PHP数据核心:Zend HashTable详解
最近看了篇关于php内的hashtable的文章,PHP数据存储的核心,各种常量、变量、函数、类、对象等都用它来组织的。转载地址 http://www.phppan.com/2009/12/zend-hashtable/,源码还没看,看了第一部分的逻辑讲解,先转载一下
HashTable在通常的数据结构教材中也称作散列表,哈希表。其基本原理比较简单(如果你对其不熟悉,请查阅随便一本数据结构教材或在网上搜 索),但PHP的实现有其独特的地方。理解了HashTable的数据存储结构,对我们分析PHP的源代码,特别是Zend Engine中的虚拟机的实现时,有很重要的帮助。它可以帮助我们在大脑中模拟一个完整的虚拟机的形象。它也是PHP中其它一些数据结构如数组实现的基 础。
Zend HashTable的实现结合了双向链表和向量(数组)两种数据结构的优点,为PHP提供了非常高效的数据存储和查询机制。
一、 HashTable的数据结构
在Zend Engine中的HashTable的实现代码主要包括zend_hash.h, zend_hash.c这两个文件中。Zend HashTable包括两个主要的数据结构,其一是Bucket(桶)结构,另一个是HashTable结构。Bucket结构是用于保存数据的容器,而 HashTable结构则提供了对所有这些Bucket(或桶列)进行管理的机制。
typedef struct bucket {
|
在Zend HashTable中,每个数据元素(Bucket)有一个键名(key),它在整个HashTable中是唯一的,不能重复。根据键名可以唯一确定 HashTable中的数据元素。键名有两种表示方式。第一种方式使用字符串arKey作为键名,该字符串的长度为nKeyLength。注意到在上面的 数据结构中arKey虽然只是一个长度为1的字符数组,但它并不意味着key只能是一个字符。实际上Bucket是一个可变长的结构体,由于arKey是 Bucket的最后一个成员变量,通过arKey与nKeyLength结合可确定一个长度为nKeyLength的key。这是C语言编程中的一个比较 常用的技巧。另一种键名的表示方式是索引方式,这时nKeyLength总是0,长整型字段h就表示该数据元素的键名。简单的来说,即如果 nKeyLength=0,则键名为h;否则键名为arKey, 键名的长度为nKeyLength。
当nKeyLength > 0时,并不表示这时的h值就没有意义。事实上,此时它保存的是arKey对应的hash值。不管hash函数怎么设计,冲突都是不可避免的,也就是说不同 的arKey可能有相同的hash值。具有相同hash值的Bucket保存在HashTable的arBuckets数组(参考下面的解释)的同一个索 引对应的桶列中。这个桶列是一个双向链表,其前向元素,后向元素分别用pLast, pNext来表示。新插入的Bucket放在该桶列的最前面(类似学校里的某同学在同班级(即相同哈希值)中报道前后的关系。比如小刚和小明是同班级的,小刚在小明之前报道,所以小刚的pLast指到小明,小明的pNext指到小刚)。
在Bucket中,实际的数据是保存在pData指针指向的内存块中,通常这个内存块是系统另外分配的。但有一种情况例外,就是当Bucket保存 的数据是一个指针时,HashTable将不会另外请求系统分配空间来保存这个指针,而是直接将该指针保存到pDataPtr中,然后再将pData指向 本结构成员的地址。这样可以提高效率,减少内存碎片。由此我们可以看到PHP HashTable设计的精妙之处。如果Bucket中的数据不是一个指针,pDataPtr为NULL。
HashTable中所有的Bucket通过pListNext, pListLast构成了一个双向链表。最新插入的Bucket放在这个双向链表的最后(类似学校里的某同学在其报道前后的关系。没有班级限制)。
注意在一般情况下,Bucket并不能提供它所存储的数据大小的信息。所以在PHP的实现中,Bucket中保存的数据必须具有管理自身大小的能力。
typedef struct _hashtable {
|
在HashTable结构中,nTableSize指定了HashTable的大小,同时它限定了HashTable中能保存Bucket的最大数量,此 数越大,系统为HashTable分配的内存就越多。为了提高计算效率,系统自动会将nTableSize调整到最小一个不小于nTableSize的2 的整数次方。也就是说,如果在初始化HashTable时指定一个nTableSize不是2的整数次方,系统将会自动调整nTableSize的值。即
nTableSize = 2ceil(log(nTableSize, 2)) 或 nTableSize = pow(ceil(log(nTableSize,2)))
例如,如果在初始化HashTable的时候指定nTableSize = 11,HashTable初始化程序会自动将nTableSize增大到16。
