C++的STL总结(2)
紧接着上篇博客,把没总结全的继续补充。
(13)set容器
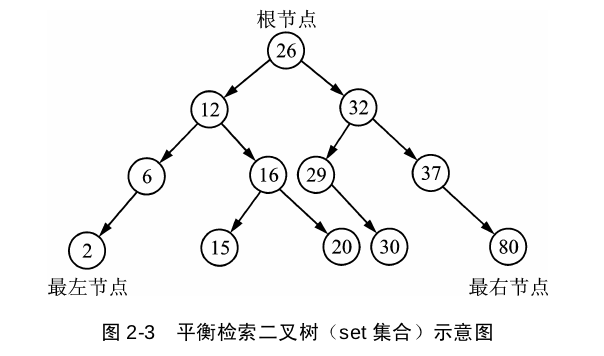
set是用红黑树的平衡二叉索引树的数据结构来实现的,插入时,它会自动调节二叉树排列,把元素放到适合的位置,确保每个子树根节点的键值大于左子树所有的值、小于右子树所有的值,插入重复数据时会忽略。set迭代器采用中序遍历,检索效率高于vector、deque、list,并且会将元素按照升序的序列遍历。set容器中的数值,一经更改,set会根据新值旋转二叉树,以保证平衡,构建set就是为了快速检索(python中的set一旦建立就是一个常量,不能改的)。
multiset,与set不同之处就是它允许有重复的键值。
set和map的区别如下
set是一种关联式容器,其特性如下:
- set以RBTree作为底层容器
- 所得元素的只有key没有value,value就是key
- 不允许出现键值重复
- 所有的元素都会被自动排序
- 不能通过迭代器来改变set的值,因为set的值就是键
map和set一样是关联式容器,它们的底层容器都是红黑树,区别就在于map的值不作为键,键和值是分开的。它的特性如下:
- map以RBTree作为底层容器
- 所有元素都是键+值存在
- 不允许键重复
- 所有元素是通过键进行自动排序的
- map的键是不能修改的,但是其键对应的值是可以修改的
2.set中常用的方法
begin() ,返回set容器的第一个元素
end() ,返回set容器的最后一个元素
clear() ,删除set容器中的所有的元素
empty() ,判断set容器是否为空
max_size() ,返回set容器可能包含的元素最大个数
size() ,返回当前set容器中的元素个数
rbegin ,返回的值和end()相同
rend() ,返回的值和rbegin()相同
#include <iostream> #include <set> using namespace std; int main() { set<int> s; s.insert(); s.insert(); s.insert(); s.insert(); cout<<"set 的 size 值为 :"<<s.size()<<endl; cout<<"set 的 maxsize的值为 :"<<s.max_size()<<endl; cout<<"set 中的第一个元素是 :"<<*s.begin()<<endl; cout<<"set 中的最后一个元素是:"<<*s.end()<<endl; s.clear(); if(s.empty()) { cout<<"set 为空 !!!"<<endl; } cout<<"set 的 size 值为 :"<<s.size()<<endl; cout<<"set 的 maxsize的值为 :"<<s.max_size()<<endl; return ; }小结:插入3之后虽然插入了一个1,但是我们发现set中最后一个值仍然是3哈,这就是set 。还要注意begin() 和 end()函数是不检查set是否为空的,使用前最好使用empty()检验一下set是否为空
- count() 用来查找set中某个某个键值出现的次数。这个函数在set并不是很实用,因为一个键值在set只可能出现0或1次,这样就变成了判断某一键值是否在set出现过了。
#include <iostream> #include <set> using namespace std; int main() { set<int> s; set<int>::const_iterator iter; set<int>::iterator first; set<int>::iterator second; for(int i = ; i <= ; ++i) { s.insert(i); } //第一种删除 s.erase(s.begin()); //第二种删除 first = s.begin(); second = s.begin(); second++; second++; s.erase(first,second); //第三种删除 s.erase(); cout<<"删除后 set 中元素是 :"; for(iter = s.begin() ; iter != s.end() ; ++iter) { cout<<*iter<<" "; } cout<<endl; return ;#include <iostream> #include <set> using namespace std; int main() { set<int> s; s.insert(); s.insert(); s.insert(); s.insert(); cout<<"set 中 1 出现的次数是 :"<<s.count()<<endl; cout<<"set 中 4 出现的次数是 :"<<s.count()<<endl; return ; }#include <iostream> #include <set> using namespace std; int main() { set<int> s; set<int>::const_iterator