mysql分区partition
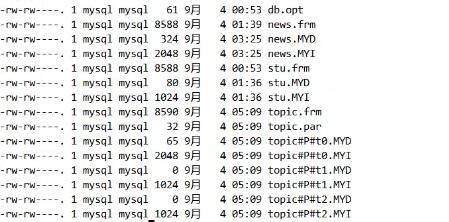
分区后 会产生多个 数据存储文件MYD,MYI ,把内容读取分散到多个文件上,这样减少并发读取,文件锁的概率,提高IO
=== 水平分区的几种模式:===
1. Range(范围) – 这种模式允许DBA将数据划分不同范围。例如DBA可以将一个表通过年份划分成三个分区,80年代(1980's)的数据,90年代(1990's)的数据以及任何在2000年(包括2000年)后的数据。
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) (
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES LESS THAN (9000000)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES LESS THAN MAXVALUE DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
在这里,将用户表分成4个分区,以每300万条记录为界限,每个分区都有自己独立的数据、索引文件的存放目录,与此同时,这些目录所在的物理磁盘分区可能也都是完全独立的,可以提高磁盘IO吞吐量。
2.Hash(哈希) – 这中模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区,。例如DBA可以建立一个对表主键进行分区的表。
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY HASH (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
分成4个区,数据文件和索引文件单独存放。
3. Key(键值) – 上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY KEY (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
)
分成4个区,数据文件和索引文件单独存放。
4.List(预定义列表) – 这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割。例如:DBA建立了一个横跨三个分区的表,分别根据2004年2005年和2006年值所对应的数据。
CREATE TABLE category (
cid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY LIST (cid) (
PARTITION p0 VALUES IN (0,4,8,12)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES IN (1,5,9,13)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES IN (2,6,10,14)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES IN (3,7,11,15)
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
分成4个区,数据文件和索引文件单独存放。
5. Composite(复合模式) - 很神秘吧,哈哈,其实是以上模式的组合使用而已,就不解释了。举例:在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区。
= 垂直分区(按列分)=
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
6.* 子分区
子分区是针对 RANGE/LIST 类型的分区表中每个分区的再次分割。再次分割可以是 HASH/KEY 等类型。例如:
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) SUBPARTITION BY HASH (uid % 4) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx'
); 对 RANGE 分区再次进行子分区划分,子分区采用 HASH 类型。
或者
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) SUBPARTITION BY KEY(uid) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx'
); 对 RANGE 分区再次进行子分区划分,子分区采用 KEY 类型。
= 分区管理 == 分区管理 == 分区管理 == 分区管理 =
1.删除分区 ALERT TABLE users DROP PARTITION p0; 删除分区 p0。
2.重建分区
RANGE 分区重建
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES LESS THAN (6000000));
将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。
LIST 分区重建
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES IN(0,1,4,5,8,9,12,13));
将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。
HASH/KEY 分区重建
ALTER TABLE users REORGANIZE PARTITION COALESCE PARTITION 2;
用 REORGANIZE 方式重建分区的数量变成2,在这里数量只能减少不能增加。想要增加可以用 ADD PARTITION 方法。
3.新增分区
新增 RANGE 分区
ALTER TABLE category ADD PARTITION (PARTITION p4 VALUES IN (16,17,18,19)
DATA DIRECTORY = '/data8/data'
INDEX DIRECTORY = '/data9/idx');
新增一个RANGE分区。
新增 HASH/KEY 分区
ALTER TABLE users ADD PARTITION PARTITIONS 8;
将分区总数扩展到8个。
4.给已有的表加上分区
alter table results partition by RANGE (month(ttime))
(PARTITION p0 VALUES LESS THAN (1),
PARTITION p1 VALUES LESS THAN (2) , PARTITION p2 VALUES LESS THAN (3) ,
PARTITION p3 VALUES LESS THAN (4) , PARTITION p4 VALUES LESS THAN (5) ,
PARTITION p5 VALUES LESS THAN (6) , PARTITION p6 VALUES LESS THAN (7) ,
PARTITION p7 VALUES LESS THAN (8) , PARTITION p8 VALUES LESS THAN (9) ,
PARTITION p9 VALUES LESS THAN (10) , PARTITION p10 VALUES LESS THAN (11),
PARTITION p11 VALUES LESS THAN (12),
PARTITION P12 VALUES LESS THAN (13) );
默认分区限制分区字段必须是主键(PRIMARY KEY)的一部分,为了去除此
http://blog.csdn.net/tjcyjd/article/details/11194489
mysql分区partition的更多相关文章
- 实战mysql分区(PARTITION)
http://lobert.iteye.com/blog/1955841 前些天拿到一个表,将近有4000w数据,没有任何索引,主键.(建这表的绝对是个人才) 这是一个日志表,记录了游戏中物品的产出与 ...
