tensorflow在文本处理中的使用——TF-IDF算法
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理
代码地址:https://github.com/nfmcclure/tensorflow-cookbook
解决问题:使用“tfidf”来进行垃圾短信的预测(使用逻辑回归算法)
缺点:未考虑单词顺序
TF-IDF:TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
TF表示词条在文档d中出现的频率。
IDF的主要思想是:如果包含词条t的文档越少,也就是分母越小,IDF越大,则说明词条t具有很好的类别区分能力。
i词在j文档中的tfidf值计算
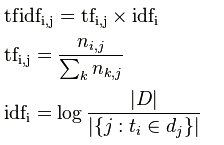
|D|是全部文档数目
分母为有i词的文档数目,有时分母会为0,采用拉普拉斯平滑,作+1处理
步骤如下:
step1:导入需要的包
step2:准备数据集
step3:分词且构建文本向量
step4:分割数据集
step5:构建图
step6:训练效果变化
step1:导入需要的包
import tensorflow as tf
import matplotlib.pyplot as plt
import csv
import numpy as np
import os
import string
import requests
import io
import nltk
from zipfile import ZipFile
from sklearn.feature_extraction.text import TfidfVectorizer
from tensorflow.python.framework import ops
ops.reset_default_graph() # Start a graph session
sess = tf.Session() #定义批处理大小和特征向量长度
batch_size = 200
max_features = 1000
step2:准备数据集
step3:分词且构建文本向量
# Define tokenizer
def tokenizer(text):
words = nltk.word_tokenize(text)
return words # Create TF-IDF of texts
tfidf = TfidfVectorizer(tokenizer=tokenizer, stop_words='english', max_features=max_features)
sparse_tfidf_texts = tfidf.fit_transform(texts)
此时sparse_tfidf_texts已经将每个文本转成一个1000维的向量,多个文本构成矩阵(注意该矩阵为稀疏矩阵,查看值使用sparse_tfidf_texts.todense())
step4:分割数据集
# Split up data set into train/test
train_indices = np.random.choice(sparse_tfidf_texts.shape[0], round(0.8*sparse_tfidf_texts.shape[0]), replace=False)
test_indices = np.array(list(set(range(sparse_tfidf_texts.shape[0])) - set(train_indices)))
texts_train = sparse_tfidf_texts[train_indices]
texts_test = sparse_tfidf_texts[test_indices]
target_train = np.array([x for ix, x in enumerate(target) if ix in train_indices])
target_test = np.array([x for ix, x in enumerate(target) if ix in test_indices])
step5:构建图
# Create variables for logistic regression设置权重和偏置项
A = tf.Variable(tf.random_normal(shape=[max_features,1]))
b = tf.Variable(tf.random_normal(shape=[1,1])) # Initialize placeholders设置数据的占位符
x_data = tf.placeholder(shape=[None, max_features], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32) # Declare logistic model (sigmoid in loss function)
model_output = tf.add(tf.matmul(x_data, A), b) # Declare loss function (Cross Entropy loss)损失函数计算
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(model_output, y_target)) # Actual Prediction 预测结果
prediction = tf.round(tf.sigmoid(model_output))
predictions_correct = tf.cast(tf.equal(prediction, y_target), tf.float32)
accuracy = tf.reduce_mean(predictions_correct) # Declare optimizer 用GD优化算法更新权重,最小化损失
my_opt = tf.train.GradientDescentOptimizer(0.0025)
train_step = my_opt.minimize(loss)
step6:训练效果变化
# Intitialize Variables
init = tf.initialize_all_variables()
sess.run(init) # Start Logistic Regression
train_loss = []
test_loss = []
train_acc = []
test_acc = []
i_data = []
for i in range(10000):
rand_index = np.random.choice(texts_train.shape[0], size=batch_size)
rand_x = texts_train[rand_index].todense()
