Single linked list by cursor
有了指针实现看似已经足够了,那为什么还要有另外的实现方式呢?原因是诸如BASIC和FORTRAN等许多语言都不支持指针,如果需要链表而又不能使用指针,那么就必须使用另外的实现方法。还有一个原因,是在ACM-ICPC,OI等竞赛中,比赛时间有限,用指针写起来太费事,而且数量不多的情况下,用数组实现的脸变运行速度会更快。还有一些人觉得用指针写起来不优雅。嗯,不管怎么说,多掌握一种写法还是有必要的,说不定面试就会被问到2333
下面我会先把游标实现的细节阐述清楚,然后给出一个例题,来辅助理解。
其实游标在操作起来和普通链表并无太大不同,实际上两者的实现代码(特别是链表中函数的实现)差别不大,游标实现的链表效率会高一些,因为他是通过数组存储数据的,所以读写速度都是O(1)的,非常快。但是它并不能像普通链表一样实现动态增长缩减,一旦定义了数组大小,则能存储的数据的个数便不可更改了,所以更适合事先知道最大数据个数的案例
根据之前的知识,在链表的指针实现种有两个重要的特点
- 数据存储在一组结构体中。每一个结构体包含有数据以及指向下一个结构体的指针。
- 一个新的结构体可以通过调用malloc而从系统全局内存(global memory)得到,并可以通过调用free而被释放。
那游标法就必须能够模拟这两条特性,因为这是指针的基础性质。满足条件1的逻辑方法是要有一个全局的结构体数组,这个数组用来干嘛的?应该很容易想到——一方面存数据,这是单元内容。另一方面,那么下标呢?对于这个数组的任何单元,它的下标用来代表一个地址。
先给出一些声明
typedef int PtrToNode; //因为现在不需要把数据和指针绑定,所以不再是结构体,而是数组下标
typedef PtrToNode List;
typedef PtrToNode Position;
#define SpaceSize 100
struct Node{
int Element;
Position Next;
};
struct Node CursorSpace[SpaceSize];
这里的声明和之前的指针实现保持结构上的一致,这样就会形成一种对称的美感~
现在我们必须模拟条件2,让CursorSpace数组中的单元代行malloc和free的职能。为此,我们将保留一个数组(也就是free list),用slot命名,还挺形象2333,这个表由不在任何表中的单元构成。而且用0号单元作为表头,下面给出它的初始配置
|
Slot |
Element |
Next |
|
0 |
1 |
|
|
1 |
2 |
|
|
2 |
3 |
|
|
3 |
4 |
|
|
4 |
5 |
|
|
5 |
6 |
|
|
6 |
7 |
|
|
7 |
8 |
|
|
8 |
9 |
|
|
9 |
10 |
|
|
10 |
0 |
这是一个初始化的CursorSpace,对于Next,0值等价于一个NULL指针。上面的状态用链表形式表示为:
CursorSpace[0]—>CursorSpace[1]—>CursorSpace[2]—>CursorSpace[3]—>CursorSpace[4]—>CursorSpace[5]—>CursorSpace[6]—>CursorSpace[7]—>CursorSpace[8]—>CursorSpace[9]—>CursorSpace[10]—>NULL.