arBuckets是HashTable的关键,HashTable初始化程序会自动申请一块内存,并将其地址赋值给arBuckets,该内存大 小正好能容纳nTableSize个指针。我们可以将arBuckets看作一个大小为nTableSize的数组,每个数组元素都是一个指针,用于指向 实际存放数据的Bucket。当然刚开始时每个指针均为NULL。
nTableMask的值永远是nTableSize – 1,引入这个字段的主要目的是为了提高计算效率,是为了快速计算Bucket键名在arBuckets数组中的索引。
nNumberOfElements记录了HashTable当前保存的数据元素的个数。当nNumberOfElement大于nTableSize时,HashTable将自动扩展为原来的两倍大小。
nNextFreeElement记录HashTable中下一个可用于插入数据元素的arBuckets的索引。
pListHead, pListTail则分别表示Bucket双向链表的第一个和最后一个元素,这些数据元素通常是根据插入的顺序排列的。也可以通过各种排序函数对其进行重 新排列。pInternalPointer则用于在遍历HashTable时记录当前遍历的位置,它是一个指针,指向当前遍历到的Bucket,初始值是 pListHead。
pDestructor是一个函数指针,在HashTable的增加、修改、删除Bucket时自动调用,用于处理相关数据的清理工作。
persistent标志位指出了Bucket内存分配的方式。如果persisient为TRUE,则使用操作系统本身的内存分配函数为Bucket分配内存,否则使用PHP的内存分配函数。具体请参考PHP的内存管理。
nApplyCount与bApplyProtection结合提供了一个防止在遍历HashTable时进入递归循环时的一种机制。
inconsistent成员用于调试目的,只在PHP编译成调试版本时有效。表示HashTable的状态,状态有四种:
状态值 含义
HT_IS_DESTROYING 正在删除所有的内容,包括arBuckets本身
HT_IS_DESTROYED 已删除,包括arBuckets本身
HT_CLEANING 正在清除所有的arBuckets指向的内容,但不包括arBuckets本身
HT_OK 正常状态,各种数据完全一致
typedef struct _zend_hash_key {
|
现在来看zend_hash_key结构就比较容易理解了。它通过arKey, nKeyLength, h三个字段唯一确定了HashTable中的一个元素。
根据上面对HashTable相关数据结构的解释,我们可以画出HashTable的内存结构图:
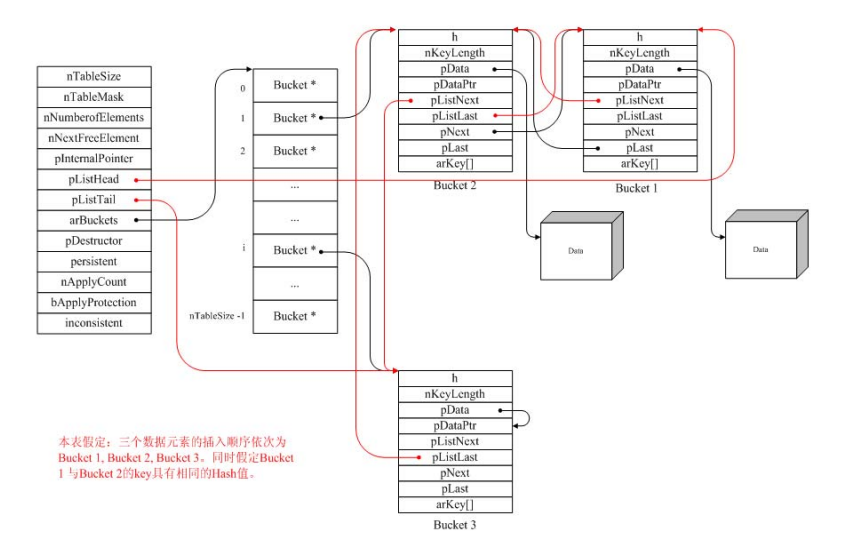
hashtable结构
二、 Zend HashTable的实现
本节具体介绍一下PHP中HashTable的实现。以下函数均取自于zend_hash.c。只要充分理解了上述数据结构,HashTable实现的代码并不难理解。
1 HashTable初始化
HashTable提供了一个zend_hash_init宏来完成HashTable的初始化操作。实际上它是通过下面的内部函数来实现的:
ZEND_API int _zend_hash_init(HashTable *ht, uint nSize, hash_func_t pHashFunction, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC) |
在以前的版本中,可以使用pHashFunction来指定hash函数。但现PHP已强制使用DJBX33A算法,因此实际上pHashFunction这个参数并不会用到,保留在这里只是为了与以前的代码兼容。
2 增加、插入和修改元素
向HashTable中添加一个新的元素最关键的就是要确定将这个元素插入到arBuckets数组中的哪个位置。根据上面对Bucket结构键名 的解释,我们可以知道有两种方式向HashTable添加一个新的元素。第一种方法是使用字符串作为键名来插入Bucket;第二种方法是使用索引作为键 名来插入Bucket。第二种方法具体又可以分为两种情况:指定索引或不指定索引,指定索引指的是强制将Bucket插入到指定的索引位置中;不指定索引 则将Bucket插入到nNextFreeElement对应的索引位置中。这几种插入数据的方法实现比较类似,不同的只是定位Bucket的方法。
修改HashTable中的数据的方法与增加数据的方法也很类似。
我们先看第一种使用字符串作为键名增加或修改Bucket的方法:
ZEND_API int _zend_hash_add_or_update(HashTable *ht, char *arKey, uint nKeyLength, void *pData, uint nDataSize, void **pDest, int flag ZEND_FILE_LINE_DC) |
