SpingData 的学习
Spring Data : Spring 的一个子项目,类似于Sping MVC 一样是Spring的另一个模块,所以还需要下载其jar ,它需要的jar有:
spring-data-jpa-1.11.8.RELEASE.jar spring-data-commons-1.13.8.RELEASE.jar slf4j-api-1.7.5.jar
没有添加slf4j会报错,Spring Data的版本不兼容也会报错,我在 使用SpringData出现java.lang.AbstractMethodError 这篇笔记中记载了,这里就不复述了。
Spring Data是用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷
SpringData 项目所支持 NoSQL 存储:
- MongoDB (文档数据库)
- Neo4j(图形数据库)
- Redis(键/值存储)
- Hbase(列族数据库)
SpringData 项目所支持的关系数据存储技术:
- JDBC
- JPA(我们一般将Spring Data与JPA配合使用)
JPA +Spring Data : 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就只是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成,很类似于Mybatis的mapper接口吧,但是我们一般使用的JPA实现产品都是Hibernate,所以并不像Mybatis那样还需要写SQL,最多写的就是JPQL(面向对象的写法)。
框架怎么会知道要使用什么样的业务逻辑呢?
比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。没错,Spring Data可以通过规范方法名字的方式,来确定方法具体需要实现什么样的逻辑。
准备工作
使用 Spring Data JPA 进行持久层开发需要的四个步骤:
1.配置 Spring 整合 JPA,添加jar包
2.在 Spring 配置文件中配置 Spring Data,让 Spring 为声明的接口创建代理对象。配置了 <jpa:repositories> 后(不要忘了在applicationContext.xml文件中添加jpa的约束),Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动注入的特性来直接使用该对象。
<!-- 配置SpringDate -->
<!-- 记得要加入jpa的约束 -->
<!-- base-package: 扫描 Repository Bean 所在的 package
自定义Repository中的方法是要注意Spring Data 会在 base-package 中查找 "接口名Impl" 作为实现类.
entity-manager-factory-ref:引用EntityManagerFactory
transaction-manager-ref:引用transactionManager-->
<jpa:repositories base-package="cn.lynu.repository"
entity-manager-factory-ref="entityManagerFactory"
transaction-manager-ref="transactionManager"></jpa:repositories>
3.声明持久层的接口,该接口继承 Repository,Repository 是一个标记型接口,它不包含任何方法,如必要,Spring Data 可实现 Repository 其他子接口,其中定义了一些常用的增删改查,以及分页相关的方法。 在接口中声明需要的方法,在实际使用中我们让自定义的repository接口继承Repository的子接口,可以方便我们开发。
4.Spring Data 将根据给定的策略(也就是根据方法名)来生成实现代码。
Repository 接口
Repository 接口是 Spring Data 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法。
public interface Repository<T, ID extends Serializable> { }
Spring Data可以让我们只定义接口,只要遵循 Spring Data的规范,就无需写实现类。
与继承 Repository 等价的一种方式,就是在持久层接口上使用 @RepositoryDefinition 注解,并为其指定 domainClass 和 idClass 属性。如下两种方式是完全等价的:
1.
@RepositoryDefinition(domainClass=Person.class,idClass=Integer.class)
public interface PersonRepository{} 2.
public interface PersonRepository extends Repository<Person, Integer>{}
Repository 的子接口
我们刚才说了,Repository接口中没有任何方法,所以我们可以继承其子接口,其子接口中提供了CRUD和分页的操作,开始了解一些这些子接口吧:
- Repository: 仅仅是一个标识,表明任何继承它的均为仓库接口类
- CrudRepository: 继承 Repository,实现了一组 CRUD 相关的方法
- PagingAndSortingRepository: 继承 CrudRepository,实现了一组分页排序相关的方法
- JpaRepository: 继承 PagingAndSortingRepository,实现一组 JPA 规范相关的方法
这些repository自下而上是一种继承关系。
CrudRepository接口
- T save(T entity);//保存或更新单个实体(保存还是更新区别于是否有id)
- Iterable<T> save(Iterable<? extends T> entities);//保存集合
- T findOne(ID id);//根据id查找实体
- boolean exists(ID id);//根据id判断实体是否存在
- Iterable<T> findAll();//查询所有实体,不用或慎用!
- long count();//查询实体数量
- void delete(ID id);//根据Id删除实体
- void delete(T entity);//删除一个实体
- void delete(Iterable<? extends T> entities);//删除一个实体的集合
- void deleteAll();//删除所有实体,不用或慎用!
