Python全栈day14-15-16-17(函数)
一,数学定义的函数
函数的定义:给定一个数集A,对A施加对应法则f,记作f(A),得到另一数集B,也就是B=f(A)。那么这个关系式就叫函数关系式,简称函数。函数概念含有三个要素:定义域A、值域C和对应法则f。其中核心是对应法则f,它是函数关系的本质特征。
二,Python定义函数
def test(x):
#"comment"
x += 1
return x #def:定义函数的关键字
#test函数名称
#(内可定义形参)
#注释(非必要但是强烈建议添加描述信息)
#x += 1 处理逻辑
#return定义返回值
#调用运行 可以带参数也可以不带参数
三,为什么要有函数
1,代码重用
2,保持一致性
3,易维护
四,函数和过程
过程就是没有返回值的函数
举例说明
vim day14-4.py
def test01():
msg = 'Hello The little green frog'
print(msg) def test02():
msg = 'Hello ZhangSan'
print(msg)
return msg t1 = test01()
t2 = test02() print ('From test01 rerurn is [%s]' %t1)
print ('From test02 return is [%s]' %t2) Hello The little green frog
Hello ZhangSan
From test01 rerurn is [None]
From test02 return is [Hello ZhangSan]
可以看到test01是没有返回值的返回None,test02是有返回值的
函数可以有多个返回值如果返回值数=0 返回None 返回值数=1 返回为返回值本身 返回值>1 返回一个以返回值为元素的一个元祖
五,函数的参数
1,形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后不能再使用该形参变量
2,实参可以是常量,变量,表达式,函数等,无论实参是何种类型的量,在进行函数调用时,他们必须有确定的值,以便把这些值传递给形参。因此应预先赋值
举例说明
vim day14-6.py
def calc(x,y):
res = x**y
return res a = 2
b = 3
c = calc(a,b)
print(c) 8
x,y为形参a,b为实参
PS:函数遇到return马上结束,只要有一个return只返回第一个return后面不运行
位置参数和关键字
标准调用实参于形参一一对应,关键字调用位置无需按照顺序但是也是必须一一对应,也可以混搭但是位置参数必须在关键字参数左边
vim day14-7.py
def test(x,y,z):
print(x)
print(y)
print(z) test(1,2,3)
test(x=1,z=3,y=2)
test(1,2,z=3)
1
2
3
1
2
3
1
2
3
默认参数(默认一个值如果不赋值就是默认值如果有赋值就是赋值的)
def handle(x,type='mysql'):
print()
print(type) handle('hello',type='sql') sql
参数组,非固定长度参数
def test(x,*args):
print(x)
print(args) test(1,2,3,4,5,6) 1
(2, 3, 4, 5, 6)
1作为参数传递给x了,后面作为元祖传递
返回字典
def test(x,**kwargs):
print(x)
print(kwargs) test(1,y=2,z=3) 1
{'z': 3, 'y': 2}
六,局部变量与全局变量
顶头写的变量就是全局变量,在任何位置都可以调用
name = 'zhangsan' def change_name():
print(name)
change_name() zhangsan
局部变量是定义在函数或者其他内部的变量,只在函数内部有效,如果局部变量于全局变量冲突在函数内部优先使用局部变量
name = 'zhangsan' def change_name():
name = '我最帅'
print(name)
change_name() 我最帅
可以在函数内部通过global参数定义全局变量
name = 'zhangsan' def change_name():
global name
name = 'lisi'
print(name) def change_name1():
print(name)
change_name()
change_name1() lisi
lisi
先执行change_name 里面重新定义了全局变量name并且修改了name的值为lisi所以再次调用change_name1函数的时候name的值为lisi,如果把执行顺序掉过来则先输出是zhangsan然后输出lisi
name = 'zhangsan' def change_name():
global name
name = 'lisi'
print(name) def change_name1():
print(name)
change_name1()
change_name() zhangsan
lisi
