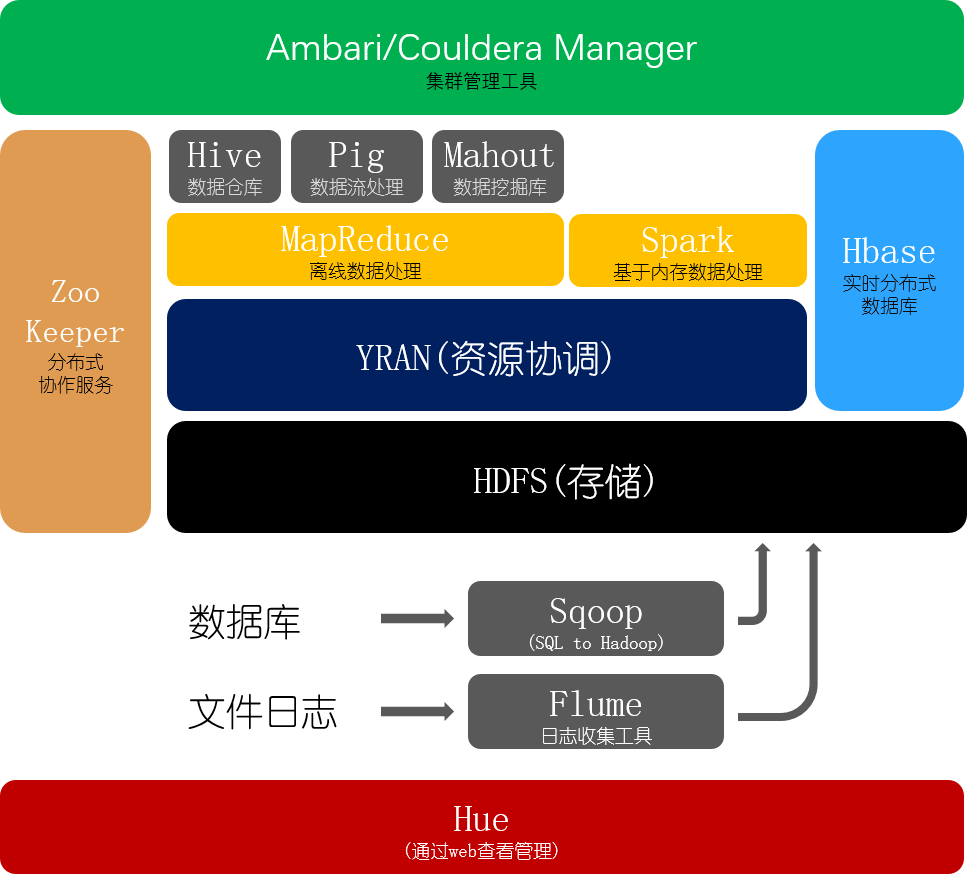
Hadoop生态系统图解
Hadoop生态架构图
参考文章:
Hadoop生态系统介绍
HDFS架构
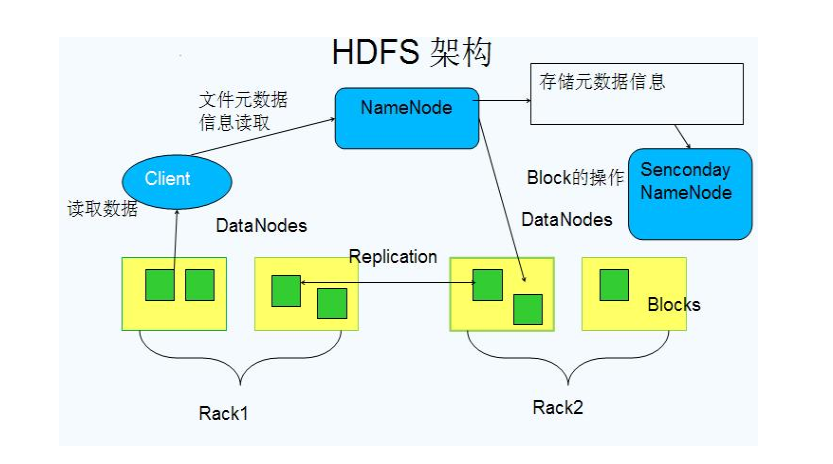
1.NaneDode:主节点,**存储文件的元数据**如文件名,文件目录结构,文件属性(生成时间,副本数量,文件权限),以及每个文件的块列表所在DataNode等
一个JAVA进程:数据存储在内存中,为了速度读写(本地还有备份)
本地磁盘:1、fsimage:镜像文件
2、edits :编辑日志
2.DataNode:数据节点,实际的本地文件系统,**存储文件块数据,以及快数据的检验和**
真正的存储:数据在磁盘中
3.Secondary NameNode用来**监控HDFS状态的辅助后台程序**,每隔一段时间**获取HDFS元数据快照**,就是定时对本地磁盘的 NameNode 的 fsimage 和 edits 进行合并,不断更新镜像
数据以block方式存储
Hadoop2.x块大小:128M
参考文章:
HDFS 原理、架构与特性介绍
谷歌三大核心技术(一)Google File System中文版
YARN架构

1.ResourceManager 资源管理者
*接收客户端请求
*启动/监控ApplicationMaster
*监控NodeManager
*资源分配与调度
2.NodeManager 节点管理者
*管理节点资源
*处理来自ResourceManager的任务
*处理来自ApplicationMaster的任务
