静态频繁子图挖掘算法用于动态网络——gSpan算法研究
摘要
随着信息技术的不断发展,人类可以很容易地收集和储存大量的数据,然而,如何在海量的数据中提取对用户有用的信息逐渐地成为巨大挑战。为了应对这种挑战,数据挖掘技术应运而生,成为了最近一段时期数据科学的和人工智能领域内的研究热点。数据集中的频繁模式作为一种有价值的信息,受到了人们的广泛关注,成为了数据挖掘技术研究领域内的热门话题和研究重点。
传统的频繁模式挖掘技术被用来在事务数据集中发现频繁项集,然而随着数据挖掘技术应用到非传统领域,单纯的事务数据结构很难对新的领域的数据进行有效的建模。因此,频繁模式挖掘技术需要被扩展到了更为复杂的数据结构上。
图不但可以对数据实体进行建模,还可以对数据实体之间的复杂关系进行建模,因此图可以作为一个通用的数据模型,故而与图有关的模式挖掘的研究就显得相当重要。在图数据集中挖掘频繁子图模式是一种困难的问题,虽然至今已经提出了很多的算法,但在将算法应用在具体应用问题上的时候,仍然存在很多待解决的问题。
gSpan算法是用于静态频繁子图挖掘的经典算法。然而除了静态图,目前使用图模型进行建模的具体应用很多都呈现出动态特性。因此本文试图将用于静态频繁子图挖掘的gSpan算法应用于动态网络。
本文首先介绍频繁子图挖掘问题的基本概念和相关算法,国内外的研究现状,并阐述频繁子图挖掘算法研究的应用背景和现实意义。然后详细介绍gSpan算法的基本思想和实现方法,并在静态图集数据和动态网络数据上对实现的程序进行测试,并分析算法的局限性和改进的方向。
关键词: 数据挖掘 图挖掘 频繁子图挖掘 频繁模式挖掘 gSpan
ABSTRACT
With the continuous development of information technology, it is easy to collect and store a large amount of data. However, how to extract useful information from the massive data becomes a big challenge. In order to deal with this challenge, data mining technology emerges, and has become a hotspot in the field of data science and artificial intelligence. As a kind of valuable information, the frequent patterns in data sets have been paid more and more attention and become a hot topic in the field of data mining.
Traditional frequent pattern mining techniques were used in the transaction data set to find frequent item sets, but with the application of data mining technology to the nontraditional areas, it is difficult to model new domain data by using transaction data structure. So frequent pattern mining techniques need to be extended to more complex data structures.
Graph not only can be used to model the data entities, also can be used to model the complex relationship between data entities, so the Graph can be used as a common data model, therefore the research on Graph mining is very important. Mining frequent subgraph patterns in graph set is a difficult problem. Although many algorithms have been proposed so far, when the algorithm is applied in the specific application problems, there are still many problems to be solved.
GSpan algorithm is a classical algorithm for static frequent subgraph mining. However, in addition to static graphs, many of the specific applications that are currently modeled with the graph are presented with dynamic characteristics. Therefore, this paper attempts to apply the gSpan algorithm for static frequent subgraph mining to dynamic networks.
This paper first introduces the basic concepts and related algorithms of frequent subgraph mining, the research status at home and abroad. Then I will introduce the basic idea and implementation method of gSpan algorithm in detail, and carries on the test on the static graph set data and the dynamic network data to the program, and analyzes the limitation of the algorithm and the direction of improvement.
Keywords: data mining graph mining frequent subgraph mining frequent pattern mining gSpan
目录
目录
绪论
研究背景
大数据和云计算技术的发展使得存储并分析大量的数据成为可能。然而从大量的数据中发现有用的模式是一个很大的挑战。通常,由于目标数据量太大,我们根本无法使用传统的数据分析工具和技术处理。有时候,即使数据量相对较小,但是由于数据本身具有非传统的特点,使得我们也不能利用传统的方法和技术处理这些数据。
数据挖掘技术是一种用于处理大规模数据的思维方法和技术手段,它是在信息时代数据爆炸的背景下产生的。因为数据的拥有者很难从海量的数据中获取有用的信息和知识,这促使人们产生了对数据分析技术的强烈需求。
数据挖掘技术现在已经被广泛用于零售,保险,电信,银行等领域的数据分析。由于数据挖掘技术在各种信息产业中的广泛应用而且具有很大的实用价值,数据挖掘技术逐渐的成为了数据科学领域的研究重点。
频繁模式挖掘是数据挖掘研究中的一个重要问题。频繁模式挖掘技术最初被用于"购物篮分析"。在由购物篮数据构成的事务数据集中发现频繁项集,进而发现高置信度的关联规则,进而为超市的销售策略提供建议。频繁模式挖掘技术
在数据挖掘技术中扮演了很重要的角色,不但能作为关联规则分析的基础,还能将对象的频繁模式作为对象的特征,进而在分类和聚类等其它数据挖掘任务中发挥基础作用。最初,频繁模式挖掘只适用于有限的数据表示,比如购物篮数据。然而真实的应用需求需要处理不同的数据类型。随着研究的深入,频繁模式挖掘所涉及的数据模型,也从最初的集合,到序列,树,栅栏和图。图数据广泛存在于我们的生活中,如化合物分子结构数据,蛋白质相互作用网络数据,万维网数据,社交网路数据,因此基于图的频繁模式挖掘算法的研究很有必要。图作为一种通用的数据结构可以对数据实体以及实体之间的复杂关系进行建模,因此频繁子图模式的挖掘在频繁模式挖掘中有着重要的地位,受到了更多的关注。
后来,随着研究的深入,研究者试图将频繁子图模式的概念拓展到动态网络。因为很多复杂的系统都是随着时间不断演化的,静态网络建模的建模方法在某种程度上具有很大的局限性。因为随着时间的变化,人与人之间的关系也会发生变化;生物系统也在不断地发生变化,从更长远的时间角度来看,生物物种在进化过程中,其分子网络结构在不断地发生着。从一个人的生命的范围来看,一个人从孕育、成长、衰老到死亡,其身体内部的分子网络在不断地发生变化。所以复杂网络的变化几乎是无时无刻不再发生的。对复杂网络的某一时刻的快照进行分析,必然会失去与其动态特性有关的有用模式。随着图挖掘技术的不断发展,研究者试图将静态频繁子图挖掘算法应用于动态网络进而分析动态网络中的频繁模式[2]。
本论文以此背景为出发点,主要研究与静态频繁子图挖掘有关的算法并试图将其应用于动态网络。
国内外研究现状分析
在很多的复杂系统中,实体和实体之间具有复杂的联系,这种复杂的关系很难使用一般的数据结构加以表达。图数据结构作为表述复杂关系的一种通用数据结构,成为了数据挖掘研究的热点和难点。在社交网络分析中,人与人之间的关系可以抽象为一个图,其中每个人可以作为图中的顶点,人与人之间的关系可以被抽象为图中的边。因此,对社会群体的分析,就转化为了对社交网络拓扑结构和顶点属性的分析。在生物科学领域,生物学家发现蛋白质基因结构配位实验是费时费力的工作,他们希望使用数据挖掘技术,以提高结构匹配实验的效率。蛋白质的复杂结构可以被描述为图,其中氨基酸是图的顶点,而接触残基则是顶点之间的边。通过对蛋白质结构图集的挖掘可以预先发现蛋白质结构之间的内在关系或者共享模式。在一组图上面挖掘频繁子图具有很重要的意义。频繁子图传递了很多有意义的结构化信息,比如热点网络访问模式,公共蛋白质结构,对象识别中的共享模式,电子支付中的欺诈检测等。正是由于这些应用的迫切要求,图挖掘成为数据挖掘领域研究的一个热点。
