神经网络系列学习笔记(二)——神经网络之DNN学习笔记
一、单层感知机(perceptron)
拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换到达输出层,在输出层得到分类结果;
缺点:无法模拟稍复杂一些的函数(例如简单的异或计算)。
解决办法:多层感知机。
二、多层感知机(multilayer perceptron)
有多个隐含层的感知机。
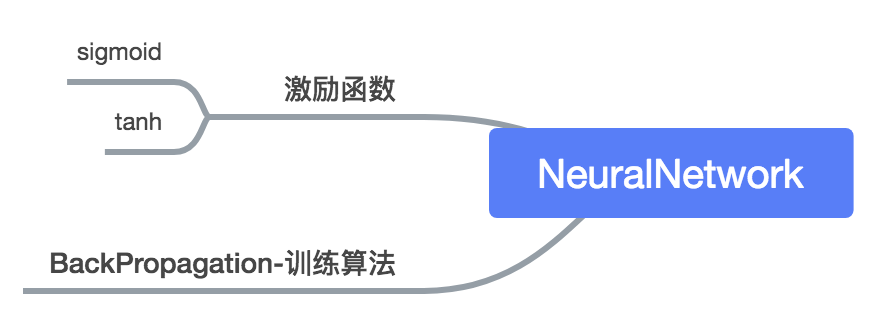
多层感知机解决了之前无法模拟异或逻辑的缺陷,同时,更多的层数使得神经网络可以模拟显示世界中更加复杂的情形。
多层感知机给我们的启示是,神经网络的层数直接决定它的刻画能力——利用每层更少的神经元拟合更复杂的函数;
缺点:网络层数越多,优化函数越来越容易陷入局部最优解;利用有限数据训练的深层网络,性能可能还不如浅层网络;“梯度消失”现象更加严重;
三、深度学习的起源及其与机器学习、神经网络的区别:

浅层学习:
深度学习:
区别于传统的浅层学习,深度学习的不同:
问题:
deep learning(neural network)的缺点:
神经网络:
deep learning:
四、Deep learning训练过程
难点:非凸目标函数中的局部极小值是训练困难的主要来源。
BP算法存在的问题:
(1)梯度越来越稀疏;
(2)收敛到局部最小值;
(3)只能用有标签的数据来训练;
deep learning 训练过程:
hinton提出在非监督数据上建立多层神经网络:step1.layer-wise learning;step2.tuning;使得原始表示x向上生成的高级表示r和该高级表示r向下生成的x'尽可能一致。
wake-sleep算法:
1)wake阶段:认知过程,通过外界的特征和向上的权重(认知权重)产生每一层的抽象表示(结点状态),并且使用梯度下降修改层间的下行权重(生成权重)。也就是“如果现实跟我想象的不一样,改变我的权重使我想象的东西就是这样的”。
2)sleep阶段:生成过程,通过顶层表示(醒时学得的概念)和向下权重,生成底层的状态,同时修改层间向上的权重。也就是“如果梦中的景象不是我脑中的相应概念,改变我的认知权重使得这种景象在我看来就是这个概念”。
deep learning 具体训练过程:
1)使用自下上升非监督学习(就是从底层开始,一层一层的往顶层训练):
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是feature learning过程):
*问题:无标定数据怎么训练第一层?
