学而精计算机公共基础学习之路TEST1
算法
一:算法基本概念
算法是个什么概念学了这么久的程序尽然没有听说过,其实算法就是为了解决问题那么怎么准确完整的解决这个问题就是算法。所以我们所写的程序就可以说为对算法的描述,但是程序编制是不能有于算法的因为程序往往还要考虑到计算机运行的环境限制问题。
算法的特性:
1、可行性(Effectiveness)
a、算法中的每一个步骤都必须实现。注意:不允许出现分母为0的操作、实数范围内不能求负数的平方根
b、算法的执行结果要达到预期的目的
2、确定性(Definiteness)
3、有穷性(Finiteness)
4、拥有足够的情报
二:算法设计基本方法
1、举例法
2、归纳法
3、递推
4、递归
5、减半递推技术
6、回溯
三:算法的复杂度
1、算法的时间复杂度。
算法的时间复杂度是指,执行算法所需要的计算工作量。
算法的计算工作量用算法所执行的基本运算次数来度量,而算法所执行的基本运算次数是问题规模的函数,即:
算法的工作量=f(n)(其中n是问题规模)
例如,两个N×N矩阵相乘所需要的基本预算次数为n3,即计算量为n3,也就是时间复杂度为n3。
另外,在同一问题规模下,若算法执行所需的基本运算次数取决于某一特定输入数据时,我们可以用平均性态分析和最坏情况分析两种方法来分析算法的工作量。
顾名思义,平均性态分析即输入所有可能的平均值,相应的时间复杂度为算法的平均时间复杂度;最坏情况分析法则是以最坏的情况估算算法执行时间的一个上界。一般情况下,后者更为常用。
2、算法的空间复杂度。
算法的空间复杂度是指,执行此算法期间所需要占用的内存空间,包括3部分:算法程序所占的空间、输入的初始数据所占的存储空间以及算法执行过程中所需要的额外空间。
实际应用中,为了减少算法所占用的存储空间,通常采用压缩存储技术,用于减少不必要的额外空间。
数据结构的基本概念
计算机随着时代发展已近进入一个大数据时代生活中无处不在计算机改变这我们的生活,就拿移动支付来说,没有支付宝和微信去校门口卖一个烧红薯都没有办法买到。没有手机出门什么事情都不办成,但是我们曾想过我们这么多人使用记录我们操作的数据究竟在哪里、是否安全,OK,那我们就来一起研究吧。
1.什么是数据结构
数据结构是指反映数据元素之间关系的数据元素的集合。而数据元素具有广泛含义,一般来说,现实世界中客观存在的一切个体都可以是数据元素。它可以是一个数字或一个字符,也可以是一个具体的事物,或者其他更复杂的信息。数据结构作为数据元素的集合,它包括逻辑结构和存储结构两种。
(1)数据的逻辑结构。
反映数据元素之间逻辑关系(即前后件关系)的逻辑结构。它包括数据元素的信息和数据元素之间的前后关系两个要素。
(2)数据的存储结构。
别名:数据的物理结构,是指数据的逻辑结构在计算机存储空间中的存放方式。
计算机存储数据=数据的信息+数据间的前后件的信息。
数据结构的存储方式包括:顺序存储、链式存储、索引存储、散列存储
2.数据结构的图形表示
前后件关系是数据元素之间最基本的关系。前后关系中,每一个二元组,都可以用图形来表示。我们用中间标有元素值的方框来表示数据元素,此方框一般称为数据结点,简称结点。对于每一个二元组,需要一条有向线段从前件指向后件。
例如,一年四季的数据结构可以用如图所示的图形来表示。
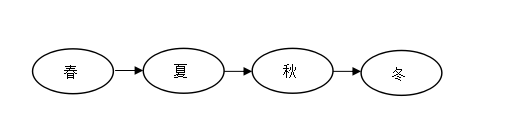
图:一年四季的数据结构的图形表示
又如数据结构的知识体系可以用如图所示的图形来表示。
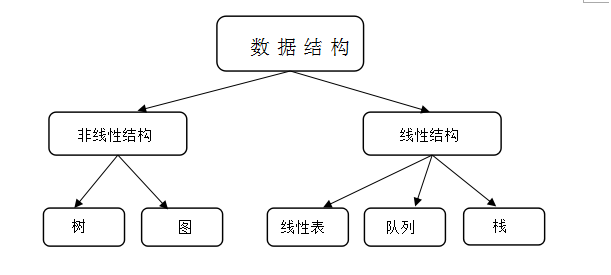
图:数据结构的知识体系的图形表示
用图形表示数据结构直观易懂,在没有歧义的情况下,前件结点到后件结点连线上的箭头也可以省去。
3.线性结构与非线性结构
根据数据结构中各数据元素之间前后关系的复杂程度,一般可将数据结构分为两大类型:线性结构和非线性结构。若一非空的数据结构有且只有一个根结点,并且每个结点最多有一个直接前驱和一个直接后继,则称该数据结构为线性结构,也称线性表。
不满足上述条件的数据结构则称为非线性结构。
由上我们可以判断,图13.1为线性结构,图13.2为非线性结构。
对于空的数据结构,既可能是线性结构的,也可能是非线性结构,这要根据对该数据结构的运行规则来定。
13.1.3 线性表及其顺序存储结构
1.线性表的基本概念
在数据结构中,线性表是最简单也是最常用的一种数据结构。
线性表是由n个(n≥0)数据结构元素x1,x2,x3,…,xn组成的一个有限序列。除了表中的第一个元素外,有且只有一个直接前驱;除了最后一个元素外,有且只有一个直接后继。将线性表示为(x1,x2,x3,…,xn),其中xi=(1,2,…,n)是线性表的数据元素,也称为线性表的一个结点。线性表中的数据元素必须具有相同的属性,即属于同种数据对象。
例如:
◎字母表(A,B,C,…,Z)就是一个长度为26的线性表,其中每个字母就是一个数据元素,如图13.3所示;
◎四季(春,夏,秋,冬)是一个长度为4的线性表,其中的每一个季节是一个数据元素;
