spark client + yarn计算
前提:完成hadoop + kerberos安全环境搭建。
安装配置spark client:
1. wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
2. 配置
指定hadoop路径
vim conf/spark-env.sh HADOOP_CONF_DIR=/xxx/soft/hadoop-2.7.3/etc/hadoop
配置环境变量:
vim /etc/profile export SPARK_HOME=/xxx/soft/spark-2.2.0-bin-hadoop2.7
分配kerberos
kadmin.local addprinc -randkey sparkclient01@JENKIN.COM
xst -k /var/kerberos/krb5kdc/keytab/sparkclient01.keytab sparkclient01@JENKIN.COM
将keytab分发给spark client
scp /var/kerberos/krb5kdc/keytab/sparkclient01.keytab hadoop1:/xxx/soft/spark-2.2.0-bin-hadoop2.7/
在hdfs上建立文件夹:( eventLog.dir )
hadoop fs -mkdir -p /jenkintest/tmp/spark01 hadoop fs -ls /jenkintest/tmp/
启动client:
cd ./bin ./spark-submit --class org.apache.spark.examples.SparkPi \
--conf spark.eventLog.dir=hdfs://jenkintest/tmp/spark01 \
--master yarn \
--deploy-mode client \
--driver-memory 4g \
--principal sparkclient01 \
--keytab /xxx/soft/spark-2.2.0-bin-hadoop2.7/sparkclient01.keytab \
--executor-memory 1g \
--executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples*.jar \
10
命令解释:
--master yarn //代表spark任务在yarn上
--master cluser //代表spark 在yarn集群上
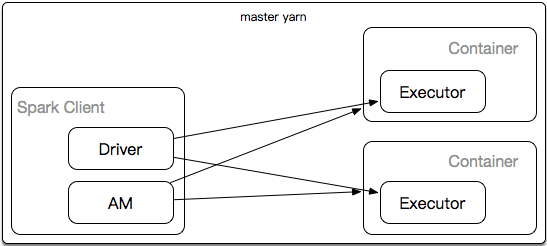
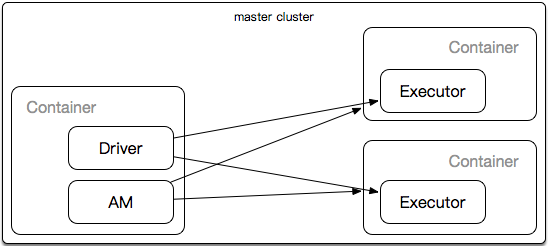
AM负责在yarn上申请资源,运行在container。
spark通过Driver控制Executor。
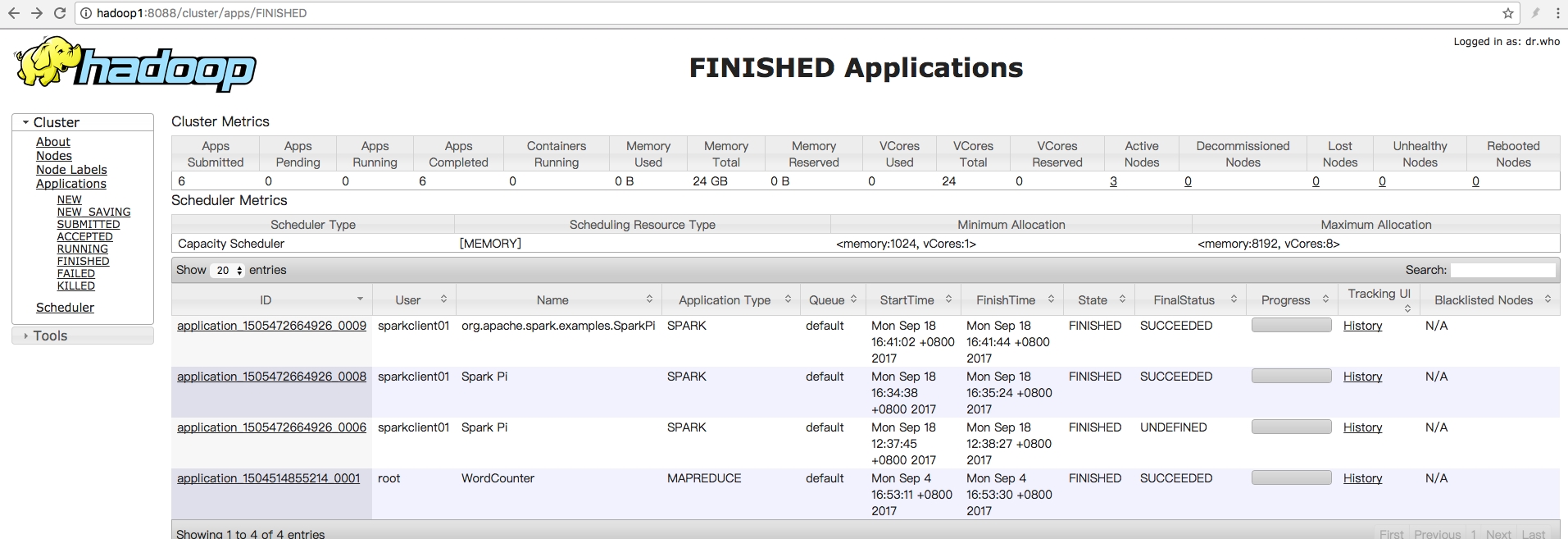
运行结果:
spark client + yarn计算的更多相关文章
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark on yarn,client模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
- Spark通过YARN提交任务不成功(包含YARN cluster和YARN client)
无论用YARN cluster和YARN client来跑,均会出现如下问题. [spark@master spark-1.6.1-bin-hadoop2.6]$ jps 2049 NameNode ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎. 概要 Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准.其主要职责将是分布式计算集群的 ...
- Spark on Yarn
