为什么我们选择parquet
说明:此方案已经我们已经运行1年。
1、场景描述:
我们对客户登录日志做了数据仓库,但实际业务使用中有一些个共同点,
A 需要关联维度表
B 最终仅取某个产品一段时间内的数据
C 只关注其中极少的字段
基于以上业务,我们决定每天定时统一关联维度表,对关联后的数据进行另外存储。各个业务直接使用关联后的数据进行离线计算。
2、择parquet的外部因素
在各种列存储中,我们最终选择parquet的原因有许多。除了parquet自身的优点,还有以下因素
A、公司当时已经上线spark 集群,而spark天然支持parquet,并为其推荐的存储格式(默认存储为parquet)。
B、hive 支持parquet格式存储,如果以后使用hiveql 进行查询,也完全兼容。
3、选择parquet的内在原因
下面通过对比parquet和csv,说说parquet自身都有哪些优势
csv在hdfs上存储的大小与实际文件大小一样。若考虑副本,则为实际文件大小*副本数目。(若没有压缩)
3.1 parquet采用不同压缩方式的压缩比
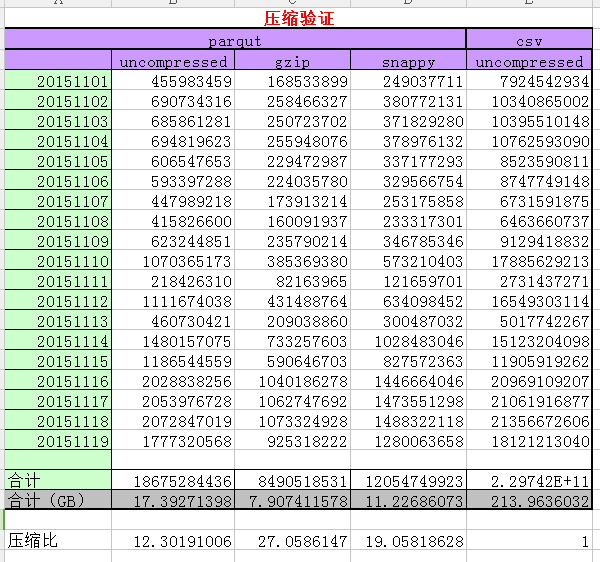
说明:原始日志大小为214G左右,120+字段
采用csv(非压缩模式)几乎没有压缩。
采用parquet 非压缩模式、gzip、snappy格式压缩后分别为17.4G、8.0G、11G,达到的压缩比分别是:12、27、19。
若我们在hdfs上存储3份,压缩比仍达到4、9、6倍
3.2 分区过滤与列修剪
3.2.1分区过滤
parquet结合spark,可以完美的实现支持分区过滤。如,需要某个产品某段时间的数据,则hdfs只取这个文件夹。
spark sql、rdd 等的filter、where关键字均能达到分区过滤的效果。
使用spark的partitionBy 可以实现分区,若传入多个参数,则创建多级分区。第一个字段作为一级分区,第二个字段作为2级分区。。。。。
3.2.2 列修剪
列修剪:其实说简单点就是我们要取回的那些列的数据。
当取得列越少,速度越快。当取所有列的数据时,比如我们的120列数据,这时效率将极低。同时,也就失去了使用parquet的意义。
3.2.3 分区过滤与列修剪测试如下:
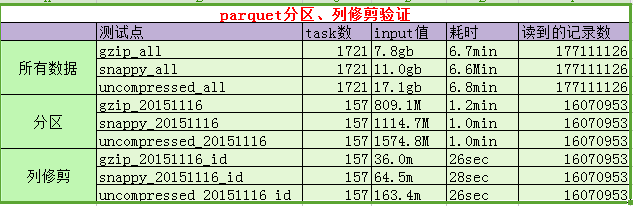
说明:
A、task数、input值、耗时均为spark web ui上的真实数据。
B、之所以没有验证csv进行对比,是因为当200多G,每条记录为120字段时,csv读取一个字段算个count就直接lost excuter了。
C、注意:为避免自动优化,我们直接打印了每条记录每个字段的值。(以上耗时估计有多部分是耗在这里了)
D、通过上图对比可以发现:
- 当我们取出所有记录时,三种压缩方式耗时差别不大。耗时大概7分钟。
- 当我们仅取出某一天时,parquet的分区过滤优势便显示出来。仅为6分之一左右。貌似当时全量为七八天左右吧。
- 当我们仅取某一天的一个字段时,时间将再次缩短。这时,硬盘将只扫描该列所在rowgroup的柱面。大大节省IO。如有兴趣,可以参考深入分析Parquet列式存储格式

E、测试时请开启filterpushdown功能
4、结论
- parquet的gzip的压缩比率最高,若不考虑备份可以达到倍。可能这也是spar parquet默认采用gzip压缩的原因吧。
- 分区过滤和列修剪可以帮助我们大幅节省磁盘IO。以减轻对服务器的压力。
- 如果你的数据字段非常多,但实际应用中,每个业务仅读取其中少量字段,parquet将是一个非常好的选择。
为什么我们选择parquet的更多相关文章
- hadoop入门到实战(6)hive常用优化方法总结
问题导读:1.如何理解列裁剪和分区裁剪?2.sort by代替order by优势在哪里?3.如何调整group by配置?4.如何优化SQL处理join数据倾斜?Hive作为大数据领域常用的数据仓库 ...