频繁子图挖掘算法的核心是图的同构测试。在过去四十年里,许多著名的图的同构测试算法被发现。例如J. R. Ullmann的回溯法和B. D. McKay的贪心算法,以及大量的近似算法。然而,频繁子图挖掘问题并没有很好的被解决。在化学信息学领域,一些高效的算法被设计出来,用以在一组化合物中发现频繁的公共子结构。L. Dehaspe et al. 使用化合物的公共子结构来预测化合物的毒性。然而这些系统都难以应用大规模较大的数据集上,可拓展性并不是很好。L. B. Holder et al. 提出了SUBDUC算法用来挖掘近似的子结构模式,所以其不能挖掘全部的频繁模式。2000年左右,Inokuchi et al. 提出了一种基于Apriori的算法AGM用来发现频繁子图模式。后来Kuramochi 和Karypis进一步发展了Apriori的思想,使用一种更高效的图的表示结构和边的增长策略。这个算法叫做FSG,获得了巨大的性能提高。
AGM和FSG都利用了Apriori的模式增长思想。这些方法虽然减少了搜索空间,但仍然存在一些致命的问题,使得算法的执行要浪费很多的时间。比如:
- 大量的候选生成
- 多次扫描数据库
- 比较耗费时间的同构测试
- 难以发现比较大的频繁子图模式
为了避免这些问题,2002年,X. Yan等人提出了一种高效的利用深度优先策略搜索子图空间的方法,并在此基础上给出了基于图的子结构模式挖掘算法gSpan[4]。GSpan算法不同于AGM和FSG算法,它没有采用Apriori的思想,而是利用边模式增长的方式深度优先挖掘频繁子图。随后在2003年,他们在gSpan算法的基础上进一步提出了挖掘频繁闭合子图的算法CloseGraph,频繁闭合子图是频繁子图的压缩表示。它可以有效地去除冗余的频繁子图,减少结果集的大小,并能保证不丢失任何信息。
当然,还有很多相关的研究成果,这里不再赘述。综上所述,图模式挖掘算法多种多样,应用广泛。虽然,图模式挖掘具有很高的复杂性,但是该领域的研究已经展现出广阔的发展空间和蓬勃的生机。
论文主要内容和组织结构
论文主要内容
图数据结构对实体集合及其之间的关系具有强大的建模能力,因而图数据结构被广泛用于对现实生活中各种各样复杂的系统进行建模。作为大数据一部分的图结构数据,是大数据中最难以分析的一部分,因此如何从图结构数据中提取有用的模式和知识,进而帮助我们预测网络的变化和发展至关重要。
本文围绕静态频繁子图挖掘算法中的gSpan算法进行研究,独自实现gSpan
算法并将其应用于动态网络数据,发现动态网络演化过程中稳定存在的模式。
论文组织结构
本文各章节的内容组织如下:
第一章:论述研究背景,介绍国内外的研究现状,阐明了本文的主要研究内容和组织结构。
第二章:简要介绍静态频繁子图挖掘的数学基础和有关概念。重要阐述了频繁子图挖掘的基本定义和基础知识,图论的基础知识,频繁子图挖掘中遇到的问题,一些基础的频繁子图挖掘技术和思想。最后介绍了几个著名的频繁子图挖掘算法及其主要技术。
第三章:详细介绍与gSpan有关的基本概念,包括DFS编码,DFS字典序,DFS编码树等。详细介绍gSpan算法的伪代码。
第四章:详细介绍gSpan算法实现的总体设计和详细设计。重点介绍gSpan算法实现的数据结构。介绍算法分别在静态图集数据和动态网络数据上的测试结果,详细地分析测试结果。
第五章:总结和展望。总结在本论文中所做的研究工作,分析本论文所做工作的不足之处,指出可以改进的方向。
图挖掘相关基础
图论基础
图是一种用来对数据实体以及数据实体之间的复杂关系进行建模的数据结构,可以作为一种通用的数据模型对数据进行建模。也就是说,任何的数据模型,包括序列,集合,树等数据结构都可以一般化为图数据结构。图由顶点和边构成,一般我们只考虑顶点和边的连接关系,而不考虑其具体的位置。其中顶点代表任意的实体,边代表实体之间的关系。为了增强图模型的表达能力,我们还可以为图的顶点和边赋予任意的标号或者标号组,用于表示顶点和边所具有的属性或者属性集合。下面,给出图的一些形式化的定义。
定义2.1
图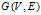 包含顶点集
包含顶点集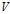 和边集
和边集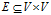 。因此图的本质是顶点集上的二元关系。若二元组
。因此图的本质是顶点集上的二元关系。若二元组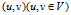 是有序的,即
是有序的,即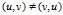 ,则图
,则图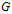 是有向图(directed graph)。若二元组
是有向图(directed graph)。若二元组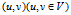 是无序的,即
是无序的,即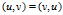 ,则图
,则图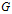 是无向图(undirected graph)。一般在有向图中,用
是无向图(undirected graph)。一般在有向图中,用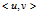 来表示顶点
来表示顶点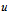 到顶点
到顶点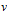 之间有一条边。在本文中,若不特别指出,图一般指的是无向图[2]。
之间有一条边。在本文中,若不特别指出,图一般指的是无向图[2]。定义 2.2 子图
图G'=(V', E')是另一个图G=(V, E)的子图,如果它的顶点集V'是V的子集,并且它的边集E'是E的子集。子图关系记作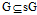 [2]。
[2]。定义2.3
两个图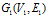 和
和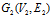 是同构的,当且仅当顶点集
是同构的,当且仅当顶点集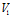 和
和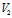 之间存在双射,即
之间存在双射,即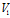 中的任意两个顶点
中的任意两个顶点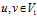 若有边相连,则这两个顶点在
若有边相连,则这两个顶点在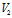 的映射顶点之间也有边相连[2]。
的映射顶点之间也有边相连[2]。频繁子图挖掘基础
什么才是图数据集上有用的模式呢?频繁模式就是一种有用的模式,因为频繁出现的模式可能代表着这个数据集上比较本质的东西,当然也不排除代表着比较普通的东西。图数据集上的频繁出现的模式就是频繁子图。考虑到一组具有抗癌作用的化合物集合,是什么样的共性使得这组药物具有抗癌的作用呢?也就是抗癌的效用是如何体现在分子的结构上的
。我们可以做出判断,在这组化合物上频繁出现的子结构模式可能代表了抗癌的效用的本质。因此,我们想知道如何才能在这组化合物上发现频繁的子结构模式。如果把化合物抽象为图,其中图的顶点表示化合物的原子,图中的边表示化合物的化学键,那么,我们就可以通过挖掘图集中的频繁出现的子图模式来发现化合物数据集中频繁出现的子结构模式,以此来发现这组化合物抗癌效用的本质。这将为人工合成新的抗癌药物提供参考。除此之外,频繁子图挖掘还有很多应用,如表 21所示[3]。表 21 不同应用领域中实体的图形表示
图形
顶点
边
Web挖掘
Web浏览模式
Web页面
页面之间的超链接
计算化学
化学化合物的结构
原子或离子
原子或离子之间的键
网络计算
计算机网络
计算机和服务器
机器之间的关联
语义Web
XML文档的集合
XML元素
元素之间的父子联系
生物信息学
蛋白质结构
氨基酸
接触残基
定义 2.4 支持度
给定图的集合ζ,子图g的支持度定义为包含它的所有图所占的百分比,即[3]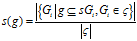
定义 2.5 频繁子图挖掘 给定图的集合
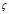 和支持度阈值minsup,频繁子图挖掘的目标是找出使得
和支持度阈值minsup,频繁子图挖掘的目标是找出使得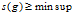 的子图g。[3]
的子图g。[3]尽管该定义适用于所有类型的图,但是本文主要关注无向连通图(undirected, connected graph)。这种图的定义如下:
- 一个图是连通的,如果图中每对顶点之间都存在一条路径;其中,路径是顶点的序列<v1v2v3…vk>,使得序列中的每对相邻的顶点(vi,vi+1)之间都有一条边。
- 如果一个图是无向的,如果它只包含无向边。一条边(vi, vj) 是无向的,如果它与(vj,vi)没有任何区别。
