, control = rpart.control(...))
}
Notice the argument ... is being passed to control in rpart, which is where these hyperparameters can be used.
Fit the models
Now, to fit our models, use pmap to iterate down the values. The following is iterating through each row of our gs data frame, plugging the hyperparameter values for that row into our model.
gs <- gs %>% mutate(fit = pmap(gs, mod))
gs
#> # A tibble: 9 × 3
#> minsplit maxdepth fit
#> <dbl> <dbl> <list>
#> 1 2 1 <S3: rpart>
#> 2 5 1 <S3: rpart>
#> 3 10 1 <S3: rpart>
#> 4 2 3 <S3: rpart>
#> 5 5 3 <S3: rpart>
#> 6 10 3 <S3: rpart>
#> 7 2 8 <S3: rpart>
#> 8 5 8 <S3: rpart>
#> 9 10 8 <S3: rpart>
Obtain accuracy
Next, let’s assess the performance of each fit on our test data. To handle this efficiently, let’s write another small function:
compute_accuracy <- function(fit, test_features, test_labels) {
predicted <- predict(fit, test_features, type = "class")
mean(predicted == test_labels)
}
Now apply this to each fit:
test_features <- test %>% select(-am)
test_labels <- test$am
gs <- gs %>%
mutate(test_accuracy = map_dbl(fit, compute_accuracy,
test_features, test_labels))
gs
#> # A tibble: 9 × 4
#> minsplit maxdepth fit test_accuracy
#> <dbl> <dbl> <list> <dbl>
#> 1 2 1 <S3: rpart> 0.7142857
#> 2 5 1 <S3: rpart> 0.7142857
#> 3 10 1 <S3: rpart> 0.7142857
#> 4 2 3 <S3: rpart> 0.8571429
#> 5 5 3 <S3: rpart> 0.8571429
#> 6 10 3 <S3: rpart> 0.7142857
#> 7 2 8 <S3: rpart> 0.8571429
#> 8 5 8 <S3: rpart> 0.8571429
#> 9 10 8 <S3: rpart> 0.7142857
Arrange results
To find the best model, we arrange the data based on desc(test_accuracy). The best fitting model will then be in the first row. You might see above that we have many models with the same fit. This is unusual, and likley due to the example I’ve chosen. Still, to handle this, I’ll break ties in accuracy withdesc(minsplit) and maxdepth to find the model that is most accurate and also simplest.
gs <- gs %>% arrange(desc(test_accuracy), desc(minsplit), maxdepth)
gs
#> # A tibble: 9 × 4
#> minsplit maxdepth fit test_accuracy
#> <dbl> <dbl> <list> <dbl>
#> 1 5 3 <S3: rpart> 0.8571429
#> 2 5 8 <S3: rpart> 0.8571429
#> 3 2 3 <S3: rpart> 0.8571429
#> 4 2 8 <S3: rpart> 0.8571429
#> 5 10 1 <S3: rpart> 0.7142857
#> 6 10 3 <S3: rpart> 0.7142857
#> 7 10 8 <S3: rpart> 0.7142857
#> 8 5 1 <S3: rpart> 0.7142857
#> 9 2 1 <S3: rpart> 0.7142857
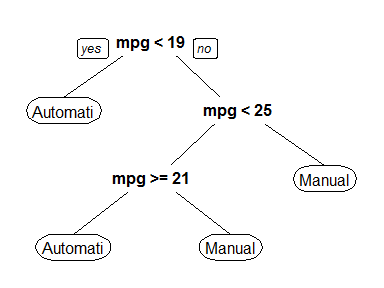
It looks like a minsplit of 5 and maxdepth of 3 is the way to go!
To compare to our fully fit tree, here’s a plot of this top-performing model. Remember, it’s in the first row so we can reference [[1]].
prp(gs$fit[[1]])
Food for thought
Having the results in a tidy data frame lets us do a lot more than just pick the optimal hyperparameters. It lets us quickly wrangle with and visualize the results of the various combinations. Here are some ideas:
- Search among the top performers for the simplest model.
- Plot performance across the hyperparameter combinations.
- Save time by restricting the hypotheses before model fitting. For example, in a large data set, it’s practically pointless to try a small
minsplitand smallmaxdepth. In this case, before fitting the models, we canfilterthegsdata frame to exclude certain combinations.