因为这个函数是使用字符串作为键名来插入数据的,因此它首先检查nKeyLength的值是否大于0,如果不是的话就直接退出。然后计算arKey对应的 hash值h,将其与nTableMask按位与后得到一个无符号整数nIndex。这个nIndex就是将要插入的Bucket在arBuckets数 组中的索引位置。
现在已经有了arBuckets数组的一个索引,我们知道它包括的数据是一个指向Bucket的双向链表的指针。如果这个双向链表不为空的话我们首先检查 这个双向链表中是否已经包含了用字符串arKey指定的键名的Bucket,这样的Bucket如果存在,并且我们要做的操作是插入新Bucket(通过 flag标识),这时就应该报错 – 因为在HashTable中键名不可以重复。如果存在,并且是修改操作,则使用在HashTable中指定了析构函数pDestructor对原来的 pData指向的数据进行析构操作;然后将用新的数据替换原来的数据即可成功返回修改操作。
如果在HashTable中没有找到键名指定的数据,就将该数据封装到Bucket中,然后插入HashTable。这里要注意的是如下的两个宏:
CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex])
CONNECT_TO_GLOBAL_DLLIST(p, ht)
前者是将该Bucket插入到指定索引的Bucket双向链表中,后者是插入到整个HashTable的Bucket双向链表中。两者的插入方式也不同,前者是将该Bucket插入到双向链表的最前面,后者是插入到双向链表的最末端。
下面是第二种插入或修改Bucket的方法,即使用索引的方法:
ZEND_API int _zend_hash_index_update_or_next_insert(HashTable *ht, ulong h, void *pData, uint nDataSize, void **pDest, int flag ZEND_FILE_LINE_DC) |
flag标志指明当前操作是HASH_NEXT_INSERT(不指定索引插入或修改), HASH_ADD(指定索引插入)还是HASH_UPDATE(指定索引修改)。由于这些操作的实现代码基本相同,因此统一合并成了一个函数,再用flag加以区分。
本函数基本与前一个相同,不同的是如果确定插入到arBuckets数组中的索引的方法。如果操作是HASH_NEXT_INSERT,则直接使用nNextFreeElement作为插入的索引。注意nNextFreeElement的值是如何使用和更新的。
3 访问元素
同样,HashTable用两种方式来访问元素,一种是使用字符串arKey的zend_hash_find();另一种是使用索引的访问方式zend_hash_index_find()。由于其实现的代码很简单,分析工作就留给读者自已完成。
4 删除元素
HashTable删除数据均使用zend_hash_del_key_or_index()函数来完成,其代码也较为简单,这里也不再详细分析。需要的是注意如何根据arKey或h来计算出相应的下标,以及两个双向链表的指针的处理。
5 遍历元素
/* This is used to recurse elements and selectively delete certain entries |
因为HashTable中所有Bucket都可以通过pListHead指向的双向链表来访问,因此遍历HashTable的实现也比较简单。这里值得一 提的是对当前遍历到的Bucket的处理使用了一个apply_func_t类型的回调函数。根据实际需要,该回调函数返回下面值之一:
ZEND_HASH_APPLY_KEEP
ZEND_HASH_APPLY_STOP
ZEND_HASH_APPLY_REMOVE
它们分别表示继续遍历,停止遍历或删除相应元素后继续遍历。
还有一个要注意的问题就是遍历时的防止递归的问题,也就是防止对同一个HashTable同时进行多次遍历。这是用下面两个宏来实现的:
HASH_PROTECT_RECURSION(ht)
HASH_UNPROTECT_RECURSION(ht)
其主要原理是如果遍历保护标志bApplyProtection为真,则每次进入遍历函数时将nApplyCount值加1,退出遍历函数时将nApplyCount值减1。开始遍历之前如果发现nApplyCount > 3就直接报告错误信息并退出遍历。
上面的apply_func_t不带参数。HashTable还提供带一个参数或可变参数的回调方式,对应的遍历函数分别为:
typedef int (*apply_func_arg_t)(void *pDest,void *argument TSRMLS_DC); |
除了上面提供的几种提供外,还有许多其它操作HashTable的API。如排序、HashTable的拷贝与合并等等。
PHP数据核心:Zend HashTable详解的更多相关文章
- PHP源代码分析(第一章):Zend HashTable详解【转】
转载于http://www.phppan.com/2009/12/zend-hashtable/ 在PHP的Zend引擎中,有一个数据结构非常重要,它无处不在,是PHP数据存储的核心,各种常量.变量. ...
