第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试。所以我们讲下伪分布式安装hadoop.
我们继续上一章继续讲解,安装完先试试SSH装上没有,敲命令,注意:这个安装是hadoop伪分布式的安装,配置集群我在后面讲!!!!!!!!
ls -a

如果没有ssh,输入命令
ssh 查看
ssh localhost

其实这个代表已经装上了
如果没有在进行下面的命令:
sudo apt-get install openssh-server 下载
mkdir .ssh 自己创建ssh
chmod 777 .ssh
代表安装上了ssh,接下来我们要为虚拟机分配一个静态的ip
一:配置静态IP
1. sudo -i 获取最高用户级别
2.nano /etc/network/interface,把IP改成静态的,加上address,netmask,gateway,修改完以后ctrl+o保存,
然后回车,ctrl+x切换到输入行。

3.nano /etc/resolv.conf

4.reboot 重新启动
启动完把网络转成桥接网卡,试试看能不能上网,如果网不能上,你在查看下第3步有没有改成功。
在这里我们假设可以OK上网了
做好准备工作,下载jdk-7u3-linux-i586.tar 这个软件包和hadoop-1.1.2-1374045102000.tar软件包
二:配置JDK
1.tar zxvf jdk-7u3-linux-i586.tar.gz 解压jdk
tar zxvf hadoop-1.1.2-1374045102000.tar.gz 解压hodoop
2.sudo -i
3.nano /etc/profile,在最下面加入这几句话,保存

验证jdk是否安装成功,敲命令
java

javac

这样就代表jdk安装成功了。
三:配置SSH 免密码登陆
1。sudo -i
2.ssh-keygen -t dsa -P ' ' -f ~/.ssh/id_dsa
ssh-keygen代表生成密钥,-t代表指定生成的密钥类型,dsa代表密钥类型,-P代表提供密语
-f代表生成的密钥文件

3.cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
4.ssh localhost 没有让你输入密码就代表ssh装成功了
或者 ls .ssh/ 看看有没有那几个文件

四。配置Hadoop
上面已经解压完hadoop
1.sudo -i
2.nano /home/tree/hadoop-1.1.2/conf/hadoop-env.sh 指定JDK的安装位置
在文本最下面加入export JAVA_HOME=/home/tree/jdk1.7.0_03

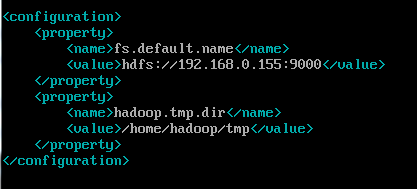
3.nano /home/tree/hadoop-1.1.2/conf/core-site.xml 修改核心文件
我这里设置的IP是192.168.0.153,这个图是之前的图,大家见谅
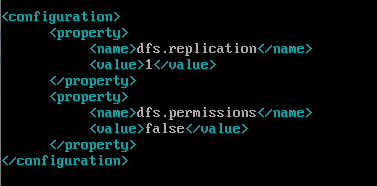
4.nano /home/tree/hadoop-1.1.2/conf/hdfs-site.xml 修改HDFS配置,配置的备份
方式默认是3,在单机版本中,需要将其改为1
5.nano /home/tree/hadoop-1.1.2/conf/mapred-site.xml MapReduce的配置文件,配置
jobTracker的地址及端口
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.0.153:9001</value>
</property>
</configuration>
6.chown -R tree:tree /home/tree/hadoop-1.1.2 给用户赋予权限
注意:我这个是在ubuntu系统操作下执行的,如果想在centOS系统执行,就不用切换当前用户,后面都用root用户
7.exit 返回到tree用户 。centOS不用返回,直接用root用户格式化
8.cd /home/tree/hadoop-1.1.2/
9.bin/hadoop namenode -format 需要格式化Hadoop文件系统HDFS,记住,格式化一次就可以了,以后修改哪里都不需要在格式化了,记住,上面
配置都正确就可以格式化了。如果格式化失败,找到出现的问题,比如无法解析域名等等(centOS系统要修改hosts文件),问题解决后,要先把创建的
临时文件删除(core-site.xml 中你设置临时文件的目录,用 rm -ef 临时文件位置 命令删除),在格式化。
10.bin/start-all.sh 输入命令,启动所有线程
bin/stop-all.sh 输入命令,关闭所有线程
验证Hadoop是否安装成功,打开网页,输入:
http://localhost:50030 (MapReduce的web页面)

http://localhost:50070 (HDFS的web页面)

如果只想启动HDFS (bin/start-dfs.sh)或者MapReduce(bin/start-mapred.sh),输入命令就可以了
一般启动完以后,可以通过jps查看各个状态

五:配置HBase
首先,先到HBase官网上下载http://www.apache.org/dyn/closer.cgi/hbase/ ,下载hbase-0.94.13.tar.gz 版本
注意:安装hadoop的时候,要注意hbase的版本,如果hadoop与hbase不匹配会影响hbase系统的稳定性。在hbase的lib目录下有对应的hadoop的jar文件,
如果想使用其它hadoop版本,那么需要将hadoop系统安装目录hadoop-*.*.*-core.jar文件和hadoop-*.*.*-test.jar复制到hbase的lib文件夹下,以
替换其它版本的hadoop.
1.tar zxvf hbase-0.94.13.tar.gz 解压HBase
2. sudo -i 获取最高用户级别
3.nano /home/tree/hbase-0.94.13/conf/hbase-env.sh 也需要指定JDK位置
在文本最下面加入export JAVA_HOME=/home/tree/jdk1.7.0_03

