[转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html
有时候我们在用,但是却不知道为什么。就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地球的万有引力。ok了,希望通过了解MapReduce,我们能够写出更好的MapReduce例子。
第一部分:MapReduce工作原理<ignore_js_op>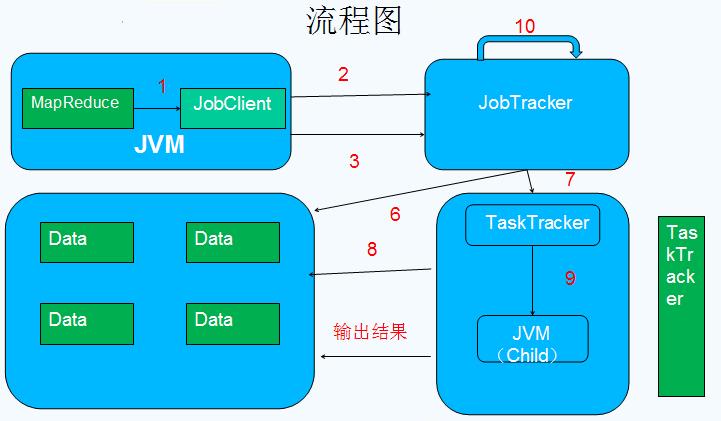
<ignore_js_op>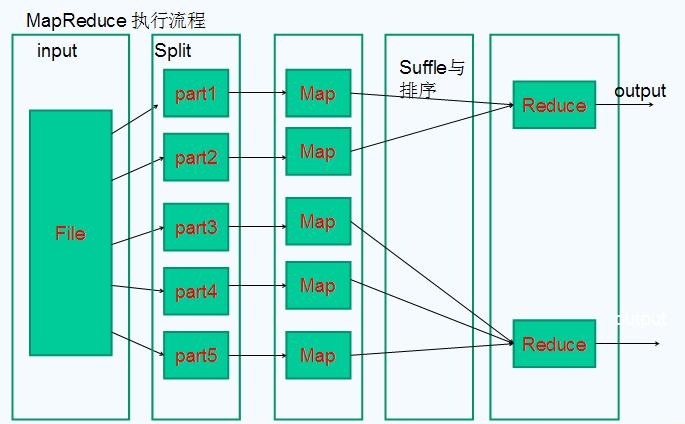
MapReduce 角色
•Client :作业提交发起者。
•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业。
•TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
提交作业
•在作业提交之前,需要对作业进行配置
•程序代码,主要是自己书写的MapReduce程序。
•输入输出路径
•其他配置,如输出压缩等。
•配置完成后,通过JobClinet来提交
作业的初始化
•客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
任务的分配
•TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
•TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
任务的执行
•申请到任务后,TaskTracker会做如下事情:
•拷贝代码到本地
•拷贝任务的信息到本地
•启动JVM运行任务
状态与任务的更新
•任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
•任务进度是通过计数器来实现的。
作业的完成
•JobTracker是在接受到最后一个任务运行完成后,才会将任务标志为成功。
•此时会做删除中间结果等善后处理工作。
第二部分:错误处理
任务失败
•MapReduce在设计之出,就假象任务会失败,所以做了很多工作,来保证容错。
•一种情况: 子任务失败
•另一种情况:子任务的JVM突然退出
•任务的挂起
TaskTracker失败
•TaskTracker崩溃后会停止向Jobtracker发送心跳信息。
•Jobtracker会将该TaskTracker从等待的任务池中移除。并将该TaskTracker上的任务,移动到其他地方去重新运行。
•TaskTracker可以被JobTracker放入到黑名单,即使它没有失败。
JobTracker失败
•单点故障,Hadoop新的0.23版本解决了这个问题。
第三部分:作业调度
FIFO
Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选 择被执行的作业
公平调度器
为任务分配资源的方法,其目的是随着时间的推移,让提交的作业获取等量的集 群共享资源,让用户公平地共享集群。具体做法是:当集群上只有一个任务在运行 时,它将使用整个集群,当有其他作业提交时,系统会将TaskTracker节点空间的时 间片分配给这些新的作业,并保证每个任务都得到大概等量的CPU时间。
容量调度器
支持多个队列,每个队列可配置一定的资源量,每个队列采用 FIFO 调度策略,为 了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交 的作业所 占资源量进行限定。调度时,首先按以下策略选择一个合适队列:计算每个队列中正在运行的任务数与其应该分得的计算资源之间的比值,选择一个该比值 最小的队 列;然后按以下策略选择该队列中一个作业:按照作业优先级和提交时间顺序选择 ,同时考虑用户资源量限制和内存限制。但是不可剥夺式
配置公平调度器
1.修改mapred-stie.xml 加入如下内容
<property>
<name>mapred.jobtracker.taskScheduler</name>
<value>org.apache.hadoop.mapred.FairScheduler</value>
</property>
<property>
<name>mapred.fairscheduler.allocation.file</name>
<value>/opt/hadoop/conf/allocations.xml</value>
</property>
<property>
<name>mapred.fairscheduler.poolnameproperty</name>
<value>pool.name</value>
</property>
2 . 在 Hadoop conf 下创建
allocations.xml
内容为
<?xml version="1.0"?>
<alloctions>
</alloctions>
样例:
<pool name="sample_pool">
<minMaps>5</minMaps>
<minReduces>5</minReduces>
<weight>2.0</weight>
</pool>
<user name="sample_user">