PS:如果函数内部没有global关键字则在函数内部只能读取该变量,无法重新赋值,但是对于可变对象可以对内部元素操作比如append等,在内部赋值操作也是针对该局部变量非全局变量。
如果函数中有global关键字表示当前局部的变量其实是全局变量,可以修改及赋值。
代码规范:全局变量全部用大写,局部变量使用小写,就不会有冲突出现了
进一步理解全局变量与局部变量
函数的执行顺序,当定义一个函数的时候不会调用到内存里面执行,只有在调用的的时候才会执行,看以下列子,函数里面嵌套函数以及函数的执行顺序
vim day15-2.py
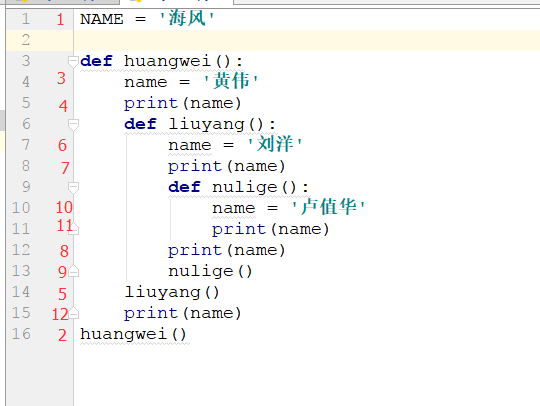
NAME = '海风' def huangwei():
name = '黄伟'
print(name)
def liuyang():
name = '刘洋'
print(name)
def nulige():
name = '卢值华'
print(name)
print(name)
nulige()
liuyang()
print(name)
huangwei() 黄伟
刘洋
刘洋
卢值华
黄伟
为什么输出是这个下面一步步解释
1,定义全局变量NAME赋值为'海风'
2,调用huangwei函数
3,执行huangwei函数的内部程序定义局部变量name赋值为'黄伟'
4,执行huangwei函数内部程序打印name值为‘黄伟’(输出第一行黄伟)
5,执行huangwei函数内部程序调用函数liuyang
6,执行liuyang函数内部程序定义局部变量name值为'刘洋'
7,执行liuyang函数内部程序打印name值为‘刘洋’(输出第二行刘洋)
8,执行liuyang函数内部程序打印name值为‘刘洋’(输出第三行刘洋)
9,调用nulige函数
10,执行nulige函数内部程序定义局部变量name值为
11,执行nulige函数内部程序打印name值为‘卢值华’(输出第四行卢值华)
12,执行huangwei函数内部传递打印name因为已经跳出其他函数这里的name值为‘黄伟‘(输出第五行黄伟)
在看一个在函数内部定义全局变量的列子
vim day15-3.py
name = '度娘' def weihou():
name = "陈卓"
def weiweihou():
global name
name = "冷静"
weiweihou()
print(name) print(name)
weihou()
print(name) 度娘
陈卓
冷静
以下是执行顺序

1,定义全局变量name值为‘度娘‘
2,打印name(输出第一行度娘)
3,调用函数weihou
4,执行函数weihou内部程序定义局部变量name值为‘陈卓‘
5,调用函数weiweihou
6,在函数内部定义全局变量name
7,修改全局变量name的值为‘陈卓‘
8,打印变量name,这里的name值为‘陈卓‘因为局部变量优先于局部变量(输出第二行陈卓)
9,打印全局变量name由于在函数weiweihou内部重新赋值了这里打印的为冷静(输出第三行冷静)
七,前向引用
看以下列子
def bar():
print('from bar')
def foo():
print('from foo')
bar()
foo() from foo
from bar
1,调用foo函数先输出from foo
2,foo函数调用了bar函数再输出from bar
调整函数顺序把foo函数放在前面
def foo():
print('from foo')
bar()
def bar():
print('from bar')
foo() from foo
from bar
1,调用foo函数输出from foo
2,虽然bar函数定义在foo函数后面但是已经执行在内存里面只是假如没有运行foo函数就没有调用而已,运行了foo也就调用了bar函数输出from bar
调整顺序把调用函数foo放在中间
def foo():
print('from foo')
bar()
foo()
def bar():
print('from bar')
运行会报错,因为调用foo函数的时候还没有定义到bar函数
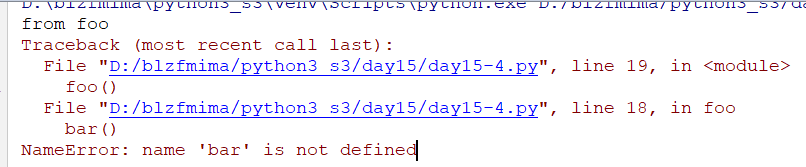
理论:函数及变量,def定义函数的时候把里面的代码当成是字符串全部放在内存里面所以即使里面有的函数并没有定义也不会报错。
八,函数递归
在函数内部可以调用其他函数,如果调用自己就是递归
import time
def calc(n):
print(n)
time.sleep(2)
calc(n)
calc(10)
没隔两秒无限循环输出传入的参数,如果设置sleep则会运行不断无限循环超出内存极限直至报错
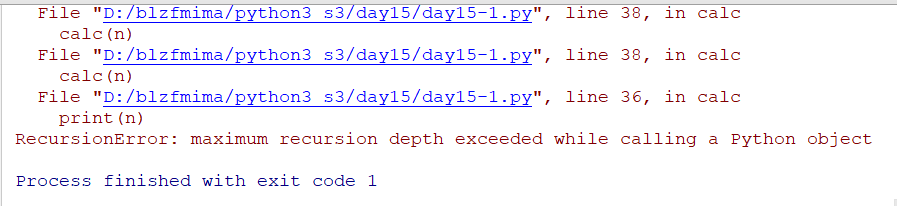
看以下递归函数
vim day15-5.py
def calc(n):
print(n)
if int(n/2) == 0:
return n
return calc(int(n/2)) calc(10) 10
5
2
1
1,调用函数参数为10,打印10 (输出第一行10)
2,判断条件10/2取整数为5不等于0,不满足if条件
3,递归调用此时参数为5,打印5(输出第二行5)
4,判断条件5/2取整数为2不等于0,不满足if条件
5,递归调用此时参数为2,打印2(输出第三行2)
6,判断条件2/2取整数为1,不满足if条件
