hadoop之存储篇
---持续更新中,可留言讨论---
--题目导航见页面左上角的悬浮框#目录导航#--
一、目录:
- 集群规划
- HDFS HA
- 冒烟测试
- 功能特性
二、集群规划:
- 负载类型
- 容量规划
- 可扩展性
- 角色分离
- 管理节点
- Master节点
- Worker节点
- 边缘节点
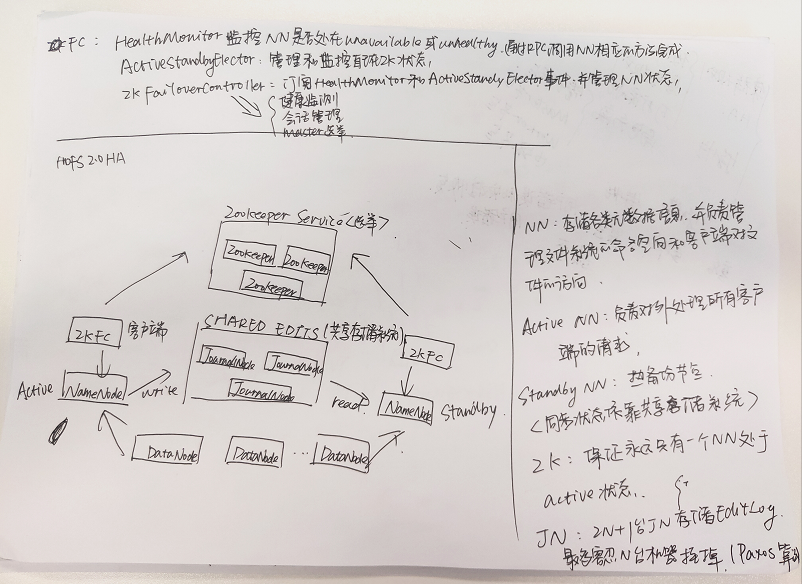
三、HDFS HA(高可用)
架构原理见下图:
四、冒烟测试:
详细说明参见之前的博客:https://www.cnblogs.com/huxinga/p/9627084.html
五、功能特性:
- HDFS Balancer
- 快照 Snapshots
- 配额 Quota
- 权限 ACLs
- 存储策略
- 集中缓存管理
- 机架感知
- Erasure Coding
- Memory as Storage
- Short-Circuit Local Reads
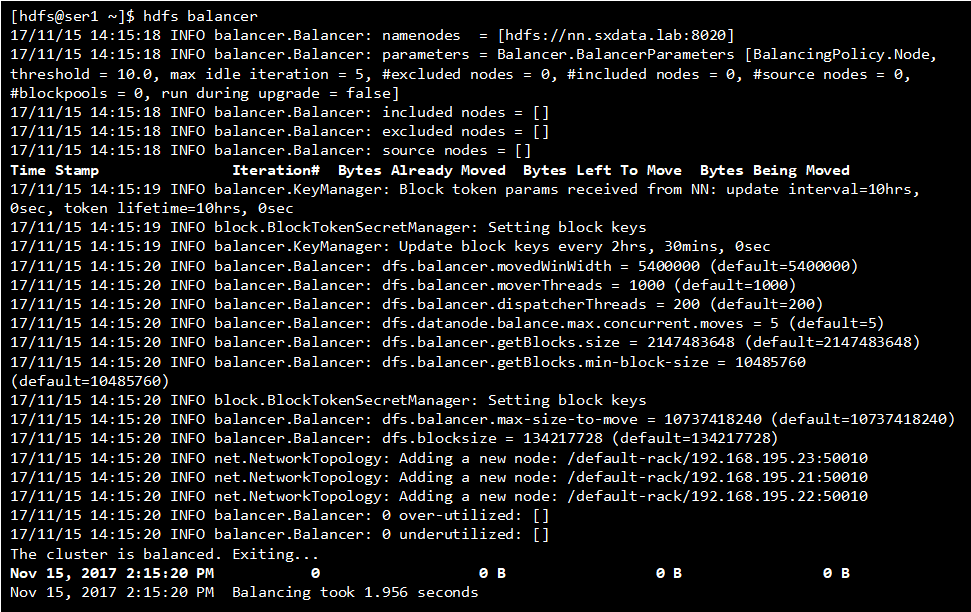
5.1 HDFS Balancer
balancer是当hdfs集群中一些datanodes的存储要写满了或者有空白的新节点加入集群时,用于均衡hdfs集群磁盘使用量的一个工具。
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点。当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等。可见,保证HDFS中的数据平衡是非常重要的。在Hadoop中,包含一个Balancer程序,通过运行这个程序,可以使得HDFS集群达到一个平衡的状态
参考命令:
hdfs balancer
hdfs dfsadmin [-setBalancerBandwidth <bandwidth in bytes per second>]
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value></value>
</property>
5.2 快照 snapshots
HDFS快照是文件系统的只读时间点的副本。可以在文件系统的子树或整个文件系统上拍摄快照。快照的一些常见⽤例是数据备份,防⽌用户错误和灾难恢复。
HDFS中可以对目录创建Snapshot,创建之后不管后续目录发生什么变化,都可以通过snapshot找回原来的文件和目录结构。
实现原理:
实现上是通过在每个目标节点下面创建snapshot节点,后续任何子节点的变化都会同步记录到snapshot上。例如删除子节点下面的文件,并不是直接文件元信息以及数据删除,而是将他们移动到snapshot下面。这样后续还能够恢复回来。另外snapshot保存是一个完全的现场,不仅是删除的文件还能找到,新创建的文件也无法看到。后一种效果的实现是通过在snapshot中记录哪些文件是新创建的,查看列表的时候将这些文件排除在外。
参考命令:
# 为指定目录开启快照功能
hdfs dfsadmin -allowSnapshot <path>