<maxRunningJobs>6</maxRunningJobs>
</user>
<userMaxJobsDefault>3</userMaxJobsDefault>
3. 重启 JobTracker
4. 访问 http://jobTracker:50030/scheduler , 查看 FariScheduler 的 UI
5 . 提交任务测试
第四部分:Shuffle与排序
Mapreduce 的 map 结束后,把数据重新组织,作为 reduce 阶段的输入,该过程称 之为 shuffle--- 洗牌。
而数据在 Map 与 Reduce 端都会做排序。
Map
• Map 的输出是由collector控制的
• 我们从collect函数入手
Reduce
•reduce的Shuffle过程,分成三个阶段:复制Map输出、排序合并、reduce处理。
•主要代码在reduce的 run函数
Shuffle优化
•首先Hadoop的Shuffle在某些情况并不是最优的,例如,如果需要对2集合合并,那么其实排序操作时不需要的。
•我们可以通过调整参数来优化Shuffle
•Map端
•io.sort.mb
•Reduce端
•mapred.job.reduce.input.buffer.percent
第五部分:任务的执行时的一些特有的概念
推测式执行
•每一道作业的任务都有运行时间,而由于机器的异构性,可能会会造成某些任务会比所有任务的平均运行时间要慢很多。
•这时MapReduce会尝试在其他机器上重启慢的任务。为了是任务快速运行完成。
•该属性默认是启用的。
JVM重用
•启动JVM是一个比较耗时的工作,所以在MapReduce中有JVM重用的机制。
•条件是统一个作业的任务。
•可以通过mapred.job.reuse.jvm.num.tasks定义重用次数,如果属性是-1那么为无限制。
跳过坏记录
•数据的一些记录不符合规范,处理时抛出异常,MapReduce可以讲次记录标为坏记录。重启任务时会跳过该记录。
•默认情况下该属性是关闭的。
任务执行环境
•Hadoop为Map与Reduce任务提供运行环境。
•如:Map可以知道自己的处理的文件
•问题:多个任务可能会同时写一个文件
•解决办法:将输出写到任务的临时文件夹。目录为:{mapred.out. put.dir}/temp/${mapred.task.id}
第六部分:MapReduce的类型与格式
类型
•MapReduce的类型 使用键值对作为输入类型(key,value)•输入输出的数据类型是通过输入输出的格式进行设定的。
输入格式
•输入分片与记录
•文件输入
•文本输入
•二进制输入
•多文件输入
•数据库格式的输入
输入分片与记录
•Hadoop通过InputSplit表示分片。
•一个分片并不是数据本身,而是对分片数据的引用。
•InputFormat接口负责生成分片
<ignore_js_op>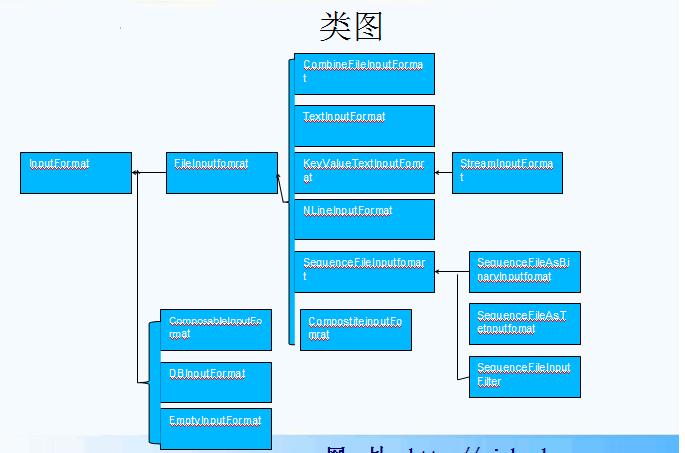
文件输入
•实现类:FileInputFormat
•通过文件作为输入源的基类。
•四个方法:
•addInputPath()
•addInputPaths()
•setInputPath()
•setInputPaths()
•FileInputFormat会按HDFS块的大小来分割文件
•避免分割
•继承FileInputFormat 重载isSplitable()
•return false
文本输入
•实现类:TextInputFormat
•TextInputFormat 是默认的输入格式。
•包括:
•KeyValueTextInputFormat
•NLineInputFormat
•XML
•输入分片与HDFS块之间的关系
•TextInputFormat的某一条记录可能跨块存在
二进制输入
•实现类:SequenceFileInputFormat
•处理二进制数据
•包括:
•SequenceFileAsTextInputFormat
•SequenceFileAsBinaryInputFormat
多文件输入
•实现类:MultipleInputs
•处理多种文件输入
•包括:
•addInputPath
数据库输入
•实现类:DBInputFormat
•注意使用,因为连接过多,数据库无法承受。
输出格式
•文本输出
•二进制输出
•多文件输出
•数据库格式的输出
文本输出
•实现类:TextOutputFormat
•默认的输出方式
• 以 "key \t value" 的方式输出
二进制输出
•基类: SequenceFileOutputFormat
•实现类: SequenceFileAsTextOutputFormat
MapFileOutputFormat
SequenceFileAsBinaryOutputFormat
多文件输出
•MutipleOutputFormat•MutipleOutputs
•两者的不同在于MutipleOutputs可以产生不同类型的输出
数据库格式输出• 实现类
DBOutputFormat
[转载] MapReduce工作原理讲解的更多相关文章
- MapReduce工作原理讲解
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•TaskT ...
