CS:APP3e 深入理解计算机系统_3e MallocLab实验
**详细的题目要求和资源可以到 http://csapp.cs.cmu.edu/3e/labs.html 或者 http://www.cs.cmu.edu/~./213/schedule.html 获取。**
在这个实验中我们需要实现自己的动态内存申请器(malloc、free、realloc)
前期准备:
- 完全阅读书本第9章
man 3 realloc
注意事项:
1.先从小的测试文件开始,例如short1-bal.rep
2.为了调试方便,在Makefile中将CFLAGS更改为:
CFLAGS = -Wall -O2 -m32 -ggdb
这样用GDB调试的时候就能看到源码了
3.地址要对8字节对齐。
4.注意realloc的实现要和libc一致。
5.本实验环境WORD=4=sizeof(void *),DWORD=8(gcc -m32)
思路要点及其实现:
对于速度(thru)而言,我们需要关注malloc、free、realloc每次操作的复杂度。对于内存利用率(util)而言,我们需要关注internal fragmentation (块内损失)和 external fragmentation (块是分散不连续的,无法整体利用),即我们free和malloc的时候要注意整体大块利用(例如合并free块、realloc的时候判断下一个块是否空闲)。
我这里实现的是书上9.9.13和9.9.14提到的Explicit Free Lists + Segregated Free Lists + Segregated Fits ,详细的介绍参考书上写的。
块的结构如下,其中低三位由于内存对齐的原因总会是0,A代表最低位为1,即该块已经allocated:

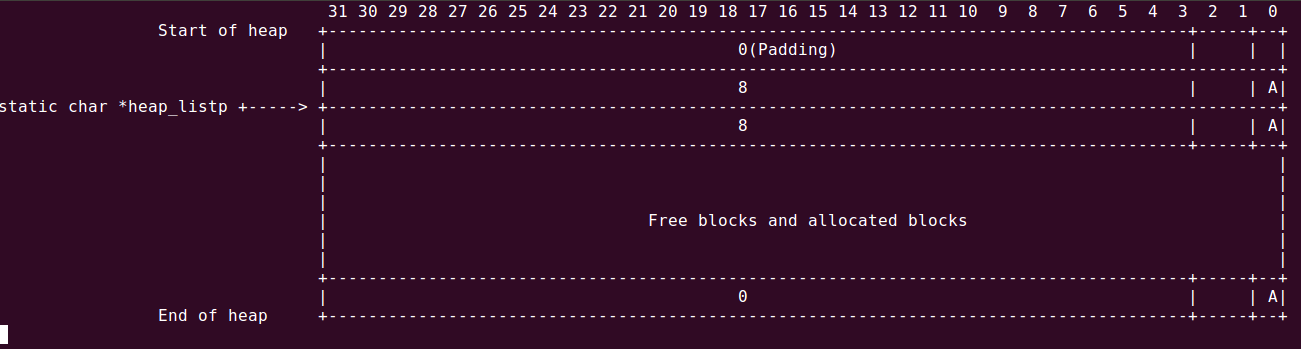
堆的起始和结束结构如下:
Free list的结构如下,每条链上的块按大小由小到大排列,这样我们用“first hit”策略搜索链表的时候就能获得“best hit”的性能,例如第一条链,A是B的successor,B是A的predecessor,A的大小小于等于B;不同链以块大小区分,依次为{1}{2}{34}{58}...{1025~2048}... :
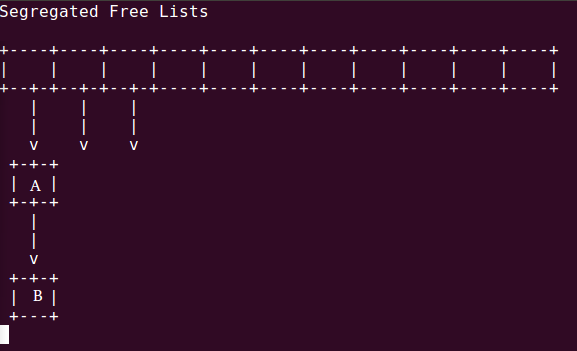
更新:这里的箭头应该是双向的,画错了。
下面是各个模块的实现,**部分代码改编自CS:APP3e官网的Code examples 的mm.c(完整代码),如需使用请联系Randy Bryant and Dave O'Hallaron ** 。这次注释用中文写的,就不另外解释了。
常数及指针运算的宏定义
/* 向上进行对齐 */
#define ALIGNMENT 8
#define ALIGN(size) ((((size) + (ALIGNMENT-1)) / (ALIGNMENT)) * (ALIGNMENT))
#define WSIZE 4
#define DSIZE 8
/* 每次扩展堆的块大小(系统调用“费时费力”,一次扩展一大块,然后逐渐利用这一大块) */
#define INITCHUNKSIZE (1<<6)
#define CHUNKSIZE (1<<12)
#define LISTMAX 16
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define MIN(x, y) ((x) < (y) ? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc))
/* 下面对指针所在的内存赋值时要注意类型转换,否则会有警告 */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
#define SET_PTR(p, ptr) (*(unsigned int *)(p) = (unsigned int)(ptr))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(ptr) ((char *)(ptr) - WSIZE)
#define FTRP(ptr) ((char *)(ptr) + GET_SIZE(HDRP(ptr)) - DSIZE)
#define NEXT_BLKP(ptr) ((char *)(ptr) + GET_SIZE((char *)(ptr) - WSIZE))
#define PREV_BLKP(ptr) ((char *)(ptr) - GET_SIZE((char *)(ptr) - DSIZE))
#define PRED_PTR(ptr) ((char *)(ptr))
#define SUCC_PTR(ptr) ((char *)(ptr) + WSIZE)
#define PRED(ptr) (*(char **)(ptr))
