深度学习—BN的理解(二)
神经网络各个操作层的顺序:
1、sigmoid,tanh函数:conv -> bn -> sigmoid -> pooling
2、RELU激活函数:conv -> bn -> relu -> pooling
一般情况下,先激活函数,后pooling。但对于RELU激活函数,二者交换位置无区别。
论文原文里面是“weights -> batchnorm -> activation ->maxpooling-> weights -> batchnorm -> activation -> dropout”。原文认为这样可以利用到激活函数的不同区间(sigmoid的两个饱和区、中间的线性区等)实现不同的非线性效果,在特定的情况下也可能学习到一个恒等变换的batchnorm,一般用这个即可。
为了activation能更有效地使用输入信息,所以一般放在激活函数之前。
tensorflow中关于BN(Batch Normalization)的函数主要有两个,分别是:
- tf.nn.moments
- tf.nn.batch_normalization
- tf.layers.batch_normalization
- tf.contrib.layers.batch_norm
应用中一般使用 tf.layers.batch_normalization 进行归一化操作。因为集成度较高,不需要自己计算相关的均值和方差。
1、tf.nn.moments计算的是哪一部分均值方差?
举例:
tf.nn.moments(x, axes, name=None, keep_dims=False);其中x是输入,axes表示在哪一维计算,输出为计算的均值和方差。
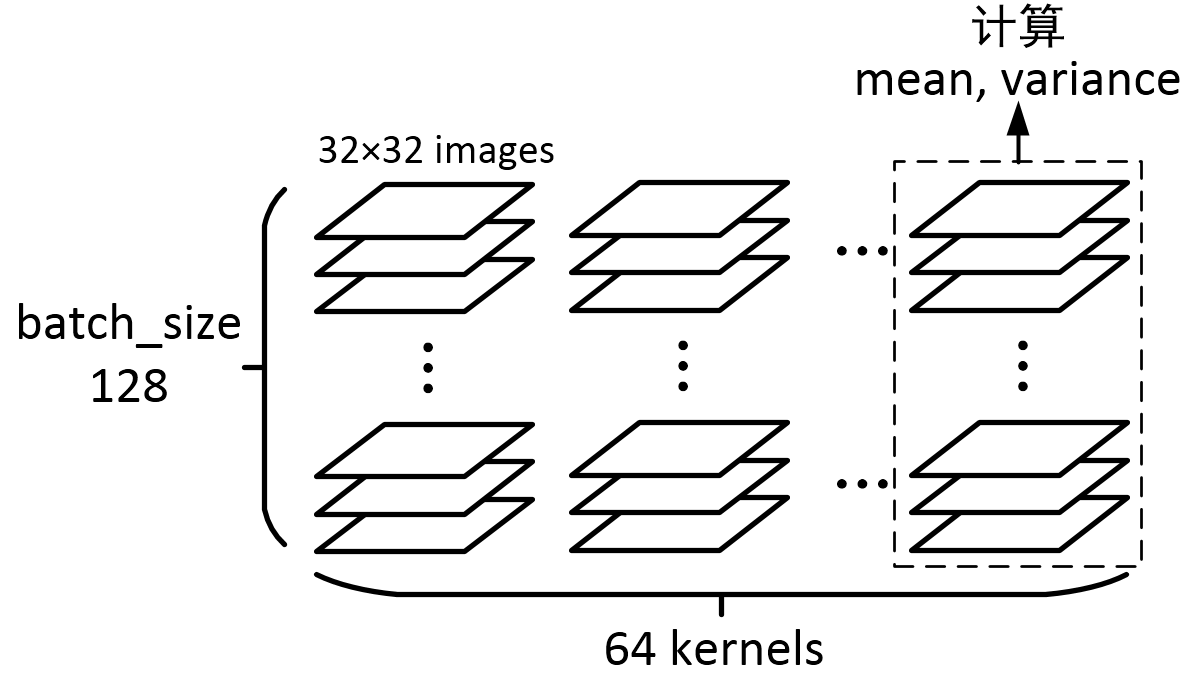
img = tf.Variable(tf.random_normal([128, 32, 32, 64]))
axis = list(range(len(img.get_shape()) - 1))
mean, variance = tf.nn.moments(img, axis)
一个batch里的128个图,经过一个64 kernels卷积层处理,得到了128×64个图,再针对每一个kernel所对应的128个图,求它们所有像素的mean和variance,因为总共有64个kernels,输出的结果就是一个一维长度64的数组啦!最后输出是(64,)的数组向量。
2、 tf.layers.batch_normalization
在TensorFlow中,如果我们要使用batch normalization层,可以使用的API有tf.layers.batch_normalization和tf.contrib.layers.batch_norm,如果我们直接使用这两个API构建我们的网络,往往会出现训练的时候网络的表现非常好,而当测试的时候我们将其中的参数is_training设置为False时,网络的表现非常的差。这往往是因为我们训练的时候忽视了一个细节。
(1)方法1:
在tf.contrib.layers.batch_norm的帮助文档中我们看到有以下的文字
Note: when training, the moving_mean and moving_variance need to be updated. By default the update ops are placed in tf.GraphKeys.UPDATE_OPS, so they need to be added as a dependency to the train_op.