iter; set<int>::iterator first; set<int>::iterator second; for(int i = ; i <= ; ++i) { s.insert(i); } //第一种删除 s.erase(s.begin()); //第二种删除 first = s.begin(); second = s.begin(); second++; second++; s.erase(first,second); //第三种删除 s.erase(); cout<<"删除后 set 中元素是 :"; for(iter = s.begin() ; iter != s.end() ; ++iter) { cout<<*iter<<" "; } cout<<endl; return ;
(14)正反遍历,迭代器iterator、reverse_iterator
#include<iostream>
#include<set> using namespace std; int main()
{
set<int> v;
v.insert();
v.insert();
v.insert();
v.insert();
v.insert();
v.insert(); //中序遍历 升序遍历
for(set<int>::iterator it = v.begin(); it != v.end(); ++it)
{
cout << *it << " ";
}
cout << endl; for(set<int>::reverse_iterator rit = v.rbegin(); rit != v.rend(); ++rit)
{
cout << *rit << " ";
}
cout << endl; return ;
}

(15) 自定义比较函数,insert的时候,set会使用默认的比较函数(升序),很多情况下需要自己编写比较函数。
1、如果元素不是结构体,可以编写比较函数,下面这个例子是用降序排列的(和上例插入数据相同):
#include<iostream>
#include<set> using namespace std; struct Comp
{
//重载()
bool operator()(const int &a, const int &b)
{
return a > b;
}
};
int main()
{
set<int,Comp> v;
v.insert();
v.insert();
v.insert();
v.insert();
v.insert();
v.insert(); for(set<int,Comp>::iterator it = v.begin(); it != v.end(); ++it)
{
cout << *it << " ";
}
cout << endl; for(set<int,Comp>::reverse_iterator rit = v.rbegin(); rit != v.rend(); ++rit)
{
cout << *rit << " ";
}
cout << endl; return ;
}

2、元素本身就是结构体,直接把比较函数写在结构体内部,下面的例子依然降序:
#include<iostream>
#include<set>
#include<string> using namespace std; struct Info
{
string name;
double score; //重载 <
bool operator < (const Info &a) const
{
return a.score < score;
}
};
int main()
{
set<Info> s;
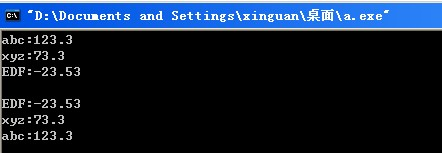
Info info; info.name = "abc";
info.score = 123.3;
s.insert(info); info.name = "EDF";
info.score = -23.53;
s.insert(info); info.name = "xyz";
info.score = 73.3;
s.insert(info); for(set<Info>::iterator it = s.begin(); it != s.end(); ++it)
{
cout << (*it).name << ":" << (*it).score << endl;
}
cout << endl; for(set<Info>::reverse_iterator rit = s.rbegin(); rit != s.rend(); ++rit)
{
cout << (*rit).name << ":" << (*rit).score << endl;
}
cout << endl; return ;
}
(16)map的用法
#include<iostream>
#include<map>
#include<string> using namespace std; int main()
{
map<string,double> m; //声明即插入
m["li"] = 123.4;
m["wang"] = 23.1;
m["zhang"] = -21.9;