#define SUCC(ptr) (*(char **)(SUCC_PTR(ptr)))
全局变量
/* 分离空闲表 */
void *segregated_free_lists[LISTMAX];
/* 实验信息 */
team_t team = {"1603002","Qiuhao Li","liqiuhao727@outlook.com","",""};
Helper functions
/* 扩展推 */
static void *extend_heap(size_t size);
/* 合并相邻的Free block */
static void *coalesce(void *ptr);
/* 在prt所指向的free block块中allocate size大小的块,如果剩下的空间大于2*DWSIZE,则将其分离后放入Free list */
static void *place(void *ptr, size_t size);
/* 将ptr所指向的free block插入到分离空闲表中 */
static void insert_node(void *ptr, size_t size);
/* 将ptr所指向的块从分离空闲表中删除 */
static void delete_node(void *ptr);
Helper functions: extend_heap
static void *extend_heap(size_t size)
{
void *ptr;
/* 内存对齐 */
size = ALIGN(size);
/* 系统调用“sbrk”扩展堆 */
if ((ptr = mem_sbrk(size)) == (void *)-1)
return NULL;
/* 设置刚刚扩展的free块的头和尾 */
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
/* 注意这个块是堆的结尾,所以还要设置一下结尾 */
PUT(HDRP(NEXT_BLKP(ptr)), PACK(0, 1));
/* 设置好后将其插入到分离空闲表中 */
insert_node(ptr, size);
/* 另外这个free块的前面也可能是一个free块,可能需要合并 */
return coalesce(ptr);
}
Helper functions: insert_node
static void insert_node(void *ptr, size_t size)
{
int listnumber = 0;
void *search_ptr = NULL;
void *insert_ptr = NULL;
/* 通过块的大小找到对应的链 */
while ((listnumber < LISTMAX - 1) && (size > 1))
{
size >>= 1;
listnumber++;
}
/* 找到对应的链后,在该链中继续寻找对应的插入位置,以此保持链中块由小到大的特性 */
search_ptr = segregated_free_lists[listnumber];
while ((search_ptr != NULL) && (size > GET_SIZE(HDRP(search_ptr))))
{
insert_ptr = search_ptr;
search_ptr = PRED(search_ptr);
}
/* 循环后有四种情况 */
if (search_ptr != NULL)
{
/* 1. ->xx->insert->xx 在中间插入*/
if (insert_ptr != NULL)
{
SET_PTR(PRED_PTR(ptr), search_ptr);
SET_PTR(SUCC_PTR(search_ptr), ptr);
SET_PTR(SUCC_PTR(ptr), insert_ptr);
SET_PTR(PRED_PTR(insert_ptr), ptr);
}
/* 2. [listnumber]->insert->xx 在开头插入,而且后面有之前的free块*/
else
{
SET_PTR(PRED_PTR(ptr), search_ptr);
SET_PTR(SUCC_PTR(search_ptr), ptr);
SET_PTR(SUCC_PTR(ptr), NULL);
segregated_free_lists[listnumber] = ptr;
}
}
else
{
if (insert_ptr != NULL)
{ /* 3. ->xxxx->insert 在结尾插入*/
SET_PTR(PRED_PTR(ptr), NULL);
SET_PTR(SUCC_PTR(ptr), insert_ptr);
SET_PTR(PRED_PTR(insert_ptr), ptr);
}
else
{ /* 4. [listnumber]->insert 该链为空,这是第一次插入 */
SET_PTR(PRED_PTR(ptr), NULL);
SET_PTR(SUCC_PTR(ptr), NULL);