频繁子图挖掘是一项计算量很大的任务,因为搜索空间是指数级的。为了解释这项任务的复杂性,考虑包含d个数据实体的数据集。在频繁子图挖掘中,每个实体是一个项,待考察的搜索空间大小是2d,这是可能产生的候选项集的个数。在频繁子图挖掘中,每个实体是一个顶点,并且最多可以有d-1条到其它顶点的边。假定顶点的标号是唯一的,则子图的总数是
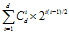
其中,
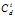
是选择i个顶点形成子图的方法数,而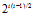
是i个顶点的图的总数。表 22对不同的d比较了项集和子图的个数。表 22 对于不同的维度d,项集和子图的个数比较
实体个数d
1
2
3
4
5
6
7
8
项集个数
2
4
8
16
32
64
128
256
子图个数
2
5
18
113
1450
40069
2350602
286192513
挖掘频繁子图的一种蛮力方法是,产生所有的连通子图作为候选,并计算它们各自的支持度。候选子图的个数比传统的关联规则挖掘中的候选子图的个数大得多,其原因如下。
- 项在某个项集中至少出现一次,而某个顶点标号可能在一个图中出现多次。
- 相同的顶点标号对可以有多种边标号选择。
给定大量候选子图,即使对于适度规模的图,蛮力方法也可能垮掉。
频繁子图挖掘过程
因为有更高效的gSpan算法作为本文的核心算法,所以这里仅对类Apriori算法的基本框架做出一个简要的介绍。
挖掘频繁子图的类Apriori算法由以下步骤组成。
- 候选生成:合并频繁(k-1)-子图对,得到候选k-子图。
- 候选剪枝:丢弃包含非频繁的(k-1)-子图的所有候选k-子图。
- 支持度计数:统计
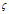 中包含每个候选的图的个数。
中包含每个候选的图的个数。
- 候选删除:丢弃支持度小于minsup的所有候选子图。
候选集生成
首要的问题是如何定义子图的大小k。通过添加一个顶点,迭代地扩展子图的方法称为顶点增长(vertex growing )。K也可以是图中边的个数。添加一条边到已有的子图中来扩展子图的方法叫做边增长(edge growing)。其中在类Apriori的频繁子图挖掘算法中,AGM算法采用顶点增长的策略,FSG算法采用边增长的策略。gSpan算法则采用边增长的策略。
候选集剪枝
产生候选k-子图后,需要减去(k-1)-子图非频繁的候选。候选剪枝可以通过如下步骤实现:相继从k-子图删除一条边,并检查对应的(k-1)-子图是否连通且频繁。如果不是,则该候选k-子图可以丢弃。这种策略与频繁项集挖掘的Apriori算法是类似的。
为了检查(k-1)-子图是否频繁,需要将它与其它频繁(k-1)-子图匹配。判定两个图是否拓扑等价(或同构)称为图同构问题。
支持度计数
支持度计数也是开销很大的操作,因为对于每个
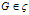
,必须确定包含在G中的所有候选子图。在后面详细介绍gSpan算法的时候,我会有详细的介绍。在进行支持度计数的时候需要进行图的同构测试。处理图同构的标准方法是,将每一个图都映射到一个唯一的串表达式,称为规范标号(canonical label )。规范标号具有如下性质:如果两个图是同构的,则它们的代码一定相同。这个性质使得我们可以通过比较图的规范标号来检查图同构。
在基于Apriori思想的算法中,通过图的邻接矩阵定义了一种规范标号。通过将图的邻接矩阵按行展开,逐行拼接,可以获得邻接矩阵的串表示。同一个图会有不同的邻接矩阵表示,所以也会有不同的串表示。我们将字典序最小的串表示作为图的规范标号。这里只是简单的陈述,因为在gSpan算法中,作者设计了一种独特的规范标号系统,我会在后面详细介绍gSpan算法的时候详细介绍。
本章小结
本章主要介绍频繁子图挖掘的概念和基础知识。首先,简要介绍了图论的相关知识,包括图的定义和组成,子图的定义,图同构和子图同构的定义。其中图同构和子图同构问题是频繁子图挖掘领域研究的重点,因为图同构测试在很大程度上影响了频繁子图挖掘算法的性能。然后,重点介绍了频繁子图挖掘的基本定义和基础知识。介绍了解决频繁子图挖掘的一般步骤(候选产生,候选剪枝,支持度计数,候选删除)和对应的基本方法。
本章介绍了频繁子图挖掘的基础知识,为了后面的章节详细介绍频繁子图挖掘算法做好了准备工作。
静态频繁连通子图挖掘算法
在每一层频繁子图的挖掘过程中,Apriori算法都会产生大量的非频繁的候选子图。然后对候选的频繁子图执行支持度计数。对于所有频繁的候选子图,还需要进行图的同构测试,以减除重复的频繁候选子图。因为图的同构测试是一种NP完全问题,所以对于大规模的频繁子图进行图的同构测试是一个开销很大的过程,甚至是不可能完成的任务。因此,大量生成的候选子图和图的同构测试的巨大开销是Apriori类方法的性能瓶颈。下面,将介绍一种不同于Apriori类方法的算法:基于模式增长的方法。不同于Apriori类的方法通过每次合并频繁k子图来生成候选k+1子图,基于模式增长的方法,每次扩展一条边来生成规模更大的候选。
模式增长方法:一个朴素的算法框架
算法1 NaiveGraph(g, D, min_sup, S)
Input: A graph g, a graph dataset D, and min_sup.
Output: The frequent graph set S.
1: if g exists in S then return;
2: else insert g to S;
3: scan D once, find every edge e such that g can be extended to g
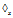 e and it is frequent;
e and it is frequent;4: for each frequent g
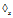 e do
e do5: Call NaiveGraph(g
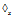 e, D, min_sup, S);
e, D, min_sup, S);6: return;
算法1描述了一个朴素的频繁子图挖掘算法[6]。这个算法挖掘所有的频繁子图。在下一节,我们试图对这个朴素的算法框架进行改造,创造性地提出高效率的gSpan算法。这个算法框架大概基于这样的过程:对于每一个已经发现的频繁子图g,迭代地执行边扩展的策略(每次增长一条边),直到所有能包含图g的频繁子图被完全发现为止。
这个朴素的算法框架使用两种必要的和显而易见的策略对频繁子图挖掘算法的搜索空间进行剪枝。在第四行展示了一种剪枝策略:当一个被频繁子图扩展出来的子图的支持度小于最小支持度阈值的时候,我们就没有扩展这个子图的必要了(根据子图支持度的非单调性)。第一行展示出第二种剪枝策略,当一个被扩展出来的频繁子图已经出现在挖掘结果的集合里面了,我们也没有必要对此进行扩展了(因为对此图的扩展已经完成了,没有必要进行重复地扩展)。
NaiveGraph虽然很简单,而且使用了两种高效的剪枝策略,但搜索频繁子图的代价仍然很高。它的瓶颈是扩展子图规模的时候的低效率,因为同样的图可能重复发现很多次[5]。我们只要观察一下一个频繁n边图是如何产生的,就可以明白这种重复是多么的严重。假设此n边图随意去除一条边可以生成连通的n-1边图(当然去除一条边可能使得n-1边图不连通,但是为了问题的简便,我们可以忽略掉),那么这个n边图可以生成n个n-1边图(忽略掉图的对称性以及相同边的影响)。根据支持度计数的反单调性,这n个n-1边图都是频繁的。反过来说,这n个n-1边图都可以通过一条边的扩展生成此频繁n边图。同样的图的反复出现必然带来计算资源的浪费。我们称二度发现的图为复制图(duplicatie graph)[5]。
我们仔细看一下这种重复图是如何带来计算资源的浪费的。首先,重复图的产生会消耗计算资源,其次重复的支持度计数会带来资源的浪费。然后,对重复图递归调用NaiveGraph函数,在挖掘的结果集合中查找此图是否为重复图。在结果集合中查找频繁子图不是一个简单的过程,需要进行图的同构测试。然而图的同构测试属于一个NP完全问题,会消耗非常大的计算资源。所以我们可以看出这种朴素算法结构的局限性所在。
为了优化这种朴素的算法框架,我们可以从两方面着手:首先,可以使用比较好的扩展策略,以此减少重复图的产生;其次,可以改进图的同构测试方法,以此降低图的查找和图的同构测试所产生的代价。正是这两个改进的方向,启发了gSpan算法的出现,极大地提高了NaiveGraph算法的性能。
gSpan算法思想
gSpan算法通过解决3.1节提出的问题来极大地提高了NaiveGraph算法的效率[5]。gSpan算法通过执行最右扩展的策略减少了重复的产生,同时也保证了搜索结果的完备性。gSpan算法设计出一种新式的图的规范标号,将图的同构测试与重复图的检测结合到一块,避免了在已经获得的频繁子图集合中搜索重复图。这些改进极大地提高了频繁子图挖掘算法的效率。
为此,gSpan算法引入了两个相关重要的概念:DFS字典序和最小DFS编码。以这两个创新的概念为基础,创造性的设计出一种高效的图的规范标号系统。
图的规范化表示和规范化扩展思想概述
让我们回顾一下NaiveGraph算法所面对的两个重要缺陷:首先,模式增长的过程中产生了大量的重复图;其次,对于重复图的检索和同构测试耗费大量的计算机资源。为什么频繁项集挖掘的模式增长算法不是面临这样的问题呢?我想,问题的根源在于图的表示的不确定性和不规范性。我们知道,如果将项集中的项有序排列,那么这个项集就有了唯一的表示方式。而且可以对项集进行有序的枚举以发现频繁项集。与之相反,同一个图会有不同的表示形式。考虑图的邻接矩阵表示,不同的顶点顺序对应不同的图的邻接矩阵表示。所以一个图共有n!种不同的邻接矩阵表示形式。这也造成了图的同构测试的复杂性!