m["abc"] = 12.1;
for(map<string,double>::iterator it = m.begin(); it != m.end(); ++it)
{
//first --> key second --> value
cout << (*it).first << ":" << (*it).second << endl;
}
cout << endl;
return ;
}

用map实现数字分离
string --> number
之前用string进行过数字分离,现在使用map
#include<iostream>
#include<map>
#include<string> using namespace std; int main()
{
map<char,int> m; m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
m[''] = ;
/*
等价于
for(int i = 0; i < 10; ++i)
{
m['0' + i] = i;
}
*/ string sa;
sa = "";
int sum = ;
for( int i = ; i < sa.length(); ++i)
{
sum += m[sa[i]];
}
cout << sum << endl;
return ;
}
number --> string
#include <iostream>
#include <map>
#include <string> using namespace std; int main()
{
map<int,char> m; for(int i = ; i < ; ++i)
{
m[i] = '' + i;
} int n = ; string out = "the number is :";
cout << out + m[n] << endl; return ;
}

(17)multimap
multimap由于允许有重复的元素,所以元素插入、删除、查找都与map不同。
插入insert(pair<a,b>(value1,value2))
#include <iostream>
#include <map>
#include <string> using namespace std; int main()
{
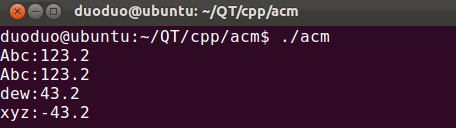
multimap<string,double> m; m.insert(pair<string,double>("Abc",123.2));
m.insert(pair<string,double>("Abc",123.2));
m.insert(pair<string,double>("xyz",-43.2));
m.insert(pair<string,double>("dew",43.2)); for(multimap<string,double>::iterator it = m.begin(); it != m.end(); ++it )
{
cout << (*it).first << ":" << (*it).second << endl;
}
cout << endl; return ;
}
(18)deque
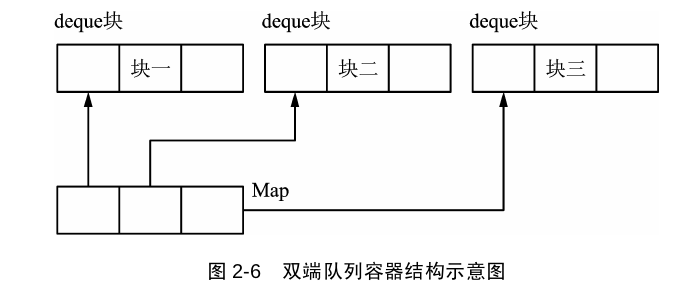
deque和vector一样,采用线性表,与vector唯一不同的是,deque采用的分块的线性存储结构,每块大小一般为512字节,称为一个deque块,所有的deque块使用一个Map块进行管理,每个map数据项记录各个deque块的首地址,这样以来,deque块在头部和尾部都可已插入和删除元素,而不需要移动其它元素。使用push_back()方法在尾部插入元素,使用push_front()方法在首部插入元素,使用insert()方法在中间插入元素。一般来说,当考虑容器元素的内存分配策略和操作的性能时,deque相对vectore更有优势。(下面这个图,我感觉Map块就是一个list< map<deque名字,deque地址> >)
#include <iostream>
#include <deque> using namespace std; int main()
{
deque<int> d; //尾部插入
d.push_back();
d.push_back();
d.push_back();
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl << endl; //头部插入
d.push_front();
d.push_front(-);
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl << endl; d.insert(d.begin() + ,);
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl << endl; //反方向遍历
for(deque<int>::reverse_iterator rit = d.rbegin(); rit != d.rend(); ++rit )