- Parquet与ORC:高性能列式存储格式(收藏)
背景 随着大数据时代的到来,越来越多的数据流向了Hadoop生态圈,同时对于能够快速的从TB甚至PB级别的数据中获取有价值的数据对于一个产品和公司来说更加重要,在Hadoop生态圈的快速发展过程中,涌 ...
- 大数据小视角2:ORCFile与Parquet,开源圈背后的生意
上一篇文章聊了聊基于PAX的混合存储结构的RCFile,其实这里笔者还了解一些八卦,RCfile的主力团队都是来自中科院的童鞋在Facebook完成的,算是一个由华人主导的编码项目.但是RCfile仍 ...
- Hive 导入 parquet 格式数据
Hive 导入 parquet 数据步骤如下: 查看 parquet 文件的格式 构造建表语句 倒入数据 一.查看 parquet 内容和结构 下载地址 社区工具 GitHub 地址 命令 查看结构: ...
- 开源列式存储引擎Parquet和ORC
转载自董的博客 相比传统的行式存储引擎,列式存储引擎具有更高的压缩比,更少的IO操作而备受青睐(注:列式存储不是万能高效的,很多场景下行式存储仍更加高效),尤其是在数据列(column)数很多,但每次 ...
- 【kudu pk parquet】runtime filter实践
已经有好一阵子没有写博文了,今天给大家带来一篇最近一段时间开发相关的文章:在impala和kudu上支持runtime filter. 大家搜索下实践者社区,可以发现前面已经有好几位同学写了这个主题的 ...
- Parquet and ORC
http://dongxicheng.org/mapreduce-nextgen/columnar-storage-parquet-and-orc/ 相比传统的行式存储引擎,列式存储引擎具有更高的压缩 ...
- parquet文件格式——本质上是将多个rows作为一个chunk,同一个chunk里每一个单独的column使用列存储格式,这样获取某一row数据时候不需要跨机器获取
Parquet是Twitter贡献给开源社区的一个列数据存储格式,采用和Dremel相同的文件存储算法,支持树形结构存储和基于列的访问.Cloudera Impala也将使用Parquet作为底层的存 ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
随机推荐
- 入参是小数的String,返回小数乘以100的String
String money = request.getParameter("orderAmt"); BigDecimal moneyDecimal = new BigDecimal( ...
- 008-Shell 流程控制
一.if else 1.1.if if 语句语法格式: if condition then command1 command2 ... commandN fi 写成一行(适用于终端命令提示符): ]; ...
- JAVA math包
Math类: java.lang.Math 类中包含基本的数字操作,如指数.对数.平方根和三角函数. java.math是一个包,提供用于执行任意精度整数(BigInteger)算法和任意精度小数(B ...
- sql中表级约束和列级约束
sql中表级约束和列级约束,在SQL SERVER中, (1) 对于基本表的约束分为列约束和表约束约束是限制用户输入到表中的数据的值的范围,一般分为列级约束与表级约束.列级约束有六种:主键Primar ...
- 一个简单的ssm项目
准备说明jdk.tomcat.idea.mave配置请看我前两篇,这里说下mysql以及我的mysql图像化工具 数据库 项目概览 项目构建--------搭建一个简单的mave的web项目,构建步骤 ...
- Shiro安全框架入门篇
一.Shiro框架介绍 Apache Shiro是Java的一个安全框架,旨在简化身份验证和授权.Shiro在JavaSE和JavaEE项目中都可以使用.它主要用来处理身份认证,授权,企业会话管理和加 ...
- 【转】使用DataConnectionDialog在运行时设置数据源连接字符串
介绍: DataConnectionDialog 类: 打开“数据连接”对话框,获取用户选择的数据连接信息. 命名空间为:Microsoft.Data.ConnectionUI 所在程序集:Micro ...
- Hexo博客部署codingNet静态资源无法加载
用Hexo搭建的个人博客,部署到github的pages的话,好像百度搜索不到.所以在国内的codingNet的pages服务也一起部署一下,这样方便国内国外搜索引擎收录进来.具体部署教程我是参考这里 ...
- java内存空间
Java内存分配与管理是Java的核心技术之一,之前我们曾介绍过Java的内存管理与内存泄露以及Java垃圾回收方面的知识,今天我们再次深入Java核心,详细介绍一下Java在内存分配方面的知识.一般 ...
- 详解Java中的clone方法 -- 原型模式
转自: http://blog.csdn.net/zhangjg_blog/article/details/18369201 Java中对象的创建 clone顾名思义就是复制, 在Java语言中, ...