 而这个Slot的值,其实就是CursorSpace这个结构体数组的下标!!理解这点,下面的分配和返还函数的细节就容易理解了。
而这个Slot的值,其实就是CursorSpace这个结构体数组的下标!!理解这点,下面的分配和返还函数的细节就容易理解了。
我们做什么操作都离不开第一步——初始化,这很简单,一个循环就够了。
与此同时,为了执行malloc的功能,需要把表头后面的第一个元素从freelist中删除,为什么要这样做——因为这个slot数组模拟的是系统内存,你申请一块,他就少一块。为了执行 free的功能,我们把要删除的单元放在freelist的前面,下面给出内存分配和返还的游标实现。如果没有可用空间,我们就让P=0,它表明没有空间可用,并且也可以使分配函数的第二行称为空操作。
先说初始化一个游标空间
void Initial(){
int i;
for (i=; i<SpaceSize-; i++) //遍历每一个单元
CursorSpace[i].Next=i+; //依次对next升序编号
CursorSpace[].Element=; //初始元素置空
CursorSpace[SpaceSize-].Next=;//把最后一个单元的next设为0,就类似指针链表的尾指针是NULL
}
下面这两个是重中之重,各位要看仔细了,这两个基础操作理解透彻了,后面的都是小菜一碟。
static Position CursorAlloc(){
Position P;
P=CursorSpace[].Next; //先从next的第0个单元获取一个数,这个数是第P个单元的地址
CursorSpace[].Next=CursorSpace[P].Next; //cursor 0后面本来接的是cursor P,但现在第P个单元被申请走了,所以顺接到P后面的位置。
return P;
}
这里的CursorSpace[0]仅代表一般意义上的“第一个元素”,未必是真正的下标0.这几句代码不太好理解,我一开始学的时候费了不少劲去弄懂,后来总结出一个状态转换的示意图,能很清晰地解释这个函数的运行过程:
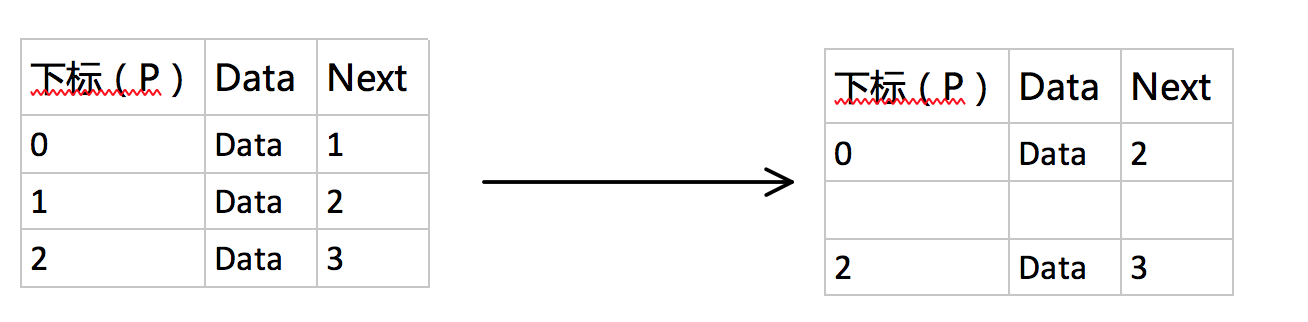
因为malloc的时候要将第一个元素(表头之后的第一个)从freelist中删除。
释放内存:
void CursorFree(Position P){
CursorSpace[P].Next=CursorSpace[].Next;//cursor P后面接上原本是cursor 0所指的下一个
CursorSpace[].Next=P; //cursor 0后面接上被删除的P,相当于返还给操作系统。
}
这两句代码的顺序不能反过来,不然的话,cursor 0里面存的Next值就会改变,顺序就乱了。不过——我们思考这个free过程的时候最好从下往上看,因为要返还P这个单元,所以从逻辑上,表头的下一位记录P,然后P记录“原本是表头的下一位”那个单元的序号——也就是下标。记住!是从逻辑上,不是从代码细节上。实际写的时候要考虑边边角角,调整Next值的顺序一定要小心,就像用指针删除链表时的顺序问题(回想一下)。
这个的运行过程如下:

因为free后要把该单元放在freelist的前端,放回去。
有没有发现,这两个函数的操作是完全对称的!多么和谐的美感啊,无论顺序和具体的步骤,他们都是对称的,所以这个细节也会有利于我们去理解内存的分配和返还机制。这或许对我们理解后续课程有帮助。
有了这些,链表的游标实现就简单了。为了前后一致我们将用一个头节点实现我们的链表。为了方便从整体架构上理解游标链表,给出一个例子:
|
Slot |
Element |
Next |
|
0 |
- |
6 |
|
1 |
B |
9 |
|
2 |
F |
0 |
|
3 |
Header |
7 |
|
4 |
- |
0 |
|
5 |
Header |
10 |
|
6 |
- |
4 |
|
7 |
C |
8 |
|
8 |
D |
2 |
|
9 |
E |
0 |
|
10 |
A |
1 |
假设L=5,M=3,那么L表示链表a->b->e->NULL,M表示链表c->d->f->NULL。为了写出用游标实现链表的这些函数,必须传递和返回与指针实现时相同的参数。
这节因为有了之前的基础,注释就不写那么冗长了。
判断是否为空表,也就是一个元素都没有的表。
int Isempty(List L) {
return CursorSpace[L].Next==;
}
判断是否为末尾
int IsLast(Position P) {
return CursorSpace[P].Next==;
}
虽然细节和判空相同,但是用作接口由于实际功能有细微差别,还是要区分开写的。
查找是这样的
Position Find(int X,List L) {
Position P;
P=CursorSpace[L].Next;
while(P && CursorSpace[L].Element!=X) //当后续的表还存在,并且还未找到给定的X时
P=CursorSpace[P].Next; //向后迭代,并逐个比对元素
return P; //返回X在L中的位置,当没有找到时,返回0
}
我们再说删除:
和之前一样,删除要先找到前一个元素
Position FindPrevious(int X,List L){
Position P;
P=L;
while (P && CursorSpace[CursorSpace[P].Next].Element!=X) { //P没有走到末尾,同时还没找到给定的X时
