Elasticsearch同义词词汇单元过滤器
1 简单扩展
"jump,hop,leap"
搜索jump会检索出包含jump、hop或leap的词
1.1 扩展应用在索引阶段
1.2 扩展应用在查询阶段
1.3 对比

2 简单收缩
把左边的多个同义词映射到了右边的单个词:
"leap,hop => jump"
必须同时应用于索引和查询阶段,以确保查询词项映射到索引中存在的同一个值。
优缺点:
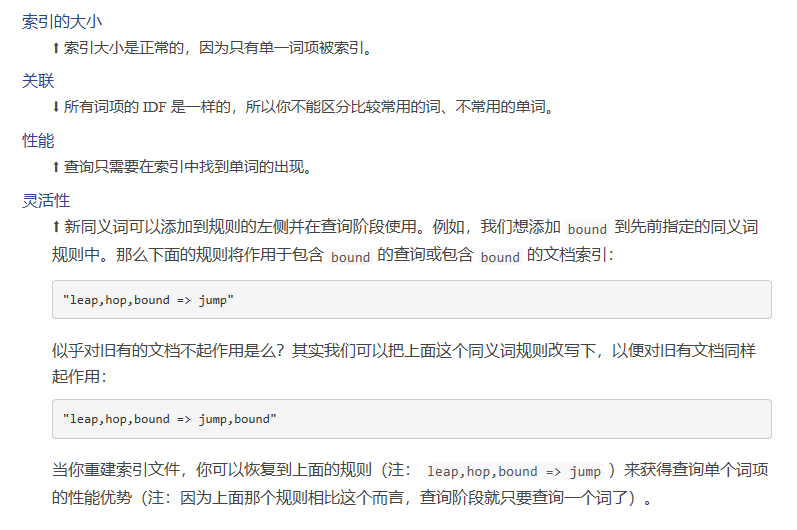
3 类型扩展
"cat => cat,pet",
"kitten => kitten,cat,pet",
"dog => dog,pet"
"puppy => puppy,dog,pet"
如第一行,所有包含cat的文档ID会被索引到倒排索引cat和pet里面。
注意,右边扩大了左边词的的范围。因此,倘若你在索引和查询阶段都使用类型扩展,当你搜索某个词(如cat)的时候,由于cat的IDF值就是cat本来的IDF值,pet的IDF值会比实际上pet的IDF值偏小,因此,包含cat的文档的分数会比包含pet的文档,因而排在更前面。
4 注意
4.1 PET->pet词义变化
经过lowercase过滤器后,包含PET(正电子发射断层扫描)的文档ID会被索引到倒排索引pet中。
解决方案:
在lowercase过滤器之前,利用使用一层同义词词汇单元过滤器,将特殊的单词转化为特殊的词单元,如:
"CAT,CAT scan => cat_scan"
"PET,PET scan => pet_scan"
"Johnny Little,J Little => johnny_little"
"Johnny Small,J Small => johnny_small"
经过lowercase过滤器之后,在进行一次常规的同义词词汇单元过滤器,如:
"cat => cat,pet"
"dog => dog,pet"
"cat scan,cat_scan scan => cat_scan"
"pet scan,pet_scan scan => pet_scan"
"little,small"
4.2 短语查询
如果同义词中有短语词组,如:
"usa,united states,u s a,united states of america"
一定要在分词之前,使用词义收缩,否则会造成严重不匹配(原因)
"united states,u s a,united states of america=>usa"
这个方法的缺点是,因为把 united states of america 转换成了同义词 usa, 你就不能使用 united states of america 去搜索出 united 或者 states 。 你需要使用一个额外的字段并用另一个解析器链来达到这个目的。
4.3 符号同义词
符号表情能够很好地表示语义。为了在分词过程中损失掉这部分信息。可以通过映射字符过滤器将表情符号转化为一个表示它的特殊同义词。如,
":)=>emoticon_happy"
Elasticsearch同义词词汇单元过滤器的更多相关文章
- Python Elasticsearch api,组合过滤器,term过滤器,正则查询 ,match查询,获取最近一小时的数据
Python Elasticsearch api 描述:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.下 ...