segregated_free_lists[listnumber] = ptr;
}
}
}
Helper functions: delete_node
static void delete_node(void *ptr)
{
int listnumber = 0;
size_t size = GET_SIZE(HDRP(ptr));
/* 通过块的大小找到对应的链 */
while ((listnumber < LISTMAX - 1) && (size > 1))
{
size >>= 1;
listnumber++;
}
/* 根据这个块的情况分四种可能性 */
if (PRED(ptr) != NULL)
{
/* 1. xxx-> ptr -> xxx */
if (SUCC(ptr) != NULL)
{
SET_PTR(SUCC_PTR(PRED(ptr)), SUCC(ptr));
SET_PTR(PRED_PTR(SUCC(ptr)), PRED(ptr));
}
/* 2. [listnumber] -> ptr -> xxx */
else
{
SET_PTR(SUCC_PTR(PRED(ptr)), NULL);
segregated_free_lists[listnumber] = PRED(ptr);
}
}
else
{
/* 3. [listnumber] -> xxx -> ptr */
if (SUCC(ptr) != NULL)
{
SET_PTR(PRED_PTR(SUCC(ptr)), NULL);
}
/* 4. [listnumber] -> ptr */
else
{
segregated_free_lists[listnumber] = NULL;
}
}
}
Helper functions: coalesce
static void *coalesce(void *ptr)
{
_Bool is_prev_alloc = GET_ALLOC(HDRP(PREV_BLKP(ptr)));
_Bool is_next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(ptr)));
size_t size = GET_SIZE(HDRP(ptr));
/* 根据ptr所指向块前后相邻块的情况,可以分为四种可能性 */
/* 另外注意到由于我们的合并和申请策略,不可能出现两个相邻的free块 */
/* 1.前后均为allocated块,不做合并,直接返回 */
if (is_prev_alloc && is_next_alloc)
{
return ptr;
}
/* 2.前面的块是allocated,但是后面的块是free的,这时将两个free块合并 */
else if (is_prev_alloc && !is_next_alloc)
{
delete_node(ptr);
delete_node(NEXT_BLKP(ptr));
size += GET_SIZE(HDRP(NEXT_BLKP(ptr)));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
}
/* 3.后面的块是allocated,但是前面的块是free的,这时将两个free块合并 */
else if (!is_prev_alloc && is_next_alloc)
{
delete_node(ptr);
delete_node(PREV_BLKP(ptr));
size += GET_SIZE(HDRP(PREV_BLKP(ptr)));
PUT(FTRP(ptr), PACK(size, 0));
PUT(HDRP(PREV_BLKP(ptr)), PACK(size, 0));
ptr = PREV_BLKP(ptr);
}
/* 4.前后两个块都是free块,这时将三个块同时合并 */
else
{
delete_node(ptr);
delete_node(PREV_BLKP(ptr));
delete_node(NEXT_BLKP(ptr));
size += GET_SIZE(HDRP(PREV_BLKP(ptr))) + GET_SIZE(HDRP(NEXT_BLKP(ptr)));
PUT(HDRP(PREV_BLKP(ptr)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(ptr)), PACK(size, 0));
ptr = PREV_BLKP(ptr);
}
/* 将合并好的free块加入到空闲链接表中 */
insert_node(ptr, size);
return ptr;
}
Helper functions: place
static void *place(void *ptr, size_t size)
{
size_t ptr_size = GET_SIZE(HDRP(ptr));
/* allocate size大小的空间后剩余的大小 */
