机器学习:集成学习(Soft Voting Classifier)
一、Hard Voting 与 Soft Voting 的对比
1)使用方式
- voting = 'hard':表示最终决策方式为 Hard Voting Classifier;
- voting = 'soft':表示最终决策方式为 Soft Voting Classifier;
2)思想
- Hard Voting Classifier:根据少数服从多数来定最终结果;
- Soft Voting Classifier:将所有模型预测样本为某一类别的概率的平均值作为标准,概率最高的对应的类型为最终的预测结果;
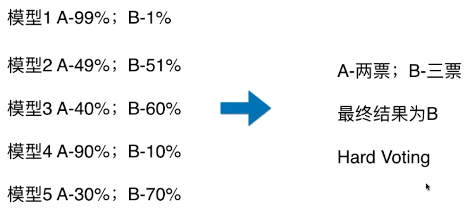
Hard Voting
- 模型 1:A - 99%、B - 1%,表示模型 1 认为该样本是 A 类型的概率为 99%,为 B 类型的概率为 1%;
Soft Voting
- 将所有模型预测样本为某一类别的概率的平均值作为标准;

- Hard Voting 投票方式的弊端:
- 如上图,最终的分类结果不是由概率值更大的模型 1 和模型 4 决定,而是由概率值相对较低的模型 2/3/5 来决定的;
二、各分类算法的概率计算
- Soft Voting 的决策方式,要求集合的每一个模型都能估计概率;
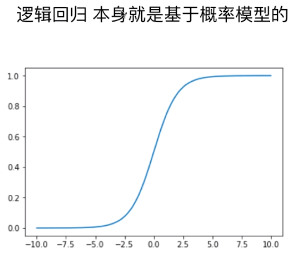
1)逻辑回归算法
- P = σ( y_predict )
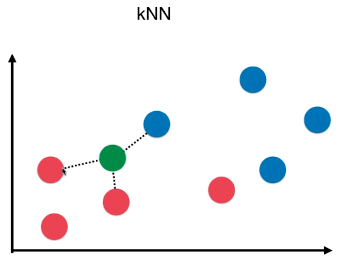
2)kNN 算法
- k 个样本点中,数量最多的样本所对应的类别作为最终的预测结果;
- kNN 算法也可以考虑权值,根据选中的 k 个点距离待预测点的距离不同,k 个点的权值也不同;
- P = n / k
- n:k 个样本中,最终确定的类型的个数;如下图,最终判断为 红色类型,概率:p = n/k = 2 / 3;
3)决策树算法
- 通常在“叶子”节点处的信息熵或者基尼系数不为 0,数据集中包含多种类别的数据,以数量最多的样本对应的类别作为最终的预测结果;(和 kNN 算法类似)
- P = n / N
- n:“叶子”中数量最多的样本的类型对应的样本数量;
- N:“叶子”中样本总量;
4)SVM 算法
- 在 scikit-learn 中的 SVC() 中的一个参数:probability
- probability = True:SVC() 返回样本为各个类别的概率;(默认为 False)
from sklearn.svm import SVC
svc = SVC(probability=True) - 计算样本为各个类别的概率需要花费较多时间;
三、scikit-learn 中使用集成分类器:VotingClassifier
1)模拟数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
2)voting = 'hard':使用 Hard Voting 做决策
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier # 实例化
voting_clf = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC()),
('dt_clf', DecisionTreeClassifier(random_state=666))
], voting='hard') voting_clf.fit(X_train, y_train)
voting_clf.score(X_test, y_test)
# 准确率:0.896
3)voting = 'soft':使用 Soft Voting 做决策
voting_clf = VotingClassifier(estimators=[
('log_clf', LogisticRegression()),
('svm_clf', SVC(probability=True)),
('dt_clf', DecisionTreeClassifier(random_state=666))
], voting='soft') voting_clf.fit(X_train, y_train)
voting_clf.score(X_test, y_test)
# 准确率:0.912- 使用 Soft Voting 时,SVC() 算法的参数:probability=True
机器学习:集成学习(Soft Voting Classifier)的更多相关文章
- 【笔记】集成学习入门之soft voting classifier和hard voting classifier
集成学习入门之soft voting classifier和hard voting classifier 集成学习 通过构建并结合多个学习器来完成学习任务,一般是先产生一组"个体学习器&qu ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 集成学习-Majority Voting
认识 集成学习(Ensemble Methods), 首先是一种思想, 而非某种模型, 是一种 "群体决策" 的思想, 即对某一特定问题, 用多个模型来进行训练. 像常见的单个模型 ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
随机推荐
- INSPIRED启示录 读书笔记 - 第23章 改进现有产品
不是一味地添加功能 改进产品不是简单地满足个别用户的要求,也不能对用户调查的结果照单全收.能提高指标的功能才是关注的重点.应该找准方向,分析关键指标,有针对性地改进产品
- jack server 常见错误解决方法【转】
本文转载自:https://blog.csdn.net/qq_27061049/article/details/70156200 jack 服务常见错误解决方法 当你编译Android时,你不需要修改 ...
- Mysql 导出导入
MySQL数据库导出 以root登录vps,执行以下命令导出. 1./usr/local/mysql/bin/mysqldump -u root -p123456 zhumaohai > /ho ...
- 暑假爆零欢乐赛SRM08题解
这真的是披着CF外衣的OI赛制?我怎么觉得这是披着部分分外衣的CF?果然每逢cf赛制必掉rating,还是得%%%cyc橙名爷++rp.. A题就是找一找序列里有没有两个连在一起的0或1,并且不能向两 ...
- MAC 系列 之XCode7.1 + HBuilder MUI 离线打包 ipa 上次application leader 问题:ERROR ITMS - 90032
90032 解决方法:
- mssql 函数STUFF 的用法
DECLARE @limitDay INT;SET @limitDay = 92;IF DATEDIFF(DAY, '2017-12-13 00:00:00', '2017-12-13 18:00:0 ...
- VS10_慢_优化
参考网址: http://blog.csdn.net/cll131421/article/details/15341367 1. 我暂时只做了这个: “ 一.VS2010选项视觉体验设置 工具-> ...
- strip_tags--php
函数剥去字符串中的 HTML.XML 以及 PHP 的标签 strip_tags(string,allow) 参数 描述 string 必需.规定要检查的字符串. allow 可选.规定允许的标签.这 ...
- Mac开机启动
1. Finder打开资源库的LaunchAgents目录. 打开Finder,按⇧⌘G,输入 /Library/LaunchAgents/ 以及 ~/Library/LaunchAgents/ 2. ...
- HANA aggregate 数字聚合
在project 1 里面 具有服务店代码,金额.应该上一层aggregate 就自动聚合了.可是并没有.要自己手工设置一下.在columns 右键变成——convert to aggregated ...