深度学习的异构加速技术(一):AI 需要一个多大的“心脏”?
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
作者:kevinxiaoyu,高级研究员,隶属腾讯TEG-架构平台部,主要研究方向为深度学习异构计算与硬件加速、FPGA云、高速视觉感知等方向的构架设计和优化。“深度学习的异构加速技术”系列共有三篇文章,主要在技术层面,对学术界和工业界异构加速的构架演进进行分析。
一、概述:通用=低效
作为通用处理器,CPU (Central Processing Unit) 是计算机中不可或缺的计算核心,结合指令集,完成日常工作中多种多样的计算和处理任务。然而近年来,CPU在计算平台领域一统天下的步伐走的并不顺利,可归因于两个方面,即自身约束和需求转移。
(1)自身约束又包含两方面,即半导体工艺,和存储带宽瓶颈。
一方面,当半导体的工艺制程走到7nm后,已逼近物理极限,摩尔定律逐渐失效,导致CPU不再能像以前一样享受工艺提升带来的红利:通过更高的工艺,在相同面积下,增加更多的计算资源来提升性能,并保持功耗不变。为了追求更高的性能,更低的功耗,来适应计算密集型的发展趋势,更多的设计通过降低通用性,来提升针对某一(或某一类)任务的性能,如GPU和定制ASIC。
另一方面,CPU内核的计算过程需要大量数据,而片外DDR不仅带宽有限,还具有较长的访问延迟。片上缓存可以一定程度上缓解这一问题,但容量极为有限。Intel通过数据预读、乱序执行、超线程等大量技术,解决带宽瓶颈,尽可能跑满CPU,但复杂的调度设计和缓存占用了大量的CPU硅片面积,使真正用来做运算的逻辑,所占面积甚至不到1%[1]。同时,保证程序对之前产品兼容性的约束,在一定程度上制约了CPU构架的演进。
(2)需求转移,主要体现在两个逐渐兴起的计算密集型场景,即云端大数据计算和深度学习。尤其在以CNN为代表的深度学习领域,准确率的提升伴随着模型深度的增加,对计算平台的性能要求也大幅增长,如图1所示[2]。相比于CPU面对的通用多任务计算,深度学习计算具有以下特点:任务单一,计算密度大,较高的数据可复用率。对计算构架的要求在于大规模的计算逻辑和数据带宽,而不在于复杂的任务调度,因此在CPU上并不能跑出较好的性能。

图1.1 深度学习的发展趋势:更高精度与更深的模型,伴随着更高的计算能力需求。
基于上述原因,CPU构架在深度学习、大数据分析,以及部分嵌入式前端应用中并不具备普适性,此时,异构计算开始进入人们的视野。本文主要针对深度学习的计算构架进行讨论。
在讨论之前,先上一张经典的类比图:分别以“可编程能力/灵活性”和“开发难度/定制性/计算效率/能耗”为横轴和纵轴,将CPU与当前主流异构处理器,如GPU、FPGA、专用ASIC等进行比较。

图1.2 计算平台选择依据
通过前文分析可知,CPU最大限度的灵活性是以牺牲计算效率为代价。GPU将应用场景缩减为图形图像与海量数据并行计算,设计了数千计算内核,有效的提升了硅片上计算逻辑的比例,但随之而来的带宽需求也是相当恐怖的。为了解决这一问题,一方面,为了保证通用性,兼容低数据复用的高带宽场景,GPU内部设计了大量分布式缓存;另一方面,GPU的显存始终代表了当前可商用化存储器的最新成果。显存采用的DDR始终领先服务器内存1~2代,并成为业界首先使用HBM的应用。因此,相比于CPU,GPU具备更高的计算性能和能耗比,但相对的通用性和带宽竞争使其能耗比依然高于FPGA和ASIC,并且性能依赖于优化程度,即计算模型和数据调度要适配GPU的底层架构。
