SuperMap iObjects for Spark使用
本文档环境基于ubuntu16.04版本,(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
1. 基础环境搭建
基础环境搭建请参考上一篇文档:Hadoop集群+Spark集群搭建(一篇文章就够了).
2. 软件准备
SuperMap iObjects Java 9.x
(supermap-iobjectsjava-9.1.1-16827-70590-linux64-all-Bin.tar.gz)SuperMap iObjects for Spark 9.x
(supermap-spark-911-20181228.zip)
3. iObjects for Spark部署
3.1 iObjects for Spark 安装
1.下载supermap-iobjectsjava-9.1.1-16827-70590-linux64-all-Bin.tar.gz和相应的supermap-spark-911-20181228.zip组件
2.放到opt下解压,并修改名字
tar -zxvf supermap-iobjectsjava-9.1.1-16827-70590-linux64-all-Bin.tar.gz
mv Bin iobjects_new
3.新建iobjects_spark目录
mkdir /opt/iobjects_spark
4.supermap-spark-911-20181228.zip解压,将lib下的所又内容包拷贝到/opt/iobjects_spark目录中,内容如下:

3.2 iObjects for Spark配置
1.将for Spark和iObjects Java环境变量配置到/etc/profile中,结合之前hadoop和spark配置,并使用命令source /etc/profile使其生效。总配置如下
export JAVA_HOME=/opt/jdk
export JRE_HOME=/opt/jdk/jre
export HADOOP_HOME=/opt/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HIVE_HOME/bin:$JAVA_HOME/bin:$PATH
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7
export SUPERMAP_OBJ=/opt/iobjects_new
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SUPERMAP_OBJ
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/iobjects_spark
2.进入spark-2.1.0-bin-hadoop2.7/conf
编辑spark-env.sh文件,总配置如下,注意SUPERMAP_OBJ顺序
export JAVA_HOME=/opt/jdk
export SPARK_MASTER_IP=192.168.241.132
export SPARK_WORKER_MEMORY=8g
export SPARK_WORKER_CORES=4
export SPARK_EXECUTOR_MEMORY=4g
export HADOOP_HOME=/opt/hadoop-2.7.7/
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
export SUPERMAP_OBJ=/opt/iobjects_new
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SUPERMAP_OBJ:/opt/jdk/jre/lib/amd64
3.3 集群配置
主节点修改完文件后,记得scp传递到子节点中,并重启Spark服务。
scp /etc/profile root@另一台机器名:/etc/profile
3.4 实例程序验证
我们使用for Spark示例来验证是否安装成功。
3.4.1 将for Spark产品包中的示例数据放到中/opt/中。
- newyork_taxi_2013-01_14k.csv
- newyork_taxi_2013-01_14k.meta
3.4.2 将示例数据导入到hdfs中。
启动hadoop,在hadoop-2.7.7/bin中执行
./hadoop fs -mkdir /input #创建/input目录
./hdfs dfs -put /opt/newyork_taxi_2013-01_14k.csv /input/
./hdfs dfs -put /opt/newyork_taxi_2013-01_14k.meta /input/
导入完成后,可以使用如下命名查看
./hadoop fs -ls /input

3.4.3 创建文件输出文件夹
mkdir /opt/data/
3.4.4 安装所却检查依赖
可以使用iServer一键化安装依赖工具,支持(Suse、Redhat、Ubuntu)将iServer自带的support文件夹拷贝到opt下,iServer下载地址:http://support.supermap.com.cn/DownloadCenter/DownloadPage.aspx?id=1050
./dependencies_check_and_install.sh install -y
3.4.5 安装许可 (support/SuperMap_License/Support/aksusbd-2.4.1-i386)
./dinst
看到如下输出内容代表安装成功
dpkg-query: no packages found matching aksusbd
Copy AKSUSB daemon to /usr/sbin ...
Copy WINEHASP daemon to /usr/sbin ...
Copy HASPLMD daemon to /usr/sbin ...
Copy start-up script to /etc/init.d ...
Link HASP SRM runtime environment startup script to system startup folder
Starting HASP SRM runtime environment...
Starting AKSUSB daemon: .
Starting WINEHASP daemon: .
Starting HASPLM daemon: .
Coping VLIB...
Installing v2c...
Done
3.4.6 启动Spark,切换到spark-2.1.0-bin-hadoop2.7/bin下执行(点数据集网格聚合统计)
./spark-submit --class com.supermap.bdt.main.SummarizeMeshMain --master spark://master:7077 /opt/iobjects_spark/com.supermap.bdt.core-9.1.1.jar --input '{"type":"csv","info":[{"server":"hdfs://master:9000/input/newyork_taxi_2013-01_14k.csv"}]}' --meshType hexagon --bounds -74.05,40.6,-73.75,40.9 --meshSize 100 --output '{"type":"udb","server":"/opt/data/SummaryMain.udb","datasetName":"SummaryMain"}'
简单解释下命令
--class 表示主类名称,含包名,本例子指的是需要执行的类
--master Spark集群总入口
--input 简单理解为操作数据来源
--meshType 网格类型
-- bounds 范围
--output 输出路径
--meshSize 聚合范围(默认单位是米)
3.4.7 执行开始