Sign off
Thanks for reading and I hope this was useful for you.
For updates of recent blog posts, follow @drsimonj on Twitter, or email me atdrsimonjackson@gmail.com to get in touch.
If you’d like the code that produced this blog, check out the blogR GitHub repository.
转自:https://drsimonj.svbtle.com/grid-search-in-the-tidyverse
Grid search in the tidyverse的更多相关文章
- Comparing randomized search and grid search for hyperparameter estimation
Comparing randomized search and grid search for hyperparameter estimation Compare randomized search ...
- 3.2. Grid Search: Searching for estimator parameters
3.2. Grid Search: Searching for estimator parameters Parameters that are not directly learnt within ...
- How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras
Hyperparameter optimization is a big part of deep learning. The reason is that neural networks are n ...
- Grid Search学习
转自:https://www.cnblogs.com/ysugyl/p/8711205.html Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性 ...
- grid search 超参数寻优
http://scikit-learn.org/stable/modules/grid_search.html 1. 超参数寻优方法 gridsearchCV 和 RandomizedSearchC ...
- scikit-learn:3.2. Grid Search: Searching for estimator parameters
參考:http://scikit-learn.org/stable/modules/grid_search.html GridSearchCV通过(蛮力)搜索參数空间(參数的全部可能组合).寻找最好的 ...
- [转载]Grid Search
[转载]Grid Search 初学机器学习,之前的模型都是手动调参的,效果一般.同学和我说他用了一个叫grid search的方法.可以实现自动调参,顿时感觉非常高级.吃饭的时候想调参的话最差不过也 ...
- grid search
sklearn.metrics.make_scorer(score_func, greater_is_better=True, needs_proba=False, needs_threshold=F ...
- Hackerrank - The Grid Search
https://www.hackerrank.com/challenges/the-grid-search/forum 今天碰见这题,看见难度是Moderate,觉得应该能半小时内搞定. 读完题目发现 ...
随机推荐
- Android开发学习-view
题记:抱着对Android开发的浓厚兴趣,加入了Study jams的线上学习小组,开启了自己的Android学习之旅.一.学习前准备:1.自己动手搭建了"Android Studio&qu ...
- 极化SAR图像基础知识(1)
从今天开始学习极化SAR图像,记录于此. 极化散射矩阵S是用来表示单个像素散射特性的一种简便办法,它包含了目标的全部极化信息.
- PHP站内搜索
1.SQL语句中的模糊查找 LIKE条件一般用在指定搜索某字段的时候, 通过"% 或_" 通配符的作用实现模糊查找功能,通配符可以在前面也可以在后面或前后都有. 搜索以PHP100 ...
- MySQL最常用分组聚合函数
一.聚合函数(aggregation function)---也就是组函数 在一个行的集合(一组行)上进行操作,对每个组给一个结果. 常用的组函数: AVG([distinct] expr) 求平均值 ...
- websoket使用Protocol Buffers3.0传输
Protocol Buffers是Google推出的一个数据交换格式,相对于xml它的体积更小,更快,因为它是二进制传输的.3.0相对于2.0变动比较大.这些变动可以去看官方说明. 在前端使用Prot ...
- hdu1512 Monkey King
Problem Description Once in a forest, there lived N aggressive monkeys. At the beginning, they each ...
- JQuery 根据ID在页面中定位
1.锚点跳转简介 锚点其实就是可以让页面定位到某个位置上的点.在高度较高的页面中经常见到.比如百度的百科页面,wiki中的page内容. 我知道实现锚点的跳转有两种形式,一种是a标签+name属性:还 ...
- webUI自动化测试框架---”pyswat“介绍
webUI自动化测试框架---"pyswat"介绍 大家好我是lamecho 辣么丑,今天给大家介绍一款web自动化测试框架pyswat. "pyswat"是 ...
- 不同浏览器的margin值与padding值
IE-7: 有默认外边距margin样式的元素: dd,menu, ol, ul, blockquote, body, dd, dl, form, h1-6, ul 有默认内边距padding样式的元 ...
- 产品经理学Python:逻辑判断与运算符
这是关于Python的第6篇文章,主要介绍下逻辑判断与运算符. (一) 逻辑判断: 如果要实现一个复杂的功能程序,逻辑判断必不可少.逻辑判断的最基本标准:布尔类型. 布尔类型只有两个值:True和Fa ...