因此,有一个直接的想法就是,如何构造一种图的规范表示形式,使得对于任何一个潜在的频繁子图,都有唯一的规范表示与之对应。我们称这个规范表示形式为规范标号。图的规范标号首先可以用于进行图的同构测试,如果两个图的规范标号相同,则这两个图同构。
其次,我们还希望图的规范标号还具有这样一种性质:对图的规范表示形式进行有限制的扩展之后,所获得的图很可能还是图的规范表示形式,我把它称之为规范的扩展。所谓有限制的规范扩展是指:并非对从图的任何位置进行模式的扩展,而是从规范表示的图的特定的位置进行扩展,以此减少重复图的产生,并且使得增长后的模式很可能仍然是一个频繁子图的规范表示形式。我们尽最大的可能保证扩展出来的图是频繁的而且是规范的。如果扩展出来的图不是规范的,我们直接就可以在搜索树上把它减去。这样,我们同样避免了在挖掘结果集合中检索并进行图同构测试。我们只需要检查扩展出来的子图是否是频繁的并且是否是规范的表示,然后把经过测试的结果放入到结果集合。
基于Apriori思想的算法使用了一种将图的邻接矩阵表示序列化之后编码最小化的图的规范标号方案。但是这种方案只能用于图的同构测试,而不能指导图的规范增长过程。因此,我们需要设计出一种新的图的规范标号系统。
受到图的邻接矩阵序列化方法的启发,我们可以考虑将图的边序列化,构造出一种图的规范标号出来。这个部分,我将详细地介绍gSpan算法设计出的符合以上要求的创新的规范标号系统,用于解决NaiveGraph算法所面临的性能瓶颈。为了构造出来这种规范标号系统,我会依次介绍一些新的概念。
图的序列化
为了将图的表示序列化,我们尝试定义一种基于深度优先搜索的边序。图的深度优先搜索可以定义图的顶点序,但是我们需要一些另外的规定以定义图的边序。首先介绍几个概念:
DFS下标。我们使用深度优先搜索访问图的节点,并根据访问到的次序为这些顶点定序。所有顶点的次序标号的集合称为图的DFS下标。在遍历的过程中,访问到的边和顶点构成了深度优先搜索树。因为一个图有不同的存储形式,比如同一个节点的邻接顶点存储的顺序不同,就可能造成节点下标的不一致。所以一个图可能产生不同的深度优先搜索树。将深度优先搜索树T做下标的图G记作
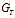 。T称为G的一个DFS下标(DFS subscripting )[5]。
。T称为G的一个DFS下标(DFS subscripting )[5]。图的二元组边序列。为了将图的表示序列化,我们现在介绍边的序。通过DFS下标,我们定义了图的顶点序。我们自然地可以通过顶点序来定义边的序。我们将图G在DFS树中的边称为前向边,不在其DFS树中的边称为后向边。自然地,DFS树已经定义了前向边的发现次序。现在,我们把后向边添加到该边序。给定顶点v,它的所有后向边应该正好在它的前向边之前出现。如果v没有前向边,把它的后向边放在该前向边之后,其中v是第二个顶点。在相同的顶点的后向边之中,强加一个序。假设顶点
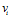
有两个后向边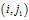
和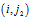
。如果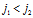
,则边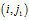 将出现在
将出现在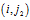 之前[5]。到此为止,我们已经完全定义了图中边的序。基于这个序,可以将图转换为边的序列,称为图的序列化表示。
之前[5]。到此为止,我们已经完全定义了图中边的序。基于这个序,可以将图转换为边的序列,称为图的序列化表示。图的五元组边序列。其次,即使两个图的边序相同而且边序对于这两个图都是唯一的,我们能说明这两个图是同构的吗?不是的,可虑到这样一种情况:两个图的拓扑结构相同,但是顶点和边的标号有一些差异。这时,即使这两个图的边序列是一样的,但是这两个图因为标号的差异,却不是同构的图。因此,标号作为图的表示的一部分,理应作为边序的一部分用来确定图的规范表示。使用一个五元组来表示一个边
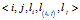
。其中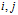
表示边的DFS下标,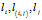
分别表示顶点i的标号,边的标号和顶点j的标号。我们把每个加下标的图转化为这样的五元组的序列,称为DFS 编码。规范化表示
因为图的存储形式的不确定性,所以,一个图对应着不同的DFS树,进而对应着不同的DFS编码。我们必须从众多的DFS编码中选出一种来作为图的规范标号,用于进行图的同构测试和图的规范化地有限制地扩展。
现在我们定义图的不同DFS编码的大小关系,用于寻找最小DFS编码作为图的规范标号,称为DFS字典序。同时,DFS字典序也定义了不同图的规范标号的大小关系,用于指导图的有序的扩展。令边序关系

具有第一优先级,顶点的标记
具有第二优先级,边标记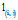
具有第三优先级,而顶点标记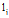
具有第四优先级,来决定两条边的序。基于上述规则的序称为DFS字典序(DFS Lexicographic Order)[5]。根据DFS字典序,给定图G的最小DFS Code记作DFS(G),是所有DFS编码中的最小者。我们将最小DFS编码作为图的规范标号,也称为图的规范化表示。
规范化扩展
先介绍几个概念:
最右顶点和最右路径。给定一棵DFS树T,称T的起始顶点v0为根。最后访问的顶点vn称为最右顶点。从v0到vn的直接路径称为最右路径[5]。
NaiveGraph算法在每个可能的位置随意扩展频繁图,这可能产生大量的重复图。gSpan算法引入了一种更为适当的扩展机制。新的方法对扩展有如下限制:给定图G和G的DFS树T,一条新边e可以添加到最右顶点和最右路径上另一个顶点之间(后向扩展);或者可以引进一个新的顶点并且连接到最右路径上的顶点(前向扩展)。由于这两种扩展都发生在最右路径上,因此称为最右扩展(right-most extension ),记为
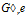
(为简短起见,这里省略了T)。这种扩展的完备性证明请参考文献[5]。通过最右扩展,可以大量减少重复图的产生。而且执行最右扩展的时候只需要在频繁图的最小DFS编码最后面添加一个表示边的五元组就可以获得扩展图的DFS编码,并且新生成的DFS编码很可能仍然是最小的DFS编码。我们称这种在最右端扩展最小DFS编码的过程成为规范化地有限制地扩展。对于扩展而成的子图,我们只需要测试其是否为最小的DFS编码,就可以决定是否将其加入到频繁子图结果集合以及是否继续随后的模式增长过程。这避免了在频繁结果集合中进行图的逐个比对和同构测试,因此极大地提高了频繁子图挖掘的效率。
DFS编码树。根据字典序的定义,频繁子图的最小DFS编码必然大于其扩展出来的后代的DFS编码,而且可以有序地对频繁子图的子代进行深度优先搜索。因此这样的搜索过程定义了DFS编码树。在一个DFS编码树里面,每一个节点代表一个DFS编码。其中孩子结点是在父母节点的基础上执行最右扩展得到的。兄弟节点按照字典序排列。因此,对于DFS编码树的前序遍历的结果就是按照字典序排列的频繁子图的最小DFS编码。在下面的3.3节,我将会详细地介绍这样的搜索过程。
gSpan算法介绍
gSpan算法框架
在这一部分里面,我们详细地介绍gSpan算法。首先,我将给出gSpan主要框架的伪代码描述,如下[4]:
算法2 GraphSet_Projection (GS,S)
1: sort labels of the vertices and edges in GS by their frequency;
2: remove infrequent vertices and edges;
3: relabel the remaining vertices and edges in descending frequency;