◎矩阵可以看做一个比较复杂的线性表,在矩阵中,既可以把每一行看成一个数据元素,也可以把每一列看成一个数据元素。其中每一个数据元素(一个行向量或者列向量)实际上又是一个简单的线性表。
|
A |
B |
C |
… |
Z |
图13.3 字母表的线性表表示
2.线性表的顺序存储结构
将线性表中的元素在计算机中一段相邻的存储区域中连续存储,称为线性表的顺序存储。线性表的顺序存储结构具有以下两个基本特点:
◎所有元素所占的存储空间必须是连续的;
◎所有元素在存储空间的位置是按逻辑顺序存放的。
由其基本特点我们可以看到,线性表中元素之间逻辑上的相邻关系即元素在计算机内物理位置上的相邻关系。所以只要确定了首地址,线性表内所有元素的地址都可以方便地查找出来。对线性表的处理主要有插入、删除、查找、排序、分解、合并、复制、逆转等。
3.线性表的插入运算
在对线性表进行插入操作时,若在第i(1≤i≤n+1)个元素之前插入一个新元素,则完成插入操作需以下3个步骤:原来第n个结点至第i结点依次往后移一个位置;把新结点放在第i个位置上;线性表的结点数加1,如图13.4所示。
|
3 |
5 |
2 |
6 |
7 |
… |
… |
… |
… |
↑插入4
(a)插入前线性表n=5
|
3 |
5 |
2 |
4 |
6 |
7 |
… |
… |
… |
(b)插入元素4后线性表n=6
图13.4 线性表的顺序存储结构插入前后的状况
当在线性表尾进行插入运算时,则只需在表的末尾增加一个元素即可,不需要移动线性表中的元素。当在线性表头位置插入新的元素时,则需要移动表中的所有元素。
一般的,线性表会事先开辟出一个大于线性表长度的空间,但当多次插入运算后,可能出现在存储空间已满的情况下仍继续进行插入运算,此时将会产生错误,此类错误称为“上溢”。
4.线性表的删除运算
在对线性表进行删除操作时,若要删除第i个元素,需要进行以下步骤:把第i元素之后(不包括第i个元素)的n-i个元素依次前移一个位置;线性表的节点数减1.如图13.5所示。
|
3 |
5 |
2 |
6 |
7 |
… |
… |
… |
… |
↑插入6
(a)插入前线性表n=5
|
3 |
5 |
2 |
7 |
… |
… |
… |
… |
… |
(b)插入元素6后线性表n=4
图13.5 线性表的顺序存储结构删除前后的状况
当删除运算在线性表尾进行时,即删除第n个元素,不需要移动线性表中的元素。当要删除第1个元素时,则需要移动表中除第1个元素外所有的元素。
13.1.4 栈和队列
1.栈及其基本运算
(1)栈的基本概念。
栈,实际上也是一种线性表,只不过是一种特殊的线性表。其特殊性体现在,它的插入和删除运算都只在线性表的一端进行,而另一端是封闭的,不进行任何操作。在栈中,允许进行插入和删除操作的一端称为栈顶,另一端则称为栈底。当栈中没有元素时称为空栈。
由于其操作的特殊性,栈也被称为“先进后出”表或“后进先出”表。
(2)栈的特点。
由栈的定义,我们容易得到栈具有以下的特点:
◎栈底元素总是最早被插入的元素,同时也是最晚被删除的元素;
◎栈顶元素总是最后被插入的元素,同时也是最早被删除的元素;
◎栈具有记忆作用;
◎顺序栈的插入和删除运算都不需要移动表中其他的数据元素;
◎栈顶指针动态地反映了栈中元素的变化情况。
(3)栈的顺序存储及其运算。
栈的基本运算有3种:
入栈运算:即栈的插入,在栈顶位置插入一个新数据。
退栈运算:即栈的删除,就是取出栈顶元素赋予指定变量。
读栈顶元素:即将栈顶元素(即栈顶指针top指向的元素)的值赋给某个变量。
如图13.6所示是一个顺序表示的栈的动态示意图。随着数据的插入和删除,栈顶指针top显示了栈的状态变化。
↑top
(a)栈空状态
|
1 |
↑top
(b)插入数据1后的栈状态
|
1 |
2 |
3 |
4 |
5 |
↑top
(c)插入数据2,3,4,5后的栈状态
|
1 |
2 |
3 |
↑top
(d)删除数据4,5后的栈状态
图13.6 栈的动态示意图
2.队列及其基本运算
(1)队列的基本概念。
队列是同栈不太相同的线性结构,它是允许在一端进行插入,而在另一端进行删除的线性表。允许插入的一端称为队尾,通常用一个称为尾指针(rear)的指针指向队尾元素;允许删除的一端称为队头,通常用一个称为头指针(front)的指针指向头元素的前一个位置。
队列又称为“先进先出”的线性表。
队列的基本结构如图13.7所示。
|
1 |
2 |
3 |
4 |
←退队
←入队
图13.7 队列的基本结构
(2)循环队列及其运算。
循环队列,顾名思义,就是将队列存储空间的最后一个位置绕到第一个位置,形成逻辑上的环状空间,线性结构可供队列循环使用。
在循环队列中,用尾指针(rear)指向队列的尾元素,用头指针(front)指向头元素的前一个位置。所以,我们可以知道从头指针(front)所指向的后一个位置直到尾指针(rear)指向的位置之间所有的元素均为队列中的元素。当rear=front时,循环队列的状态有两种:可能是队列满,也可能是队列空。为了区分这两种情况,我们通常增加一个标志量S,S值的定义如下:
