Job流程:Mapper类分析
此文紧接Job流程:决定map个数的因素,Map任务被提交到Yarn后,被ApplicationMaster启动,任务的形式是YarnChild进程,在其中会执行MapTask的run()方法。无论是MapTask还是ReduceTask都是继承的Task这个抽象类。
1). Mapper类中 setup() 和 cleanup() 两个方法负责 map 任务的 初始化 和 清理工作(默认是空实现)
2). Mapper类中 run() 方法负责调用用户自定义的 map()方法。最主要的代码在于while()循环。其中,Context类是一个内部类,继承自MapContext接口,间接继承自TaskInputOutputContext类。此类中有一个nextKeyValue()抽象方法,用于将Inputsplit解析成一个个的键值对。在其子类MapContextImpl中提供了具体的解析实现。
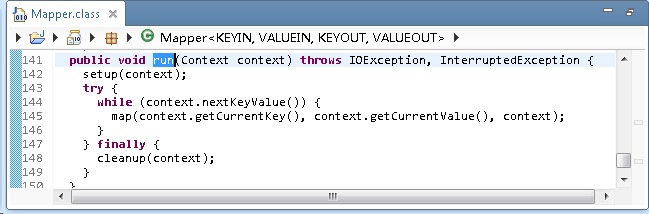
其中,reader是RecordReader类的一个实例。可以看出:map解析Inputsplit成一个个键值对是通过调用RecordReader类的nextKeyValue()方法完成的。
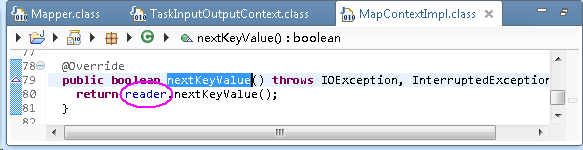
3). map结果是通过context.write()方法写入内存,实际是写入MapOutputBuffer类中。在此类实例化的第一个阶段是初始化init()过程,会根据配置信息初始化内存buf:
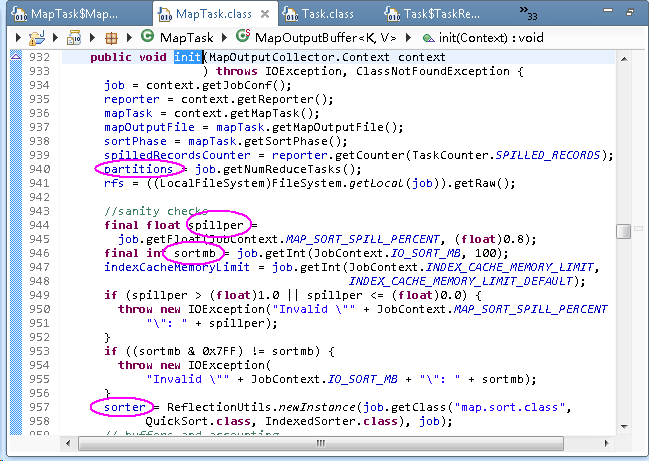
- partition:读取job中设置的分区个数,默认为1.
- sortmb:内存buf的大小,默认100MB
- spillper:内存buf的阀值,默认0.8,即100*0.8=80MB
- indexCacheMemoryLimit:内存index的大小。默认为1024*1024
- sorter:对mapper输出的key的排序,默认是快排QuickSort
MR执行流程
1) 客户端提交一个MapReduce的JAR包给JobClient(提交方式:hadoop jar ...),JobClient就是提交节点
2) JobClient通过RPC协议和RM进行通信,返回一个JobId和存放JAR包的HDFS路径
3) JobClient使用FileSystem将JAR包写入到HDFS当中(path = hdfs上的地址 + JobId)。默认10份(mapreduce.client.submit.file.replication),运行结束会被删掉。
4) 开始提交MR任务,提交任务的描述信息(不是JAR包,而是JobId,JAR存放的位置,配置信息等)给RM。
5) RM进行初始化任务。将任务的描述信息存放进调度器(默认是队列调度器)之中,NM通过心跳HeartBeat机制向RM领取任务。NM领取任务之后,NM启动相应的子进程ApplicationMaster运行任务
6) ApplicationMaster读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
7) NM通过HeartBeat心跳机制继续领取任务资源(任务的描述信息)
8) 下载所需的JAR包,配置文件等
9) NM启动一个子进程yarn-child,用来执行具体的子任务(MapperTask或ReducerTask)
10) 将最终结果写入到HDFS当中
Job流程:Mapper类分析的更多相关文章
- 源码分析篇 - Android绘制流程(三)requestLayout()与invalidate()流程及Choroegrapher类分析
本文主要探讨能够触发performTraversals()执行的invalidate().postInvalidate()和requestLayout()方法的流程.在调用这三个方法到最后执行到per ...