- 云计算:Linux运维核心管理命令详解
云计算:Linux运维核心管理命令详解 想做好运维工作,人先要学会勤快: 居安而思危,勤记而补拙,方可不断提高: 别人资料不论你用着再如何爽那也是别人的: 自己总结东西是你自身特有的一种思想与理念的展 ...
- Code First开发系列之管理数据库创建,填充种子数据以及LINQ操作详解
返回<8天掌握EF的Code First开发>总目录 本篇目录 管理数据库创建 管理数据库连接 管理数据库初始化 填充种子数据 LINQ to Entities详解 什么是LINQ to ...
- 8天掌握EF的Code First开发系列之3 管理数据库创建,填充种子数据以及LINQ操作详解
本文出自8天掌握EF的Code First开发系列,经过自己的实践整理出来. 本篇目录 管理数据库创建 管理数据库连接 管理数据库初始化 填充种子数据 LINQ to Entities详解 什么是LI ...
- iOS:核心动画的详解介绍:CAAnimation(抽象类)及其子类
核心动画的详解介绍:CAAnimation(抽象类) 1.核心动画基本概念 Core Animation是一组非常强大的动画处理API,使用它能做出非常炫丽的动画效果,而且往往是事半功倍! 使用它 ...
- <转>ASP.NET学习笔记之MVC 3 数据验证 Model Validation 详解
MVC 3 数据验证 Model Validation 详解 再附加一些比较好的验证详解:(以下均为引用) 1.asp.net mvc3 的数据验证(一) - zhangkai2237 - 博客园 ...
- [转帖]IP /TCP协议及握手过程和数据包格式中级详解
IP /TCP协议及握手过程和数据包格式中级详解 https://www.toutiao.com/a6665292902458982926/ 写的挺好的 其实 一直没闹明白 网络好 广播地址 还有 网 ...
- 转:WCF传送二进制流数据基本实现步骤详解
来自:http://developer.51cto.com/art/201002/185444.htm WCF传送二进制流数据基本实现步骤详解 2010-02-26 16:10 佚名 CSDN W ...
- Oracle10g数据泵impdp参数详解--摘自网络
Oracle10g数据泵impdp参数详解 2011-6-30 12:29:05 导入命令Impdp • ATTACH 连接到现有作业, 例如 ATTACH [=作业名]. • C ...
随机推荐
- Winform跨窗体操作控件(使用委托)
Winform跨窗体操作控件是winform开发中很常见的形式,最常见且简单有效的方式便是使用委托的方式来进行操作,下面我将通过一个小实例来说明如何使用委托跨窗体实现控件操作. 实例介绍:两个窗体,F ...
- IE常见bug及其修复方法
一.双边距浮动的bug 1.1一段无错的代码把一个居左浮动(float:left)的元素放置进一个容器盒(box) 2.1在浮动元素上使用了左边界(margin-left)来令它和容器的左边产 ...
- [转载]MySQL运行状态show status详解
要查看MySQL运行状态,要优化MySQL运行效率都少不了要运行show status查看各种状态,下面是参考官方文档及网上资料整理出来的中文详细解释,不管你是初学mysql还是你是mysql专业级的 ...
- HashSet源码阅读
HashSet的实现基于HashMap 看几个简单的初始化方法 public HashSet() { map = new HashMap<>(); } public HashSet(Col ...
- 将linux下的office从libreoffice换成wps
1.下载wps的linux的deb版本 2.运行dpkg -i wpsXXX.deb 3.提示权限不够 4.运行 sudo dpkg -i wpsXXX.deb 5.提示错误 未安装软件包 libpn ...
- 迭代器中next()的用法
>>> g = (x ** 2 for x in range(10)) >>> next(g) 0 >>> next(g) 1 >>& ...
- jsp+servlet登录框架模板
一.建立一个名叫jsp_servlet的工程 二.建立一个AcountBean类和CheckAccount类 1.AcountBean类包含登录名(username)和登录密码(password) p ...
- Flask-SQLAlchemy
Flask-SQLAlchemy SQLAlchemy 一. 介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言 ...
- JVM GC知识回顾
这两天刚好有朋友问到我面试中GC相关问题应该怎么答,作为java面试中热门问题,其实没有什么标准回答.这篇文章结合自己之前的总结,对GC做一个回顾. 1.分代收集 当前主流VM垃圾收集都采用" ...
- 学习笔记 - 兼容ie的透明度问题
.opacity{font-size: 14px;-khtml-opacity:0.6;-moz-opacity:0.6;filter:alpha(opacity=60);filter:"a ...