rand_y = np.transpose([target_train[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y}) # Only record loss and accuracy every 100 generations,100回记录,500回输出状态
if (i+1)%100==0:
i_data.append(i+1)
train_loss_temp = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
train_loss.append(train_loss_temp) test_loss_temp = sess.run(loss, feed_dict={x_data: texts_test.todense(), y_target: np.transpose([target_test])})
test_loss.append(test_loss_temp) train_acc_temp = sess.run(accuracy, feed_dict={x_data: rand_x, y_target: rand_y})
train_acc.append(train_acc_temp) test_acc_temp = sess.run(accuracy, feed_dict={x_data: texts_test.todense(), y_target: np.transpose([target_test])})
test_acc.append(test_acc_temp)
if (i+1)%500==0:
acc_and_loss = [i+1, train_loss_temp, test_loss_temp, train_acc_temp, test_acc_temp]
acc_and_loss = [np.round(x,2) for x in acc_and_loss]
print('Generation # {}. Train Loss (Test Loss): {:.2f} ({:.2f}). Train Acc (Test Acc): {:.2f} ({:.2f})'.format(*acc_and_loss))
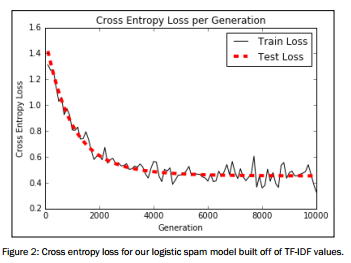
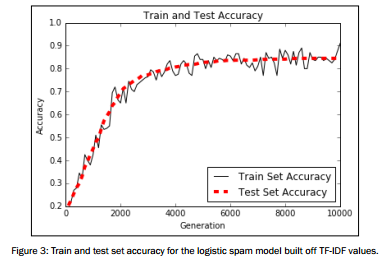
结果如下:

图像展示
# Plot loss over time
plt.plot(i_data, train_loss, 'k-', label='Train Loss')
plt.plot(i_data, test_loss, 'r--', label='Test Loss', linewidth=4)
plt.title('Cross Entropy Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('Cross Entropy Loss')
plt.legend(loc='upper right')
plt.show() # Plot train and test accuracy
plt.plot(i_data, train_acc, 'k-', label='Train Set Accuracy')
plt.plot(i_data, test_acc, 'r--', label='Test Set Accuracy', linewidth=4)
plt.title('Train and Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
tensorflow在文本处理中的使用——TF-IDF算法的更多相关文章
- tensorflow在文本处理中的使用——Doc2Vec情感分析
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——Word2Vec预测
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——skip-gram模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
随机推荐
- IOS 第三方管理库管理 CocoaPods
CocoaPod集成Tips http://www.jianshu.com/p/dcde0668eee9 import导入类失败 http://www.360doc.com/content/15/03 ...
- 数据分析1:安装tushare安装包
1. 2. 3.重点内容
- WinMail邮件服务器(客户端)环境搭建与配置
WinMail邮件服务器(客户端)环境搭建与配置 一.在搭建WinMail邮件服务器(客户端)之前必备 (1).在虚拟机上安装两个干净无毒的操作系统 ...
- Zabbix清理历史数据库,缩减表大小
zabbix 由于历史数据过大, 因此导致磁盘空间暴涨, 下面是解决方法步骤: 一.分析数据库: 1. 统计数据库中每个表所占的空间: mysql> SELECT table_name AS ...
- Java练习 SDUT-2053_整理音乐
整理音乐 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 请用链表完成下面题目要求. xiaobai 很喜欢音乐,几年来 ...
- 微信小程序中支持es7的async语法
最近在原生的微信小程序项目中需要把原来es6的promise方法改成es7的async await,这样代码看起来更直观,也方便以后的兄弟维护,但是改了代码之后项目就报错了. 提示的错误是:regen ...
- 5G时代-计算机和网络的又一个春天
预言 5G时代的到来计算机和网络即将再次变成热门,计算机和网络的前途将不可限量,就经济学思想来说一定是最具有经济价值的技术,计算机和网络将蓬勃发展,迅速膨胀,经济价值变得极高.将成为科技和智能生活的最 ...
- 2019-8-31-PowerShell-拿到最近的10个系统日志
title author date CreateTime categories PowerShell 拿到最近的10个系统日志 lindexi 2019-08-31 16:55:58 +0800 20 ...
- ROW_NUMBER(),不允许并列名次、相同值名次不重复,结果如123456……
将score按ID分组排名:row_number() over(partition by id order by score desc) 将score不分组排名:row_number() over(o ...
- MaxCompute Studio使用心得系列7——作业对比
在数据开发过程中,我们通常需要将两个作业进行对比从而定位作业运行性能或者结果有差异的问题,但是对比作业时需要同时打开两个studio 的tab页,或者两个Logview页,不停切换进行对比,使用起来非 ...