3.4.8 执行过程中,可以访问http://192.168.241.132:4040/jobs/查看执行情况

3.4.9 执行完成后,访问/opt/data可以查看完成的内容,如果大小不为0则代表分析成功
root@master:/opt/spark-2.1.0-bin-hadoop2.7/bin# ll /opt/data/
total 2376
drwxr-xr-x 2 root root 4096 Mar 19 17:13 ./
drwxr-xr-x 11 root root 4096 Mar 19 16:43 ../
-rw-r--r-- 1 root root 1437160 Mar 19 17:13 SummaryMain.udb
-rw-r--r-- 1 root root 986112 Mar 19 17:13 SummaryMain.udd

3.4.10 将数据下载下来使用iDesktop .NET 打开查看
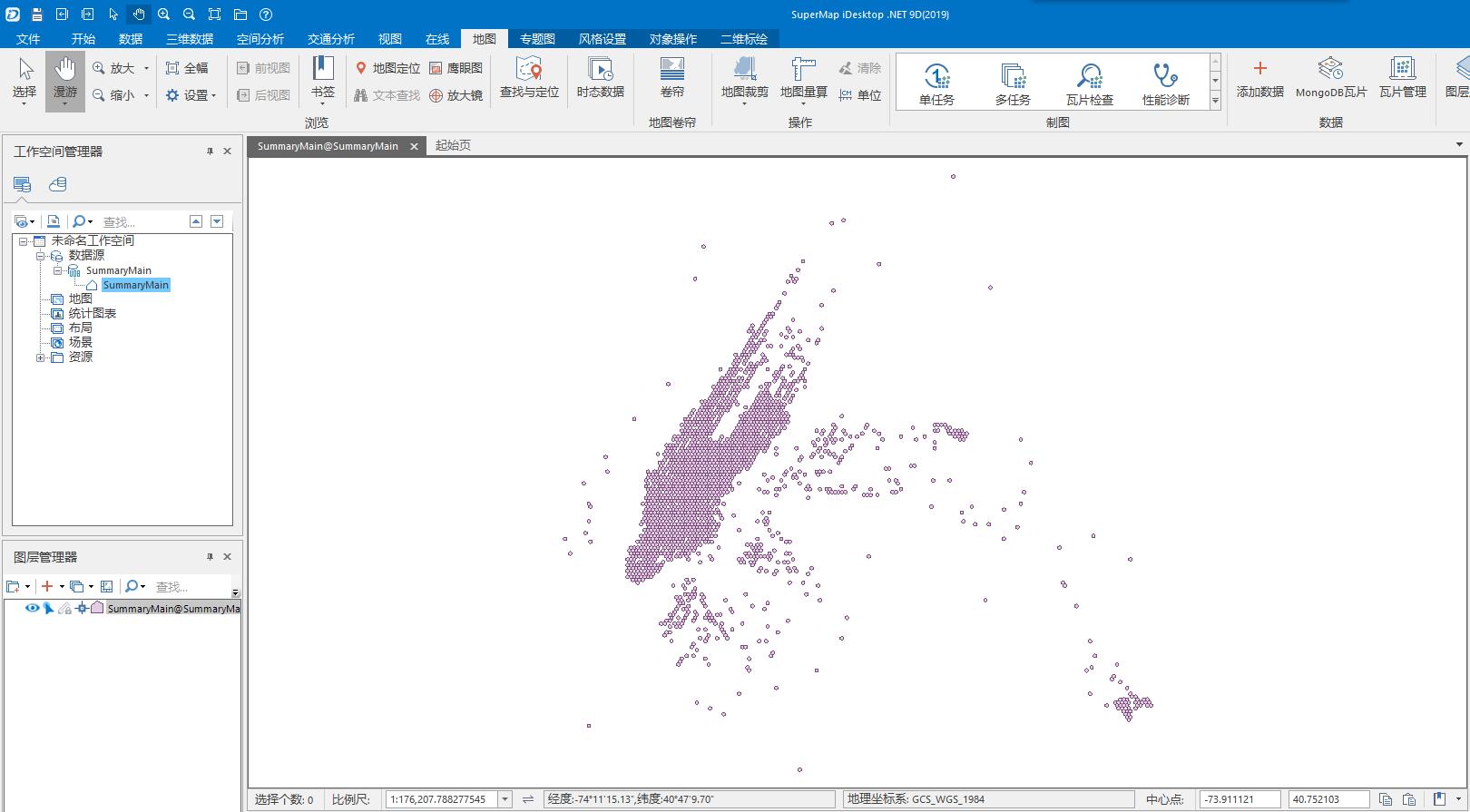
(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
SuperMap iObjects for Spark使用的更多相关文章
- 利用SuperMap iObjects.NET控件模拟小球平抛运动
1.部署SuperMap iObjects.NET控件 相关控件部署参考博客:SuperMap开发入门2--环境部署--我也是个傻瓜 2.Github项目地址 小球平抛运动项目源码 3 ...
- SuperMap iObject入门开发系列之一组件式GIS开发平台介绍
本文是一位好友“炀炀”授权给我来发表的,介绍都是他的研究成果,在此,非常感谢.平台介绍:SuperMap iObjects Java/.NET 是面向GIS应用系统开发者的组件式GIS开发平台,具有强 ...
- SuperMap 三维产品资料一览表
转自:http://blog.csdn.net/supermapsupport/article/details/68924713 如何能快速地开发项目中的三维功能呢?本文为您提供全方位的三维资料,为您 ...
- SuperMap开发入门2——环境部署
由于超图的相关资源比较少,可参考官方提供的<SuperMap iDesktop 9D安装指南>和<SuperMap iObjects .NET 9D安装指南>完成应用软件和开发 ...
- SuperMap 9D 实时数据服务学习笔记
SuperMap 在9月份发布了结合大数据技术的9D新产品,今天就和大家介绍下iServer9D中的实时数据服务. 1.技术框架 结合Spark的streaming流处理框架,将各种数据进行批量处理. ...
- SuperMap开发入门1——资源下载
前言(废话) 由于项目需要,我们将被改用超图(SuperMap)平台进行GIS开发.记忆中,我还是在学生时代使用过超图软件5.0版本,安装包只有50M,这也是超图与学校有合作关系的缘故. 在以后的学习 ...
- SuperMap iServer 9D HBase使用
需提前将HBase进行部署,参考上篇部署文档 https://www.cnblogs.com/zhangyongli2011/p/9982143.html (转发请注明出处:http://www.cn ...
- GIS+=地理信息+云计算技术——Spark集群部署