4:

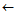 all frequent 1-edge graphs in GS;
all frequent 1-edge graphs in GS;5: sort
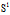 in DFS lexicographic order;
in DFS lexicographic order;6:
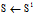 ;
;7: for each edge
 do
do8: initialize s with e, set s.GS =
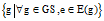 ;(only graph ID is recorded)
;(only graph ID is recorded)9: Subgraph_Mining(GS, S, s);
10:
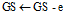 ;
;11: if
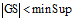
12: break;
第一步(1-6行)从图集GS中移除不频繁的顶点和边。对剩下的边根据标号的频率递减序重新标号。把所有的频繁一边图加入到
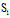
并且按照字典序排序。第二步(8-9行)对于所有的频繁一边图,调用模式增长算法Subgraph_mining,迭代增长图的规模。
第三步(10行)在挖掘了所有的以某一频繁一边图为起点的频繁子图后,移除图集GS中所有的与此频繁一边图的边相同的边。这一步能将图集GS映射到一个更小规模的图集。
第四步(7,11行)当所有的频繁一边图以及它们的子代被挖掘后,程序结束。
子程序2.1 Subgraph_mining (GS, S, s)
1: if
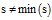 ;
;2: return;
3:
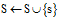 ;
;4: generate all s' potential children with one edge growth;
5: Enumerate(s);
6: for each c, c is s' child do
7: if support(c)
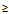 minSup
minSup8:
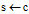 ;
;9: Subgraph_Mining(GS, S, s);
在每一次迭代过程中,Subgraph_mining子程序将子图s扩展一条边,并且发现s所有的频繁子代图(s是一个DFS编码或者DFS编码树中的一个节点)。Subgraph_mining程序递归执行。在每一次递归过程中,Subgraph_mining按照前序遍历搜索树,所以gSpan算法按照DFS字典序扩展频繁子图s。
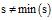 对重复图以及它们的子代进行剪枝。可以证明,这样的剪枝策略可以保证搜索接过
对重复图以及它们的子代进行剪枝。可以证明,这样的剪枝策略可以保证搜索接过
的完备性。如果s 是它所表示的图的最小DFS编码,那么Subgraph_mining子程序将s加入到频繁子图的结果集合S。然后,生成频繁子图s的一条边增长获得的后代集合,然后对每一个子代递归的调用Subgraph_mining子程序。生成子代的过程不会耗费太大的代价,但有很多的技巧值得讨论,我会在后面详细地介绍。子程序2.2 Enumerate (s)
1: for each
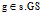 do
do2: enumerate the next occurrence of s in g;
3: for each c, c is s' child and occurs in g do
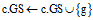 ;
;4: if g covers all children of s
break;
通过枚举频繁子图s在图集GS中的图g中的每一次出现,Enumerate(s)子程序对图g的每一个孩子进行计数。
在子程序2.2Enumerate(s)中没有必要进行子图同构测试。我们设计出一种在深度优先搜索树中进行回溯的策略。这种策略将子图的匹配和DFS编码的增长结合到一个过程,因此在很大程度上降低了计算的复杂性,而且可以将算法很容易地扩展到诱导子图同构问题上。枚举粗略简述如下。给定一个最小DFS编码,我们想要找到这个最小DFS编码在另外一个图g中的所有匹配。我们从DFS编码的一条边开始试图与图g中的一条边进行匹配。然后我们重复这样的步骤,每次迭代地匹配一条边。有时候如果我们无法匹配当前的边,我们不得不对匹配的深度进行回溯。我们重复这个过程,直到我们发现了一个匹配或者匹配失败然后结束。因为gSpan算法需要发现S在图g中的所有匹配,所以,一旦我们发现了一个匹配结果,我们就对这个匹配能够拓展的子代进行计数。然后,我们对匹配的过程进行回溯,尝试获取下一次匹配。因为在一次扫描的过程中能够发现所有的匹配,总的开销并不是很大。在下一部分,我们将会讨论几种优化。在这一部分的结尾,我将给出算法性能的分析以及算法可能的扩展。
gSpan算法分析
gSpan执行DFS搜索树的前序遍历。有关性质保证了DFS搜索树包含了所有潜在的频繁子图。因此,gSpan算法的完备性是可以保证的。相比于AGM算法和FSG算法,gSpan算法主要有以下的这些优势[4]:
- 没有候选生成和错误测试。在gSpan算法中,频繁(k+ 1)-edge子图直接从频繁k-edge子图增长得到。gSpan算法不用执行候选生成,不用测试所有任何的阴性候选,这不同于任何的基于Apriori思想的算法,例如AGM和FSG算法。而且相比于挖掘频繁项集的算法,挖掘频繁子图的算法进行候选生成会耗费更大的代价。虽然FSG算法对候选生成的过程有所生成,但是gSpan算法能够完全避免候选生成的过程。
- 深度优先搜索比广度优先搜索更节省空间。gSpan 算法是一种深度优先搜索算法,与之不同的是基于Apriori思想的AGM和FSG算法都采纳了广度优先搜索的策略。在I/O和内存的开销方面,广度优先搜索算法通常比深度优先搜索算法开销更大。
- 图数据集的快速收缩。在算法2中,每一个频繁一边图以及其子代被迭代地挖掘后,都会在图数据集GS上移除此频繁一边,以此来收缩图集GS的规模,使得GS中的图拥有更少的顶点和边。在挖掘的过程中,这会在很大程度上加速程序的执行过程。
算法实现和性能测试
第三章详细介绍了gSpan算法的伪代码描述。在4.1,首先介绍gSpan算法的实现,包括gSpan算法实现所需要的数据结构和程序框架。在4.2节,介绍对gSpan算法的性能测试结果,包括在经典的化合物数据集上运行的结果,以及在动态网络运行的结果。
算法实现
程序总体设计
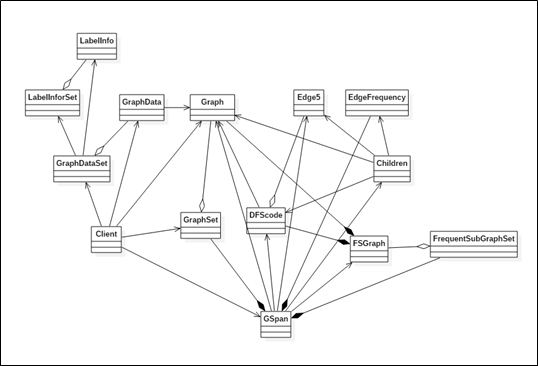
图 41 gSpan算法类图
从图 41可以看出,gSpan算法的数据结构非常的复杂。在实现的过程中用到了图的多种存储方式,分别是边表,邻接表,邻接矩阵
和 DFS 编码
。准确的选用不同的表示形式会使 gSpan 算法在不同的阶段获得比较好的性能,并且降低实现的难度。gSpan算法在实现过程中综合使用到多种数据结构,比如向量,数组,矩阵,栈,队列和 hash 表,图,树;能使用到很多的算法比如排序,树的前序遍历,图的深度优先搜索,图同构测试等。算法的结构很复杂,如何设计数据结构,优化算法的性能都是gSpan算法设计的困难所在。下面一节,我会简单介绍,以上类图中的每个类的功能以及是如何实现的。类的详细设计