3.ApplicationMaster 应用主管
*数据切分
*为应用程序向ResourceManager提出资源申请,并分配给内部任务
*任务监控与容错
4.container 容器
*对任务运行环境的抽象,封装了CPU,内存等多维资源以及环境变量,启动命令等运行任务的相关信息
参考文章:
Hadoop构架概览
MapReduce框架(离线运算框架)
1.将数据计算过程分为两个阶段 Map 和 Reduce
*Map将数据进行并行处理
*Reduce将处理结果进行汇总
2.shuffle 连接 Map 和 Reduce 阶段
*Map Task 将数据存储到本地磁盘
*Reduce Task 将数据从 Map Task 上读一份数据
特点:
*仅适合离线数据处理,有极高的容错性和拓展性,适合简单批处理任务
*启动开销大,过多使用磁盘导致效率低下
MapReduce on YRAN
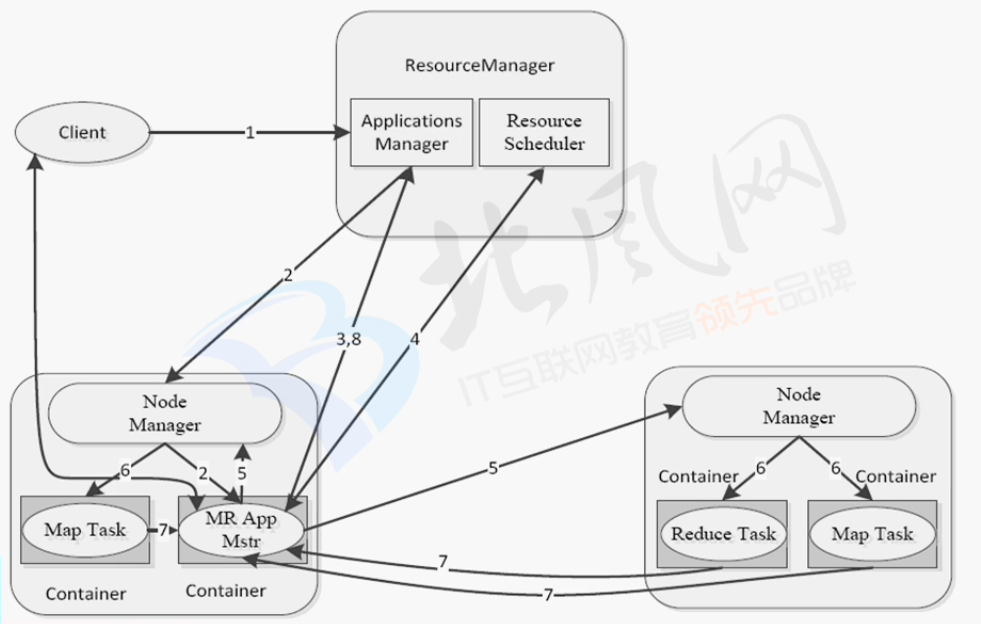
从客户端到客户端中间的过程详解图
注:图片来源见水印,侵删
Hadoop生态系统图解的更多相关文章
- Hadoop概念学习系列之Hadoop 生态系统(十二)
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Hadoop生态系统如何选择搭建
Apache Hadoop项目的目前版本(2.0版)含有以下模块: Hadoop通用模块:支持其他Hadoop模块的通用工具集. Hadoop分布式文件系统(HDFS):支持对应用数据高吞吐量访问的分 ...