*答:这层可看作是得到一个使得输出和输入差别最小的三层神经网络的隐层,训练时只要保证训练样本的输出和输入差别最小,以此得到参数的权重;
由于模型容量的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到第n-1层后,将n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数;
2)自顶向下的监督学习(就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调):
基于第一步得到的各层参数进一步fine-tune整个多层模型的参数,这一步是一个有监督训练过程;第一步类似神经网络的随机初始化初值过程,由于deep learning的第一步不是随机初始化(也就是说,神经网络训练时,迭代的第一步是随机初始化参数),而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果;所以deep learning效果好很大程度上归功于第一步的feature learning过程。
五、深度学习具体模型及方法
一、基本结构——特征表示/学习
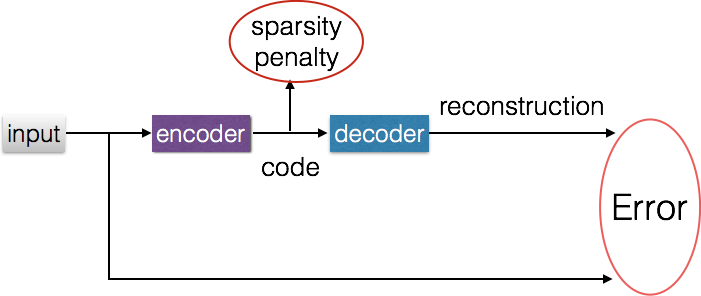
Deep Learning最简单的一种应用就是进行特征表示。跟人工神经网络(ANN)一样,如果我们给定一个神经网络,假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入i的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
自动编码器:

上图就是自动编码器的训练原理。
这个auto-encoder还不能用来分类数据,因为它还没有学习如何去连接一个输入和一个类,它只是学会了如何去重构或者复现它的输入而已。但是在这个过程中,神经网络学会了一些抽象特征,我们最后只需要将输入,以及最后一层的特征code输入到最后的分类器(例如logistic regression,svm ……),通过有标签的样本,使用监督学习的方法进行微调。
有两种方法:
1、只调整分类器:

2、通过有标签样本,微调整个系统:(如果有足够多的数据,这是最好的方法,端对端学习)

研究发现,如果在原有的特征中加入这些自动学习得到的特征可以大大提高精确度,甚至在分类问题中比目前最好的分类算法效果还好。
注:
Fine-tuning的目的,是使得整个网络系统达到全局的最优(end2end),而不是之前分段的局部最优。
二、其他模型结构及其演进版本
(1)稀疏自动编码器
在auto-encoder的网络使用加上L1的Regularity限制,(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分神经元是受到抑制的)。
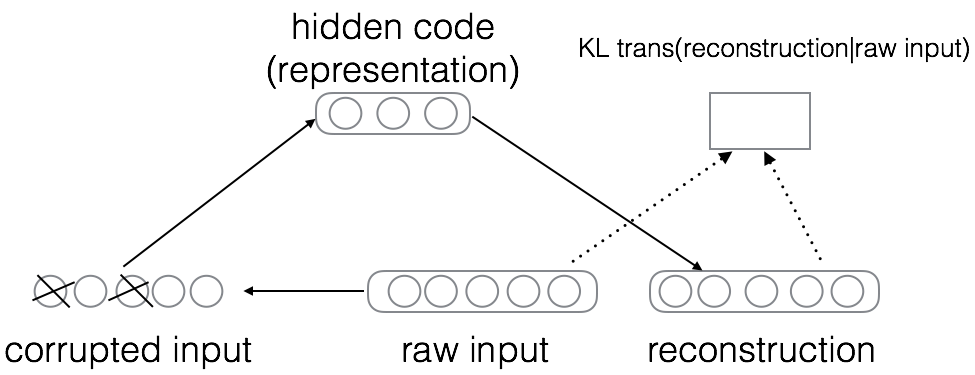
(2)降噪自动编码器
Denoising auto-encoder (DA)是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪音污染过的输入。因此,就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。DA可以通过梯度下降算法去训练。
(3)sparse coding稀疏编码
简单来说,就是将输入向量表示为一组基向量的线性组合。
Sparse coding:超完备基(基向量的个数比输入向量的维数要大)
PCA:完备基 (降维)
Deep learning:Unsupervised Feature Learning
Image: pixcel -> basis -> high level basis -> learning
Doc: word -> term -> topic -> learning
特征表示的粒度:
a.不是特征越底层,粒度越细,学习算法的效果越好;
b.不是特征越多越好,探索的空间大,计算复杂,可以用来训练的数据在每个特征上就会稀疏,带来各种问题。
稀疏编码算法:
稀疏编码是一个重复迭代的过程,每次迭代分两步:
1)选择一组 S[k] (“基”),然后调整 a[k] (系数权重),使得Sum_k (a[k] * S[k]) 最接近 T(输入)。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
缺点:
稀疏编码是有一个明显的局限性的,这就是即使已经学习得到一组基向量,如果为了对新的数据样本进行“编码”,我们必须再次执行优化过程来得到所需的系数。这个显著的“实时”消耗意味着,即使是在测试中,实现稀疏编码也需要高昂的计算成本,尤其是与典型的前馈结构算法相比。
(4)限制玻耳兹曼机
a.二部图:无向图G为二分图的充分必要条件是,G至少有两个顶点,且其所有回路的长度均为偶数。
b.Restricted BoltzmannMachine(RBM) 玻耳兹曼机的定义:假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设其全概率分布p(v,h)满足Boltzmann分布;(Restricted在这里是指:这些网络被“限制”为一个可视层和一个隐层,层间存在连接,但层内的单元间不存在连接),隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。
c.为什么说它是一个deep learning?