GraphData 这个类是图的边表表示形式。如图 42所示,这个类使用顶点表和边表来表示一个图。此类包含顶点标签列表,顶点掩码列表,边的起始id列表,边的终止id列表,边的标签列表,边的掩码列表,顶点的新id列表。其中,顶点掩码列表,顶点的新的id列表,边的掩码列表并不是表示一个图所必须的,但是对于gSpan算法来说,这些结构有利于对图数据的预处理,这将会在gSpan算法reLabel的阶段用得着。
为了便捷地实现高效率的gSpan算法,我将会综合使用图的四种数据表示形式,分别为边表,邻接表,邻接矩阵和DFS编码。GraphData这个类就代表图的边表表示形式。因为边表的表示形式方便存储,所有我们能获得的图数据文件一般都是使用边表保存的。所以我将使用边表保存图数据的类称为GraphData。其次,边表的表示形式非常有利于统计顶点和边的标号的频率,过滤掉非频繁的边,重新标号等预处理过程,所以在读取图数据的过程中,我并没有急于直接将边表表示转换为邻接表表示。但是对于图的遍历过程,边表表示显然不如邻接表或者邻接矩阵方便。所以在对图数据进行重新标号之后,将边表表示转化为邻接表表示。
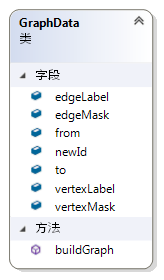
图 42 Class GraphData
GraphDataSet这个类是GraphData类的容器,是继承了Vector内置容器后实现的。如图 43所示,除了继承Vector容器的方法和属性之外,我又定义了很多新的方法和属性,以便于gSpan算法的使用,另外GraphSet类,FrequentSubGraphSet类都是基于同样的思路。其中,edge_label_size表示gSpan算法进行重新标号之后的不同标号的种类。edgeLabelRecover保存了重新标号之后的标号系统与重新标号之前的标号系统之间的映射,用于在gSpan算法结束后,恢复标号的映射。min_sup保存最小支持度阈值。nodeLabelRecover类似于edgeLabelRecover,用于恢复边的标号。vertex_label_size与edge_label_size类似,用于保存顶点标号的种类数。readFromFile方法用于从文件中读取图数据到GraphDataSet的对象。reLabel的作用与gSpan算法中的reLabel一致,用于对顶点标号和边标号进行统计,按照标号的频率对标号进行降序排序,将标号的顺序作为标号的值对图数据进行重新标号。
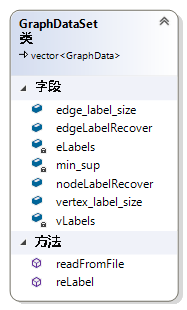
图 43 Class GraphDataSet
Graph这个类是图的邻接表表示。因为邻接表表示有利于图的遍历,所以在重新标号之后,要将GraphData表示的图数据转换为Graph表示的数据,即使用图的邻接表表示形式。如图 44所示,edgeLabel,edgeTo都是二维动态向量用于实现图的邻接表表示。vertexLabel用于保存顶点的标号。addEdge和addVertex分别用于在Graph中添加一条边和一个顶点。hasEdge用于判断Graph的对象中是否存在某一条边。RemoveEdge用于移除Graph的对象中的某一条边。
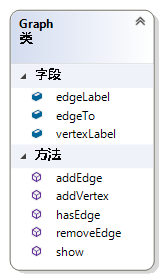
图 44 Class Graph
GraphSet 是用于保存Graph的容器,另外封装了一些方法,体现了面向对象封装和抽象的思想。如图 45,GraphSet有两个属性,与GraphDataSet中的同名属性含义相同。Show方法用于将图数据集显示在屏幕上或者保存到文件里面。
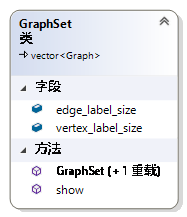
图 45 Class GraphSet
Edge5使用一个5元组表示一条边。如图图 46,五元组分别为边的起始id,边的终止id,边的起始顶点的标号,边的标号,边的终止顶点的标号,分别对应于Edge5的五个属性。这个五元组跟gSpan算法中的五元组是一样的,用于将一个图的表示序列化。方法forward和backward用于判断此五元组表示的边是前向的还是后向的。此外重载了比较运算符,用于gSpan算法对边进行排序。
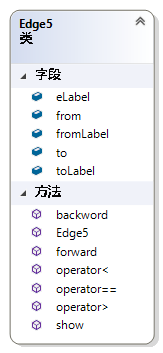
图 46 Class Edge5
DFScode即是Edge5的容器,也是图的序列化表示,最小DFScode可以作为图的规范标号,用于判别图是否同构。edgeVisited是图的矩阵表示形式,用于快速判断某一个边是否访问过。graph2code保存从图的邻接矩阵表示形式的顶点id到DFScode表示形式的顶点id的映射,在判断DFScode是否为最小时发挥作用。Is_min用于保存判断的结果。isMin方法用于判断此DFScode是否为最小DFS编码。Show方法可以用于打印图的DFScode表示形式到屏幕上。toGraph方法用于将图的DFScode表示形式转换为类Graph表示的形式。
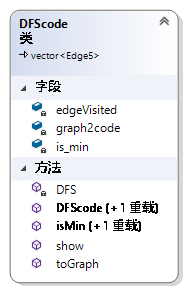
图 47 Class DFScode
EdgeFrequency用于记录某一条边是否是频繁的。此结构对于提升gSpan算法的性能非常重要。首先,如果一条边不是频繁的,那么就不应该以此为基础进行图的模式扩展以挖掘其频繁后代。因为根据频繁模式的反单调性,包含此非频繁一边的子图必定不频繁。其次,如果一条边是不频繁的,我们就没有必要在匹配成功一个频繁子图之后扩展这样的一条边从而生成后代,同样是因为反单调性。在扩展一条边的时候,只需要查一下这条边是否是频繁的,即查一下这张表,就可以少扩展出很多的子代,从而优化了程序的性能。如图 48,这个类是三维数组的手动实现形式,主要为了程序的可扩展性,使用了动态内存分配。
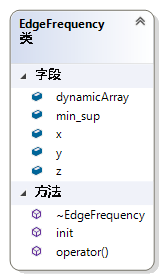
图 48 Class EdgeFrequency
FSGraph并没有什么特别的,主要是为了封装一些数据和方法,用于保存挖掘出来的频繁子图。如图 49所示,属性g表示图的邻接表表示形式,类型为Graph,gc为图的DFScode表示形式,类型为DFScode。isMaximal 用于保存这个频繁子图是否为极大频繁子图。Supporter用于保存频繁子图的支持度计数。saveToFile顾名思义,用来将结果保存到文件。Show方法用于将结果显示到屏幕上。因为挖掘出来的结果可能会很多,所以show方法并没有saveToFile实用。
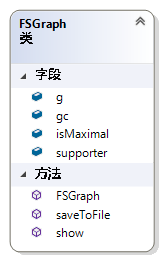
图 49 Class FSGraph
FrequentSubGraphSet 是FSGraph类的容器结构,如图 410所示,这个类只有一个方法,show方法,用于保存结果。
图 410 Class FrequentSubGraphSet
Children类用于在图g中找出所有可以通过gc(DFScode类型)扩展得到的子图,在gSapn算法中可以用于对子图进行枚举。Children继承了内置容器set,保存的元素为Edge5类型的。因为子图是由gc(DFScode类型)扩展得到的,而且扩展的边只能放在gc的最后边,所以Children类型只需要保存扩展的边即可,反正其它的边都是所有的Children所共有的,即gc中的边。使用set类型是为了防止后代枚举重复,即防止后代子图支持度计数重复。如图 411code2graph,edgeVisited,g,gc的功能与DFScode中的同名属性作用一样。graph2code是code2graph的反向映射。rmPath记录最右路径,ef是EdgeFrequency类型的对象,用于子代扩展时的非频繁边扩展的剪枝。getChildren方法用于执行匹配和扩展的过程,获得可以扩展的子代。DFS方法采用回溯法扩展子代,由getChildren方法调用。
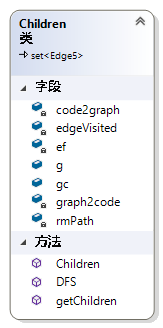
图 411 Class Children