◎S=0,表示循环队列为空;
◎S=1,表示循环队列非空。
由此判断队列空和队列满这两种情况:
当S=0时,循环队列为空;
当S=1时,且front=rear时,循环队列满。
循环队列中计算所有元素总数的方式为:(rear-front+线性表总长)%线性表总长。
循环队列的基本运算主要有两种:
① 入队运算
入队运算是指在循环队列的队尾加入一个新元素。首先队尾指针进1(即rear=rear+1),然后在rear指针指向的位置,插入新元素。当S=1时,且front=rear时,循环队列满。此时进行入队运算,会发生“上溢” 错误。
②退队运算
退队运算是指在循环队列的排头位置退出一个元素,并赋给指定的变量。首先头指针进1(即front=front+1),然后删除front指针指向的位置上的元素。当S=0时,循环队列为空,此时进行退队运算,会发生“下溢”错误。
13.1.5 线性链表
前面主要介绍了线性表的顺序存储结构及其基本运算。线性表顺序存储结构的特点是简单、运算方便,对于小线性表或长度固定的线性表,采用顺序存储结构的优越性显而易见。但是线性表的顺序存储结构在数据量大、运算量大的时候就显得很不方便,运算效率也较低。此时,我们就要用到链式存储方式。
前面在介绍一般的线性表以及栈和队列时,主要介绍了相应的顺序存储,下面我们将讲解线性表的链式存储。
1.线性链表的基本概念
线性表的链式存储结构称为线性链表,该结构的特点是用一组不连续的存储单元存储线性表中的各个元素。
为了存储线性表中的每一个元素,一方面要存储数据元素的值,另一方面要存储各数据元素之间的前后关系。因此,在链式存储方式中,每个节点有两部分组成:一部分称为数据域,用于存放数据元素的值;另一部分称为指针域,用于存放与之相关数据元素的地址。链式存储结构既可以表示线性结构,也可以表示非线性结构。
线性链表,就是指线性表的链式存储结构,简称链表。由于在这种链表中,每个结点只有一个指针域,故又称为单链表。
例如,如图13.8所示为线性表(A,B,C,D,E,F)的线性链表存储结构。头指针HEAD中存放的是第一个元素A的存储地址(即存储序号)。
D(i) NEXT(i)
|
(1)C |
7 |
|
… |
… |
|
(3)B |
1 |
|
… |
… |
|
(7)D |
19 |
|
… |
… |
|
(10)A |
3 |
|
(11)F |
null |
|
… |
… |
|
(19)E |
11 |
|
… |
… |
图13.8 线性链表示例
图13.8中“…”的存储单元可能存有数据,也可能是null。也就是说,线性链表的存储单元是任意的,即各数据结点的存储序号可以是连续的,也可以是不连续的,而各结点在存储空间中的位置关系与逻辑关系也不一致,前后关系由存储结点的指针来表示。指向第一个数据元素的头指针HEAD=NULL或者0时,称为空表。
栈和队列也可以采用链式存储结构表示,将其组织成一个单链表。这种数据结构称为带链的栈和带链的队列。栈和队列中的元素对应链表中的一个结点。
顺序表和链表的优缺点比较见表13.2。
表13.2 顺序表和链表的优缺点比较
|
类型 |
优点 |
缺点 |
|
顺序表 |
随机存取表中的任意结点; 无须额外表示结点间的逻辑关系 |
插入和删除运算效率很低; 存储空间不便于扩充; 不能动态分配存储空间 |
|
链表 |
在进行插入和删除运算时,不需要移动元素而只需要改变指针; 链表的存储空间易于扩充并且可以动态分配 |
需要指针域来表示数据元素之间的逻辑关系; 存储密度比顺序表要低 |
2.线性链表的基本运算
对线性链表进行的运算主要包括查找、插入、删除、合并、分解、逆转、复制和排序。其中线性链表的查找、插入和删除运算是学习的重点。
(1)在线性链表中查找指定元素。
在链表中查找指定元素必须从队头指针出发,沿着指针域中的Next指针逐个结点搜索,直到找到指定元素或链表尾部为止,这不同于顺序表,可以通过首地址计算出任意元素的存储地址。因此,线性链表不是随机存储结构。
在链表中,扫描到等于指定元素值的结点时,返回该节点的位置,如果链表中没有元素的值等于指定元素,则扫描完所有元素后,返回空。
(2)线性链表的插入。
线性链表的插入是指在链式存储结构下的线性表中插入一个新元素。
要在线性链表中数据域为M的结点之后插入一个新元素N,首先要给N分配一个新的结点P,然后在线性链表中查找数据域为M的结点,将其指针域内容存放在变量Q中,然后将M的指针域指向P,P的指针域修改为变量Q。
(3)线性链表的删除。
线性链表的删除是指在链式存储结构下的线性表中删除包含指定元素的结点。
在线性链表中删除数据域为M的结点,首先在线性链表中寻找包含M元素的前一个结点,然后把它的指针域修改为M的指针域,最后把结点M释放。
3.循环链表及其基本运算
(1)循环链表的定义。
在单链表的第一个结点前增加一个表头结点,队头指针指向表头结点,将最后一个结点的指针域的值由null改为指向表头结点,这样的链表称为循环链表。循环链表中,所有结点的指针构成了一个环状链。