第一步:安装软件 Spark 1.5.4:wget http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
随机推荐
- [转]Android之Activity的几种跳转方式
1.显示调用方法 Intent intent=new Intent(this,OtherActivity.class); //方法1 Intent intent2=new Intent(); in ...
- [转]在eclipse打开的android虚拟手机,打开File Explorer,下面是空的没有data、mnt、system三个文件
在eclipse打开的android虚拟手机,打开File Explorer,下面是空的没有data.mnt.system三个文件 这是因为模拟器没有选择打开的缘故,必须首先打开一个模拟器(AVD), ...
- Codeforces Beta Round #6 (Div. 2 Only) D. Lizards and Basements 2 dfs
D. Lizards and Basements 2 题目连接: http://codeforces.com/contest/6/problem/D Description This is simpl ...
- linux基础命令学习(十二)yum命令
主要功能是更方便的添加/删除/更新RPM包. 它能自动解决包的倚赖性问题. 它能便于管理大量系统的更新问题 yum list|more 列出所有包文件,可搭配grep查 ...
- mysql 绿色版安装
1. 下载MySql5.6.10GA解压缩版,这就不多说也不上图了,下不到或者下好之后不知道如何解压的接下去的文章也没什么好多看的. 2. 解压好之后进入根目录是这样个情况(本人使用的是MySql5. ...
- Wifi模块的工作原理
http://www.wifitop1.com/news/content-98.html 在无线网络领域里面,无线wifi是最火的名词.对于串口wifi模块的工作是什么呢?串口wifi模块又有什么功能 ...
- TCP/IP具体解释--TCP/UDP优化设置总结& MTU的相关介绍
首先要看TCP/IP协议,涉及到四层:链路层,网络层.传输层,应用层. 当中以太网(Ethernet)的数据帧在链路层 IP包在网络层 TCP或UDP包在传输层 TCP或UDP中的数据(Data)在应 ...
- openfire Hazelcast插件集群配置
原文:http://blog.csdn.net/frankcheng5143/article/details/48708899 注意虽然hazelcast 官方已经有了3.5.2版本,但是openfi ...
- MySQL create table as与create table like对比
a.create table like方式会完整地克隆表结构,但不会插入数据,需要单独使用insert into或load data方式加载数据b.create table as 方式会部分克隆表结 ...
- sqlalchemy: TimeoutError: QueuePool limit of size 5 overflow 10 reached, connection timed out, timeout 30
mysql建立的连接要及时删除,不然连接池资源耗尽 相关文章参考: http://blog.csdn.net/robinson1988/article/details/4713294 http://b ...