P=CursorSpace[P].Next; //P向后走
}//走到这一步时,说明要么没找到,P=NULL(结尾处),要么找到了,P=前驱的位置
return P;
}
接下来就要删除了,有了前面的基础,就容易理解了。
void Delete(int X , List L){
Position P,TempCell;
P=FindPrevious(X, L);
if (!IsLast(P)) {
TempCell=CursorSpace[P].Next;
CursorSpace[P].Next=CursorSpace[TempCell].Next;//相当于P->Next=P->Next->Next
CursorFree(TempCell);
}
}
再说插入,顺次向后添加一个单元比较自然,就先说向后插入的实现:
Position Insert(int X,Position P){//P是插入前的末尾节点
Position TempCell;
TempCell=CursorAlloc(); //申请一块新内存
if(!TempCell)
printf("Out of space!");
CursorSpace[TempCell].value=X;
CursorSpace[TempCell].Next=;
CursorSpace[P].Next=TempCell;
return TempCell;
}
哦对了,应该有不少人对之前的“freelist”感到疑惑吧hhhhh 它从字面上看表示了一种有趣的数据结构,从freelist删除的单元是刚刚由free放在那里的单元。因此,最后被放在freelist的单元是最先被拿走的单元。有一种数据结构也具有这种性质,叫做栈(stack),它是下一节要讨论的内容。
下面给出一个有趣的题目,emmmm有兴趣的or有能力的可以继续往下看——没人希望自己很弱吧,所以都接着往下看吧哈哈哈
破损的键盘(又名:悲剧文本),Uva OJ 11988
你有一个破损的键盘,键盘上的所有键都可以正常工作,但有时Home或者End键会自动按下。你并不知道键盘存在这一问题,于是专心地打稿子,甚至连显示器都没打开。当你打开显示器后,展现在你面前的是一段悲剧的文本。你的任务是打开显示器之前,计算出这段悲剧文本。
输入包含多组数据,每组数据占一行,包含不超过100000个字母、下划线、字符“[”或者“]”。其中字符“[”表示Home键,“]”表示End键。输入结束标志为文件结束符(EOF)输入文件不超过5MB,对于每组数据,输出一行,即屏幕上的悲剧文本。
Sample:
Input
This_is_a_[Beiju]_text [[]][]Happy_Birthday_to_Tsinghua_University
Output
BeijuThis_is_a__text Happy_Birthday_to_Tsinghua_University
最简单的想法是用一个数组保存这段文本,然后用一个变量pos保存光标的位置。这样的话,输入一个字符相当于在数组中插入一个字符……那这就很尴尬了,每插入一个字符,需要把当前位置的所有元素向右移动,还要考虑是否存在溢出的问题。很不方便而且时间开销巨大,这样的代码妥妥TLE。
解决方案是用链表,每输入一个字符就把它存起来。假设输入的字符串是s[1~n],则可以用next[i]表示在当前显示器中s[i]右边的字符编号——也就是对应的下标。方便起见,假设字符串s的最前面有一个虚拟的s[0],则next[0]就表示显示器中最左边的第一个有效字符。再用一个变量cur表示光标位置:当前光标位于s[cur]的右边。cur=0说明光标在虚拟字符的右边,也就是显示器的最左边、刚开始要输入的那个位置。
为了移动光标,还需要用一个变量last表示显示器的最后一个字符是s[last]。现在思路大概理顺了,实现如下:
#include <stdio.h>
#include <string.h>
const int maxn = +;
int last,cur,next[maxn],i;
char s[maxn];
int main(){
while (scanf("%s",s+)==) { //每次输入一个字符,存储地址向后偏移一位
int n=strlen(s+); //n为当前字符串长度
last=cur=;
next[]=;
for (i=; i<n+; i++) { //遍历每一个字符
char ch=s[i];
if(ch=='[') cur=; //遇到Home键就把光标移到最左边
else if(ch==']') cur=last;//遇到End键就把光标移到最后的位置
else{ //如果是文本
next[i]=next[cur];
next[cur]=i;
if(cur==last)last=i; //更新最后一个字符的编号
cur=i; //移动光标
}
}
for (i=next[];i!= ;i=next[i]) //对于建立好的链表,通过next数组遍历整个处理后的字符串
printf("%c",s[i]);
printf("\n");
}
return ;
}
有哪里感到疑惑的就直接写在评论里吧,我会积极参与讨论的2333
下一篇写栈。
Single linked list by cursor的更多相关文章
- Linux C single linked for any data type
/************************************************************************** * Linux C single linked ...