{
cout << (*rit) << " ";
}
cout << endl << endl; //删除元素pop pop_front从头部删除元素 pop_back从尾部删除元素 erase中间删除 clear全删
d.clear();
d.push_back();
d.push_back();
d.push_back();
d.push_back();
d.push_back();
d.push_back();
d.push_back();
d.push_back();
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl; d.pop_front();
d.pop_front();
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl; d.pop_back();
d.pop_back();
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl; d.erase(d.begin() + );
for(deque<int>::iterator it = d.begin(); it != d.end(); ++it )
{
cout << (*it) << " ";
}
cout << endl;
return ;
}
(19)list
list<int> l
插入:push_back尾部,push_front头部,insert方法前往迭代器位置处插入元素,链表自动扩张,迭代器只能使用++--操作,不能用+n -n,因为元素不是物理相连的。
遍历:iterator和reverse_iterator正反遍历
删除:pop_front删除链表首元素;pop_back()删除链表尾部元素;erase(迭代器)删除迭代器位置的元素,注意只能使用++--到达想删除的位置;remove(key) 删除链表中所有key的元素,clear()清空链表。
查找:it = find(l.begin(),l.end(),key)
排序:l.sort()
删除连续重复元素:l.unique() 【2 8 1 1 1 5 1】 --> 【 2 8 1 5 1】
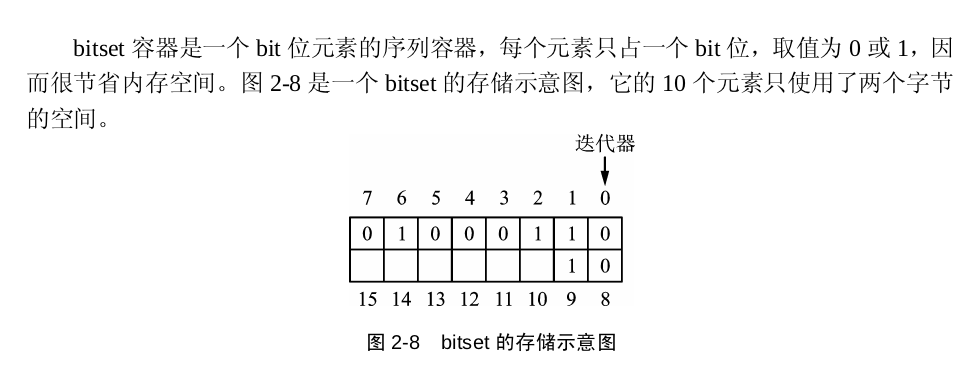
(20)bitset

(21)stack(后进先出)
这个印象深刻,学数据结构的时候做表达式求值的就是用的栈。

#include <iostream>
#include <stack>
using namespace std; int main()
{ stack<int> s;
s.push();
s.push();
s.push();
s.push(); cout << s.size() << endl; while(s.empty() != true)
{
cout << s.top() << endl;
s.pop();
}
return ;
}
(22)queue(先进先出)

queue有入队push(插入)、出队pop(删除)、读取队首元素front、读取队尾元素back、empty,size这几种方法
(23)priority_queue(最大元素先出)


#include <iostream>
#include <queue>
using namespace std; int main()
{ priority_queue<int> pq; pq.push();
pq.push();
pq.push();
pq.push();
pq.push();
pq.push(); cout << "size: " << pq.size() << endl; while(pq.empty() != true)
{
cout << pq.top() << endl;
pq.pop();
}
return ;
}
重载操作符同set重载操作符。
参考:https://www.cnblogs.com/CnZyy/p/3317999.html
C++的STL总结(2)的更多相关文章
- 详细解说 STL 排序(Sort)
0 前言: STL,为什么你必须掌握 对于程序员来说,数据结构是必修的一门课.从查找到排序,从链表到二叉树,几乎所有的算法和原理都需要理解,理解不了也要死记硬背下来.幸运的是这些理论都已经比较成熟,算 ...
- STL标准模板库(简介)
标准模板库(STL,Standard Template Library)是C++标准库的重要组成部分,包含了诸多在计算机科学领域里所常见的基本数据结构和基本算法,为广大C++程序员提供了一个可扩展的应 ...
- STL的std::find和std::find_if
std::find是用来查找容器元素算法,但是它只能查找容器元素为基本数据类型,如果想要查找类类型,应该使用find_if. 小例子: #include "stdafx.h" #i ...
- STL: unordered_map 自定义键值使用
使用Windows下 RECT 类型做unordered_map 键值 1. Hash 函数 计算自定义类型的hash值. struct hash_RECT { size_t operator()(c ...