因为输入层v(visible variables)和隐藏层h(hidden layer)都满足Boltzmann分布,在二部图模型中,通过调整参数,使得从隐藏层得到的可视层v1与原来的可视层v一样,那么这时候得到的隐藏层就是可视层的另外一种表达,也就是隐藏层可以作为输入层(可视层)输入数据的特征表示,所以它就是一种deep learning方法。
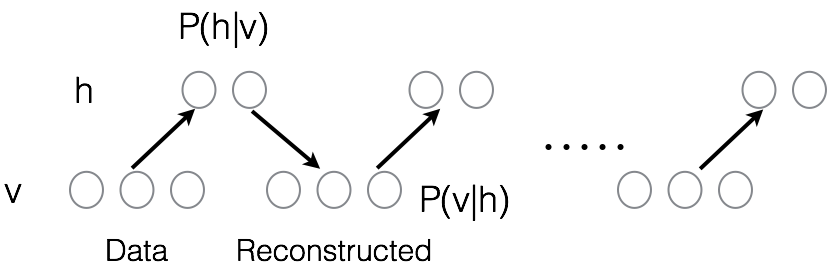
d.训练 (也就是确定可视层节点和隐藏层节点之间的权值)

定义:
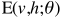 :假设函数 (联合组态的能量) (1)
:假设函数 (联合组态的能量) (1)
Boltzmann:参数所服从的分布 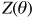 (2)
(2)
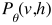 :假设函数(1)的分布 (概率生成模型的联合分布) (3)
:假设函数(1)的分布 (概率生成模型的联合分布) (3)
将(2)带入(3),定义
最优化函数Loss (4)
观测样本集 (5)
由(4)和(5),便可以学习到参数W.
如果把隐藏层的层数增加,我们可以得到Deep Boltzmann Machine(DBM);如果我们在靠近可视层的部分使用贝叶斯信念网络(即有向图模型,当然这里依然限制层中节点之间没有链接),而在最远离可视层的部分使用Restricted BoltzmannMachine,我们可以得到DeepBelief Net(DBN)。



(5)深信度网络(Deep Belief Network)
1. Deep Belief Network网络结构
DBNs是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和P(Lable|Observation)都做了评估,而判别模型仅仅评估了后者。
DBNs在使用传统的BP算法进行训练的时候,遇到了如下问题:
1.1 需要为训练提供一个有标签的样本集;
1.2 学习过程较慢;
1.3 不适当的参数选择会导致学习收敛于局部最优解;

Figure 1.DBN的网络结构
2. 训练方法
2.1 预训练
首先,通过一个非监督贪婪逐层方法去预训练获得生成模型的权值,非监督贪婪逐层方法被Hinton证明是有效的,并被其称为对比分歧(contrastive divergence)。
具体过程参加Figure 2 。