4.nano /home/tree/hbase-0.94.13/conf/hbase-site.xml
配置 hbase-site.xml, 这里将 hbase.rootdir 存放在 HDFS 上,这里端口号一定要和之前设置的 HDFS的 fs.default.name的端口号一致。
这样hbase就配置好了。

5. 注意点
由于这样的配置,HBase是依赖与HDFS的文件系统的。所以应当先启动HDFS,之后启动HBase。所以,切记,一定要先启动Hadoop,并且可以通过 http://localhost:50070/dfshealth.jsp 查看HDFS并且可以浏览文件之后再启动HBase。否则 HBase也会出现一切问题,如启动时间过长,Master一直在初始化等等。
如何启动HDFS命令上面已经讲过了,启动完HDFS以后,页面也正常,再启动HBase
cd /home/tree/hbase-0.94.13/
bin/start-hbase.sh
启动完以后,查看运行状态
- 如果你需要对HBase的日志进行监控你可以查看 hbase.x.x./logs/下的日志文件,可以使用tail -f 来查看。
- 通过 web方式查看运行在 HBase 下的zookeeper http://localhost:60010/zk.jsp
- 如果你需要查看当前的运行状态可以通过web的方式对HBase服务器进行查看,输入http://localhost:60010/master-status 如图所示:


删除文件夹的命令 rm -rf 文件名
使用: bin/hbase shell 进入HBase命令行模式

进入hbase shell,输入help之后,可以获取hbase shell 所支持的命令。

第二章 伪分布式安装hadoop hbase的更多相关文章
- 第七章 伪分布式安装hive,sqoop
第一部分:先讲这么去安装hive.先去hive官网下载,我这里以hive-0.12.0为例子. 前面第二章讲了安装hadoop,hbase实例,我们继续讲这么安装hive,先说下hive配置文件 一, ...
- 指导手册02:伪分布式安装Hadoop(ubuntuLinux)
指导手册02:伪分布式安装Hadoop(ubuntuLinux) Part 1:安装及配置虚拟机 1.安装Linux. 1.安装Ubuntu1604 64位系统 2.设置语言,能输入中文 3.创建 ...
- 伪分布式安装Hadoop
Hadoop简单介绍 Hadoop:适合大数据分布式存储与计算的平台. Hadoop两大核心项目: 1.HDFS:Hadoop分布式文件系统 HDFS的架构: 主从结构: 主节点,只有一个:namen ...
- CentOS 6.5 伪分布式 安装 hadoop 2.6.0
安装 jdk -openjdk* 检查安装:java -version 创建Hadoop用户,设置Hadoop用户使之可以免密码ssh到localhost su - hadoop ssh-keygen ...
- Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用. 环境 操作系统 Centos 6.5_64bit 本机名称 hadoop001 本机IP ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- HBase基础和伪分布式安装配置
一.HBase(NoSQL)的数据模型 1.1 表(table),是存储管理数据的. 1.2 行键(row key),类似于MySQL中的主键,行键是HBase表天然自带的,创建表时不需要指定 1.3 ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
随机推荐
- c# 多线程调用窗体上的控件 示例
private delegate void InvokeCallback(string msg); private void SetCountValue(string s) { if (this.fo ...
- 依存可视化︱Dependency Viewer——南京大学自然语言处理研究组
来源网页:http://nlp.nju.edu.cn/tanggc/tools/DependencyViewer.html 视频演示网页:http://nlp.nju.edu.cn/tanggc/to ...
- charles抓包--手机端
Fiddler和charles都是抓包工具,可以抓到pc端的请求,手机上设置代理后也可以抓到手机上的请求,也可以修改请求数据和返回的数据. 在接口已经使用的时候,比如说已经用到了app上,app端测试 ...
- Java 保存对象到文件并恢复 ObjectOutputStream/ObjectInputStream
1.从inputFile文件中获取内容,读入到set对象: 2.然后通过ObjectOutputStream将该对象保存到outputFile文件中: 3.最后通过ObjectInputStream从 ...
- 错误:XMLHttpRequest cannot load
原因:Chrome浏览器不支持本地ajax访问,具体就是ajax不能访问file 有3种解决办法:http://frabbit2013.blog.51cto.com/1067958/1254285 其 ...
- 在tableView中设置cell的图片和文字
// 设置UITableViewCellEditingStyle的 accessoryType UITableViewCellAccessoryNone, // d ...
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- scrapy与scrapyd安装
Scrapy是用python编写的爬虫程序. Scrapyd是一个部署与运行scrapy爬虫的应用,提供JSON API的调用方式来部署与控制爬虫 . 本文验证在fedora与centos是安装成功. ...
- shell脚本中执行sql的例子
这个例子演示了如何在shell脚本中执行多个sql来操作数据库表. #! /bin/sh USER_HOME=/home/`whoami` . /etc/profile if [ -f ${USER_ ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...