hadoop+hive+spark搭建(三)
一、spark安装
因为之前安装过hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can use with most Hadoop distributions]”,然后,点击“Download Spark”后面的“spark-2.1.0-bin-without-hadoop.tgz”下载即可。Pre-build with user-provided Hadoop: 属于“Hadoop free”版,这样,下载到的Spark,可应用到任意Hadoop 版本。

上传spark软件包到任意节点上
解压缩spark软件包到/usr/local/目录下

重命名为spark文件夹
mv spark-2.1.0-bin-without-hadoop/ spark
重命名conf/目录下spark-env.sh.template为spark-env.sh
cp spark-env.sh.template spark-env.sh
重命名conf/目录下slaves.template为slaves
mv slaves.template slaves
二、配置spark
编辑conf/spark-env.sh文件,在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
#上述表示Spark可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
export JAVA_HOME=/usr/local/jdk64/jdk1.8.0
编辑conf/slaves文件
三、验证spark是否安装成功
在spark目录中输入命令验证spark是否安装成功
bin/run-example SparkPi
bin/run-example SparkPi 2>&1 | grep "Pi is" #过滤显示出pi的值

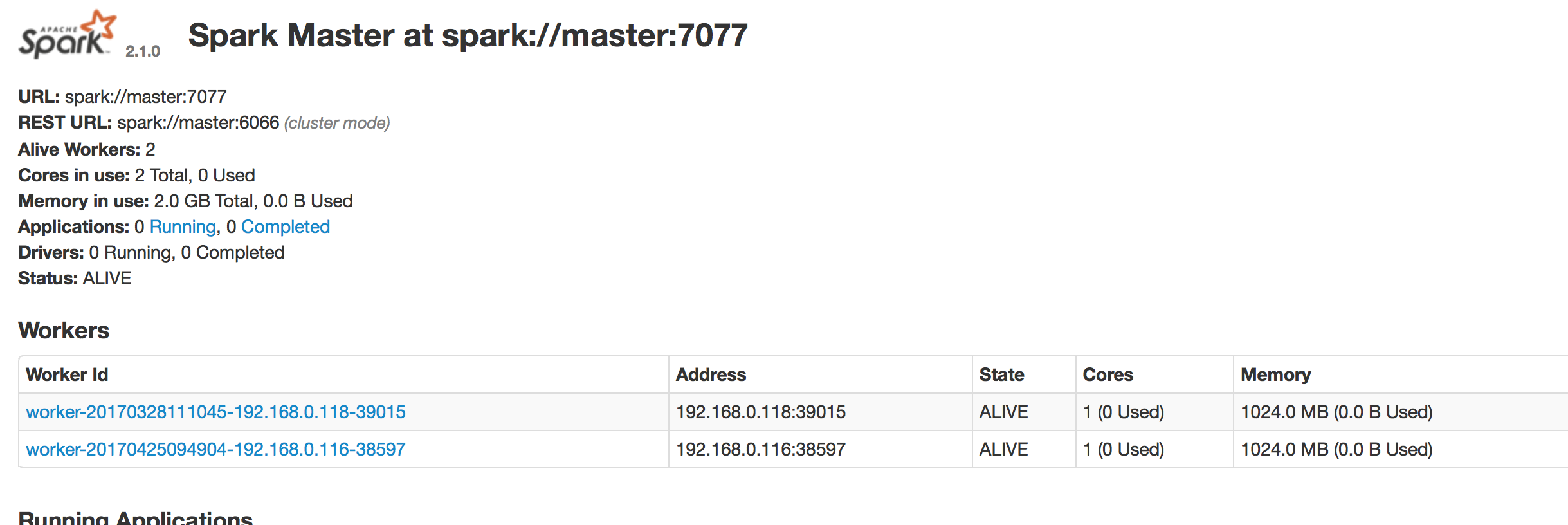
web界面为8080端口
集群模式下shell
pyspark --master spark://master:7077 #python
提交应用
spark-submit
--class <main-class> #需要运行的程序的主类,应用程序的入口点
--master <master-url> #Master URL,下面会有具体解释
--deploy-mode <deploy-mode> #部署模式
... # other options #其他参数
<application-jar> #应用程序JAR包
[application-arguments] #传递给主类的主方法的参数
hadoop+hive+spark搭建(三)的更多相关文章
- hadoop+hive+spark搭建(一)
1.准备三台虚拟机 2.hadoop+hive+spark+java软件包 传送门:Hadoop官网 Hive官网 Spark官网 一.修改主机名,hosts文件 主机名修改 hostnam ...
- hadoop+hive+spark搭建(二)
上传hive软件包到任意节点 一.安装hive软件 解压缩hive软件包到/usr/local/hadoop/目录下 重命名hive文件夹 在/etc/profile文件中添加环境变量 export ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- hadoop和spark搭建记录
因玩票需要,使用三台搭建spark(192.168.1.10,192.168.1.11,192.168.1.12),又因spark构建在hadoop之上,那么就需要先搭建hadoop.历经一个两个下午 ...
- 了解大数据的技术生态系统 Hadoop,hive,spark(转载)
首先给出原文链接: 原文链接 大数据本身是一个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你能够把它比作一个厨房所以须要的各种工具. 锅碗瓢盆,各 ...
- 一文教你看懂大数据的技术生态圈:Hadoop,hive,spark