7,递归调用此时参数为1,打印1(输出第四行1)
8,判断条件1/2取整数为0,满足if条件返回值为参数1,退出函数。如果这里加一个n变量等于calc(10)则最后n的值为1
递归特性
1,必须有一个明确的结束条件
2,每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3,递归效率不高,递归层次过多会导致栈溢出
以下递归模拟一个问路过程
vim day15-6.py
import time person_list = ['zhangsan','lisi','xiaohong']
def ask_way(person_list):
print('-'*60)
#如果问路的列表人数为空还没有遇到知道路的人则返回没人知道路
if len(person_list) == 0:
return '没人知道在哪里'
person = person_list.pop(0)
#xiaohong知道在哪里遇到xiaohong就返回结果
if person == 'xiaohong':
return '%s说:我知道,东莞就在远方' %person print('hi 美男[%s],东莞在哪里' %person)
print('%s回答道:我不知道,你等着我帮你问问%s...' %(person,person_list))
#暂停sleep一秒钟,模拟问路过程
time.sleep(1)
res = ask_way(person_list)
print('%s问的结果是: %s' %(person,res))
return res res = ask_way(person_list)
print(res) hi 美男[zhangsan],东莞在哪里
zhangsan回答道:我不知道,你等着我帮你问问['lisi', 'xiaohong']...
------------------------------------------------------------
hi 美男[lisi],东莞在哪里
lisi回答道:我不知道,你等着我帮你问问['xiaohong']...
------------------------------------------------------------
lisi问的结果是: xiaohong说:我知道,东莞就在远方
zhangsan问的结果是: xiaohong说:我知道,东莞就在远方
xiaohong说:我知道,东莞就在远方
1,定义问路人员列表为person_list为['zhangsan','lisi','xiaohong']
2,定义问路函数ask_way把里面的代码值为字符串写入内存但是不执行
3,执行函数ask_way参数为列表person_list返回值赋给变量res
4,第一次调用函数ask_way判断传入的列表是否为空,如果是空则打印没人知道在哪里,这里列表为['zhangsan','lisi','xiaohong']非空,不执行if下面语句
5,删除列表第一个元素既zhangsan并且把值赋给person=zhangsan
6,判断问路的人是否是xiaohong如果是则返回问路结果,不是xiaohong执行打印此时person为zhangsan列表删除了第一个元素为['lisi', 'xiaohong']
7,递归调用函数ask_way把列表['lisi', 'xiaohong']作为参数传递给函数,返回给res变量,假设为res['zhangsan']
8,第二次调用函数ask_way判断传入的列表是否为空,如果是空则打印没人知道在哪里,这里列表为['lisi','xiaohong']非空,不执行if下面语句
9,删除列表第一个元素既lisi并且把值赋给person=lisi
10,判断问路的人是否是xiaohong如果是则返回问路结果,不是xiaohong执行打印此时person为lisi列表删除了第一个元素为['xiaohong']
11,递归调用函数ask_way把列表['xiaohong']作为参数传递给函数,返回给res变量,假设为res['lisi']
12,第二次调用函数ask_way判断传入的列表是否为空,如果是空则打印没人知道在哪里,这里列表为['xiaohong']非空,不执行if下面语句
13,删除列表第一个元素既lisi并且把值赋给person=xiaohong
14,判断问路的人是否是xiaohong如果是则返回问路结果为‘ xiaohong说:我知道,东莞就在远方’ 并且把这个结果返回给res[lisi]
15,函数跳回上一层并且把res结果返回给res[zhangsan]
16,函数跳回上一层并且res结果返回得到最终的问路结果并且打印
递归原理图如下
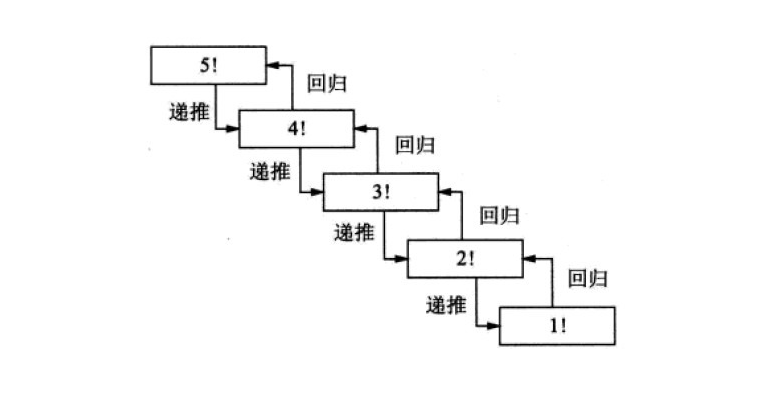
九,函数作用域
一个函数的返回值可以是另外一个函数的函数名,返回的是该函数的地址,可以加()执行
vim day16-2.py
name = 'zhangsan'
def foo():
name = 'lisi'
def bar():
print(name)
return bar
a = foo() #把foo函数执行的结果返回给变量a
print(a) #打印变量a因为foo()返回的是函数bar所以这里打印的是一个内存地址
a() #a加()及执行 相当于运行了bar函数 打印print(name)为lisi <function foo.<locals>.bar at 0x00000235842C6950>