# 列出开启了快照功能的目录
hdfs lsSnapshottableDir
# 创建快照
hdfs dfs -createSnapshot <path> [<snapshotName>]
# ⽐较两个快照之间的区别
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
# 列出快照内的⽂文件
hdfs dfs -ls /foo/.snapshot
# 从快照中恢复数据。
此处使用了了preserve选项来保留时间戳、所有权、权限、ACL 和 XAttrs扩展属性
hdfs dfs -cp -ptopax /foo/.snapshot/s0/bar /tmp

例子分析:
我们通过一个例子来分析整个snapshot的实现细节:
1. 文件目录树如下图所示,并且我们已经通过命令启动了a的snapshot功能,结构如下图所示:

图中.snapshot是虚拟节点,保存了所有的snapshot列表,其中diff中还保存当前节点下面的变化,一个snapshot对应于一个diff.要注意的是snapshot中可以被多个目录的diff引用,后续会进行说明。
2. 当我们执行createSnapshot命令时,结果如下: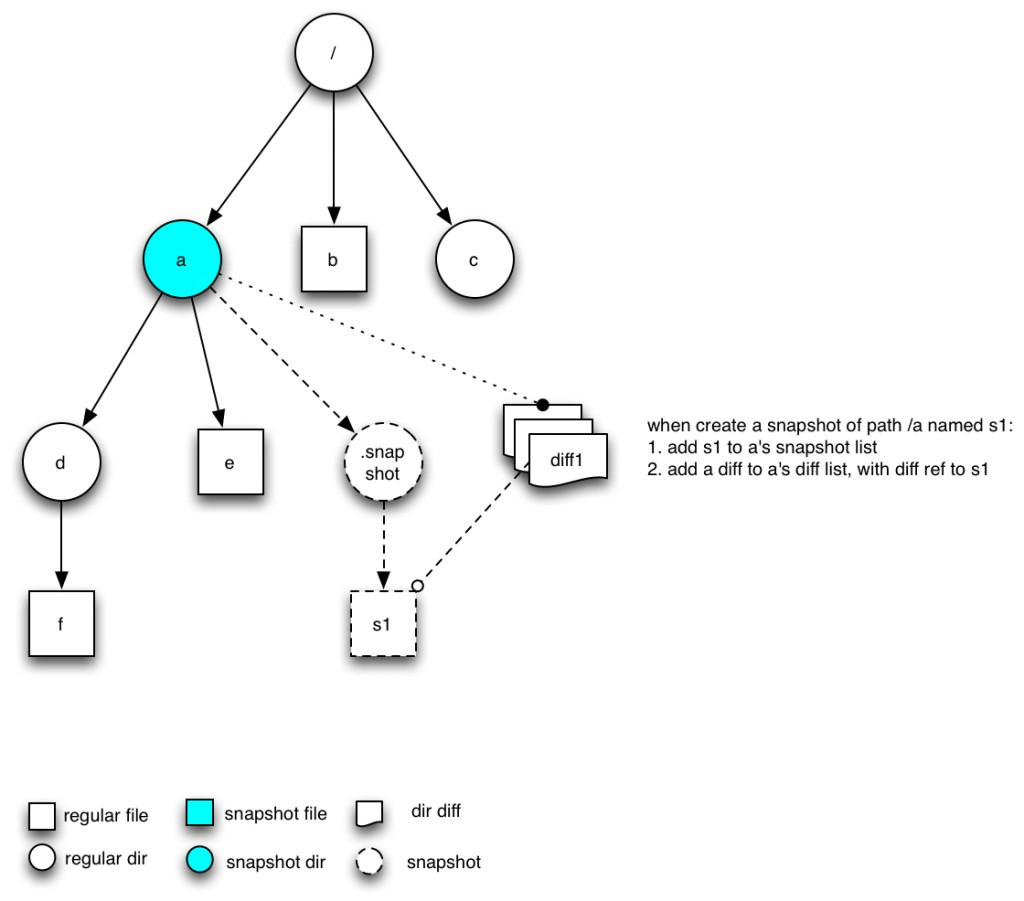
3. 当删除文件e的时候
不论是删除一个文件还是一个目录,只要是直接子节点,都会将节点转换为快照版本.例如e会变成INodeFileWithSnapshot,在a的DirectoryDiff中ChildDiff中deleted列表中将会包含e,而在a的正常节点下会被删除。目录节点的处理同样。
4. 删除孙子节点是的情况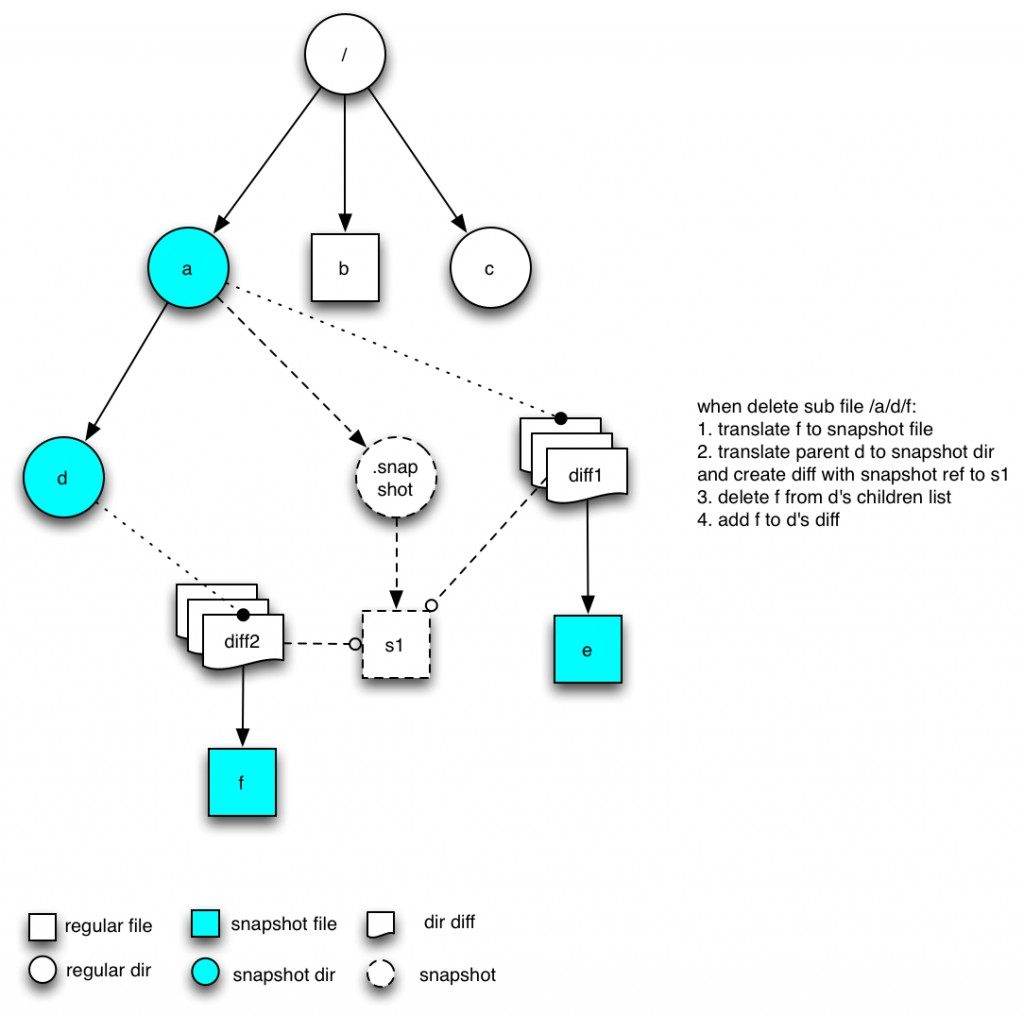
处理这种节点的原则是:先将孙子节点转变为Snapshot版本,然后将父节点变为snapshot版本,同时将孙子节点版本加入到直接父节点的diff列表中。为了能够通过同一个snapshot找到当时的文件,需要将新的diff指向到老的snapshot版本上。图中d节点是INodeDirectoryWithSnapshot(不是INodeDiretorySnapshottable, 本身不允许在d上创建snapshot)
5.3 配额 Quata
Name Quotas :
Name Quota 是该目录下所有文件和目录总的数量的硬限制。如果超出配额,文件和目录创建将失败。配额为1会强制目录保持为空。 重命名后依然有效
Space Quotas :
Space Quota 是该目录下所有文件使用的字节数的硬限制。如果配额不允许写入完整块,则块分配将失败。块的每个副本都会计入配额。 最好设置空间大小为快的整数倍。空间配额为0时可以创建文件,但不能向文件中写入内容,单位为BYTE。
存储类型配额 :
存储类型配额是该目录中文件使用特定存储类型(SSD,DISK,ARCHIVE)的硬限制
参考命令:
hdfs dfsadmin -setQuota <N> <directory>...<directory>