(2)循环链表与单链表的比较。
单链表的访问方法是顺序访问,即从其中的某一结点出发,可以访问它的直接后继而无法访问它的直接前驱。而且空表与非空表的操作也不一样,对于空表和非空表的第一结点的处理都必须单独考虑。
而在循环链表中,只要得到表中任一结点的位置,就可以从它出发访问到全表所有的结点,且由于表头结点是循环链表所固有的结点,因此即使在表中没有数据元素的情况下,表中也至少会有一个结点存在,从而使空表和非空表的运算得到统一。
13.1.6 树和二叉树
1.树的基本概念
树是一种简单的非线性结构,它是以分支关系定义的层次结构。它和自然界的树结构形式很类似,所以我们称之为树。树结构在客观世界中是大量存在的。
例如,物种分类(门、纲、目、科、属、种等)、组织机构(处、科、室等)、行政区(国家、省、市、区),这些具有层次关系的数据,都可以用树这种结构来描述。
在用图形表示数据结构中元素之间的前后关系时,一般使用有向箭头,如上文中图13.1和13.2所示,但在树形结构中,一般去掉箭头也不会引起歧义,常常使用无向线段代表数据元素之间的逻辑关系。
下面结合图13.9介绍树的相关术语。
图13.9 树结构
◎父结点:在树结构中,每一个结点只有一个前件,称为父结点,没有前件的结点只有一个,称为树的根结点,简称树的根。在图13.9中,结点A是数的根结点。
◎子结点和叶子结点:在树结构中,每一个结点可以有多个后件,称为该结点的子结点。没有后件的结点称为叶子结点。在图13.9中,结点D,H,I,F,G均为叶子结点。
◎度:在树结构中,一个节点所拥有的后件个数称为该结点的度,所有结点中最大的度称为树的度。在图13.9中,根结点A和结点E的度为2,结点B的度为3,结点C的度为1,叶子结点D、H、I、F、G的度为0。所以,该数的度为3。
◎深度:定义一棵树的根结点所在的层次为1,其他结点所在的层次等于它的父结点所在的层次加1。树的最大层次称为树的深度。在图13.9中,根结点A在第1层,结点B、C在第2层,结点D、E、F、G在第3层,结点H、I在第4层。该树的深度为4。
◎子树:在书中,以某结点的一个子结点为根构成的树称为该结点的一棵子树。在图13.9中,结点A有两棵子树,他们分别以B、C为根结点。结点B有3棵子树,它们分别以D、E、F为根结点,其中,以D、F为根结点的子树实际上只有根结点一个结点。树的叶子结点度为0,所以没有子树。
2.二叉树及其基本性质
(1)二叉树的定义。
二叉树是一个有限的结点集合,该集合或者为空,或者由一个根结点及其两棵互不相交的左、右二叉子树组成。
二叉树具有以下特点:
◎二叉树可以为空,空的二叉树没有结点,非空二叉树有且只有一个根结点;
◎每一个结点最多有两颗子树,切分别成为该结点的左子树与右子树;
◎二叉树的子树有左、右之分,其次序不能任意颠倒。
(2)满二叉树和完全二叉树。
满二叉树指除最后一层外,每一层上的所有结点都有两个子结点的二叉树。
完全二叉树指除最后一层外,每一层上的结点数均达到最大值,在最后一层上只缺少右边的若干结点。
满二叉树与完全二叉树的关系:满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
(3)二叉树的主要性质。
◎一颗非空二叉树的第k层上最多有2k-1个结点(k≥1);
◎深度为m的满二叉树中有2m-1个结点;
◎对任何一颗二叉树而言,度为0的结点(即叶子的结点)总是比度为2的结点多一个;
◎具有n个结点的二叉树的深度k至少为[log2n]+1,其中[log2n]表示取log2n的整数部分。
◎具有n个结点的完全二叉树的深度为[log2n]+1;
◎设完全二叉树共有n个结点。如果从根结点开始,按层序(每一层从左到右)用自数1,2,…,n给结点进行编号,则对于编号为k(k=1,2…n)的结论:
若k=1,则该结点为根结点,它没有父结点;若k>1,则该结点的父结点编号为INT(k/2);
若2k≤n,则编号为k的结点的左子结点编号为2k;否则该结点无子结点(显然也没有右子结点);
若2k+1≤n,则编号为k的结点的右子结点编号为2k+1;否则该结点无右子结点。
3.二叉树的存储结构
在计算机中,二叉树通常采用链式存储结构。用于存储二叉树中各元素的存储结点由数据域和指针域组成。由于每个元素可以有两个后件(即两个子结点),所以用于存储二叉树的存储结点的指针域有两个:一个指向该结点的左子结点的存储地址,称为左指针域;另一个指向该结点的右子结点的存储地址,称为右指针域。因此,二叉树的链式存储结构也称为二叉链表。二叉树的一个存储结点如图13.10所示。
左指针域 数据域 右指针域
|
L(i) |
Data(i) |
R(i) |
图13.10 二叉树的一个存储结点
对于满二叉树与完全二叉树可以按层次进行顺序存储。
4.二叉树的遍历
二叉树的遍历是指不重复地访问二叉树中的所有结点。
二叉树的遍历有前序遍历中序遍历和后序遍历。
◎前序遍历(DLR)首先访问根结点,然后遍历左子树,最后遍历右子树。