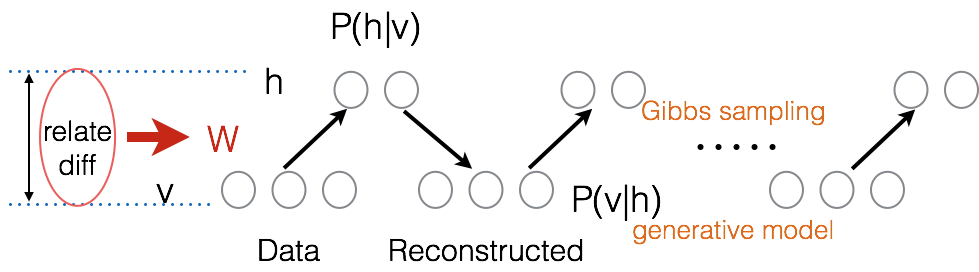
Figure 2.DBN的训练过程
a.训练时间会显著的减少,因为只需要单个步骤就可以接近最似然学习,而不是像BP训练那样需要反复迭代直到收敛。b.增加进网络的每一层都会改进训练数据的对数概率,我们可以理解为越来越接近能量的真实表达。这些优点,以及c.无标签数据的使用,是深度学习被应用的决定性因素。
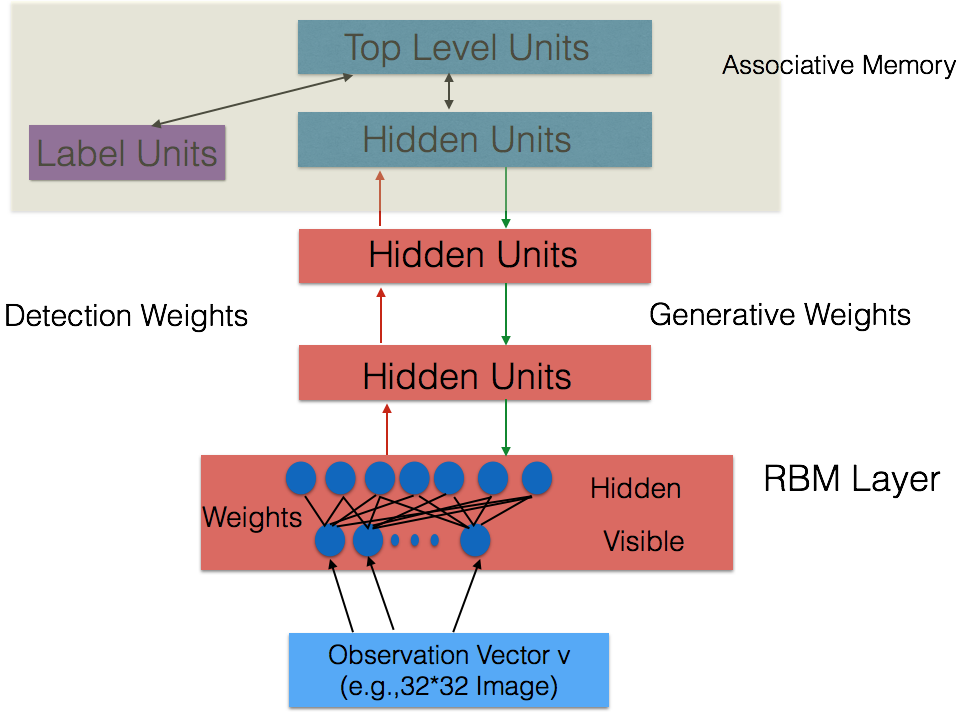
Figure 3. Illustration of the Deep Belief Network framework
在最高两层,权值被连接到一起,这样更底层的输出将会提供一个参考的线索或者关联给顶层,这样顶层就会将其联系到它的记忆内容。而我们最关心的,是其最后的判别性能,例如分类任务里面。
2.2 fine-tuning
在预训练后,DBN可以通过利用带标签数据用BP算法去对判别性能做调整(即fine tuning)。在这里,一个标签集将被附加到顶层(推广联想记忆),通过一个自下向上的,学习到的识别权值获得一个网络的分类面。这个分类器的性能会比单纯的使用BP算法训练的网络好。这可以很直观的解释,DBNs预训练后再加BP算法的方法,只需要对权值参数空间进行一个局部的搜索(就是局部fine-tune),这相比前向神经网络来说,训练是要快的,而且收敛的时间也少。
3、DBNs的缺点和不足
1)没有考虑到图像的高维结构信息;其拓展卷积DBNs就考虑了这个问题,它利用邻域像素的空域关系,通过一个称为卷积RBMs的模型区达到生成模型的变换不变性,而且可以容易地变换到高维图像。
2)DBNs并没有明确地处理对观察变量的时间联系的学习上;序列学习方法的研究和应用,给语音信号处理问题带来了一个让人激动的未来研究方向;
4、应用
堆叠自动编码器
5、几种编码器的对比
1)自动编码器
使用判别模型;
2)降噪自动编码器
其训练方法和RBMs训练生成模型的过程一样;
3)堆叠自动编码器
它是通过用堆叠自动编码器来替换传统DBMs里面的RBMs;这就使得可以通过同样的规则来训练产生深度多层神经网络架构,但它缺少层的参数化的严格要求。
参考:
神经网络系列学习笔记(二)——神经网络之DNN学习笔记的更多相关文章
- spring cloud 学习(二)关于 Eureka 的学习笔记
关于 Eureka 的学习笔记 个人博客地址 : https://zggdczfr.cn/ ,欢迎光临~ 前言 Eureka是Netflix开发的服务发现组件,本身是一个基于REST的服务.Sprin ...