hdfs dfsadmin -clrQuota <directory>...<directory>
hdfs dfsadmin -setSpaceQuota <N> <directory>...<directory>
hdfs dfsadmin -clrSpaceQuota <directory>...<directory>
hdfs dfsadmin -setSpaceQuota <N> -storageType <storagetype> <directory>...<directory> hdfs dfsadmin -clrSpaceQuota -storageType <storagetype> <directory>...<directory>
hadoop fs -count -q [-h] [-v] [-t [comma-separated list of storagetypes]] <directory>...<directory
5.4 HDFS ACLs
ACLs主要是给指定的用指定目录分配指定的权限
首先需要了解chmod命令详情,参考我之前的博客:https://www.cnblogs.com/huxinga/p/9946464.html
HDFS支持POSIX ACL(访问控制列表),启用HDFS ACLs:
dfs.namenode.acls.enabled = true
参考命令:
hdfs dfs [generic options] -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]
hdfs dfs [generic options] –setfacl --set <acl_spec> <path>
hdfs dfs [generic options] -getfacl [-R] <path>
5.5 存储策略
存储类型:
- DISK-普通磁盘,存储
- SSD -SSD盘
- RAM_DISK 内存盘
- ARCHIVE -归档/压缩,不是实际的磁盘类型,而是数据被压缩存储。
存储策略:
- Hot - 存储和计算都热。 如果是热快,那么复制的目标也是DISK(普通的磁盘)。
- Cold -用于有限计算的存储。 数据不再使用,或者需要归档的数据被移动到冷存储。如果数据块是冷的,则复制使用ARCHIVE.
- Warm -半冷半热。warm块的复制内容,部分放置在DISK,其它的在ARCHIVE.
- All_SSD - 所有数据存储在SSD.
- One_SSD - 一个复制在SSD,其它的在DISK.
- Lazy_Persist -只针对只有一个复制的数据块,它们被放在RAM_DISK,之后会被写入DISK。
当有足够空间的时候,块复制使用下表中第三列所列出的存储类型。
如果第三列的空间不够,则考虑用第四列的(创建的时候)或者第五列的(复制的时候)
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | <none> | ARCHIVE |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | <none> | <none> |