lisi
不管在那个位置调用函数,但是函数的作用域是在该函数定义时的作用域所以这里打印出来的是lisi
看一下更加绕的例子
vim day16-3.py
name = 'zhangsan' def foo():
name = 'lisi'
def bar():
name = 'wangwu'
def tt():
print(name)
return tt
return bar func = foo() #执行函数foo把函数bar的内存地址赋值给变量func
print(func) #打印函数bar的内存地址
func1 = func() #func保存的是函数bar的内存地址所以这里是加()执行函数bar把函数tt的内存地址返回给变量func1
print(func1) #打印函数tt的内存地址
func()()
func1() #func1加一个()的执行结果和func加两个()的运行结果是一样的 <function foo.<locals>.bar at 0x000001D86B6F6950>
<function foo.<locals>.bar.<locals>.tt at 0x000001D86BF736A8>
wangwu
wangwu
十,匿名函数
定义一个函数返回值是输入参数+1
def calc(x):
return x+1
print(calc(10)) 11
以上函数可以使用匿名函数实现,:前面是传递的参数后面是return返回值
func = lambda x:x+1
print(func) #打印是函数的内存
print(func(10)) #传递参数打印结果11 11
PS:1,用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数
2,匿名函数只有一行代码内部不能有复杂逻辑
也可以有多个返回值
f = lambda x,y,z:(x+1,y+1,z+1)
print(f(1,2,3)) (2,3,4)
后面有多个返回值必须加(),否则报错,类似于函数可以有多个返回值,返回值以元祖的方式返回
十一,函数式编程
编程方法论
1,面向过程
2,函数式
3,面向对象
高阶函数
满足两个特性任意一个即为高阶函数
1,函数的传入参数是一个函数名
2,函数的返回值是一个函数名
函数式编例一 不可变:不用变量保存状态,不修改变量
vim day16-5.py
#非函数式
a = 1
def incr_test1():
global a
a+=1
return a
#改变了全局变量a的值
incr_test1()
print(a) #函数式
n = 1
def incr_test2(n):
return n+1 print(incr_test2(1))
print(n) 2
2
1
使用非函数式编程变量a的值有改变,使用函数式变量n的值没有改变
函数式编程列二:函数名作为实参传递给另外一个函数
vim day16-6.py
def foo(n):
print(n) def bar(name):
print('my name is %s' %name) foo(bar) #把函数名作为参数传递给函数foo 打印函数bar的内存地址
foo(bar('zhangsan')) #先执行bar('zhangsan')打印my name is zhangsan
#把执行bar('zhangsan')的返回值None作为参数传递给函数foo打印None
<function bar at 0x000001D287326950>
my name is zhangsan
None
函数式编程列三:函数名作为函数返回值
vim day16-7.py
def bar():
print('from bar')
def foo():
print('from foo')
return bar n = foo() #运行函数foo先打印from foo 然后把函数的返回值及函数bar的内存地址赋值给n
n() #n加()运行打印from bar from foo
from bar
函数式编程列四:尾调用,在函数的最后一步调用另外一个函数(最后一步不一定是最后一行)
vim day16-8.py
#函数bar在foo内为尾调用
def bar(n):
return n
def foo(x):
return bar(x) #函数bar1和bar2在foo内均为尾调用,二者在if条件判断条件不同的情况下均有可能作为函数的最后一步
def bar1(n):
return n def bar2(n):
return n+1 def foo(x):
if type(x) is str:
return bar1(x)
elif type(x) is int:
return bar2(x) #函数bar在foo内为非尾调用
def bar(n):
return n
def foo(x):
y = bar(x)
return y #函数bar在foo内为非尾调用
def bar(n):
return n
def foo(x):
return bar(x)+1
十二,map函数
列:一个列表为[1,2,3,4,5,6]求平方以后的值
1,使用for循环实现vim day16-9.py
num_1 = [1,2,3,4,5,6]
ret = []
for i in num_1:
