Spark SQL利器:cacheTable/uncacheTable










Spark SQL利器:cacheTable/uncacheTable的更多相关文章
- Spark SQL利器:cacheTable/uncacheTable【转】
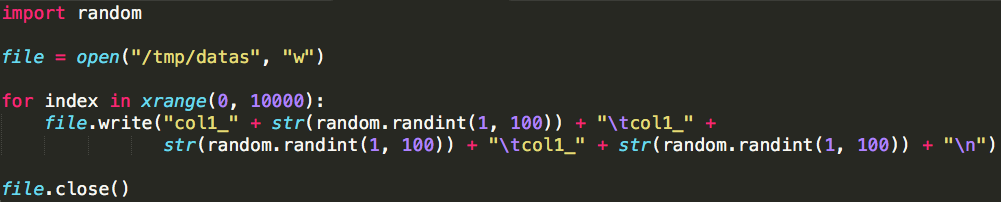
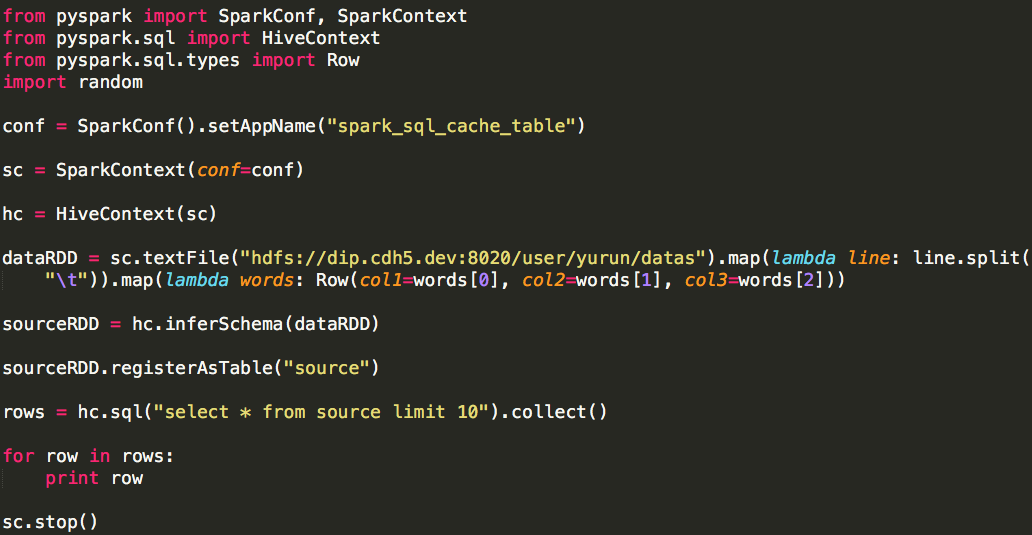
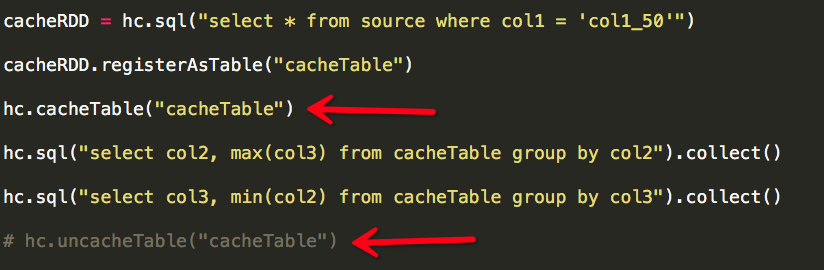
转自:http://www.cnblogs.com/yurunmiao/p/4936583.html Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个Map ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- spark sql cache
1.几种缓存数据的方法 例如有一张hive表叫做activity 1.CACHE TABLE //缓存全表 sqlContext.sql("CACHE TABLE activity" ...
- Spark SQL 初步
已经Spark Submit 2013哪里有介绍Spark SQL.就在很多人都介绍Catalyst查询优化框架.经过一年的发展后,.今年Spark Submit 2014在.Databricks放弃 ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
随机推荐
- dedeCMS修改文章更新发布时间问题
今天在dedeCMS系统中,修改或文章时发现,只要提交以后,文章发布时间便是当前时间.但有时候修改文章以后并不想把文章发布时间也更新成修改时间.我希望的是,修改文章不对时间做更改保持文章原有发布时间, ...
- 详细介绍Linux shell脚本基础学习
Linux shell脚本基础学习这里我们先来第一讲,介绍shell的语法基础,开头.注释.变量和 环境变量,向大家做一个基础的介绍,虽然不涉及具体东西,但是打好基础是以后学习轻松地前提.1. Lin ...
- [Twisted] 事件驱动模型
在事件驱动编程中,多个任务交替执行,并且在单一线程控制下进行.当执行I/O或者其他耗时操作时,回调函数会被注册到事件循环. 当I/O完成时,执行回调.回调函数描述了在事件完成之后,如何处理事件.事件循 ...
- JS实时监听浏览器宽度的变化
boot:function(){ //加载页面时执行一次 changeMargin(); //监听浏览器宽度的改变 window.onresize = function(){ changeMargin ...
- C++自定义异常处理
自定义异常类 class MyException { public: MyException() { } MyException(char* str) { msg = str; } MyExcepti ...
- Win32中GDI+应用(三)---Graphics类
在我理解看来,Graphics是一个device context和你的drawing conetent之间的一个中介.它存储了device context的相关属性,以及drawing content ...
- jquery之分页插件smartpaginator
今天推荐一个分页工具条插件:Smart Paginator,这个插件用途还是很广的,而且可定制性相当不错,目前内置三种颜色,有需要的话,可以自己改css定制颜色 1.如何使用Smart Paginat ...
- Vive开发教程汇总
最近在整理在HTC Vive平台上开发VR应用程序的教程,现在把结果全部汇总在下面的表格里,希望更多的开发者参与到VR内容的开发之中,真的很好玩.现在主流的开发VR应用的引擎是Unity3D和Unre ...
- JavaScript 输入自动完成插件
作为web开发的一员,应该都不陌生,信息处理时,很多时候需要根据用户的输入实时反馈查询结果供其选择,这给了用户很好的人机交互体验,在各大门户网站上已经被使用的很成熟了,最近项目中用到此功能,网上有很多 ...
- java 使用substring 截取特殊字符串的后一位或者数字
关于截取特殊的字符串的后一位或者数字 需求:截取特殊字符为 . 后一位 String[] str = uri.split("/"); String str1 = str[st ...