LAZY_PERSIST策略只用于复制一个块
文件/路径的存储策略按照如下规则解析:
如果有设定特定的策略,那么就是那个策略
如果没有设定,就返回上级目录的存储策略。如果是没有策略的根目录,那么返回默认的存储策略(hot-编号7的)。
HDFS MOVER-一个新的数据迁移工具:
这个工具用户归档数据,它类似于Balancer(移动数据方面)。MOVER定期扫描HDFS文件,检查文件的存放是否符合它自身的存储策略。如果数据块不符合自己的策略,它会把数据移动到该去的地方。
语法
hdfs mover [-p <files/dirs> | -f <local file name>]
-p 指定要迁移的文件/目录,多个以空格分隔
-f 指定本地一个文件路径,该文件列出了需要迁移的文件或者目录(一个一行)
如果不指定参数,那么就移动根目录

参考命令:
列出所有存储策略:
hdfs storagepolicies -listPolicies
设置存储策略:
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
取消存储策略:
hdfs storagepolicies -unsetStoragePolicy -path <path>
获取存储策略:
hdfs storagepolicies -getStoragePolicy -path <path>
5.6 集中式缓存管理
概念:
第一层是缓存,即为存储在HDFS中文件提供缓存的机制,从而可以加速DFSClient对文件的读操作;
第二层概念是集中式的管理,传统的HDFS缓存依赖了OS本身的缓存机制,但是这种缓存机制不能被管理员或中央节点进行管理,不能自由的控制哪些文件缓存,哪些文件不进行缓存;集中式的管理可以提高了对缓存内存的可控性
原理架构:
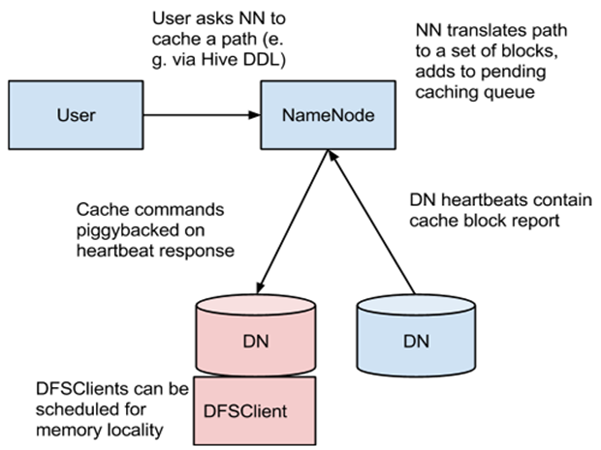
1、User通过api入口与NN进行交互,告诉NN缓存哪些文件,或者取消对那些文件的缓存;
2、NN中维护了缓存path列表;在每次接受到User的缓存请求时候,把请求的Path转化为一系列的Blocks,并把这些Blocks加入到一个待cache的队列中
3、在DN中缓存的真实内容是Blocks,在DN每次心跳协议与NN进行交互时候,NN会把属于该DN的缓存的Blocks放在心跳协议的返回值中返回给DN,DN进行缓存中
4、同时DN维持一个NN之间类似心跳协议的定时协议,定时同步DN中缓存Block的状态;
5、DFSClient在读取缓存中的文件Blocks时,可以直接从Cache中读取;
HDFS集中缓存两个主要概念:Cache Directive和Cahce Pool