也就是说,我们需要在代码运行的过程中手动对moving_mean和moving_variance进行手动更新,代码如下:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
这一步非常的重要,很多人在训练的时候往往会忽略这一步,导致训练/测试时结果相差巨大。
(2)还有一个方法:需要将is_training改成True。
要注意的地方是,在做测试的时候,如果将is_training改为 False,就会出现测试accuracy很低的现象,需要将is_training改成True。虽然这样能得到高的accuracy,但是明显不合理!!
3、tf.nn.batch_normalization
自己写,用tf.nn.batch_normalization
tensorflow实现:
def batchNorm_layer(inputs, is_training, decay = 1e-5, epsilon = 1e-3):
scale = tf.Variable(tf.ones(inputs.get_shape()[1:].as_list()))
beta = tf.Variable(tf.zeros(inputs.get_shape()[1:].as_list()))
pop_mean = tf.Variable(tf.zeros(inputs.get_shape()[1:].as_list()), trainable=False)
pop_var = tf.Variable(tf.ones(inputs.get_shape()[1:].as_list()), trainable=False) if is_training:
batch_mean, batch_var = tf.nn.moments(inputs, [0])
train_mean = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay))
train_var = tf.assign(pop_var, pop_var * decay + batch_var * (1 - decay))
with tf.control_dependencies([train_mean, train_var]):
return tf.nn.batch_normalization(inputs, batch_mean, batch_var, beta, scale, epsilon)
else:
return tf.nn.batch_normalization(inputs, pop_mean, pop_var, beta, scale, epsilon)
参考:https://www.jianshu.com/p/0312e04e4e83
深度学习—BN的理解(二)的更多相关文章
- 深度学习—BN的理解(一)
0.问题 机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障.那BatchNorm的作用是 ...
- 转载-【深度学习】深入理解Batch Normalization批标准化
全文转载于郭耀华-[深度学习]深入理解Batch Normalization批标准化: 文章链接Batch Normalization: Accelerating Deep Network T ...
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
- 深度学习入门实战(二)-用TensorFlow训练线性回归
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :董超 上一篇文章我们介绍了 MxNet 的安装,但 MxNet 有个缺点,那就是文档不太全,用起来可能 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习笔记】(二)基于MNIST数据集的神经网络实验
一.介绍 MNIST(Mixed National Institute of Standards and Technology database)是网上著名的公开数据库之一,是一个入门级的计算机视觉数 ...
- 【深度学习】深入理解ReLU(Rectifie Linear Units)激活函数
论文参考:Deep Sparse Rectifier Neural Networks (很有趣的一篇paper) Part 0:传统激活函数.脑神经元激活频率研究.稀疏激活性 0.1 一般激活函数有 ...
- 深度学习基础(十二)—— ReLU vs PReLU
从算法的命名上来说,PReLU 是对 ReLU 的进一步限制,事实上 PReLU(Parametric Rectified Linear Unit),也即 PReLU 是增加了参数修正的 ReLU. ...
随机推荐
- hive beeline 的server启动与连接
启动hiveServer2 启动beeline之后 连接 !connect jdbc:hive2://localhost:10000/default 启动的时候连接 /beeline -u jdbc: ...
- jeecms搜索结果排序-二次开发
jeecms搜索用的是apache Lucene,要实现此功能得先去学习它. 直接上代码 package com.jeecms.cms.lucene; import java.io.IOExcepti ...
- 4.关于QT中的QFile文件操作,QBuffer,Label上加入QPixmap,QByteArray和QString之间的差别,QTextStream和QDataStream的差别,QT内存映射(
新建项目13IO 13IO.pro HEADERS += \ MyWidget.h SOURCES += \ MyWidget.cpp QT += gui widgets network CON ...
- struts2中配置文件加载的顺序是什么?
struts2的StrutsPrepareAndExecuteFilter拦截器中对Dispatcher进行了初始化 在Dispatcher类的init方法中定义了配置文件的加载顺序(下面是源码) p ...
- Win7系统CMD命令提示符输入中文变乱码怎么办
Win7系统下经常使用CMD命令提示符进行很多操作,发现Win7旗舰版系统在CMD命令提示符不能输入文字,输入的中文字都变成乱码,这是怎么回事呢?本文将提供Win7系统CMD命令提示符输入中文变乱码的 ...
- centOS6.2 最小安装下的无线网络配置
一.安装wireless_tools,http://www.linuxfromscratch.org/blfs/view/svn/basicnet/wireless_tools.html 二.vi / ...
- 装服务器,测试数据库,简单的maven命令
[说明]今天总体回顾一下:大概是早上装服务器,下午测试数据库,晚上了解简单的maven命令 一:今日完成 1)在远程服务器的tomcat 设置好管理员的登录账号 2)登录tomcat 的项目管理 查看 ...
- 【BZOJ4542】[Hnoi2016]大数 莫队
[BZOJ4542][Hnoi2016]大数 Description 小 B 有一个很大的数 S,长度达到了 N 位:这个数可以看成是一个串,它可能有前导 0,例如00009312345.小B还有一个 ...
- NOI-linux下VIM的个人常用配置
路径:/etc/vim/vimrc 打开终端:Ctrl+Alt+T 输入:sudo vim或gedit /etc/vim/vimrc (推荐用gedit,更好操作) 以下是我的配置: "我的 ...
- Python锁
# coding:utf-8 import threading import time def test_xc(): f = open("test.txt","a&quo ...