转自:https://www.cnblogs.com/reed/p/7730360.html 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞 ...
- 配置Hadoop,hive,spark,hbase ————待整理
五一一天在家搭建好了集群,要上班了来不及整理,待下周周末有时间好好整理整理一个完整的搭建hadoop生态圈的集群的系列 若出现license information(license not accep ...
- Hadoop集群搭建(三)~centos6.8网络配置
安装完centos之后,进入系统,进行网络配置.主要分为五个部分: 修改虚拟机网络编辑器:配置Winodws访问虚拟机:配置centos网卡:通过网络名访问虚拟机配置网络服务. (一)虚拟机网络编辑器 ...
- 服务器Hadoop+Hive搭建
出于安全稳定考虑很多业务都需要服务器服务器Hadoop+Hive搭建,但经常有人问我,怎么去选择自己的配置最好,今天天气不错,我们一起来聊一下这个话题. Hadoop+Hive环境搭建 1虚拟机和系统 ...
随机推荐
- (3)简单说说java中的异常体系
java异常体系 |--Throwable 实现类描述java的错误和异常 一般交由硬件处理 |--Error(错误)一般不通过代码去处理,一般由硬件保护 |--Exception(异常) |--Ru ...
- Linux系统启动过程详解
启动第一步--加载BIOS当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的重要,以至于计算机必须在最开始就找到它.这是因为BIOS中包含了CPU的相关信息.设备启动顺序信息.硬盘 ...
- 解决SQLServer 2008 日志无法收缩,收缩后大小不改变
问题 数据库日志文件上G,或者几十G了,使用日志收缩,和日志截断收缩都不管用.体积一直减不下来.. 解决方案 查看日志信息 在查询分析器中执行如下代码来查看日志信息: DBCC LOGINFO('数 ...
- 遍历Arraylist的方法
package com.test; import java.util.ArrayList; import java.util.Iterator; import java.util.List; publ ...
- tortoiseGit保存用户名和密码
简介:tortoiseGit(乌龟git)图形化了git,我们用起来很方便,但是我们拉取私有项目的时候,每次都要输入用户名和密码很麻烦,这里向大家介绍怎么避免多少输入 试验环境:window10,安装 ...
- line-height属性总结
line-height属性的继承性: 子元素不设置line-height时, 在父元上设置带单位的值和百分比时会先计算父元素的line-height大小然后继承过来,在父元素上设置无单位的数值时,子 ...
- 为什么要学Python
人生苦短,我用python.在大学四年的本科学习中,Python是我接触过语法最简单,功能最为强大的语言,拥有众多第三方库的支持的语言.如果要选一门编程语言作为入门,建议使用Python.但是为了更加 ...
- 自动化利器-RPM自定义打包
1.Rpm打包程序 1.1为什么要使用rpm打包 1.编译安装软件,优点是可以定制化安装目录.按需开启功能等,缺点是需要查找并实验出适合的编译参数,诸如MySQL之类的软件编译耗时过长. 2.yum安 ...
- 使用SevenZipSharp出现“Can not load 7-zip library or internal COM error! Message: DLL file does not exist.”的解决方案
如果你是从nuget上下载安装的SevenZipSharp库,当你写好相应代码,兴冲冲的启动程序进行测试时,以下画面会让你受到当头一棒: 究其原因,是因为SevenZipSharp只是native 7 ...
- php+ajax+jq
<html> <head> <meta charset="UTF-8"> <title>JQueryAjax+PHP</tit ...