- MapReduce工作原理
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•Tas ...
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- Hadoop MapReduce工作原理
在学习Hadoop,慢慢的从使用到原理,逐层的深入吧 第一部分:MapReduce工作原理 MapReduce 角色 •Client :作业提交发起者. •JobTracker: 初始化作业,分配 ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- MapReduce工作原理详解
文章概览: 1.MapReduce简介 2.MapReduce有哪些角色?各自的作用是什么? 3.MapReduce程序执行流程 4.MapReduce工作原理 5.MapReduce中Shuffle ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
- [转载] zookeeper工作原理、安装配置、工具命令简介
转载自http://www.cnblogs.com/kunpengit/p/4045334.html 1 Zookeeper简介Zookeeper 是分布式服务框架,主要是用来解决分布式应用中经常遇到 ...
- [转载]WebDriver工作原理
转载自:https://www.cnblogs.com/testermark/p/3546287.html WebDriver的工作原理: 在我们new一个WebDriver的过程中,Seleniu ...
随机推荐
- IDL 指针
IDL指针与C.C++和FORTRAN等其他程序语言的指针不同,它所处的多变量是可以动态分配内存的全局变量,不只想真正的内存地址 1.创建和访问指针 指针用指针函数Ptr_New()来创建,通过“*” ...
- topN 算法 以及 逆算法(随笔)
topN 算法 以及 逆算法(随笔) 注解:所谓的 topN 算法指的是 在 海量的数据中进行排序从而活动 前 N 的数据. 这就是所谓的 topN 算法.当然你可以说我就 sort 一下 排序完了直 ...
- python 目录文件
每天写一点,总有一天我这条咸鱼能变得更咸 python 中对文件及目录的操作基本依赖与os,shutil模块,其中以os模块为主,最主要的几个方法实例如下: 1.判断文件/目录是否存在(os.path ...
- win10 UWP button
button有很多和wpf一样,可以看<深入浅出WPF> 我们可以在button的click写上 <Button Content="确定" Click=" ...
- STM32外部中断线编程
#include "ExtiConfig.h" unsigned char key1Down = 0; unsigned char key2Down = 0; /********* ...
- C#使用互斥量(Mutex)实现多进程并发操作时进程间的同步操作(进程同步)
本文主要是实现操作系统级别的进程同步的代码及测试结果,代码经过测试,可直接使用,也可供参考. 承接上一篇博客的业务场景[C#使用读写锁三行代码简单解决多线程并发写入文件时线程同步的问题]. 随着服务进 ...
- Linux入门(12)——解决双系统下Ubuntu16.04不能访问Windows分区
解决办法一: 进入windows系统,关闭快速启动,关机. 解决办法二: 如果办法一不能解决问题,用这个办法. 查看盘符: sudo fdisk -l 需要在查看盘符后记下目标盘符的数字,比如想解除C ...
- 如何升级laravel5.4到laravel5.5并使用新特性?
如何升级laravel5.4到laravel5.5并使用新特性? 修改composer.json: "laravel/framework": "5.5.*", ...
- MySQL锁类型以及子查询锁表问题、解锁
MySQL中select * for update锁表的范围 MySQL中select * for update锁表的问题 由于InnoDB预设是Row-Level Lock,所以只有「明确」的指定主 ...
- kafka 的 createDirectStream
一入大数据深似海,脑袋不够用了,先留下只言片语. kafka api中给出2类直接获取流的接口:createStream和createDirectStream. createStream比较简单,只需 ...