GSpan类是算法核心类,定义了算法的具体实现过程。已上定义的类大多属于gSpan算法使用到的数据结构,抽象为类型,体现了面向对象抽象和封装的特性。gSpan类是此程序的核心类型,直接体现了第三章所提到的算法思想。如图 412所示,ef对象为EdgeFrequency类型,其作用在上文多有介绍,这里不再赘述。gs对象为GraphSet类型,保存图数据集,用于频繁子图挖掘,使用邻接表的表示方式。maximalResultSet对象为FrequentSubGraphSet类型,用于保存挖掘到的极大频繁子图。resultSet用于同样为FrequentSubGraphSet类型,用于保存挖掘到的频繁子图。min_sup属性指最小支持度阈值。Run方法为gSpan算法的主体,用于执行挖掘的过程。getResult 用于获取挖掘的结果。getMaximal用于获得挖掘的极大频繁子图。subGraphMining与第三章的伪代码中子过程2.2同名,功能也一样,用于迭代地扩展子代。show方法和save方法与已上提到的同名方法类似,这里不再赘述。gSpan算法的具体实现体现了算法2的思想,这里不再赘述。
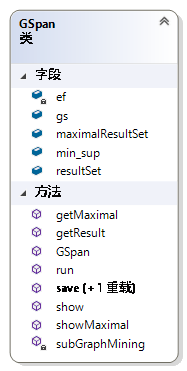
图 412 Class gSpan
程序编码实现
受到篇幅的限制,这里不再给出全部的代码。
实验分析
实验环境介绍
实验运行的硬件环境为:CPU是Intel(R) Core(TM) i5-4200M CPU @ 2.50GHz,两个实际核心,四个逻辑核心,一级缓存128KB,二级缓存512KB,三级缓存3.0MB;内存DDR3L 8GB。
实验运行的软件环境为:操作系统是 Windows 10;编译环境为Visual studio 2017;程序语言为C++语言。
实验数据介绍
化合物组件数据集。化合物组件数据集可以从以下的链接中获得。数据集包含340个化合物,其中包含24种不同的原子,66种原子类型和4种化学键类型。数据集中的图非常的稀疏,每个图平均包含27个顶点和28条边。最大的图包含214个顶点和214条边。所以,挖掘的模式更像是图模式,虽然,不排除会出现环结构。我们使用原子类型和化学键的类型分别作为顶点和边的标签。在这里,频繁子图挖掘的目标是发现公共的化合物子结构。
Enron 公司的职工E-mails网络。Enron 公司的职工E-mail网络是一个关于Enron公司职工之间收发电子邮件的公开可用的数据。时刻、发送者和接收者列表均可以从数据文件中获取,数据库中的数据以天为单位。网络中的节点表示职工,而连接两个节点的边表示这两个职工之间有电子邮件收发关系。为了更好的分析问题,以月作为时间刻度,若在某个月内,两个职工之间有电子邮件收发关系,则这两个节点之间有边相连。采用Tang等人处理过的原始数据集的简化版本进行分析,其中包含了从1999年9月到2002年3月共计28个月的数据。
实验结果分析
静态频繁子图挖掘分析使用的是化合物组件数据集,这是在静态频繁子图挖掘算法研究领域经常使用的真实数据集,包括FSG算法和gSpan算法都是在这个数据集上进行测试和比较的,因此可以将算法的实现在这个数据集上进行测试以此和其它的算法进行正确性的交叉验证和性能的对比。如图 413所示,此图表示算法的运行时间随着支持度阈值的变化情况。因为随着支持度阈值的增长,频繁子图所需要的支持度计数也在增长,从而潜在的频繁子图的个数会下降,从而算法能够有效的利用剪枝规则,加快程序的结束。因为图 413的纵坐标为对数坐标系,所以可以看出算法的时间复杂度非常的高,已经超越了指数级的增长速度。理论上的分析也是如此,在第2.2节当中,已经讨论过频繁子图挖掘算法潜在的搜索空间的大小。从而证明了,频繁子图挖掘算法的复杂性之高!
图 414表示挖掘到的频繁子图数量随着最小支持度阈值的减小而快速增长的过程。这种变化与运行时间的变化是一致的,我由此猜测,程序的运行时间会随着潜在的频繁子图数量而线性变化,理论上的推导即是如此。图 415证明了这个猜想,运行时间确实与潜在频繁子图的数量近乎呈现线性关系,这为估计一定规模的潜在频繁子图数量的频繁子图挖掘任务的运行时间提供了查考。
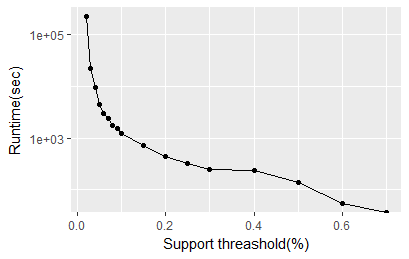
图 413运行时间随着最小支持度阈值的变化
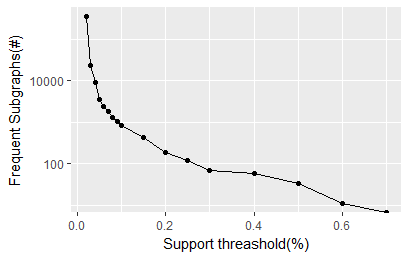
图 414挖掘到的频繁子图数量随着最小支持度阈值的变化
化合物组件数据集中的图的规模都比较小,平均27个顶点和28条边,多呈现树形的结构,少有回路。因此潜在的频繁子图数量不会太多。而对于规模较大的网络而言,gSpan算法的可扩展性值得怀疑。首先,如果潜在的最大的频繁子图如果很大,根据反单调性原理,此频繁子图的所有子图都为频繁子图,而且子图的支持度必然大于此频繁子图。如果挖掘到的频繁子图的数量很多,我们很难从挖掘到的频繁子图中获取有用的信息,因为我们挖掘的频繁子图的数量势必比原来的数据量更大!其次,即使不考虑到挖掘结果的实用性,如果潜在的最大的频繁子图如果很大,算法的复杂性也难以接受,算法的运行时间增长会很快。
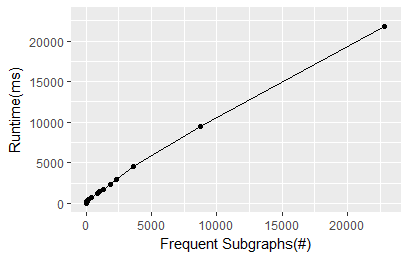
图 415运行时间随着挖掘到的频繁子图数量变化
事实上由于Enron 公司的职工E-mails网络非常大,短时间的运行即产生了海量的频繁子图数据,频繁子图挖掘的结果数据远大于原始数据本身。首先,这样的任务对于普通的计算机是无法承受的。其次,因为挖掘结果的庞大和冗余,对于挖掘结果的利用很难实现。因此,我并没有尝试把程序运行下去。
由此,我获得了有益的启发:将频繁子图挖掘算法真正的应用在真实的系统上,还有很长的路要走,这和频繁项集挖掘算法的应用困难是一致的。为了应对挖掘结果的扩张,首先要考虑到的就是挖掘结果的压缩。在这方面已经有了很多的研究,比如考虑挖掘闭合频繁子图,极大频繁子图,考虑对挖掘的结果增加一些条件限制。有些条件限制的单调性或者反单调性还可以用于搜索空间的剪枝,加快程序的运行。还可以从挖掘到的结果中,根据条件限制过滤出有用的结果,或者根据统计学的方法过滤出更符合真实情况的结果。这方面的研究成果非常的多,理论也比较丰富,这已经超出了我在这篇文章要讨论的范围。
总结和展望
频繁子图挖掘研究已经有了很多的理论成果,但是还存在很多的问题有待解决。本章总结此论文所做的工作,分析目前工作的不足之处,并指出下一步的研究方向和待解决的问题。
总结
图数据结构作为通用的数据结构,可以描述事物实体之间复杂的关系。图数据结构作的数据挖掘研究已经成为当前数据挖掘领域的一个重要研究方向,并取得了一系列的研究成果
。本文以子图挖掘为主要的研究内容,进行了下面的工作。- 学习图论中的基础知识,学习数据挖掘的基本理论,理解经典的关联规则挖掘和频繁子图挖掘算法和思想,为接下来的工作做好理论准备。
- 深入理解gSpan算法的设计思路和实现原理,设计gSpan算法的数据结构,实现gSpan算法,并分别在化合物组件数据集和Enron 公司的职工E-mails网络上运行,理解gSpan算法的局限性和图挖掘算法在应用领域的困难所在。
- 思考gSpan算法的改进方法,了解gSpan算法后续的研究进展,了解gSpan算法的应用情况。了解现今对动态网络和其它图挖掘算法的研究现状。
展望
虽然本文取得了一些研究成果,但是本文所做的研究工作还有一定的局限性。比如,虽然能够正确实现gSpan算法,但是gSpan算法并不能有效地对大规模的动态网络数据进行挖掘。事实上由于Enron 公司的职工E-mails网络非常大,短时间的运行即产生了海量的频繁子图数据,频繁子图挖掘的结果数据远大于原始数据本身。首先,这样的任务对于普通的计算机是无法承受的。其次,因为挖掘结果的庞大和冗余,对于挖掘结果的利用很难实现。
由此,我获得了有益的启发:将频繁子图挖掘算法真正的应用在真实的系统上,还有很长的路要走,这和频繁项集挖掘算法的应用困难是一致的。为了应对挖掘结果的扩张,首先要考虑到的就是挖掘结果的压缩。在这方面已经有了很多的研究,比如考虑挖掘闭合频繁子图,极大频繁子图,考虑对挖掘的结果增加一些条件限制。有些条件限制的单调性或者反单调性还可以用于搜索空间的剪枝,加快程序的运行。还可以从挖掘到的结果中,根据条件限制过滤出有用的结果,或者根据统计学的方法过滤出更符合真实情况的结果。由此可见,图数据挖掘的研究成果向应用领域转换仍存在很多问题。在实际应用领域,图挖掘仍然有相当多需要研究的内容。
致谢
本文是在***教授的精心指导下完成的。从论文的立题到最终完成,他都给予了极大的关怀和帮助,并提出了宝贵的意见。在此论文结束之际,我以诚挚的心情向她表示衷心的感谢,感谢在这半年时间里对我的亲切关怀,热情鼓励和悉心指导。
最后,特别感谢我的父母给予我的支持和理解!