PagingAndSortingRepository接口
该接口再上一个接口的基础上还提供了分页与排序功能 :
- Iterable<T> findAll(Sort sort); //排序
- Page<T> findAll(Pageable pageable); //分页查询(含排序功能)
//使用继承了PagingAndSortingRepository的Repository
@Test
public void testPgae() {
int pageNo=2-1; //注意 这里是当前页要减1(从0开始)
int size=5;
Sort sort=new Sort(Direction.DESC, "age"); //指定排序方式和排序的属性
//PageRequest是从Pageable接口的实现类
// PageRequest pr=new PageRequest(pageNo, size);
PageRequest pr=new PageRequest(pageNo, size,sort); //还可以指定排序
Page<Person> page = personRepository.findAll(pr);
System.out.println("当前页:"+(page.getNumber()+1)); //而显示当前页时需要加1
System.out.println("每页大小:"+page.getSize());
System.out.println("总记录数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
System.out.println("当前页的数据:"+page.getContent());
}
JpaRepository接口
该接口在上一个接口的基础上还提供了这样的方法:
- List<T> findAll(); //查找所有实体
- List<T> findAll(Sort sort); //排序、查找所有实体
- List<T> save(Iterable<? extends T> entities);//保存集合
- void flush();//执行缓存与数据库同步
- T saveAndFlush(T entity);//强制执行持久化 (可以执行插入或更新操作)
- void deleteInBatch(Iterable<T> entities);//删除一个实体集合
//使用继承了JpaRepository的Repository
//类似于JPA的merge方法 Hibernate的saveOrUpdate
@Test
public void testJPARepository() {
Person person=new Person();
person.setAge(21);
person.setBirth(new Date());
person.setpName("lz"); Person person2 = personRepository.saveAndFlush(person);
System.out.println(person==person2);
}
我们自定义的 XxxxRepository 需要继承 JpaRepository,这样的 XxxxRepository 接口就具备了通用的数据访问控制层的能力。还有一个接口,它不属于Repository的体系中,但是它提供带查询条件的分页,很强大,它就是 JpaSpecificationExecutor 接口。普通分页我们使用继承了JpaRepository接口中的findAll方法进行开发即可,如果要进行带查询条件的分页,就还需要继承JpaSpecificationExecutor 接口,使用其内部的的findAll方法:
public interface PersonRepository extends JpaRepository<Person, Integer>,JpaSpecificationExecutor<Person>{}
//实现带查询条件的分页要使用继承了JpaSpecificationExecutor的Repository
@Test
public void testCirPage() {
int pageNo=2-1; //注意 这里是当前页要减1(从0开始)
int size=5;
PageRequest pageable=new PageRequest(pageNo, size); //通常使用 Specification 的匿名内部类
Specification<Person> specification=new Specification<Person>() {
/**
* @param *root: 代表查询的实体类.
* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以
* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询 的 TypedQuery 对象.
* @param *cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象
* @return: *Predicate 类型, 代表一个查询条件.
*/
@Override
public Predicate toPredicate(Root<Person> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Path path = root.get("id");
Predicate predicate=cb.gt(path, 5); //gt表示> 大于 lt表示< 小于
return predicate;
}
}; Page<Person> page = personRepository.findAll(specification, pageable);