◎中序遍历(LDR)首先遍历左子树,然后访问根结点,最后遍历右子树。
◎后序遍历(LRD)首先遍历左子树,然后遍历右子树,最后访问根结点。
例如,对图13.11中的二叉树进行前序遍历的结果(或称为该二叉树的前序序列)为:A、B、D、H、E、I、C、F、G;进行中序遍历的结果(或称为该二叉树的中序序列)为:H、D、B、E、I、A、C、G、F;进行后序遍历的结果(或称为该二叉树的后序序列)为:H、D、I、E、B、G、F、C、A。
图13.11 一颗二叉树
若已知一颗二叉树的前序遍历和中序遍历序列,可以唯一确定这棵二叉树。已知一颗二叉树的后序遍历序列和中序遍历序列,也可以唯一确定这棵二叉树。已知一颗二叉树的前序遍历序列和后序遍历序列,则不能唯一确定这棵二叉树。
13.1.7 查找技术
查找,即在某种数据结构中,找出满足指定条件的元素。
查找是插入和删除等运算的基础,是数据处理的重要内容。对于不同的数据结构,应选用不同的查找算法,以获得更高的查找效率。在众多查找算法中,顺序查找和二分法查找的应用最为广泛。
1.顺序查找
顺序查找是一种最简单的查找方法。它的基本思想是:从线性表的第一个元素开始,将目标元素与线性表中的元素逐个进行比较,如果相等,则查找成功,返回结果;若整个线性表扫描完毕后,未找到与被查元素相等的元素,则表示线性表中没有要查找的元素,则查找失败。
例如,在一维数组[2,4,2,9,5,7,8]中,查找数据元素9,首先从第1个元素2开始进行比较,于要查找的数据不相等,接着与第2个元素4进行比较,依此类推,当进行到与第4个元素比较时,它们相等,所以查找成功。如果查找数据元素1,则整个线性表扫描完毕,仍未找到与1相等的元素,表示线性表中没有要查找的元素,查找不成功。
在最好的情况下,第一个元素就是目标元素,则查找次数为1次。
在最坏的情况下,最后一个元素是目标元素,顺序查找需要比较n次。
在平均情况下,需要比较n/2次。因此查找算法的时间复杂度为O(n)。
顺序查找法虽然效率很低,但在以下两种情况中,它是查找运算唯一的选择。
◎若线性表中元素是无序排列,则无论是顺序存储结构还是链式存储结构,都只能进行顺序查找;
◎即便是有序线性表,若采用链式存储结构,也只能进行顺序查找。
2.二分法查找
二分法查找也称折半查找,是一种较为高效的查找方法。
使用二分法查找的线性表,必须满足用顺序存储结构,且线性表是有序表两个条件。
为了简化问题的阐述,有序表在本书中特指线性表中的元素按值非递减排列(即从小到大,但允许相邻元素值相等)。
对于长度为n的有序线性表,利用二分法查找元素X的过程如下。
◎将X与线性表的中间项比较。
◎如果X的值与中间项的值相等,则查找成功,结束查找;
◎如果X小于中间项的值,则在线性表的前半部分以二分法继续查找;
◎如果X大于中间项的值,则在线性表的后半部分以二分法继续查找。
举个例子,长度为8的线性表的关键码序列为:[4,11,24,29,37,45,46,77],被查找元素为37,首先将与线性表的中间项比较,即与第4个数据元素29相比较,37大于中间项29,则在线性表[37,45,46,77]继续查找;接着与中间项比较,即与第2个元素45相比较,37小于45,则在线性表[37]继续查找,最后一次比较相等,查找成功。
我们容易得到,相较于顺序查找法每一次比较,查找范围减少1,而二分法查找每比较一次,查找范围则减少为原来的一半,效率大为提高。
容易证明得到,在最坏的情况下,对于长度为n的有序线性表,二分法查找只需比较log2n次,而顺序查找需要比较n次。
13.1.8 排序技术
排序,是指将一个无序序列整理成按值非递减顺序排列的有序序列的过程。排序的方法有很多,对于不同待排序序列的规模以及对数据处理的要求,应当采用不同的排序方法。我们在这里主要介绍一些常用的排序方法。
1.交换类排序法
交换类排序法,指借助数据元素的“交换”来进行排序的一种方法。主要包括冒泡排序法和快速排序法。
(1)冒泡排序法。
冒泡排序法是最简单的一种交换类排序方法。在数据元素的序列中,对于某个元素,如果其后存在一个元素小于它,则称之为存在一个逆序。冒泡排序的基本思想就是通过两两相邻数据元素之间的比较和交换,不断地消去逆序,直到所有数据元素有序为止。
冒泡排序法的基本过程如下:
◎从表头开始往后查找线性表,在查找过程中逐次比较相邻两元素的大小,若在相邻两元素中,前面的元素大于后面的元素,则将其交换,这样最后元素便为线性表的最大值;
◎从后往前查找剩下的线性表,在查找过程中逐次比较相邻两个元素的大小,若在相邻两元素中,后面的元素小于前面的元素,则将其交换;
◎对剩下的线性表重复上述过程,知道剩下的线性表变空为止,表示线性表排序完成。
最坏的情况下,当线性表的长度为n时,冒泡排序经过n/2遍的从前往后的扫描和n/2遍的从后往前扫描,需要比较n(n-1)/2次,其数量级为n2。
下面我们来看一个例子如图13.12所示,对(4,1,6,5,2,3)这样一个6个元素组成的线性表排序。图中每一遍结果中方括号“[ ]”外的元素是已经排好序的元素,方括号“[ ]”内的元素是还未排好序的元素。