FPGA和ASIC则更倾向于针对某一特定应用。无疑,专用ASIC具有最高的计算效率和最低的功耗,但在架构、设计、仿真、制造、封装、测试等各个环节将消耗大量的人力和物力。而在深度学习模型不断涌现的环境下,当尚未出现确定性应用时,对CNN、RNN中的各个模型分别进行构架设计甚至定制一款独立ASIC是一件非常奢侈的事情,因此在AI处理器的设计上,大家的做法逐渐一致,设计一款在AI领域具备一定通用性的FPGA/ASIC构架,称为领域处理器。使其可以覆盖深度学习中的一类(如常见CNN模型),或多类(如CNN+RNN等)。
二、嵌入式VS云端,不同场景下,AI处理器的两个选择
2.1 AI处理器的发展和现状
伴随着深度学习模型的深化和算力需求的提升,从学术界兴起的AI处理器方案已经迅速蔓延到工业界。目前,各大互联网、半导体、初创公司的方案主要分为云端、嵌入式端两类(或称为云侧和端侧),可归纳如表1.1所示若感兴趣可转到唐杉同学维护的列表:https://basicmi.github.io/Deep-Learning-Processor-List/

表1.1 深度学习处理器方案列表
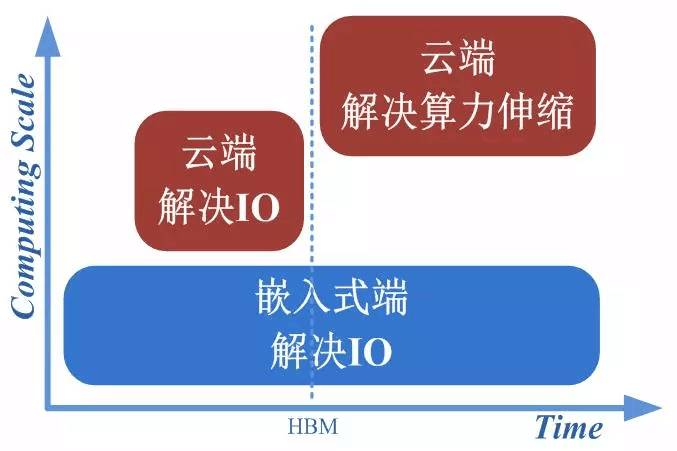
图1.3 AI处理器的发展和设计目标
AI处理器的发展过程如图1.3所示。在早期,对AI处理器架构的探讨源于学术界的半导体和体系架构领域,此时模型层数较少,计算规模较小,算力较低,主要针对场景为嵌入式前端;随着模型的逐渐加深,对算力的需求也相应增加,导致了带宽瓶颈,即IO问题(带宽问题的成因详见2.2节),此时可通过增大片内缓存、优化调度模型来增加数据复用率等方式解决;当云端的AI处理需求逐渐浮出水面,多用户、高吞吐、低延迟、高密度部署等对算力的需求进一步提升。计算单元的剧增使IO瓶颈愈加严重,要解决需要付出较高代价(如增加DDR接口通道数量、片内缓存容量、多芯片互联等),制约了处理器实际应用。此时,片上HBM(High Bandwidth Memory,高带宽存储器)的出现使深度学习模型完全放到片上成为可能,集成度提升的同时,使带宽不再受制于芯片引脚的互联数量,从而在一定程度上解决了IO瓶颈,使云端的发展方向从解决IO带宽问题,转向解决算力伸缩问题。
到目前为止,以HBM/HMC的应用为标志,云端高性能深度学习处理器的发展共经历了两个阶段:
1.第一阶段,解决IO带宽问题;
2.第二阶段,解决算力伸缩问题。
2.2 带宽瓶颈
第一阶段,囊括了初期的AI处理器,以及至今的大部分嵌入式前端的解决方案,包括第一代TPU、目前FPGA方案的相关构架、寒武纪ASIC构架,以及90%以上的学术界成果。欲达到更高的性能,一个有效的方法是大幅度提升计算核心的并行度,但算力的扩张需要匹配相应的IO带宽。例如,图1.4中的1个乘加运算单元若运行在500MHz的频率下,每秒需要4GB的数据读写带宽;一个典型的云端高性能FPGA(以Xilinx KU115为例)共有5520个DSP,跑满性能需要22TB的带宽;而一条DDR4 DIMM仅能提供19.2GB的带宽(上述分析并不严谨,但不妨碍对带宽瓶颈的讨论)。因此在第一阶段,设计的核心是,一方面通过共享缓存、数据调用方式的优化等方式提升数据复用率,配合片上缓存,减少从片外存储器的数据加载次数。另一方面通过模型优化、低位宽量化、稀疏化等方式简化模型和计算。