System.out.println("当前页:"+(page.getNumber()+1)); //而显示当前页时需要加1
System.out.println("每页大小:"+page.getSize());
System.out.println("总记录数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
System.out.println("当前页的数据:"+page.getContent()); }
SpringData 方法规范
简单条件查询: 查询某一个实体类或者集合 按照 Spring Data 的规范,查询方法以 findBy | readBy | getBy 开头,注意By关键字也不要丢失哦。 涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性以首字母大写。
例如:
//根据id查用户
Person findById(Integer id); Person findById(Integer id); Person readById(Integer id);
如果有多个查询添加的话,需要使用And关键字连接:
//根据名称或年龄查询
List<Person> findBypNameOrAge(String pName,Integer a);
对了,放心吧,方法的参数名可以自定义,但是其数据类型要与Entity的属性类型一致,不然会类型转换异常。
直接在接口中定义查询方法,如果是符合规范的,可以不用写实现,目前支持的关键字写法如下:
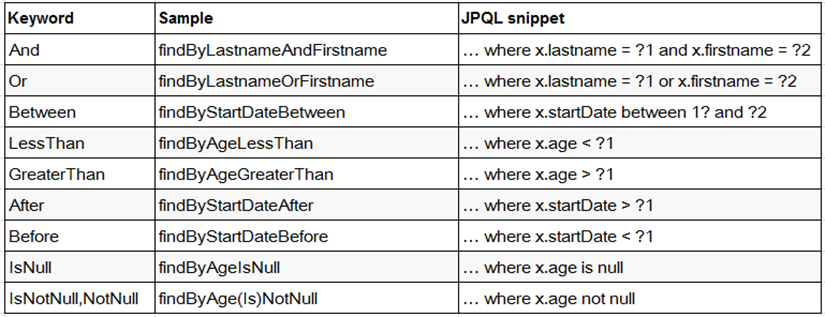
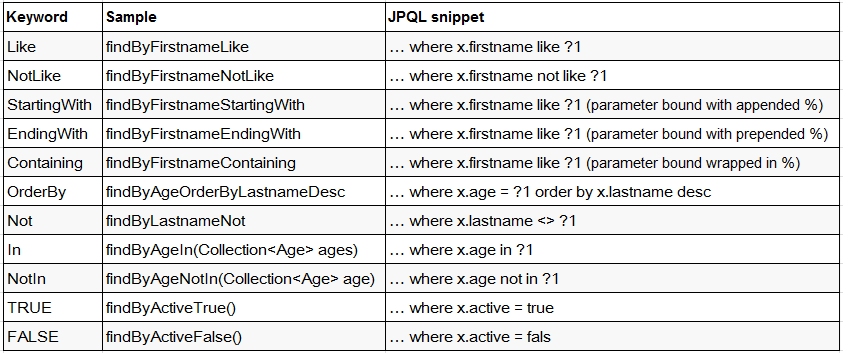
可能存在的一种特殊(很极端)情况:一个Emp实体类中有Dept 对象,Dept对象有Id属性,而Emp中有一个名为DeptId的属性,如何根据Dept的Id来查询?
如果写成 findByDeptId ,因为存在名为DeptId这个属性,所以就会按照这个属性来查询,如何区分这种同名的问题呢?这时可以明确在属性之间加上 "_" 以显式表达意图:findByDept_Id 表明是根据Emp实体中的Dept对象属性下的Id来查询
这种根据方法名称查询的方法存在一定的命名约束,如果不按照该约束命名,还会以编译时异常的形式提示开发者,如何才能随心所欲的命名方法,而可以完成各种操作呢?这就需要@Query注解了。
@Query
@Query注解使用的是 org.springframework.data.jpa.repository.Query 包下的,注意不要导错了。我们就可以在Query注解中写JPQL语句了,这样既可以摆脱方法命名约束,还可以较为灵活的创建Dao方法。
//使用@Query注解(可以不受命名约束)
//使用占位符 方法的参数顺序需要与占位符一致(?号后必须指定当前参数位置,且从1开始)
@Query("SELECT p from Person p where p.id=?1")
Person testPersonById(Integer id);
了解过JPA的就知道了,这是使用?占位符的方式,可以指定?开始的顺序是从0还是1开始。当然,也可以使用名称占位符的形式:
@Query("select p from Person p where p.id=:id or p.age=:age")
List<Person> getIdOrAge(@Param("age")Integer age,@Param("id")Integer id);
使用名称占位符的时候,需要在方法的参数上使用@Param注解来指明该参数使用的是哪一个名称占位。
如果是 @Query 中有 LIKE 关键字,后面的参数需要前面或者后面加 %,这样在传递参数值的时候就可以不加 %:
@Query("select p from Person p where p.pName like %?1%")
List<Person> likepName(String name);
@Query("select p from Person p where p.pName like %:name%")
List<Person> likepName2(@Param("name")String name);
@Modifying 注解和事务
JPQL默认情况下只支持查询,不支持UPDATE和DELETE,这也是与HQL的不同之处,但是我们可以通过添加@Modifying注解来进行修饰. 以通知 SpringData, 这是一个 UPDATE 或 DELETE 操作。注意:不支持INSERT操作。
//可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作. 注意: JPQL 不支持使用 INSERT
//在 @Query 注解中编写 JPQL 语句, 但必须使用 @Modifying 进行修饰. 以通知 SpringData, 这是一个 UPDATE 或 DELETE 操作
//UPDATE 或 DELETE 操作需要使用事务, 此时需要定义 Service 层. 在 Service 层的方法上添加事务操作.
//默认情况下, SpringData 的每个方法上有事务, 但都是一个只读事务. 他们不能完成修改操作!
@Modifying
@Query("update Person set age=:age where id=:id")
void updatePerson(@Param("age")Integer age,@Param("id")Integer id);
Spring Data默认给每个方法添加一个只读事务,注意是只读的事务,所以对于自定义的方法,如需改变 Spring Data 提供的事务默认方式,可以在方法上注解 @Transactional 声明 (这里说的就是在Service层加上事务).