- 【转载】实战mysql分区(PARTITION)
转载地址:http://lobert.iteye.com/blog/1955841 前些天拿到一个表,将近有4000w数据,没有任何索引,主键.(建这表的绝对是个人才) 这是一个日志表,记录了游戏中物 ...
- mysql分区partition详解
分区管理 论坛 1. RANGE和LIST分区的管理 针对非整形字段进行RANG\LIST分区建议使用COLUMNS分区. RANGE COLUMNS是RANGE分区的一种特殊类型,它与RANGE ...
- 深入解析MySQL分区(Partition)功能
自5.1开始对分区(Partition)有支持 = 水平分区(根据列属性按行分)= 举个简单例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录. === 水平分区 ...
- MySQL分区(Partition)功能
引用地址:http://blog.csdn.net/tjcyjd/article/details/11194489 自5.1开始对分区(Partition)有支持 = 水平分区(根据列属性按行分)=举 ...
- 理解MySQL——并行数据库与分区(Partition)
1.并行数据库 1.1.并行数据库的体系结构并行机的出现,催生了并行数据库的出现,不对,应该是关系运算本来就是高度可并行的.对数据库系统性能的度量主要有两种方式:(1)吞吐量(Throughput), ...
- mysql的partition分区
前言:当一个表里面存储的数据特别多的时候,比如单个.myd数据都已经达到10G了的话,必然导致读取的效率很低,这个时候我们可以采用把数据分到几张表里面来解决问题.方式一:通过业务逻辑根据数据的大小通过 ...
- mysql表分区 partition
表分区 partition 当一张表的数据非常多的时候,比如单个.myd文件都达到10G, 这时,必然读取起来效率降低. 可不可以把表的数据分开在几张表上? 1: 从业务角度可以解决.. (分表,水平 ...
- Atitit 分区后的查询 mysql分区记录的流程与原理
Atitit 分区后的查询 mysql分区记录的流程与原理 1.1.1. ibd是MySQL数据文件.索引文件1 1.2. 已经又数据了,如何分区? 给已有的表加上分区 ]1 1.3. 分成4个区, ...
随机推荐
- React 组件条件渲染的几种方式
一.条件表达式渲染 (适用于两个组件二选一的渲染) render() { const isLoggedIn = this.state.isLoggedIn; return ( <div> ...
- org.springframework.beans.factory.UnsatisfiedDependencyException
© 版权声明:本文为博主原创文章,转载请注明出处 1.问题描述: 搭建SSH框架,启动时报错如下: 严重: Context initialization failed org.springframew ...
- Django--基础补充
render 函数 在Django的使用中,render函数大多与浏览器发来的GET请求一并出现,它的使用方法非常简单 例如:render(request,"xxx.html",{ ...
- quartus2 13.0+modelsim联合开发环境搭建(win10)
quartus2用于硬件设计代码的综合,检查是否有语法错误:modelsim用于对硬件设计代码进行仿真,观察波形是否与需求一致,需要编写xxx_tb.v才能仿真 一.quartus2安装见这篇文章ht ...
- C语言include预处理命令与多文件编译
#include预处理命令几乎使我们在第一次接触C的时候就会碰到的预处理命令,可我现在还不怎么清楚,这次争取一次搞懂. 一.#include预处理指令的基本使用 预处理指令可以将别处的源代码内容插入到 ...
- ubuntu安装分区
♠ 文件系统 windows下常见的文件系统有FAT, FAT32, NTFS 在linux里可使用的文件系统: Ext2: 早期的格式,不支持日志. Ext3: 是ext2改良版,增加了日志功能, ...
- PHP性能之语言性能优化:vld——查看代码opcode的神器
vld介绍 vld是PECL(PHP 扩展和应用仓库)的一个PHP扩展,现在最新版本是 0.14.0(2016-12-18),它的作用是:显示转储PHP脚本(opcode)的内部表示(来自PECL的v ...
- 使用onepage-scroll全屏滚动插件时的注意事项
如果项目需要在移动端访问时需要设置responsiveFallback属性,并且在此之前还需要检测浏览器的级别(引入modernizr.js文件) var $responsiveFallback = ...
- 【BZOJ4177】Mike的农场 最小割
[BZOJ4177]Mike的农场 Description Mike有一个农场,这个农场n个牲畜围栏,现在他想在每个牲畜围栏中养一只动物,每只动物可以是牛或羊,并且每个牲畜围栏中的饲养条件都不同,其中 ...
- tmpfs(转)
什么是tmpfs tmpfs是Linux/Unix系统上的一种基于内存的文件系统.tmpfs可以使用您的内存或swap分区来存储文件. 实现原理:基于VM子系统 tmpfs是基于Linux的虚拟内存管 ...