- [基础]斯坦福cs231n课程视频笔记(二) 神经网络的介绍
目录 Introduction to Neural Networks BP Nerual Network Convolutional Neural Network Introduction to Ne ...
- DNN学习笔记 最简单的皮肤制作
说明: 在学习DNN时,使用的版本为 DNN8.参考资料:http://www.dnnsoftware.com/docs/designers/creating-themes/index.html 制作 ...
- Go语言核心36讲(Go语言实战与应用二十四)--学习笔记
46 | 访问网络服务 前导内容:socket 与 IPC 人们常常会使用 Go 语言去编写网络程序(当然了,这方面也是 Go 语言最为擅长的事情).说到网络编程,我们就不得不提及 socket. s ...
- <二>ELK-6.5.3学习笔记–使用rsyslog传输管理nginx日志
http://www.eryajf.net/2362.html 转载于 本文预计阅读时间 28 分钟 文章目录[隐藏] 1,nginx日志json化. 2,发送端配置. 3,接收端配置. 4,配置lo ...
- 二叉搜索树(BST)学习笔记
BST调了一天,最后遍历参数错了,没药救了-- 本文所有代码均使用数组+结构体,不使用指针! 前言--BFS是啥 BST 二叉搜索树是基于二叉树的一种树,一种特殊的二叉树. 二叉搜索树要么是一颗空树, ...
- JDBC二查询(web基础学习笔记八)
一.建立数据库 --创建news表空间 CREATE TABLESPACE tbs_news DATAFILE 'F:\ORACLE\news.dbf' SIZE 10M AUTOEXTEND ON; ...
- android学习笔记二、Activity深入学习
一.创建和使用: 1.Activity是android的四大组件之一,需要继承Activity并在清单文件中进行声明才能使用.没有声明则报错. 2.启动Activity是通过Intent,有两种方式: ...
- Go语言核心36讲(Go语言实战与应用二十五)--学习笔记
47 | 基于HTTP协议的网络服务 我们在上一篇文章中简单地讨论了网络编程和 socket,并由此提及了 Go 语言标准库中的syscall代码包和net代码包. 我还重点讲述了net.Dial函数 ...
随机推荐
- D. Time to Raid Cowavans 分块暴力,感觉关键在dp
http://codeforces.com/contest/103/problem/D 对于b大于 sqrt(n)的,暴力处理的话,那么算出每个的复杂度是sqrt(n),就是把n分成了sqrt(n)段 ...
- pat1097. Deduplication on a Linked List (25)
1097. Deduplication on a Linked List (25) 时间限制 300 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 ...
- android 开发-数据存储之共享参数
android提供5中数据存储方式 数据存储之共享参数 内部存储 扩展存储 数据库存储 网络存储 而共享存储提供一种可以让用户存储保存一些持久化键值对在文件中,以供其他应用对这些共享参数进行调用.共 ...
- 性能测试学习第九天_脚本编写以及controller场景
创建java脚本 环境配置: 安装jdk(lr11最高支持java1.6) 配置环境变量 在lr选择java Vuser协议 脚本结构: 一般在init中编写初始化脚本,在action中编写业务流程, ...
- 北航oo作业第三单元小结
一.梳理JML语言的理论基础 1.jml的注释结构 jml注释语言的每一行都以@作为开始,若是块注释,则需要在注释块的首尾使用/*@ 与@*/ 2.jml的表达式体系 1.原子表达式 表达式可以看作是 ...
- GitHub上易于高效开发的Android开源项目TOP20--适合新手
1. android-async-http android-async-http是Android上的一个异步.基于回调的HTTP客户端开发包,建立在Apache的HttpClient库上. 2. an ...
- vscode 常用插件安装
设置中文语言使用快捷键[Ctrl+Shift+P],弹出的搜索框中输入[configure language],然后选择搜索出来的[Configure Display Language],locale ...
- 使用Python开发环境Wing IDE设立项目注意事项
使用Wing IDE的第一步是建立一个项目文件,这样Wing IDE就可以找到并分析源代码,存储工作. Wing IDE会自动以默认的项目进行启动.在本教程中用户也可以使用这个默认项目进行示例操作.如 ...
- ubuntu14.04安装gradle
一.下载gradle $ wget https:////services.gradle.org/distributions/gradle-3.5.1-all.zip $ sudo unzip grad ...
- Winform调整DEV控件高度