为所有的 Repository 都添加自定义实现的方法
步骤:
- 定义一个接口: 声明要添加的并自实现的方法
- 提供该接口的实现类: 类名需在要声明的 Repository 后添加 Impl, 并实现方法
- 声明 Repository 接口, 并继承 1) 声明的接口 使用. 注意: 默认情况下, Spring Data 会在 base-package 中查找 "接口名Impl" 作为实现类,所以Impl的实现类需要和我们的Repository在同一个包中;如果不想以Impl结尾, 也可以通过 repository-impl-postfix 声明后缀。
第一步:定义一个接口
package cn.lynu.dao; /**
* 自定义Repository使用(自定义方法的仓库接口)
*在这个接口中写需要自定义的仓库方法
*/
public interface PersonDao {
void test();
}
第二步:添加一个以Impl结尾的实现类
package cn.lynu.repository; import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import cn.lynu.dao.PersonDao;
import cn.lynu.entity.Person; //自定义repository使用(命名规范:仓库名+Impl)
//在这里实现自定义方法的仓库接口中的方法
public class PersonRepositoryImpl implements PersonDao { @PersistenceContext
private EntityManager entityManager; @Override
public void test() {
Person person = entityManager.find(Person.class, 11);
System.out.println("--->>"+person.getpName()+"--->"+person.getAge());
} }
第三步:我们的repository也需要继承这个PersonDao接口
public interface PersonRepository extends
JpaRepository<Person, Integer>,JpaSpecificationExecutor<Person>,PersonDao{}
这样我们就可以在所有继承了PersonDao的repository中使用我们自定义的test方法了:
//使用自定义的repository的方法
@Test
public void testMyRepository() {
personRepository.test();
}
Spring MVC Spring Data Spring JPA整合
配置:
在web.xml中的配置:
基本上都是Spring和Spring MVC的配置, 还需要配置一个OpenEntityManagerInViewFilter 来处理no session 的懒加载问题,类似于在SSH整合中配的OpenSessionInView:
<!-- 处理no session(懒加载异常)问题 -->
<filter>
<filter-name>OpenEntityManagerInViewFilter</filter-name>
<filter-class>org.springframework.orm.jpa.support.OpenEntityManagerInViewFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>OpenEntityManagerInViewFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
applicationContext.xml中的配置:
其实在 JPA的学习 中 与Spring的整合都已经说过了,现在就是再添加一行整合Spring Data的代码,我在这里再贴一份吧:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa-1.8.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.3.xsd"> <!-- 配置数据源 -->
<context:property-placeholder location="classpath:db.properties"/>
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="${jdbc.user}"></property>
<property name="password" value="${jdbc.password}"></property>
<property name="driverClass" value="${jdbc.driverClass}"></property>
<property name="jdbcUrl" value="${jdbc.jdbcUrl}"></property>
</bean> <!-- 配置entitymanagerFactory -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource"></property>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"></bean>
</property>
<property name="packagesToScan" value="cn.lynu.entity"></property>
<property name="jpaProperties">
<props>
<prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.format_sql">true</prop>
<prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop>
<!-- 二级缓存和查询缓存 -->
<prop key="hibernate.cache.use_second_level_cache">true</prop>
<prop key="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</prop>
<prop key="hibernate.cache.use_query_cache">true</prop>
</props>
</property>
<!-- 只有JPA的实体类上使用@Cacheable(true)才使用二级缓存-->
<property name="sharedCacheMode" value="ENABLE_SELECTIVE"></property>
</bean> <!-- 配置组件扫描 -->
<context:component-scan base-package="cn.lynu">
<!-- 不在扫描@Controller 和@ControllerAdvice.因为已经在springmvc.xml中配置 -->
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
<context:exclude-filter type="annotation" expression="org.springframework.web.bind.annotation.ControllerAdvice"/>
</context:component-scan> <!-- JPA事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"></property>
</bean> <!-- 事务注解 -->
<tx:annotation-driven transaction-manager="transactionManager"/> <!-- 配置springData -->
<jpa:repositories base-package="cn.lynu.repository"></jpa:repositories> </beans>
整合过程使用二级缓存
在整合过程中,使用ehcache做二级缓存(还是Hibernate作为JPA的实现产品)的时候,使用Repository中自带的方法无法使用二级缓存,只有使用自定义的方法才可以,这是值得注意的。
- applicationContext.xml中配置二级缓存
- 实体类上使用@Cacheable(true) 表明该实体类使用二级缓存
- 自定义Repository中的方法,并配置@QueryHints
@QueryHints({@QueryHint(name=org.hibernate.jpa.QueryHints.HINT_CACHEABLE,value="true")})
@Query("select dept from Department dept")
public List<Department> getAll();
SpingData 的学习的更多相关文章
- 从直播编程到直播教育:LiveEdu.tv开启多元化的在线学习直播时代
2015年9月,一个叫Livecoding.tv的网站在互联网上引起了编程界的注意.缘于Pingwest品玩的一位编辑在上网时无意中发现了这个网站,并写了一篇文章<一个比直播睡觉更奇怪的网站:直 ...