参考文献
- 刘振. 频繁子图挖掘算法的研究与应用[D]. 中南大学, 2009.
- 覃桂敏. 复杂网络模式挖掘算法研究[D]. 西安电子科技大学, 2012.
- PANG-NINGTAN, MICHAELSTEINBACH, VIPINKUMAR. 数据挖掘导论:完整版[M]. 人民邮电出版社, 2011.
- Yan X, Han J. gSpan: Graph-Based Substructure Pattern Mining[C]// IEEE International Conference on Data Mining. IEEE Computer Society, 2002:721.
- Han J, Kamber M. Data Mining: Concepts and Techniques[J]. Data Mining Concepts Models Methods & Algorithms Second Edition, 2012, 5(4):1 - 18.
- Yan, Xifeng, Han, et al. CloseGraph: mining closed frequent graph patterns[J]. Proc Kdd, 2003:286-29.
静态频繁子图挖掘算法用于动态网络——gSpan算法研究的更多相关文章
- GSpan-频繁子图挖掘算法
GSpan频繁子图挖掘算法,网上有很多相关的介绍,中文的一些资料总是似是而非,讲的不是很清楚(感觉都是互相抄来抄去,,,基本都是一个样,,,),仔细的研读了原论文后,在这里做一个总结. 1. GSpa ...
- 频繁项集挖掘之Aprior和FPGrowth算法
频繁项集挖掘的应用多出现于购物篮分析,现介绍两种频繁项集的挖掘算法Aprior和FPGrowth,用以发现购物篮中出现频率较高的购物组合. 基础知识 项:“属性-值”对.比如啤酒2罐. 项集:项的集 ...
- 频繁项挖掘算法Apriori和FGrowth
一:背景介绍 最近在公司用spark的平台做了一个购物车的推荐,用到的算法主要是FGrowth算法,它是Apriori算法的升级版,算法的主要目的是找出频繁进行一起购买的商品.本文主要介绍两个算法的背 ...
- 【甘道夫】并行化频繁模式挖掘算法FP Growth及其在Mahout下的命令使用
今天调研了并行化频繁模式挖掘算法PFP Growth及其在Mahout下的命令使用,简单记录下试验结果,供以后查阅: 环境:Jdk1.7 + Hadoop2.2.0单机伪集群 + Mahout0.6 ...
- 数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法
整理数据挖掘的基本概念和算法,包括关联规则挖掘.分类.聚类的常用算法,敬请期待.今天讲的是关联规则挖掘的最基本的知识. 关联规则挖掘在电商.零售.大气物理.生物医学已经有了广泛的应用,本篇文章将介绍一 ...
- 八、频繁模式挖掘Frequent Pattern Mining
频繁模式挖掘(Frequent Pattern Mining): 频繁项集挖掘是通常是大规模数据分析的第一步,多年以来它都是数据挖掘领域的活跃研究主题.建议用户参考维基百科的association r ...
- 频繁模式挖掘中Apriori、FP-Growth和Eclat算法的实现和对比
最近上数据挖掘的课程,其中学习到了频繁模式挖掘这一章,这章介绍了三种算法,Apriori.FP-Growth和Eclat算法:由于对于不同的数据来说,这三种算法的表现不同,所以我们本次就对这三种算法在 ...
- 数据挖掘算法之关联规则挖掘(二)FPGrowth算法
之前介绍的apriori算法中因为存在许多的缺陷,例如进行大量的全表扫描和计算量巨大的自然连接,所以现在几乎已经不再使用 在mahout的算法库中使用的是PFP算法,该算法是FPGrowth算法的分布 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
随机推荐
- FastDFS分布式文件系统
FastDFS分布式文件系统 阅读目录 相关文章 1 分布式文件系统介绍 2 系统架构介绍 3 FastDFS性能方案 4 Linux基本命令操作 5 安装VirtualBox虚拟机并配置Ubuntu ...
- vue-cli 自定义指令directive 添加验证滑块
vue项目注册登录页面遇到了一个需要滑块的功能,网上看了很多插件发现都不太好用,于是自己写了一个插件供大家参考: 用的是vue的自定义指令direcive,只需要在需要的组件里放入对应的标签嵌套即可: ...
- win10 uwp 关联文件
有时候应用需要打开后缀名为x的文件,那么如何从文件打开应用? 首先,需要打开 Package.appxmanifest 添加一个功能,需要添加最少有名称,文件类型. 上面的图就是我添加jpg 的方法, ...
- C#同步方法转异步
public async Task DelayAsync() { await Task.Run(()=>Delay()); } private void Delay() { } 本作品采用知识共 ...
- 神经网络JOONE的实践
什么是joone Joone是一个免费的神经网络框架来创建,训练和测试人造神经网络.目标是为最热门的Java技术创造一个强大的环境,为热情和专业的用户. Joone由一个中央引擎组成,这是Joone开 ...
- 虚拟专用网VPN
1. 三个专用地址块: (1)10.0.0.0到10.255.255.255 (2)172.16.0.0到172.31.255.255 (3)192.168.0.0到192.168.255.255 2 ...
- iOS之 Auto Layout
1. 动画 // 修改从 StoryBoard 绑定到类的约束的值 self.boxView.constant += 80 // 在动画闭包里对其父级进行 layoutIfNeeded() UIVie ...
- Tomcat降权启动
对于任何降权的操作都是为了更好的保护自己的服务器免受危害,所以我们使用Tomcat也不了外,也需要进行降权操作.因为当 Tomcat以系统管理员身份或作为系统服务运行时,Java运行时取得了系统用户或 ...
- Flex 布局实例
如图: 代码如下: <!DOCTYPE HTML> <html> <meta charset="utf-8"> <head> < ...
- mybatis映射异常
今天写项目突然遇到了这么个问题: nested exception is org.apache.ibatis.reflection.ReflectionException: There is no ...