ret.append(i*i) print(ret) [1, 4, 9, 16, 25, 36]
假如这样的列表有多个则需要重复代码才能实现此功能
2,使用函数实现,如果有多个列表可以减少重复代码
def map_test(array):
ret = []
for i in array:
ret.append(i**2)
return ret num_1 = [1,2,3,4,5,6]
ret = map_test(num_1)
print(ret) [1, 4, 9, 16, 25, 36]
假设对列表的处理方法有变化不是平方而是其他,比如是自增1或者自减1,可以把这张方法定义成另外的函数,然后在函数map_test传递参数的时候增加一个参数调用函数名来实现
def add_one(x):
return x+1
def reduce_one(x):
return x-1
def map_test(func,array):
ret = []
for i in array:
res = func(i)
ret.append(res)
return ret num_1 = [1,2,3,4,5,6]
ret = map_test(add_one,num_1)
print(ret) [2, 3, 4, 5, 6, 7]
这里调用的是add_one函数所以增加1 同理也可以定义平方函数等其他方法的函数
使用匿名函数实现
def add_one(x):
return x+1
def reduce_one(x):
return x-1
def map_test(func,array):
ret = []
for i in array:
res = func(i)
ret.append(res)
return ret num_1 = [1,2,3,4,5,6]
ret = map_test(lambda x:x+1,num_1)
print(ret) [2, 3, 4, 5, 6, 7]
3,使用map函数实现 (返回的是一个可以迭代的内存地址使用list方法迭代生成新的列表)
num_1 = [1,2,3,4,5,6]
res = map(lambda x:x**2,num_1)
print('内置函数map处理结果',res)
print(list(res)) 内置函数map处理结果 <map object at 0x0000025A99135940>
[1, 4, 9, 16, 25, 36]
十三,filter函数
需求有一个人员列表,要求去掉以sb开头的人
1,使用for循环实现vim day16-10.py
movie_people = ['sb_zhansan','sb_lisi','wangwu']
ret = []
for p in movie_people:
if not p.startswith('sb'): #如果不是以sb开头则把他添加到列表里面
ret.append(p)
print(ret) ['wangwu']
2,使用函数实现 vim day16-11.py
def remove_sb(list): #定义函数形参为list一个列表
ret = [] #定义一个用于接收的空列表
for p in list:
if not p.startswith('sb'):
ret.appenf(p)
return ret movie_people = ['sb_zhansan','sb_lisi','wangwu']
ret = remove_sb(movie_people)
print(ret) ['wangwu']
3,但是处理的逻辑有可能是去掉前面的也有可能是去掉后面的字符,可以把处理的逻辑写成一个函数,根据需求调用vim day16-12.py
movie_people = ['sb_zhansan','sb_lisi','wangwu'] #处理以sb开头的字符串
def sb_show(n):
return n.startswith('sb') #如果是以sb开头返回True def filter_test(func,array): #定义函数包含两个形参,第一个为函数名,第二个为传递的列表
ret=[]
for p in array:
if not func(p):
ret.append(p)
return ret res=filter_test(sb_show,movie_people)
print(res) ['wangwu']
4,使用匿名函数,因为该函数逻辑简单可以使用匿名函数简化vim day16-13.py
movie_people = ['sb_zhansan','sb_lisi','wangwu'] def filter_test(func,array):
ret=[]
for p in array:
if not func(p):
ret.append(p)
return ret res=filter_test(lambda n:n.startswith('sb'),movie_people)
print(res) ['wangwu']
5,使用filter函数vim day16-14.py
filter函数前面是一个函数,后面是一个可迭代对象,把可迭代对象依次交给函数处理,如果为True则保留结果,如果
movie_people = ['sb_zhansan','sb_lisi','wangwu']