- Angular2学习笔记(1)
Angular2学习笔记(1) 1. 写在前面 之前基于Electron写过一个Markdown编辑器.就其功能而言,主要功能已经实现,一些小的不影响使用的功能由于时间关系还没有完成:但就代码而言,之 ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- 消息队列——RabbitMQ学习笔记
消息队列--RabbitMQ学习笔记 1. 写在前面 昨天简单学习了一个消息队列项目--RabbitMQ,今天趁热打铁,将学到的东西记录下来. 学习的资料主要是官网给出的6个基本的消息发送/接收模型, ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- Unity3d学习 制作地形
这周学习了如何在unity中制作地形,就是在一个Terrain的对象上盖几座小山,在山底种几棵树,那就讲一下如何完成上述内容. 1.在新键得项目的游戏的Hierarchy目录中新键一个Terrain对 ...
- 《Django By Example》第四章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:祝大家新年快乐,这次带来<D ...
- 菜鸟Python学习笔记第一天:关于一些函数库的使用
2017年1月3日 星期二 大一学习一门新的计算机语言真的很难,有时候连函数拼写出错查错都能查半天,没办法,谁让我英语太渣. 关于计算机语言的学习我想还是从C语言学习开始为好,Python有很多语言的 ...
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
随机推荐
- [转载]面试心得与总结---BAT、网易、蘑菇街等
转载自:http://mp.weixin.qq.com/s?__biz=MzIzMDIxNTQ3NA==&mid=2649111851&idx=1&sn=f43c42f7262 ...
- echarts-detail--柱状图
一:柱形图 1.Echarts-柱状图柱图宽度设置-----只需要设置series中的坐标系属性barWidth就可以 /** * 堆积柱状图 * @param xaxisdata x轴:标签(数组) ...
- CUDA Samples: Julia
以下CUDA sample是分别用C++和CUDA实现的绘制Julia集曲线,并对其中使用到的CUDA函数进行了解说,code参考了<GPU高性能编程CUDA实战>一书的第四章,各个文件内 ...
- OPEN(SAP) UI5 学习入门系列之四:更好的入门系列-官方Walkthrough
好久没有更新了,实在不知道应该写一些什么内容,因为作为入门系列,实际上应该更多的是操作而不是理论,而在UI5 SDK中的EXPLORER里面有着各种控件的用法,所以在这里也没有必要再来一遍,还是看官方 ...
- BGP选路原则
bgp选路原则 1 最高有weight优先,默认为0(思科特有,选大的) 2 本地优先级高的优先(只可以在IBGP邻居之间传递) 3 起源本路由器上的路由(network.aggregate-addr ...
- 6.二元查找树的后序遍历结果[PostOrderOfBST]
[题目] 输入一个整数数组,判断该数组是不是某二元查找树的后序遍历的结果.如果是返回true,否则返回false. 例如输入5.7.6.9.11.10.8,由于这一整数序列是如下树的后序遍历结果: 8 ...
- 【测试工具】tcpdump + wireshark 抓包实践
Tcpdump + Wireshark 抓包实践 工具介绍 Tcpdump 看到dump大家应该有所意识吧,就是下载数据,抓数据.tcpdump是linux下的一个抓取tcp包的命令 Usage: t ...
- crt,excrt学习总结
\(crt,Chinese\ Remainder\ Theorem\) 概述 前置技能:同余基础性质,\(exgcd\). \(crt\),中国剩余定理.用于解决模数互质的线性同余方程组.大概长这样: ...
- Codeforces 914H Ember and Storm's Tree Game 【DP】*
Codeforces 914H Ember and Storm's Tree Game 题目链接 ORZ佬 果然出了一套自闭题 这题让你算出第一个人有必胜策略的方案数 然后我们就发现必胜的条件就是树上 ...
- 百度地图API秘钥生成步骤
百度API