- Single linked List by pointer
其实本应该从一般性的表讲起的,先说顺序表,再说链表 .但顺序表的应用范围不是很广,而且说白了就是数组的高级版本,他的优势仅在于两点:1.逻辑直观,易于理解.2.查找某个元素只需要常数时间--O(1), ...
- 《数据结构》2.3单链表(single linked list)
//单链表节点的定义 typedef struct node { datatype data; struct node *next; }LNode,*LinkList; //LNode是节点类型,Li ...
- 单链表(Single Linked List)
链表的结点结构 ┌───┬───┐ │data|next│ └───┴───┘ data域--存放结点值的数据域 next域--存放结点的直接后继的地址(位置)的指针域(链域) 实例:从终端输入 ...
- CCI_chapter 2 Linked Lists
2.1 Write code to remove duplicates from an unsorted linked list /* Link list node */ struct node { ...
- Cracking the Coding Interview(linked list)
第二章的内容主要是关于链表的一些问题. 基础代码: class LinkNode { public: int linknum; LinkNode *next; int isvisit; protect ...
- [TS] Implement a doubly linked list in TypeScript
In a doubly linked list each node in the list stores the contents of the node and a pointer or refer ...
- linux I/O复用
转载自:哈维.dpkirin url:http://blog.csdn.NET/zhang_shuai_2011/article/details/7675797 http://blog.csdn.Ne ...
- LeetCode Note 1st,practice makes perfect
1. Two Sum Given an array of integers, return indices of the two numbers such that they add up to a ...
随机推荐
- SQL三类语句
1. DDL (Data Definition Language, 数据定义语言) CREATE: 创建数据库和表等对象 DROP: 删除数据库和表等对象 ALTER: 修改数据库和表等对象的结构 2 ...
- Sql Server——运用代码创建数据库及约束
在没有学习运用代码创建数据库.表和约束之前,我们只能用鼠标点击操作,这样看起来就不那么直观(高大上)了. 在写代码前要知道在哪里写和怎么运行: 点击新建查询,然后中间的白色空白地方就是写代码的地方了. ...
- 如何实现跨 Docker 主机存储?- 每天5分钟玩转 Docker 容器技术(73)
从业务数据的角度看,容器可以分为两类:无状态(stateless)容器和有状态(stateful)容器. 无状态是指容器在运行过程中不需要保存数据,每次访问的结果不依赖上一次访问,比如提供静态页面的 ...
- Delphi中paramstr的用法
原型 function paramstr(i:index):string 对于任何application paramstr(0)都默认代表的是应用程序的 ...
- 开源纯C#工控网关+组态软件
一. 前言 在园子潜水也七八年了.说来惭愧,这么多年虽然一直自称.NET铁杆粉丝,然仅限于回几个不痛不痒的贴,既没有发布过代码,也没有写过文章. 看着.NET和C#在国外风生水起,国内却日趋没落, ...
- matplotlib学习之绘图基础
matplotlib:http://www.cnblogs.com/jasonhaven/p/7609059.html 1.基本图形 散点图:显示两组数据的值,每个点的坐标位置由变量的值决定,头一组不 ...
- 关于form表单或者Ajax向后台发送数据时,数据格式的探究
最近在做一个资产管理系统项目,其中有一个部分是客户端向服务端发送采集到的数据的,服务端是Django写的,客户端需要用rrequests模块模拟发送请求 假设发送的数据是这样的: data = {'s ...
- JavaWeb(三)JSP概述
一.JSP概述 1.1.JSP简介 一种动态网页开发技术.它使用JSP标签在HTML网页中插入Java代码.标签通常以<%开头以%>结束.JSP是一种Java servlet,主要用于实现 ...
- php基础运算符语句
/* 多行注释 *///常用数据类型//int string double/float bool//变量的定义$a = 123;$b = "123";$c = '456';//$d ...
- Node.js之循环依赖
在Node.js中有可能会出现循环依赖的问题,在此做一个简单的记录 假如有一个模块A: exports.loaded = false; const b = require('./b'); module ...