Spark on Yarn 1. Spark on Yarn模式优点 与其他计算框架共享集群资源(eg.Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce ...
- Spark on Yarn遇到的问题及解决思路
原文:http://www.aboutyun.com/thread-9425-1-1.html 问题导读1.Connection Refused可能原因是什么?2.如何判断内存溢出,该如何解决?扩展: ...
- Spark On YARN内存分配
本文转自:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 此文解决了Spark ...
- Spark 1.0.0 横空出世 Spark on Yarn 部署(Hadoop 2.4)
就在昨天,北京时间5月30日20点多.Spark 1.0.0最终公布了:Spark 1.0.0 released 依据官网描写叙述,Spark 1.0.0支持SQL编写:Spark SQL Progr ...
随机推荐
- zookeeper未授权访问漏洞
1.什么是zookeeper? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交 ...
- ajax请求步骤
ajax步骤:第一步:创建xmlhttprequest对象,var xmlhttp = new XMLHttpRequest(); XMLHttpRequest对象和服务器交换数据.第二步:使用xml ...
- js 空正则匹配任意一个位置
看一个正则 这里明显,起到匹配作用的是 | 后的,可 | 后什么都没有,原理不知道,也没有搜到文献,只有在 Reg101 上是这样解释的, 所以得出结论: js 中,空正则匹配任意一个位置. 不过,这 ...
- MySQL 监控指标
为了排查问题,对数据库的监控是必不可少的,在此介绍下 MySQL 中的常用监控指标. 简介 MySQL 有多个分支版本,常见的有 MySQL.Percona.MariaDB,各个版本所对应的监控项也会 ...
- Powershell替代和截断——replace and substring
一:截取一个字符串的尾部,替代字符串中的特定字符或替代字符串中特定位置的特定字符 $a="W.endy.chen.SHAO" $b=$a.Substring(0,$a.Length ...
- Storm-源码分析-Topology Submit-Supervisor
mk-supervisor (defserverfn mk-supervisor [conf shared-context ^ISupervisor isupervisor] (log-message ...
- 解决iOS xcode打包unknown error -1=ffffffffffffffff错误
# 网上很多文档说重启机器,清除缓存什么的,纯属扯淡,都是相互复制粘贴,经测验在stackoverflow找到以下解决方法,亲测可用security unlock-keychain -p " ...
- SpringBoot与Mybatis整合实例详解
介绍 从Spring Boot项目名称中的Boot可以看出来,SpringBoot的作用在于创建和启动新的基于Spring框架的项目,它的目的是帮助开发人员很容易的创建出独立运行的产品和产品级别的基于 ...
- iOS版微信6.5.21发布 适配iPhone X
昨日,iOS版微信迎来v6.5.21正式版发布,本次升级主要适配iPhone X,在聊天中查找聊天内容时,可以查找交易消息.可以给聊天中的消息设置日期提醒.上一个正式版v6.5.16发布于9月13日, ...
- UILocalNotification 的使用
@IBAction func sendNotification(sender: AnyObject) { var userInfo = Dictionary<String,String>( ...