1、Cache Directive:一个directive是一个缓存的path,它可以是目录,也可以是文件;注意:目录的缓存是非递归的,只缓存目录内第一层的文件,不会缓存目录中目录;一个Directive有一个参数replication,表示该path的缓存的副本数;注意,可以对一个文件进行多次缓存;一个Directive有一个参数expiration,可以控制缓存的TTL(time-to-live),目前该时间为绝对时间,可以表示为分钟,小时和天数,比如 -ttl 30m, 4h, 2d。 测试显示一个cache过期了,NN不会自动将它从缓存列表中删除,只是在不再反馈给DFSClient进行读操作,cache的内存是否会自动释放,待测试; 测试结果表示不会释放内存,所以过期的cache,还是需要手动的去删除它;
2、Cache Pool:是Cache的管理单元,每个Pool拥有与Unix相似的权限,同时Pool也有quota limit限制(磁盘使用情况和限额)。
配置:
<property>
<name>dfs.datanode.max.locked.memory</name>
<value></value>
</property>
必须配置,单位为byte,默认该值为0,从描述中可以看到。如果该值为0,相当于关闭了集中缓存的功能;
参考命令:
hdfs cacheadmin -addPool <name>
[-owner <owner>] [-group <group>] [-mode <mode>]
[-limit <limit>] [-maxTtl <maxTtl>]
hdfs cacheadmin -addDirective -path <path> -pool <pool-name>
[-force] [-replication <replication>] [-ttl <time-to-live>]
1、Pool控制:可以通过"hdfs cacheadmin -addPool"创建一个pool,“hdfs cacheadmin -modifyPool”删除一个pool,"hdfs cacheadmin -removePool"删除一个pool,“ hdfs cacheadmin -removePool”删除一个pool。
2、Directive控制:集中缓存中一个文件是否会被缓存,完全用管理员来控制,管理员可以通过" hdfs cacheadmin -addDirective"来添加缓存,该命令会返回一个缓存id;“hdfs cacheadmin -removeDirective”通过该命令来删除指定缓存id的缓存;“ hdfs cacheadmin -removeDirectives”通过该命令来删除指定缓存path的缓存,该命令可以一次删除多个缓存;“hdfs cacheadmin -listDirectives”显示当前所有的缓存;详细的参数,在命令行中输入 hdfs cacheadmin可以看得到;
或者参考:http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html 官方文档 。
5.7 机架感知
Hadoop在设计时考虑到数据的安全,数据文件默认在HDFS上存放三份。显然,这三份副本肯定不能存储在同一个服务器节点。那怎么样的存储策略能保证数据既安全也能保证数据的存取高效呢?