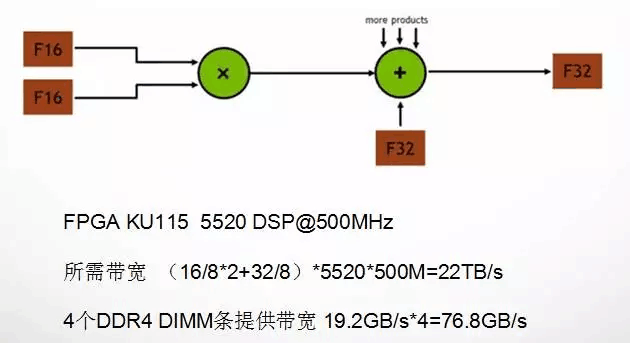
图1.4 一个乘加单元及其带宽计算(累加值通常与输出共用,故未计入带宽)
2.3 算力伸缩
尽管片上分布的大量缓存能提供足够的计算带宽,但由于存储结构和工艺制约,片上缓存占用了大部分的芯片面积(通常为1/3至2/3),限制了算力提升下缓存容量的同步提升,如图1.5所示。


图1.5 芯片中片上缓存的规模,上图为Google第一代TPU,蓝色部分为缓存区域,占用芯片面积的37%;下图为寒武纪公司的DiaoNao AI ASIC设计,缓存占面积的66.7%(NBin+NBout+SB)。
而以HBM为代表的存储器堆叠技术,将原本一维的存储器布局扩展到三维,大幅度提高了片上存储器的密度,如图1.6所示,标志着高性能AI处理器进入第二阶段。但HBM的需要较高的工艺而大幅度提升了成本,因此仅出现在互联网和半导体巨头的设计中。HBM使片上缓存容量从MB级别提升到GB级别,可以将整个模型放到片上而不再需要从片外DDR中加载;同时,堆叠存储器提供的带宽不再受限于芯片IO引脚的制约而得到50倍以上的提升,使带宽不再是瓶颈。此时,设计的核心在于高效的计算构架、可伸缩的计算规模、和分布式计算能力,以应对海量数据的训练和计算中的频繁交互。
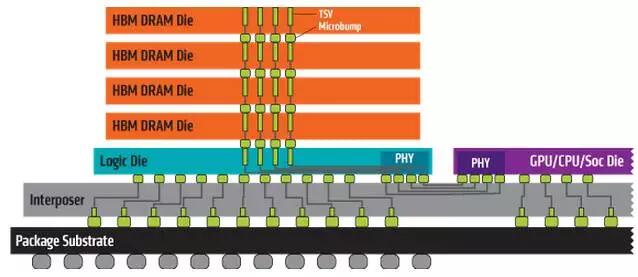
图1.6 HBM与片内垂直堆叠技术
目前AI构架已从百家争鸣,逐渐走向应用。在后续的篇幅中,将对这两个阶段进行论述。
[1] 王逵, “CPU和GPU双低效,摩尔定律之后一万倍 ——写于TPU版AlphaGo重出江湖之际”,新智元,2017.
[2] Jeff Dean, "Keynote: Recent Advances in Artificial Intelligence via Machine Learning and the Implications for Computer System Design", Hotchips2017, 2017.
相关阅读
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处
原文链接:https://cloud.tencent.com/community/article/244743?utm_source=bky
深度学习的异构加速技术(一):AI 需要一个多大的“心脏”?的更多相关文章
- win10+anaconda+cuda配置dlib,使用GPU对dlib的深度学习算法进行加速(以人脸检测为例)
在计算机视觉和机器学习方向有一个特别好用但是比较低调的库,也就是dlib,与opencv相比其包含了很多最新的算法,尤其是深度学习方面的,因此很有必要学习一下.恰好最近换了一台笔记本,内含一块GTX1 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN,Faster R-CNN
基于深度学习的目标检测技术演进:R-CNN.Fast R-CNN,Faster R-CNN object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.obj ...