- Hadoop 生态系统
1.概述 最近收到一些同学和朋友的邮件,说能不能整理一下 Hadoop 生态圈的相关内容,然后分享一些,我觉得这是一个不错的提议,于是,花了一些业余时间整理了 Hadoop 的生态系统,并将其进行了归 ...
- 从问题域出发认识Hadoop生态系统
近些年来Hadoop生态系统发展迅猛,它本身包含的软件越来越多,同时带动了周边系统的繁荣发展.尤其是在分布式计算这一领域,系统繁多纷杂,时不时冒出一个系统,号称自己比MapReduce或者Hive高效 ...
- hadoop生态系统的详细介绍
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YAR ...
- hadoop 之Hadoop生态系统
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YAR ...
- 04_Apache Hadoop 生态系统
内容提纲: 1)对 Apache Hadoop 生态系统的认识(Hadoop 1.x 和 Hadoop 2.x) 2) Apache Hadoop 1.x 框架架构原理的初步认识 3) Apache ...
- Hadoop概念学习系列之Hadoop 生态系统
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Apache Kudu: Hadoop生态系统的新成员实现对快速数据的快速分析
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop's storage la ...
随机推荐
- 详解C# Tuple VS ValueTuple(元组类 VS 值元组)
C# 7.0已经出来一段时间了,大家都知道新特性里面有个对元组的优化,并且网上也有大量的介绍,这里利用详尽的例子详解Tuple VS ValueTuple(元组类VS值元组),10分钟让你更了解Val ...
- html或者php中 input框限制只能输入正整数,逻辑与和或运算
有时需要限制文本框输入内容的类型,本节分享下正则表达式限制文本框只能输入数字.小数点.英文字母.汉字等代码. 例如,输入大于0的正整数 代码如下: <input onkeyup="if ...
- python之路 socket,socketsever初探
socket的英文原义是"孔"或"插座".作为BSD UNIX的进程通信机制,取后一种意思.通常也称作"套接字",用于描述IP地址和端口,是 ...
- python基础 - 01
python 变量名 在python中的变量命名,与其他语言大体相似,变量的命名规则如下: 变量名是数字.字母.下划线的任意组合 变量名的第一个字符不能是数字 系统的关键字不能设置为变量名 Ti ...
- VR全景智慧城市搭建掀起实体市场潮流
在互联网时代的今天,用户体验至上,全景智慧城市搭建作为一个新型的科技展示技术,通过新颖的广告方式更能吸引用户眼球,足不出户,观看现场实景,达到沉浸式体验.在这样的大环境下,全景智慧城市搭建开启了VR全 ...
- 第40篇 使用Sublime+MarkDown快速写博客
原文地址:http://blog.laofu.online/2017/06/03/how-use-sublime/ 前端的开发人员应该都知道sublime的神器,今天就说说如何使用sublime结合m ...
- Windows 修改电脑属性(一)
修改电脑属性里的注册信息 修改电脑属性的注册信息 运行注册表的方法:开始→运行→regedit→确定 1.CPU型号可以注册表编辑器中定位到下面的位置: HKEY_LOCAL_MACHINE\HARD ...
- linux tesseract 安装及部署tess4j项目的常见问题
linux上部署tess4j项目 在windows上项目是可以正常运行的,部署到Linux上后,运行报异常,异常内容为:Unable to load library 'tesseract': Nati ...
- 用户权限模块之spring security
准备工作:数据库采用mysql(5.6及以上) CREATE TABLE `auth_system` ( `ID` int(11) NOT NULL AUTO_INCREMENT COMMENT 'I ...
- window.close()方法对谷歌和火狐浏览器无效
在近期的项目中,遇到了一个问题,就是用户到新浪支付进行操作,操作成功后,指定到一个网页,需求是点击确定,关闭该网页.需求出来以后认为这种就是小菜一碟,直接用 window.close()方法就可以实现 ...