ret = filter(lambda n:not n.startswith('sb'),movie_people)
print(ret) #ret是一个可迭代对象打印是内存地址
print(list(ret)) #使用list方法迭代出列表
['wangwu']
十四,reduce函数
需求:有一个列表num_1 = [1,2,3,4,5,6,7,8,9,10]求里面所有数字相加的结果
1,使用for循环实现vim day16-15.py
num_1=[1,2,3,4,5,6,7,8,9,10]
count = 0
for i in num_1:
count = count + i
print(count) 55
2,使用函数实现vim day16-16.py
num_1=[1,2,3,4,5,6,7,8,9,10]
def reduce_test(array):
res = 0
for num in array:
res = res + num
return res res = reduce_test(num_1)
print (res) 55
3,假如方法不同不是+可能是乘或者其他,把功能细化vim day16-17.py
num_1=[1,2,3,4,5,6,7,8,9,10] #def multi(x,y):
# return x+y
def reduce_test(func,array):
res=0
for num in array:
res=func(res,num)
return res res = reduce_test(lambda x,y:x+y,num_1)
print(res) 55
4,使用reduce函数实现,合并一个序列,得到一个结果 vim day16-18.py
num_1=[1,2,3,4,5,6,7,8,9,10]
from functools import reduce #python2可以直接使用reduce 3需要导入模块
res = reduce(lambda x,y:x+y,num_1)
print(res) 55
map,filter,reduce小结
map 处理序列中的每个元素,得到的结果是一个列表,该列表元素个数及位置与原来一样
filter 遍历序列中的每一个元素,判断元素得到布尔值,如果是True则保留,如果是False则丢弃
reduce处理一个序列并且把序列安装逻辑进行合并操作
十五,内置函数
1,abs取绝对值 abs(-2) = 2
2,all 跟一个列表对列表元素取布尔值如果全为真则返回True有一个为假则返回False
3,any跟一个列表只要里面有一个为True则返回True
4,bin把十进制转换成二进制
5,bool取字符串的布尔值,None 0 的布尔值为False其余为True
6,bytes把字符串编码打印结果 print(bytes('你好',encoding='utf-8')) b'\xe4\xbd\xa0\xe5\xa5\xbd'
7,chr根据ascii打印出对应的字符
8,dir打印某一个对象下面有哪些方法
9,divmod取商得余数print(divmod(10,3)) (3,1) 可以用于网站分页
10,enumerate把一个列表生成可迭代对象使索引于对应的元素一一对应
res = enumerate([1,2,3])
print(res)
for index,i in res:
print(index,i) <enumerate object at 0x0000025F7642DD38>
0 1
1 2
2 3
11,eval
a,把字符串中的数据结构提取出来
dic_str = "{'name':'zhangsan'}"
print(eval(dic_str))
{'name': 'zhangsan'}
b,计算表达式
express='1+2*(3/3-1)-2'
print(eval(express)) -1.0
12,hash 可hash的数据类型及不可变数据类型,不可hash的数据类型为可变数据类型
hash对象的码不会随hash值大写变化而变化
不能根据hash码反推出hash源
name = 'zhangsan'
print(hash(name))
print(hash(name))
name = 'lisi'
print(hash(name)) 5623004878365971046
5623004878365971046
-8895594236205219231
13,help查看帮助print(help(int))
14,hex十进制转换成十六进制
15,oct十进制转换成八进制
16,id打印对象内存地址
17,print打印
18,int转换成数字
19,isinstance判断是否是属于什么类型
print(isinstance(1,int)) True
20,len取长度
21,globals全局变量,locals打印局部变量
name='zhangsan'
def test():
age=18
print(globals())
print(locals())
test()