- 基于深度学习的病毒检测技术无需沙箱环境,直接将样本文件转换为二维图片,进而应用改造后的卷积神经网络 Inception V4 进行训练和检测
话题 3: 基于深度学习的二进制恶意样本检测 分享主题:全球正在经历一场由科技驱动的数字化转型,传统技术已经不能适应病毒数量飞速增长的发展态势.而基于沙箱的检测方案无法满足 APT 攻击的检测需求,也 ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- 深度学习:又一次推动AI梦想(Marr理论、语义鸿沟、视觉神经网络、神经形态学)
几乎每一次神经网络的再流行,都会出现:推进人工智能的梦想之说. 前言: Marr视觉分层理论 Marr视觉分层理论(百度百科):理论框架主要由视觉所建立.保持.并予以解释的三级表象结构组成,这就是: ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- (转)基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- 深度学习面试题16:小卷积核级联卷积VS大卷积核卷积
目录 感受野 多个小卷积核连续卷积和单个大卷积核卷积的作用相同 小卷积核的优势 参考资料 感受野 在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(fe ...
- 【神经网络与深度学习】如何在Caffe中配置每一个层的结构
如何在Caffe中配置每一个层的结构 最近刚在电脑上装好Caffe,由于神经网络中有不同的层结构,不同类型的层又有不同的参数,所有就根据Caffe官网的说明文档做了一个简单的总结. 1. Vision ...
随机推荐
- BZOJ 1041 [HAOI2008]圆上的整点:数学
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1041 题意: 给定n(n <= 2*10^9),问你在圆x^2 + y^2 = n^ ...
- CSS盒子模型之详解
前言: 盒子模型是css中最核心的基础知识,理解了这个重要的概念才能更好的排版,进行页面布局.一.css盒子模型概念 CSS盒子模型 又称框模型 (Box Model) ,包含了元 ...
- Go 单例模式[个人翻译]
原文地址:http://marcio.io/2015/07/singleton-pattern-in-go/ 最近几年go语言的增长速度非常惊人,吸引着各界人士切换到Go语言.最近有很多关于使用Rub ...
- PPT的应用
ppt是Office中一个制作演示文稿的一个办公软件使阐述过程简明而又清晰,轻松又丰富详实,从而有效表达自己以及与他人沟通,所创建的文件被称为电子演示文稿,其扩展名为.PPT.一个演示文稿由若干张电子 ...
- FixedUpdate真的是固定的时间间隔执行吗?聊聊游戏定时器
0x00 前言 有时候即便是官方的文档手册也会让人产生误解,比如本文将要讨论的Unity引擎中的FixedUpdate方法. This function is called every fixed f ...
- MVC(一)-MVC的基础认知
MVC是一种编程模式和设计思想,MVC大致切割为三个主要单元:Model(实体模型),View(视图),Contrller(控制器),MVC主要目在于简化软件开发的复杂度,让程序代码形成一个松耦合. ...
- 博客志第一天——判断一个整数N是否是完全平方数?
关注博客园很久,今天是第一次写博客.先附上一个C题目:写一个函数判断一个整数是否为完全平方数,同时是否该数的各位数至少两个相同的数字 #include <stdio.h> #include ...
- C#中的异常处理(try-catch的使用)——使程序更加稳定
使用try-catch来对代码中容易出现异常的语句进行异常捕获. try { 可能出现异常的代码: } catch { 出现异常后需要执行的代码: } 注:1.在执行过程中,如果try中的代码没有出现 ...
- SpringMVC自定义配置消息转换器踩坑总结
问题描述 最近在开发时候碰到一个问题,springmvc页面向后台传数据的时候,通常我是这样处理的,在前台把数据打成一个json,在后台接口中使用@requestbody定义一个对象来接收,但是这次数 ...
- HDU 6055 Regular polygon
Regular polygon Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)T ...