原始序列:4←→1 6←→5←→2←→3
第一遍(从前往后):[1 4←→5←→2 3] 6
(从后往前):1 [2 4 5←→3] 6
第二遍(从前往后):1 [2 4←→3] 5 6
(从后往前):1 2 [3 4] 5 6
最终结果:1 2 3 4 5 6
图13.12 冒泡排序示例
第一遍的从前往后扫描:首先比较“4”和“1”,前面的元素大于后面的元素,这是一个逆序,两者交换。交换后接下来是“4”和“6”比较,不交换。然后“6”与“5”比较,这是一个逆序,交换。“6”再与“2”比较,交换。“6”再与“3”比较,交换。这时,整个线性表的最大元素“6”已经到达表的尾部。
第一遍的从前往后扫描的最后结果为(1,4,5,2,3,6)。
第一遍的从后往前扫描:由于数据元素“6”已经排好序,因此,现在的排序法的范围为(1,4,5,2,3)。先比较“3”和“2”,不交换。比较“2”和“5”,后面的元素小于前面的元素,这是一个逆序,交换。比较“2”和“4”,这是一个逆序,交换。比较“2”和“1”,不交换。此时,排序范围内(1,4,5,2,3)的最小元素“1”已经到达表头,它已经到达了它在有序表中应有的位置。第一遍的从后往前扫描的最后结果为(1,2,4,5,3,6)。
第二遍的排序方法同上,不再赘述。
(2)快速排序法。
快速排序法是冒泡排序法的一种改进。其基本思路如下:在线性表中逐个选取元素,对表进行分割,直到所有元素全部选取完毕,此时线性表及排序结束。
快速排序的具体做法是:设两个指针low和high,它们的初值分别指向线性表的第一个元素(K元素)和最后一个元素。首先从high所指向的位置向前扫描,找到第一个小于K元素的元素并与K元素互相交换。然后从low所指位置起向后扫描,找到第一个大于K元素的数据并与K元素交换。重复这两个步骤,直到low=high为止。这时,线性表已经是排好序的了。
快速排列的平均时间效率最高为0(nlog2n),最坏情况下,也就是每次划分,都只得到一个子序列,此时时间效率为O(n2)。
2.插入类排序法
插入排序是指将无序数列中的各元素依次插入到有序的线性表中。这里我们主要介绍下简单插入排序法和希尔排序法。
(1) 简单插入排序法。
简单插入是把n个待排序的元素看成一个有序表和一个无序表。开始时,有序表只包含一个元素,而无序表则包含剩余的n-1个元素,每次取无序表中的第一个元素插入到有序表中的正确的位置,使之成为增加一个元素的新的有序表。插入元素时,插入位置及其后的记录依次向后移动。最后当有序表的长度为n,无序表为空时,排序完成。
在简单插入排序中,每一次比较后最多移掉一个逆序,因此该排序方法的效率与冒泡排序法相同。在最坏的情况下,简单插入排序需要进行n(n-1)/2次比较。
简单插入排序过程如图13.13所示。图中方括号“[ ]”内为有序的子表,方括号“[ ]”外为无序的子表,每次从无序子表中取出第一个元素插入到有序子表中。
|
i=1(初始态) |
[48] 37 65 96 75 12 26 49 |
|
i=2 |
[37 48] 65 96 75 12 26 49 |
|
i=3 |
[37 48 65] 96 75 12 26 49 |
|
i=4 |
[37 48 65 96] 75 12 26 49 |
|
i=5 |
[37 48 65 75 96] 12 26 49 |
|
i=6 |
[12 37 48 65 75 96] 26 49 |
|
i=7 |
[12 26 37 48 65 75 96] 49 |
|
i=8 |
[12 26 37 48 49 65 75 96] |
图13.13 简单插入排序过程
初始状态时,有序表只包含一个元素48,而无序表包含另外其他7个元素;
当i=2时,即把第2个元素7插入到有序表中,37比48小,所以在有序表中的序列为[37 48 ];
当i=3时,即把第3个元素65插入到有序表中,65比前面2个元素大,所以在有序表中的序列为[37 48 65 ];
当i=4时,即把第4个元素96插入到有序表中,96比前面3个元素大,所以在有序表中的序列为[37 48 65 96 ];
当i=5时,即把第5个元素75插入到有序表中,75比前面3个元素大,比96小,所以在有序表中的序列为[37 48 65 75 96 ];
以此类推,直到当i=8时,所有的元素都插入到有序序列中,此时有序表中的序列为[12 26 37 48 49 65 75 96 ]。
初始排序序列就是有序的情况即最好情况下,简单插入排序的比较次数为n-1次,移动次数为0次;初始排序序列是逆序的情况即最坏情况下,比较次数为n(n-1)/2,移动次数为n(n-1)/2。
假设待排序的线性表中的各种排列出现的概率相同,可以证明,其平均比较次数和平均移动次数都约为n2/4,因此直接插入排序算法的时间复杂度为O(n2)。
(2) 希尔排序法。
希尔排序也是一种插入类排序,但希尔排序比简单插入排序更有效率。