HDFS分布式文件系统的内部有一个副本存放策略:以默认的副本数=3为例:
1、第一个副本块存本机
2、第二个副本块存跟本机同机架内的其他服务器节点
3、第三个副本块存不同机架的一个服务器节点上
好处:
1、如果本机数据损坏或者丢失,那么客户端可以从同机架的相邻节点获取数据,速度肯定要比跨机架获取数据要快。
2、如果本机所在的机架出现问题,那么之前在存储的时候没有把所有副本都放在一个机架内,这就能保证数据的安全性,此种情况出现,就能保证客户端也能取到数据
HDFS为了降低整体的网络带宽消耗和数据读取延时,HDFS集群一定会让客户端尽量去读取近的副本,那么按照以上面解释的副本存放策略的结果:
1、如果在本机有数据,那么直接读取
2、如果在跟本机同机架的服务器节点中有该数据块,则直接读取
3、如果该HDFS集群跨多个数据中心,那么客户端也一定会优先读取本数据中心的数据
机架感知就是使HDFS确定两个节点是否是统一节点以及确定的不同服务器跟客户端的远近。
在默认情况下,HDFS集群是没有机架感知的,也就是说所有服务器节点在同一个默认机架中。那也就意味着客户端在上传数据的时候,HDFS集群是随机挑选服务器节点来存储数据块的三个副本的。
那么假如默认情况下的HDFS集群,datanode1和datanode3在同一个机架rack1,而datanode2在第二个机架rack2,那么客户端上传一个数据块block_001,HDFS将第一个副本存放在dfatanode1,第二个副本存放在datanode2,那么数据的传输已经跨机架一次(从rack1到rack2),然后HDFS把第三个副本存datanode3,此时数据的传输再跨机架一次(从rack2到rack1)。显然,当HDFS需要处理的数据量比较大的时候,那么没有配置机架感知就会造成整个集群的网络带宽的消耗非常严重。
1、增加datanode节点
增加datanode节点,不需要重启namenode
非常简单的做法:在topology.data文件中加入新加datanode的信息,然后启动起来就OK
2、节点间距离计算
有了机架感知,NameNode就可以画出下图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离,得到最优的存放策略,优化整个集群的网络带宽均衡以及数据最优分配。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R2/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
参考命令:
<property>
<name>net.topology.script.file.name</name>
<value>/etc/hadoop/conf/rack-topology.sh</value>
</property>
5.8 Erasure Coding
减少数据存储资源的使用,同时保证节点级、机架级容错
- RS算法,默认为RS(6,3),需⾄少9个节点、9个机架才能同时满足节点级、机架级容错
- 条带化
优点:
- 客户端缓存数据较少
- 无论文件大小都适用
缺点: - 会影响一些位置敏感任务的性能,因为原先在一个节点上的块被分散到了多个不同的节点上