- C++ STL简述
前言 最近要找工作,免不得要有一番笔试,今年好像突然就都流行在线笔试了,真是搞的我一塌糊涂.有的公司呢,不支持Python,Java我也不会,C有些数据结构又有些复杂,所以是时候把STL再看一遍了-不 ...
- codevs 1285 二叉查找树STL基本用法
C++STL库的set就是一个二叉查找树,并且支持结构体. 在写结构体式的二叉查找树时,需要在结构体里面定义操作符 < ,因为需要比较. set经常会用到迭代器,这里说明一下迭代器:可以类似的把 ...
- STL bind1st bind2nd详解
STL bind1st bind2nd详解 先不要被吓到,其实这两个配接器很简单.首先,他们都在头文件<functional>中定义.其次,bind就是绑定的意思,而1st就代表fir ...
- STL sort 函数实现详解
作者:fengcc 原创作品 转载请注明出处 前几天阿里电话一面,被问到STL中sort函数的实现.以前没有仔细探究过,听人说是快速排序,于是回答说用快速排序实现的,但听电话另一端面试官的声音,感觉不 ...
- STL的使用
Vector:不定长数组 Vector是C++里的不定长数组,相比传统数组vector主要更灵活,便于节省空间,邻接表的实现等.而且它在STL中时间效率也很高效:几乎与数组不相上下. #include ...
- [C/C++] C/C++延伸学习系列之STL及Boost库概述
想要彻底搞懂C++是很难的,或许是不太现实的.但是不积硅步,无以至千里,所以抽时间来坚持学习一点,总结一点,多多锻炼几次,相信总有一天我们会变得"了解"C++. 1. C++标准库 ...
随机推荐
- 备份/还原MySQL数据库----MySQL Workbench
点击[Data Export],界面右侧将显示数据导出窗口. 2 点击[Refresh]按钮,刷新数据库列表(1),选择要导出的数据表(2),设置导出的目录(3),点击[Start Export]按钮 ...
- fflush(stdin)的对错?
C和C++的标准里从来没有定义过 fflush(stdin).也许有人会说:"可是我用 fflush(stdin) 解决了这个问题,你怎么能说是错的呢?"的确,某些编译器(如VC6 ...
- Linux_服务器_08_网卡eth1修改为eth0
一.现象 二.解决步骤 1.修改 70-persistent-net.rules 执行命令: vim /etc/udev/rules.d/-persistent-net.rules 找到与ifconf ...
- Execution Context(EC) in ECMAScript
参考资料 执行环境,作用域理解 深入理解JavaScript系列(2):揭秘命名函数表达式 深入理解JavaScript系列(12):变量对象(Variable Object) 深入理解JavaScr ...
- 第十七章-异步IO
异步IO的出现源自于CPU速度与IO速度完全不匹配 一般的可以采用多线程或者多进程的方式来解决IO等待的问题 同样异步IO也可以解决同步IO所带来的问题 常见的异步IO的实现方式是使用一个消息循环, ...
- stl_iterator.h
stl_iterator.h // Filename: stl_iterator.h // Comment By: 凝霜 // E-mail: mdl2009@vip.qq.com // Blog: ...
- bzoj2654tree
给定一个n个点m条边的图,每条边有黑白两色,求出恰好含need条白边的最小生成树 最小生成树...仿佛并没有什么dp的做法 大概还是个kruskal的板子再加点什么东西 考虑到“恰好含need条白边” ...
- Oracle RAC TAF 无缝failover
理论背景: TAF( Transparent Application Failover ) allows oracle clients to reconnect to a surviving inst ...
- sessionStorage,localStorage,cookies
1 HTML5的Storage主要分为两种:localStorage与sessionStorage,这两者主要在生命周期上有较明显的差别,localStorage的生命周期较长,原则上要等到透过Jav ...
- [转]WebKit CSS3 动画基础
前几天在Qzone上看到css3动画,非常神奇,所以也学习了一下.首先看看效果http://www.css88.com/demo/css3_Animation/ 很悲剧的是css3动画现在只有WebK ...