size_t remainder = ptr_size - size;
delete_node(ptr);
/* 如果剩余的大小小于最小块,则不分离原块 */
if (remainder < DSIZE * 2)
{
PUT(HDRP(ptr), PACK(ptr_size, 1));
PUT(FTRP(ptr), PACK(ptr_size, 1));
}
/* 否则分离原块,但这里要注意这样一种情况(在binary-bal.rep和binary2-bal.rep有体现):
* 如果每次allocate的块大小按照小、大、小、大的连续顺序来的话,我们的free块将会被“拆”成以下这种结构:
* 其中s代表小的块,B代表大的块
s B s B s B s B
+--+----------+--+----------+-+-----------+-+---------+
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
+--+----------+--+----------+-+-----------+-+---------+
* 这样看起来没什么问题,但是如果程序后来free的时候不是按照”小、大、小、大“的顺序来释放的话就会出现“external fragmentation”
* 例如当程序将大的块全部释放了,但小的块依旧是allocated:
s s s s
+--+----------+--+----------+-+-----------+-+---------+
| | | | | | | | |
| | Free | | Free | | Free | | Free |
| | | | | | | | |
+--+----------+--+----------+-+-----------+-+---------+
* 这样即使我们有很多free的大块可以使用,但是由于他们不是连续的,我们不能将它们合并,如果下一次来了一个大小为B+1的allocate请求
* 我们就还需要重新去找一块Free块
* 与此相反,如果我们根据allocate块的大小将小的块放在连续的地方,将达到开放在连续的地方:
s s s s s s B B B
+--+--+--+--+--+--+----------+------------+-----------+
| | | | | | | | | |
| | | | | | | | | |
| | | | | | | | | |
+--+--+--+--+--+--+----------+------------+-----------+
* 这样即使程序连续释放s或者B,我们也能够合并free块,不会产生external fragmentation
* 这里“大小”相对判断是根据binary-bal.rep和binary2-bal.rep这两个文件设置的,我这里在96附近能够达到最优值
*
*/
else if (size >= 96)
{
PUT(HDRP(ptr), PACK(remainder, 0));
PUT(FTRP(ptr), PACK(remainder, 0));
PUT(HDRP(NEXT_BLKP(ptr)), PACK(size, 1));
PUT(FTRP(NEXT_BLKP(ptr)), PACK(size, 1));
insert_node(ptr, remainder);
return NEXT_BLKP(ptr);
}
else
{
PUT(HDRP(ptr), PACK(size, 1));
PUT(FTRP(ptr), PACK(size, 1));
PUT(HDRP(NEXT_BLKP(ptr)), PACK(remainder, 0));
PUT(FTRP(NEXT_BLKP(ptr)), PACK(remainder, 0));
insert_node(NEXT_BLKP(ptr), remainder);
}
return ptr;
}
初始化堆 mm_init:
int mm_init(void)
{
int listnumber;
char *heap;
/* 初始化分离空闲链表 */
for (listnumber = 0; listnumber < LISTMAX; listnumber++)
{
segregated_free_lists[listnumber] = NULL;
}
/* 初始化堆 */
if ((long)(heap = mem_sbrk(4 * WSIZE)) == -1)
return -1;
/* 这里的结构参见本文上面的“堆的起始和结束结构” */
PUT(heap, 0);
PUT(heap + (1 * WSIZE), PACK(DSIZE, 1));
PUT(heap + (2 * WSIZE), PACK(DSIZE, 1));
PUT(heap + (3 * WSIZE), PACK(0, 1));
/* 扩展堆 */
if (extend_heap(INITCHUNKSIZE) == NULL)