- 和多副本存储策略转换比较麻烦
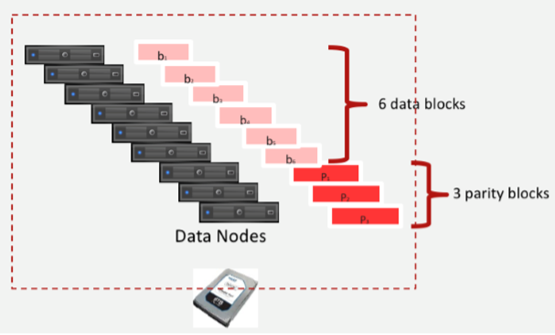
通常情况下,HDFS多备份机制存储数据,一个块是128M,加上备份,一起是128M*3,允许同时丢失2个数据块。
优点:
- 容易实现
- 方便和多副本存储策略进行转换
缺点:
- 需要客户端缓存足够的数据块
- 不适合存储小文件
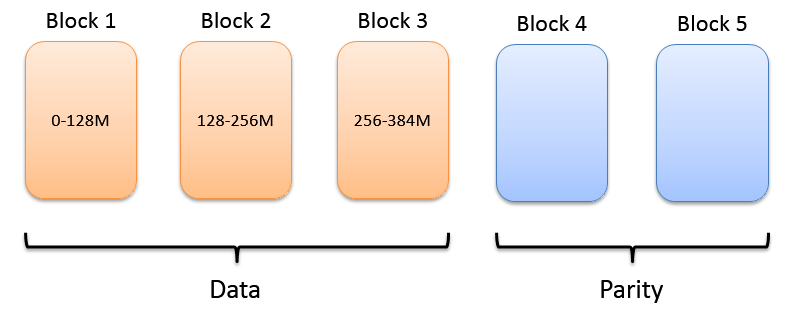
而采用EC的情况下,默认是RS(6,3),就是说将一个块128M的数据分为6份,每份大概21M,以条带化的形式存储到6个数据节点上,同时通过RS算法生成3个校验数据。EC就是这9个数据允许丢失3及以下的情况下还能保证数据的完整恢复。图片以RS(3,2)举例。
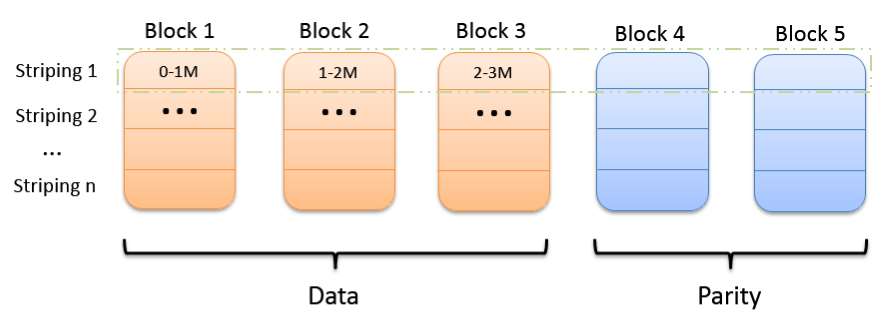
EC的优点是提高了空间利用率,通常采用的HDFS多备份机制每个块一共需要128M*3的空间(允许丢失2块),而EC仅需要21M*6+21M*3的空间(21M*3为生成的3个校验数据所占的空间)
说到这里我想到:1 .EC是以时间换空间的技术,所有的存储技术不是时间换空间,就是空间换时间 2. 计算HDFS多备份机制最少保留的数据量为128M*3*1/3=128M,而采用EC机制最少保留的数据量为(128+64)*2/3 =128M,所以说无论是什么数据存储技术,允许丢失的数据量=总数据-原数据
我怎么这么厉害!!
参考代码:
hdfs erasurecode [generic options]
[-setPolicy [-p <policyName>] <path>]
[-getPolicy <path>]
[-listPolicies]
5.9 Memory as Storage:
HDFS支持写入由数据节点管理的堆外内存。数据节点将异步刷新内存中的数据到磁盘,从而从性能敏感的IO路径中删除昂贵的磁盘IO和校验和计算,因此我们将这种写入称为Lazy Persist。 HDFS为Lazy Persist Writes提供尽力而为的持久性保证。在将副本持久保存到磁盘之前,如果节点重新启动,则可能会丢失数据。应用程序可以选择使用Lazy Persist Writes来换取一些持久性保证,以减少延迟。
换一个通俗的解释,好比我有个内存数据块队列,在队列头部不断有新增的数据块插入,就是待存储的块,因为资源有限 ,我要把队列尾部的块,也就是早些时间点的块持久化到磁盘中,然后才有空间腾出来存新的块.然后形成这样的一个循环,新的块加入,老的块移除,保证了整体数据的更新.
HDFS的LAZY_PERSIST内存存储策略架构原理如下图所示:

1,对目标文件目录设置StoragePolicy为LAZY_PERSIST的内存存储策略。
2,客户端进程向NameNode发起创建/写文件的请求。
3,然后将数据写入具体的DataNode。
4,DataNode将数据写入RAM内存中。
5,启动异步线程服务将数据持久化到磁盘中。
内存的异步持久化存储,就是明显不同于其他介质存储数据的地方.这应该也是LAZY_PERSIST的名称的源由吧,数据不是马上落盘,而是”lazy persisit”懒惰的方式,延时的处理.