{'__spec__': None, 'name': 'zhangsan', '__doc__': None, '__cached__': None, '__file__': 'D:/blzfmima/python3_s3/day16/day16-1.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001FE6B2DF2B0>, '__builtins__': <module 'builtins' (built-in)>, 'test': <function test at 0x000001FE6B299048>, '__name__': '__main__', '__package__': None}
{'age': 18}
23,max取最大值
l = [1,2,3,4]
print(max(l)) 4
24,min取最小值
25,zip根据传递的两个列表生成一个以元祖为元素的一一对应的列表
res = zip(('a','b','c'),(1,2,3))
print(list(res))
[('a', 1), ('b', 2), ('c', 3)]
zip传递的是两组可迭代对象,下面把一个字典使用zip方法一一对应
p = {'name':'zhangsan','age':18,'gender':'none'}
res = zip(p.keys(),p.values())
print(list(res))
[('gender', 'none'), ('name', 'zhangsan'), ('age', 18)]
26,max和min的高级应用
有一个字典分别是key对应的年纪大小,需要取出里面最大的年纪
age_dic={'age1':18,'age4':20,'age3':100,'age2':30}
print(max(age_dic.values())) #把values作为可迭代对象然后用max取最大值
100
假如需要在取最大值的时候取出对应的keys 可以使用以上的zip方法,把对应的年纪和key生成一一对应的列表然后使用max比较
这里把年纪放在前面了,优先比较前面的
age_dic={'age1':18,'age4':20,'age3':100,'age2':30}
print(max(age_dic.values()))
print(max(list(zip(age_dic.values(),age_dic.keys()))))
100
(100, 'age3')
PS:比较的数据类型必须相同,否则报错
需求:有一个列表包含多个字典,需要比较取出年纪最大那个字典
people = [
{'name':'zhangsan','age':18},
{'name':'lisi','age':19},
{'name':'wangwu','age':20}
] res = max(people,key=lambda dic:dic['age'])
print(res) {'age': 20, 'name': 'wangwu'}
如果是直接输入max(people)会报错,因为迭代出来的元素是字典,但是字典是无法进行比较的,这里使用了max函数的key参数指定比较的key 后面跟一个匿名函数dic返回值是对应的年纪
27,ord根据字符转换成ascii码
print(ord('a'))
97
28,pow
a,传递两个参数求幂
print(pow(3,3)) 27
b,传递三个参数前两位求幂,再对最后一位取余数
print(pow(3,3)) 1
29,range产生等差序列
30,reversed反转(原序列顺序不变)
l = [1,2,3]
print(list(reversed(l))) [3,2,1]
31,round 四舍五入
32,set把迭代对象转换成集合
33,定义切片方法,先把切片方法定义,便于修改,也可以加参数对应切片步长
l = 'hello'
s1 = slice(3,5)
print(l[s1]) lo
34,sorted排序,用法和max,min及其类似 (a,原序列不变 b,排序本质就是在比较大小,不同类型的数据无法排序)
l = [3,2,3,1,7]
print(sorted(l))
print(l) [1, 2, 3, 3, 7]
[3, 2, 3, 1, 7]
35,str转换成字符串
36,sum求和
37,tuple转换成元祖
38,type显示数据的类型
39,vars如果没有加参数打印locals变量,如果有参数打印方法,以字典的模式
40,import导入模块,模块其实就是一个py文件 可以把其他py文件写好的方法直接拿过来调用
import不能导入字符串,__import__可以导入字符串
Python全栈day14-15-16-17(函数)的更多相关文章
- Python全栈之路4--内置函数--文件操作
上节重点回顾: 判断对象是否属于某个类,例如: 列表中有个数字,但是循环列表判断长度,用len会报错;因为int不支持len,所以要先判断属于某个类,然后再进行if判断. # isinstance(对 ...
- python全栈开发-Day13 内置函数
一.内置函数 注意:内置函数id()可以返回一个对象的身份,返回值为整数. 这个整数通常对应与该对象在内存中的位置,但这与python的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以 ...
- python全栈开发-前方高能-内置函数2
python_day_15 一.今日主要内容 1. lambda 匿名函数 语法: lambda 参数:返回值 不能完成复杂的操作 2. sorted() 函数 排序. 1. 可迭代对象 2. key ...