希尔排序的基本思想是:将整个无序序列分割成若干个小的子序列并分别进行插入排序。其分割方法如下:将相隔某个增量h的元素构成一个子序列;在排序过程中,逐次减少这个增量,直到h减到1时进行一次插入排序,排序即可完成。
我们容易看出,希尔排序的效率与所选取的增量序列有关。
3.选择类排序法
(1)简单选择排序法
简单选择排序法的基本思想是:首先从所有n个待排序的数据元素中选择最小的元素,将该元素与第1个元素交换,再从剩下的n-1个元素中选出最小的元素与第2个元素交换。重复操作直到所有的元素有序。
对初始状态为(73,26,41,5,12,34)的序列进行简单选择排序过程如图13.14所示。图中方括号“[ ]”内为有序的子表,方括号“[ ]”外为无序的子表,每次从无序子表中取出最小的一个元素插入到有序子表的末尾。
|
i=1(初始态) |
73 26 41 5 12 34 |
|
i=2 |
[5] 73 26 41 12 34 |
|
i=3 |
[5 12] 73 26 41 34 |
|
i=4 |
[5 12 26] 73 41 34 |
|
i=5 |
[5 12 26 34 ]73 41 |
|
i=6 |
[5 12 26 34 41] 73 |
|
i=7 |
[5 12 26 34 41 73] |
图13.14 简单选择排序
步骤如下:
从这6个元素中选择最小的元素5,将5与第1个元素交换,得到有序序列[5];
从剩下的5个元素中挑出最小的元素12,将12与第2个元素交换,得到有序列[5 12];
从剩下的4个元素中挑出最小的元素26,将6与第3个元素交换,得到有序列[5 12 26];
以此类推,直到所有的元素都插入有序序列中,此时有序表中序列为[5 12 26 34 41 73];
简单选择排序法在最坏的情况下需要比较n(n-1)/2次。
(2)堆排序法
堆排序法属于选择类排序法。
所谓堆,即若有n个元素的序列,将元素按顺序组成一颗完全二叉树,所有结点的值大于或等于左右子结点的值,我们称之为大堆根,当所有结点的值小于或等于左右子结点的值时,称为小堆根,我们在这里只讨论大堆根的情况。
序列(91,85,53,36,47,30,24,12)是一个堆,则它对应的完全二叉树如图13.15所示。
图13.15 序列对应的完全二叉树
堆排序的方法如下:
①将一个无序序列建成堆。
②将堆顶元素与堆中最后一个元素交换。忽略已经交换到最后的元素,考虑前n-1个元素构成的子序列,只有左、右子树是堆,可以将该子树调整为堆。这样反复做第二步,直到未调整的子序列为空为止。
在最坏的情况下,堆排序需要比较的次数为O(nlog2n)。
假设图13.16(a)是某完全二叉树的一颗子树。在这棵子树中,根结点47的左、右子树均为堆,为了将整个子树调整成堆,首先将根结点47与其左、右子树的根结点进行比较,此时由于左子树根结点91大于右子树根结点53,且它又大于根结点47,因此根据堆的条件,应将元素47与91交换,如图13.16(b)所示。经过一次交换后,破坏了原来左子树的堆结构,需要对左子树再进行调整,将元素85与47进行交换,调整后的结果如图13.16(c)所示。
图13.16 堆顶元素为最大的堆
4.排序方法比较
我们共介绍了3类、共6种排序方法以及它们对应的时间和空间复杂度,现对其中5种做一个比较,见表13.3。
表13.3 常用排序方法时间、空间复杂度比较
|
方法 |
平均时间 |
最坏情况时间 |
|
冒泡排序 |
O(n2) |
O(n2) |
|
快速排序 |
O(nlog2n) |
O(n2) |
|
简单插入排序 |
O(n2) |
O(n2) |
|
简单选择排序 |
O(n2) |
O(n2) |
|
堆排序 |
O(nlog2n) |
O(nlog2n) |
表13.3中未包括的希尔排序,其时间效率与所取的增量序列有关,如果增量序列为:di=n/2,di+1=d/2(n为等待排序序列中的元素个数)。则在最坏情况下,希尔排序所需要的比较次数为O(n1.5)。
选取排序方法时需要考虑的因素有:待排序的序列长度n;数据元素本身的大小;关键字的分布情况;对排序的稳定性的要求;语言工具的条件;辅助空间的大小等。根据这些因素,我们可以得出以下几点结论:
◎n较小时,采用插入排序和选择排序。因为简单插入排序所需数据元素的移动操作比简单选择排序多,所以当数据元素本身信息量较大时,用简单选择排序方法较好。
◎如果文件的初始状态已基本有序,则最好选用简单插入排序或冒泡排序。
◎n较大时,应选择快速排序或者堆排序,其中快速选择排序是目前内部排序方法中性能最好的,当待排序的序列是随机分布时,快速排序的平均时间最少,但堆排序所需的辅助空间要少于快速排序,并且不会出现可能出现的最坏情况。
学而精计算机公共基础学习之路TEST1的更多相关文章
- 学而精计算机公共基础学习之路TEST2(程序设计基础)
程序设计基础 程序设计方法与风格 1.程序设计方法 程序设计: 指设计.编制.调试程序的方法和过程. 程序设计方法是研究问题求解如何进行系统构造的软件方法学.常用的程序设计方法有:结构化程序设计方法. ...