- elasticsearch同义词及动态更新
第一种:参考地址:http://dev.paperlesspost.com/setting-up-elasticsearch-synonyms/271.Add a synonyms file.2.Cr ...
- Elasticsearch:使用 IP 过滤器限制连接
文章转载自:https://elasticstack.blog.csdn.net/article/details/107154165
- Elasticsearch自定义分析器
关于分析器 ES中默认使用的是标准分析器(standard analyzer).如果需要对某个字段使用其他分析器,可以在映射中该字段下说明.例如: PUT /my_index { "mapp ...
- ElasticSearch 处理自然语言流程
ES处理人类语言 ElasticSearch提供了很多的语言分析器,这些分析器承担以下四种角色: 文本拆分为单词 The quick brown foxes → [ The, quick, brown ...
- ElasticSearch最全分词器比较及使用方法
介绍:ElasticSearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elasticsearch 是用 Java 开 ...
- elasticsearch索引和映射
目录 1. elasticsearch如何实现搜索 1.1 搜索实例 1.2 es中数据的类型 1.3 倒排索引 1.4 分析与分析器 1.4.1 什么是分析器 1.4.2 内置分析器种类 1.4.3 ...
- Elasticsearch查询优化总结
查询优化 1 从提高查询精确度进行优化: 本部分主要针对全文搜索进行探究. 1.1 倒排索引 1.1.1 什么是倒排索引: 一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文 ...
- Elasticsearch中的分词器比较及使用方法
Elasticsearch 默认分词器和中分分词器之间的比较及使用方法 https://segmentfault.com/a/1190000012553894 介绍:ElasticSearch 是一个 ...
随机推荐
- kiiti分割的数据及其处理
kitti和cityscape的gt的分割不太一样,下边缘不再是从黑色开始的,而是直接是类别 red,green,blue = img_gt[i,j] 1.道路的颜色(紫色):128 64 128 2 ...
- centos7 kvm安装使用
kvm简介 KVM 全称是 Kernel-Based Virtual Machine.也就是说 KVM 是基于 Linux 内核实现的. KVM有一个内核模块叫 kvm.ko,只用于管理虚拟 CPU ...
- 旧文备份:windows下编译和使用IT++
1.下载IT++最新版:<a href="http://sourceforge.net/projects/itpp/">http://sourceforge.net/p ...
- scp 远程拷贝
scp拷贝时,可以从本地拷贝到远程,也可以远程拷贝到本地.唉,我记得之前是都用过的,但是现在完全忘了,今天同事写出来我才意识到自己之前用过的. 唉,这几年在新单位如果不好好积累一下理论上的东西,真的是 ...
- python解析ini文件
python解析ini文件 使用configparser - Configuration file parser sections() add_section(section) has_section ...
- 优化tableView性能(针对滑动时出现卡的现象)
优化tableView性能(针对滑动时出现卡的现象) 在iOS应用中,UITableView应该是使用率最高的视图之一了.iPod.时钟.日历.备忘录.Mail.天气.照片.电话.短信. Safari ...
- 使用phpExcel将数据批量导出
if(isset($_POST['export']) && $_POST['export'] == '导出所选数据') { //此处为多选框已勾选的数据 $export_id=$_PO ...
- px与em的区别,权重的优先级
px与em的区别,权重的优先级 PX特点:px像素(Pixel).相对长度单位.像素px是相对于显示器屏幕分辨率而言的.EM特点:1. em的值并不是固定的:2. em会继承父级元素的字体大小. 权重 ...
- 千锋教育Vue组件--vue基础的方法
课程地址: https://ke.qq.com/course/251029#term_id=100295989 <!DOCTYPE html> <html> <head& ...
- linuxC编程介绍
第一步:写完程序 /first.c/ #include <stdio.h> int main() { printf("hello,welcome to the LinuxC!\n ...