return -1;
return 0;
}
申请块:mm_malloc:
void *mm_malloc(size_t size)
{
if (size == 0)
return NULL;
/* 内存对齐 */
if (size <= DSIZE)
{
size = 2 * DSIZE;
}
else
{
size = ALIGN(size + DSIZE);
}
int listnumber = 0;
size_t searchsize = size;
void *ptr = NULL;
while (listnumber < LISTMAX)
{
/* 寻找对应链 */
if (((searchsize <= 1) && (segregated_free_lists[listnumber] != NULL)))
{
ptr = segregated_free_lists[listnumber];
/* 在该链寻找大小合适的free块 */
while ((ptr != NULL) && ((size > GET_SIZE(HDRP(ptr)))))
{
ptr = PRED(ptr);
}
/* 找到对应的free块 */
if (ptr != NULL)
break;
}
searchsize >>= 1;
listnumber++;
}
/* 没有找到合适的free块,扩展堆 */
if (ptr == NULL)
{
if ((ptr = extend_heap(MAX(size, CHUNKSIZE))) == NULL)
return NULL;
}
/* 在free块中allocate size大小的块 */
ptr = place(ptr, size);
return ptr;
}
释放块:mm_free:
void mm_free(void *ptr)
{
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
/* 插入分离空闲链表 */
insert_node(ptr, size);
/* 注意合并 */
coalesce(ptr);
}
调整块:mm_realloc:
void *mm_realloc(void *ptr, size_t size)
{
void *new_block = ptr;
int remainder;
if (size == 0)
return NULL;
/* 内存对齐 */
if (size <= DSIZE)
{
size = 2 * DSIZE;
}
else
{
size = ALIGN(size + DSIZE);
}
/* 如果size小于原来块的大小,直接返回原来的块 */
if ((remainder = GET_SIZE(HDRP(ptr)) - size) >= 0)
{
return ptr;
}
/* 否则先检查地址连续下一个块是否为free块或者该块是堆的结束块,因为我们要尽可能利用相邻的free块,以此减小“external fragmentation” */
else if (!GET_ALLOC(HDRP(NEXT_BLKP(ptr))) || !GET_SIZE(HDRP(NEXT_BLKP(ptr))))
{
/* 即使加上后面连续地址上的free块空间也不够,需要扩展块 */
if ((remainder = GET_SIZE(HDRP(ptr)) + GET_SIZE(HDRP(NEXT_BLKP(ptr))) - size) < 0)
{
if (extend_heap(MAX(-remainder, CHUNKSIZE)) == NULL)
return NULL;
remainder += MAX(-remainder, CHUNKSIZE);
}
/* 删除刚刚利用的free块并设置新块的头尾 */
delete_node(NEXT_BLKP(ptr));
PUT(HDRP(ptr), PACK(size + remainder, 1));
PUT(FTRP(ptr), PACK(size + remainder, 1));
}
/* 没有可以利用的连续free块,而且size大于原来的块,这时只能申请新的不连续的free块、复制原块内容、释放原块 */
else
{
new_block = mm_malloc(size);
memcpy(new_block, ptr, GET_SIZE(HDRP(ptr)));
mm_free(ptr);
}
return new_block;
}
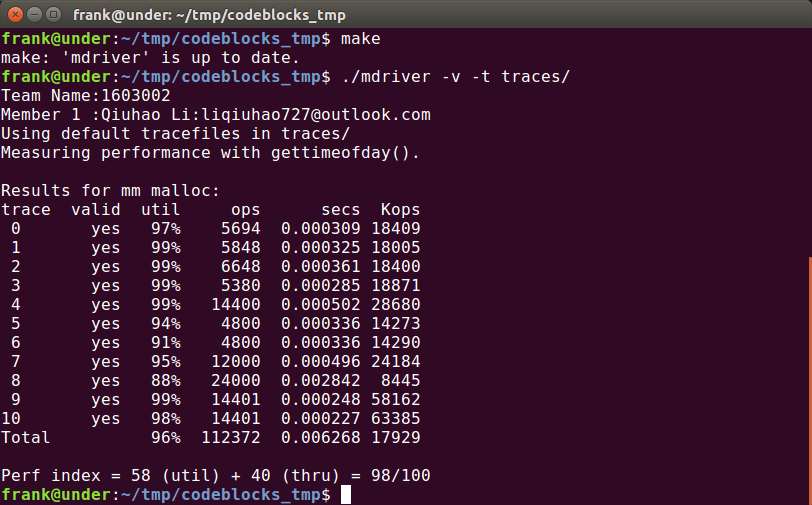
最终结果:
CS:APP3e 深入理解计算机系统_3e MallocLab实验的更多相关文章
- CS:APP3e 深入理解计算机系统_3e bomblab实验
bomb.c /*************************************************************************** * Dr. Evil's Ins ...