- Python全栈工程师(集合、函数)
ParisGabriel 感谢 大家的支持 你们的阅读评价就是我最好的动力 我会坚持把排版内容以及偶尔的错误做的越来越好 每天坚持 一天一篇 点个订阅吧 灰常感谢 ...
- Python全栈开发之16、jquery
一.查找元素 1.选择器 1.1 基本选择器 $("*") $("#id") $(".class") $("ele ...
- Python全栈day14(字符串格式化)
一,%字符串格式化 1,使用%s 后面一一对应输入对应的字符串,%s可以接受任何参数 print ("I am %s hobby is zhangsan"%'lishi') pri ...
- python全栈开发 * 15知识点汇总 * 180621
#15 函数二 与 匿名函数1.dir() # 查看内置属性,将对象所有方法名放在另一个列表中.dic={"水果":"香蕉",'蔬菜':"土豆&quo ...
- 巨蟒python全栈开发-第10天 函数进阶
一.今日主要内容总览(重点) 1.动态传参(重点) *,** *: 形参:聚合 位置参数*=>元组 关键字**=>字典 实参:打散 列表,字符串,元组=>* 字典=>** 形参 ...
- 巨蟒python全栈开发-第16天 核能来袭-初识面向对象
一.今日内容总览(上帝视角,大象自己进冰箱,控制时机) #转换思想(从面向过程到面向对象) 1.初识面向对象 面向过程: 一切以事物的发展流程为中心. 面向对象: 一切以对象为中心,一切皆为对象,具体 ...
- Python全栈day14(集合)
一,集合 1,集合由不同元素组成 2,无序 3,集合中元素必须是不可变类型 二,定义集合 1,s = {1,2,3,4,5} 2,s = set(hello)以迭代的方式生成集合 s = set(&q ...
随机推荐
- ubuntu下将CapsLock改为Ctrl键
需求:Ubuntu下用Vim时,ESC因为在左上角,还算是好按,但是Ctrl就太坑了,在左右两个下角,实在是太不方便了. 经过分析决定将:CapsLock键改为Ctrl,但仍然保留下面的原Ctrl键( ...
- NGUI和UGUI动画不能设置alpha值的问题
动画播放alpha参数改变但无实际画面效果,原因是要挂一个脚本,设置实时更新数据. NGUI void Update() { widget.SetDirty(); } UGUI void Update ...
- atitit.html5 vs 原生 app的区别与选择
atitit.html5 vs 原生 app的区别与选择 1. html5的优点 1 1.1. 最大优势::在跨平台(ios苹果,android安卓等) 1 1.2. 开放性 1 1.3. 快速的更 ...
- [svc]nginx-module-vts第三方模块安装配置
参考: https://github.com/vozlt/nginx-module-vts#installation https://github.com/kubernetes/ingress-ngi ...
- [svc]执行sudo时报错:effective uid is not 0
http://jingyan.baidu.com/article/c45ad29cd83d4b051753e232.html 今天将 / 授权给了一个普通用户 导致一些问题. 启事: 操作前一定要先在 ...
- python 使用urllib.urlopen超时问题的解决方法
准备写一个python脚本抓取网页数据,前面抓了几个都没有什么问题,但总会抓取不完整,在中间过程中没有反应,发现执行urlopen的地方总是提示超时,百度了一下,因为我使用的是urllib不是urll ...
- 改变placeholder的样式
input::-webkit-input-placeholder{ font-size:12px; color:#d2d2d2 }
- Spring Cloud心跳监测
Spring Cloud实现心跳监测,在服务注册和停止时,注册中心能得到通知,并更新服务实例列表 Spring Cloud注册中心添加配置: eureka.server.enable-self-pre ...
- SAP安装前添加虚拟网卡步骤
添加虚拟网卡: 打开控制面版中的设备管理器 点击菜单栏上的[操作(A)] 选择[添加过时硬盘件] 选择[ 安装我手动从列表选择的硬件(高级)(M) ],点击[下一步] 选择[网络适配器],点击[下一步 ...
- 一款基于jQuery的图片左右滑动焦点图
今天给大家分享一款基于jQuery的焦点图插件,这款jQuery焦点图插件的特点是可以多张图片左右滑动切换,可以点击切换按钮进行图片滑动,同时也支持图片自动切换.另外,这款jQuery焦点图是宽屏的, ...