- [Hadoop源码解读](二)MapReduce篇之Mapper类
前面在讲InputFormat的时候,讲到了Mapper类是如何利用RecordReader来读取InputSplit中的K-V对的. 这一篇里,开始对Mapper.class的子类进行解读. 先回忆 ...
- 「Android」消息驱动Looper和Handler类分析
Android系统中的消息驱动工作原理: 1.有一个消息队列,可以往这个消息队列中投递消息; 2.有一个消息循环,不断的从消息队列中取得消息,然后处理. 工作流程: 1.事件源将待处理的消息加入到消息 ...
- 支付宝app支付java后台流程、原理分析(含nei wang chuan tou)
java版支付宝app支付流程及原理分析 本实例是基于springmvc框架编写 一.流程步骤 1.执行流程 当手机端app(就是你公司开发的app)在支付 ...
- C++卷积神经网络实例:tiny_cnn代码具体解释(8)——partial_connected_layer层结构类分析(上)
在之前的博文中我们已经将顶层的网络结构都介绍完毕,包括卷积层.下採样层.全连接层,在这篇博文中主要有两个任务.一是总体贯通一下卷积神经网络在对图像进行卷积处理的整个流程,二是继续我们的类分析.这次须要 ...
- okhttp同步请求流程和源码分析
在上一次[http://www.cnblogs.com/webor2006/p/8022808.html]中已经对okhttp的同步与异步请求的基本使用有了一了初步了解,这次来从源码的角度来分析一下同 ...
- 【Java EE 学习 69 下】【数据采集系统第一天】【实体类分析和Base类书写】
之前SSH框架已经搭建完毕,现在进行实体类的分析和Base类的书写.Base类是抽象类,专门用于继承. 一.实体类关系分析 既然是数据采集系统,首先调查实体(Survey)是一定要有的,一个调查有多个 ...
- Spring源码分析——BeanFactory体系之抽象类、类分析(二)
上一篇分析了BeanFactory体系的2个类,SimpleAliasRegistry和DefaultSingletonBeanRegistry——Spring源码分析——BeanFactory体系之 ...
- Android的消息循环机制 Looper Handler类分析
Android的消息循环机制 Looper Handler类分析 Looper类说明 Looper 类用来为一个线程跑一个消息循环. 线程在默认情况下是没有消息循环与之关联的,Thread类在ru ...
随机推荐
- JRebel插件安装配置与破解激活(多方案)详细教程
JRebel 介绍 IDEA上原生是不支持热部署的,一般更新了 Java 文件后要手动重启 Tomcat 服务器,才能生效,浪费不少生命啊.目前对于idea热部署最好的解决方案就是安装JRebel插件 ...
- URI 、URL 和 URN
URI URI 是 Uniform Resource Identifier 的缩写. Uniform 统一不同类型的资源.比如 txt.mp3.jpeg 等不同的类型的资源都可以使用 URI 来标识 ...
- Spark Streaming Programming Guide
参考,http://spark.incubator.apache.org/docs/latest/streaming-programming-guide.html Overview SparkStre ...
- 剑指Offer——求1+2+3+...+n
题目描述: 求1+2+3+...+n,要求不能使用乘除法.for.while.if.else.switch.case等关键字及条件判断语句(A?B:C). 分析: 递归实现. 代码: class So ...
- Linux的概念与体系(转)
学linux就用它了 http://www.cnblogs.com/vamei/archive/2012/10/10/2718229.html
- java-mybaits-00301-SqlMapConfig
1.配置内容 mybatis的全局配置文件SqlMapConfig.xml,SqlMapConfig.xml中配置的内容和顺序如下: properties(属性) settings(全局配置参数) t ...
- 缓存系统MemCached的Java客户端优化历程
Memcached 是什么? Memcached是一种集中式Cache,支持分布式横向扩展.这里需要解释说明一下,很多开发者觉得Memcached是一种分布式缓存系统,但是其实Memcached服务端 ...
- 深入理解Oracle调试事件:10046事件详解
10046事件是SQL_TRACE的扩展,被戏称为"吃了兴奋剂的SQL_TRACE" 有效的追踪级别: ① 0级:SQL_TRACE=FASL ...
- [golang note] 内建类型
基础类型 √ golang内建基础类型有布尔类型.整数类型.浮点类型.复数类型.字符串类型.字符类型和错误类型. 复合类型 √ golang支持的复合类型有指针.数组.数组切片.字典.通道.结构体和接 ...
- Mysql—(2)—
数据库存储引擎 (更多详见) 一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存 ...