- CS:APP3e 深入理解计算机系统_3e Attacklab 实验
详细的题目要求和资源可以到 http://csapp.cs.cmu.edu/3e/labs.html 或者 http://www.cs.cmu.edu/~./213/schedule.html 获取. ...
- CS:APP3e 深入理解计算机系统_3e Datalab实验
由于http://csapp.cs.cmu.edu/并未完全开放实验,很多附加实验做不了,一些环境也没办法搭建,更没有标准答案.做了这个实验的朋友可以和我对对答案:) 实验内容和要求可在http:// ...
- CS:APP3e 深入理解计算机系统_3e CacheLab实验
详细的题目要求和资源可以到 http://csapp.cs.cmu.edu/3e/labs.html 或者 http://www.cs.cmu.edu/~./213/schedule.html 获取. ...
- CS:APP3e 深入理解计算机系统_3e ShellLab(tsh)实验
详细的题目要求和资源可以到 http://csapp.cs.cmu.edu/3e/labs.html 或者 http://www.cs.cmu.edu/~./213/schedule.html 获取. ...
- CS:APP3e 深入理解计算机系统_3e C Programming Lab实验
queue.h: /* * Code for basic C skills diagnostic. * Developed for courses 15-213/18-213/15-513 by R. ...
- CS:APP3e 深入理解计算机系统_3e Y86-64模拟器指南
详细的题目要求和资源可以到 http://csapp.cs.cmu.edu/3e/labs.html 或者 http://www.cs.cmu.edu/~./213/schedule.html 获取. ...
- 深入理解计算机系统_3e 第九章家庭作业 CS:APP3e chapter 9 homework
9.11 A. 00001001 111100 B. +----------------------------+ | Parameter Value | +--------------------- ...
- 深入理解计算机系统_3e 第八章家庭作业 CS:APP3e chapter 8 homework
8.9 关于并行的定义我之前写过一篇文章,参考: 并发与并行的区别 The differences between Concurrency and Parallel +---------------- ...
随机推荐
- 运行期以索引获取tuple元素-C++11之2
//运行期以索引获取tuple元素-C++11之2 //需支持C++11及以上标准的编译器,VS2017 15.5.x.CodeBlocks 16.01 gcc 7.2 //参见<深入应用C++ ...
- 《Qt on Android核心编程》介绍
<Qt on Android核心编程>最终尘埃落定.付梓印刷了. 2014-11-02更新:china-pub的预售链接出来了.折扣非常低哦. 封面 看看封面的效果吧,历经几版,最终就成了 ...
- minicom在虚拟机(linux)安装配置过程
1. minicom须要ncurses库的支持.否则安装会有问题. A. 下载ncurses.我选择是ncurses-5.6.tar.gz 下载地址:http://directory.fsf.org/ ...
- Python 安装 BeautifulSoup(Win7)
准备材料: 1.Win7,已安装的 Python3.4.1 2.BeautifulSoup4.3.2安装包 安装办法: 1.打开cmd 2,进入BeautifulSoup的解压文件夹 3,执行 pyt ...
- JAVA入门--目录
在此记录自己的JAVA入门笔记,备忘 JAVA入门[1]--安装JDK JAVA入门[2]-安装Maven JAVA入门[3]—Spring依赖注入 JAVA入门[4]-IntelliJ IDEA配置 ...
- 自学Python5.3-内置模块(1)
内置模块(1)内置模块是Python自带的功能,在使用内置模块相应的功能时,需要 先导入 再 使用 1.OS模块 用于提供系统级别的操作: os.getcwd() 获取当前工作目录,即 ...
- Git使用简单总结
创建版本库git add加入到暂存区git commit -m" "加入到分支 时光机穿梭git satus查看仓库的当前状态git diff file 查看修改内容 版本回退HE ...
- 《TCP-IP详解卷3:TCP 事务协议、HTTP、NNTP和UNIX域协议》【PDF】下载
TCP-IP详解卷3:TCP 事务协议.HTTP.NNTP和UNIX域协议>[PDF]下载链接: https://u253469.pipipan.com/fs/253469-230062539 ...
- C# 委托详解(一)
1.委托简单例子 class eeProgram { // 声明delegate对象 public delegate string CompareDelegate(int a, int b); // ...
- 【java】网络socket编程简单示例
package 网络编程; import java.io.IOException; import java.io.PrintStream; import java.net.ServerSocket; ...