参考命令:
1、设置内存值,此值与MemoryStorage共享,且必须⼩小于/etc/security/limits.conf中的配置值
dfs.datanode.max.locked.memory
2、挂载MEM磁盘,并写⼊入/etc/fstab中
$ sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/
3、为MEM磁盘添加标签:RAM_DISK
dfs.datanode.data.dir = [RAM_DISK]/mnt/dn-tmpfs
4、设置存储策略略
$ hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
5.10 Short-Circuit Local Reads
基于Hadoop的一大原则:移动计算比移动数据的开销小。在HDFS中,读取通常通过DataNode。因此,当客户端要求DataNode读取文件时,DataNode从磁盘读取该文件并通过TCP套接字将数据发送到客户端。所谓的“短路”读取绕过DataNode,允许客户端直接读取文件。显然,这只有在客户端与数据位于同一位置的情况下才有可能。短路读取为许多应用提供了显着的性能提升。
解决:读取数据的客户端DFSclient和提供数据的DataNode在同一节点的情况下,绕开DN自己去读数据,可以提升性能。
参考命令:
dfs.client.read.shortcircuit = true
dfs.domain.socket.path = /var/lib/hadoop-hdfs/dn_socket
hadoop之存储篇的更多相关文章
- android之存储篇——SQLite数据库
转载:android之存储篇_SQLite数据库_让你彻底学会SQLite的使用 SQLite最大的特点是你可以把各种类型的数据保存到任何字段中,而不用关心字段声明的数据类型是什么. 例如:可以在In ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - 声明式事务管理
文章目录 1. 声明式事务 2. Spring Boot默认集成事务 3. 实战演练4. 源代码 3.1. 实体对象 3.2. DAO 相关 3.3. Service 相关 3.4. 测试,测试 本文 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - ElasticSearch
文章目录 1. 版本须知 2. 环境依赖 3. 数据源 3.1. 方案一 使用 Spring Boot 默认配置 3.2. 方案二 手动创建 4. 业务操作5. 总结 4.1. 实体对象 4.2. D ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - MongoDB
文章目录 1. 环境依赖 2. 数据源 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 3. 使用mongoTemplate操作4. 总结 3.1. 实体对象 3 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - Redis
文章目录 1. 环境依赖 2. 数据源 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 3. 使用 redisTemplate 操作4. 总结 3.1. 工具类 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - JPA整合
文章目录 1. 环境依赖 2. 数据源 3. 脚本初始化 4. JPA 整合方案一 通过继承 JpaRepository 接口 4.1. 实体对象 4.2. DAO相关 4.3. Service相关 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - MyBatis整合
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. MyBatis整合5. 总结 4.1. 方案一 通过 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - 数据访问与多数据源配置
文章目录 1. 环境依赖 2. 数据源 3. 单元测试 4. 源代码 在某些场景下,我们可能会在一个应用中需要依赖和访问多个数据源,例如针对于 MySQL 的分库场景.因此,我们需要配置多个数据源. ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - MySQL
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. 使用JdbcTemplate操作5. 总结 4.1. ...
随机推荐
- CS小分队第二阶段冲刺站立会议(5月30日)
昨日成果:解决了前天遗留的问题,实现了主界面对于电脑上应用的添加和删除 遇到问题:添加和删除按钮时候,按钮位置图像与北京图片冲突,会出现闪动现象. 删除是通过右键单击出现菜单,其中有删除的选项,但是这 ...
- CS小分队第一阶段冲刺站立会议(5月13日)
昨日成果:昨日由于课程满课,未进行项目的制作 遇到困难:/ 今天计划:为2048和扫雷添加游戏音效,和组员一起合作对扫雷进行外观美化,学习程序生成时渐隐等特效
- Numpy and Pandas
安装 视频链接:https://morvanzhou.github.io/tutorials/data-manipulation/np-pd/ pip install numpy pip instal ...
- Scrum 项目 5.0
5.0--------------------------------------------------- 1.团队成员完成自己认领的任务. 2.燃尽图:理解.设计并画出本次Sprint的燃尽图的理 ...
- web三大组件的加载顺序
Web三大组件:过滤器组件 监听器组件 Servlet组件 过滤器的顶级接口:javax.servlet.Filter 监听器的顶级接口:javax.servlet.ServletContextL ...
- js & enter
js & enter keycode function (e) { if (e.which === 13 || e.keyCode === 13) { //code to execute he ...
- js & array to string
js & array to string https://stackoverflow.com/questions/13272406/convert-string-with-commas-to- ...
- oracle锁与死锁概念,阻塞产生的原因以及解决方案
锁是一种机制,一直存在:死锁是一种错误,尽量避免. 首先,要理解锁和死锁的概念: 1.锁: 定义:简单的说,锁是数据库为了保证数据的一致性而存在的一种机制,其他数据库一样有,只不过实现机制上可能大 ...
- CPU测试--通过proc获取CPU信息
adb shell cat /proc/stat | grep cpu > totalcpu0 此处第一行的数值表示的是CPU总的使用情况,所以我们只要用第一行的数字计算就可以了.下表解析第一行 ...
- CF816E-Karen and Supermarket
题目 Description 今天Karen要去买东西. 一共有 \(n\) 件物品,每件物品的价格为\(c_i\),同时每件物品都有一张优惠券,可以对这件物品减价 \(d_i\) . 使用第 \(i ...