- “戏精少女”的pandas学习之路,你该这么学!No.5
如果文章图片无法观看,请前往CSDN博客观看 https://blog.csdn.net/hihell 戏精博主即将上线 就在上一篇,梦想橡皮擦这位博主经过艰苦的努力 终于能创建一个dataframe ...
- python 零基础学习之路 02-python入门
不知不觉学习python已经两个月了,从一开始不知道如何对print的格式化,到现在可以手撸orm,这期间真的是 一个神奇的过程.为了巩固自己的基础知识,为后面的拓展埋下更好的伏笔,此文当以导师的博客 ...
- 【jq】c#零基础学习之路(1)Hello World!
从今天起我会持续发表,这个就是一个日记型的,学习编程是枯燥的,况且我们还是零基础. 学前准备 1.编译环境 vs2010.vs2012.vs2015...(本人用的是vs2010旗舰版).vs2010 ...
- Android 零基础学习之路
第一阶段:Java面向对象编程 1.Java基本数据类型与表达式,分支循环. 2.String和StringBuffer的使用.正則表達式. 3.面向对象的抽象.封装,继承,多态.类与对象.对象初始化 ...
- python基础学习之路No.3 控制流if,while,for
在学习编程语言的过程中,有一个很重要的东西,它就是判断,也可以称为控制流. 一般有if.while.for三种 ⭐if语句 if语句可以有一个通俗的解释,如果.假如 如果条件1满足,则…… 如果条件2 ...
- JAVA基础学习之路(五)数组的定义及使用
什么是数组:就是一堆相同类型的数据放一堆(一组相关变量的集合) 定义语法: 1.声明并开辟数组 数据类型 数组名[] = new 数据类型[长度]: 2.分布完成 声明数组:数据类型 数组名 [] = ...
- JAVA基础学习之路(一)基本概念及运算符
JAVA基础概念: PATH: path属于操作系统的属性,是系统用来搜寻可执行文件的路径 CALSSPATH: java程序解释类文件时加载文件的路径 注释: 单行注释 // 多行注释 /*... ...
- 【jq】c#零基础学习之路(5)自己编写简单的Mylist<T>
public class MyList<T> where T : IComparable { private T[] array; private int count; public My ...
随机推荐
- ASP.NET Core 一步步搭建个人网站(4)_主页和登录验证
上章节我们已经定制好动态配置的菜单,用户登录网站的第一步就是进入首页内容,那我们先搭建一下我们的首页内容.想着自己的网站内容主要是个人博客类型,所以,首页就展示博主本人的一些基本信息吧,哈哈.当然,做 ...
- python科学计算_numpy_广播与下标
多维数组下标 多维数组的下标是用元组来实现每一个维度的,如果元组的长度比维度大则会出错,如果小,则默认元组后面补 : 表示全部访问: 如果一个下标不是元组,则先转换为元组,在转换过程中,列表和数组的转 ...
- tophat安装
1 依赖软件:bowtie,bowtie2,samtools,boost c++ library 2 建立索引文件: bowtie包括bowtie,bowtie-build, ...
- Ubuntu16.04安装配置sublime text3
1.安装Sublime Text 3 首先添加sublime text 3的仓库: sudo add-apt-repository ppa:webupd8team/sublime-text-3 根据提 ...
- python如何玩“跳一跳”!(windows安桌版本请进!)
最近"跳一跳",很火爆,有木有? 看了一下网上的教程,动作搭建了一下环境,就可以用脚本自动跑起来啦!!! 下面说一下android手机的实现过程: 首先,是python环境的搭建 ...
- 线上服务器上安装的VNCServer不能正常工作
1.问题描述: 线上服务器上安装的不能正常工作 2.解决问题过程: 一. 重启vncserver 运行命令:vncserver -kill :1和vncserver :1 二. 发现vncserver ...
- Python 的类的下划线命名有什么不同?
1. 以一个下划线开头的命名 ,如_getFile2. 以两个下划线开头的命名 ,如__filename3. 以两个下划线开头和结尾的命名,如 __init__()4. 其它 单下划线前缀的 ...
- 删除链表中间节点和a/b处的节点
[题目]: 给定链表的头节点 head,实现删除链表的中间节点的函数. 例如: 步删除任何节点: 1->2,删除节点1: 1->2->3,删除节点2: 1->2->3-& ...
- 如何使用 Q#
Q# 是微软的量子语言,很厉害,所以本文告诉大家如何入门,如何配置. 介绍 很多新的计数机技术都在很多年前就有人提出,量子计算就是其中一个.量子计算在 1980 年就被 Richard Feynman ...
- Kotlin——从无到有系列教程(5): 你该知道的Kotlin可空类型、空安全(null)、类型转换等特性
在我们熟知的Java中,定义一个变量可以默认不赋值,因为Java的系统会给我们默认赋一个默认值,并且Java可定义一个赋值为null的变量,这样在使用这个变量的时候都会去显示判断该变量是否为null. ...