HDFS写入数据
HDFS副本摆放策略
不同的版本副本摆放策略可能并不一致,HDFS主要采用一种机架感知(rack-ware)的机制来实现摆放策略。
由于不同的机架上节点间通信要通过交换机(switches),同一机架上的通信带宽要优于不同机架。
HDFS默认采用3副本策略(参考2.9.1 & 3.2.1):
1.若操作的机器(writer)为一个DataNode,则将一个副本放在该机器上,否则任选一个DataNode;
2.将第二个副本放在与第一个不同的机架上;
3.第三个副本放置在与第二个同一机架但不同的节点上。
机架故障的可能性远小于节点故障的可能性。
如果复制因子大于3,则在确定每个机架的副本数量低于上限(基本上是(副本-1)/机架+ 2)的同时,随机确定第4个及以下副本的位置。
由于NameNode并不允许同一DataNode存放多于一个副本,因此副本数不能超过DataNode数。
HDFS写数据流程
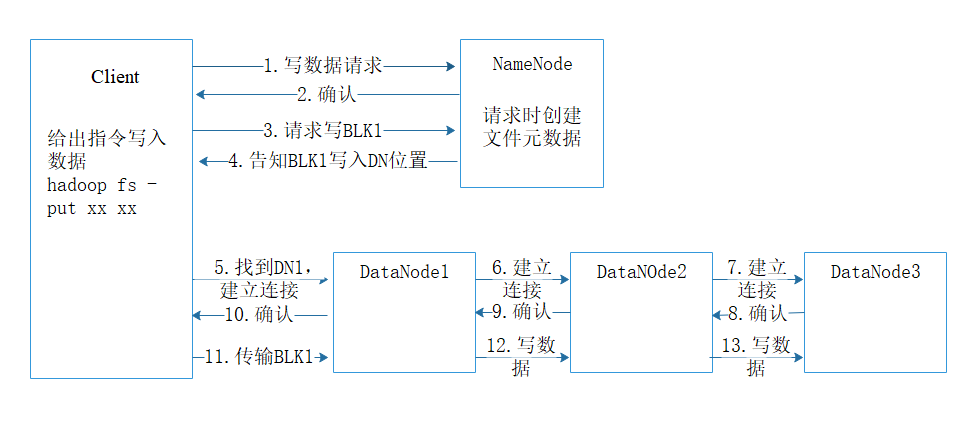
1. client发起文件上传请求,通过RPC与NameNode建立通信连接;
2. NameNode检查目标文件是否已存在等,是否可以上传;
2. client向NameNode请求写入第一个block位置;
4. NameNode根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的DataNode的地址告知client如:DN1,DN2,DN3;
5. client请求3台DataNode中的一台DN1上传数据(本质上是一个RPC调用,建立pipeline),DN1收到请求会继续调用DN2,然后DN2调用DN3,将整个pipeline建立完成,后逐级返回client;
6. client开始往DN1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(默认64K),DN1收到一个packet就会传给DN2,DN2传给DN3;N1每传一个packet会放入一个应答队列等待应答。
7. 数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点DN1将pipelineack发送给client;
8. 当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。
HDFS元数据(metadata)
元数据即数据的数据,是维护HDFS中的文件和目录所需要的信息。用于描述和组织具体的文件内容。元数据的可用性直接决定了HDFS的可用性。
形式上分为内存元数据和元数据文件两类,其中NameNode在内存中维护整个文件系统的元数据镜像,用于HDFS的管理;元数据文件则用于持久化存储。
元数据上保存信息分为以下三类:
- 文件与目录自身的属性信息,如文件名、目录名、文件大小、创建时间等;
- 文件内容存储的相关信息,如分块情况、副本个数、副本存放位置等;
- HDFS所有DataNodes的信息,用于DataNodes管理。
从来源上讲,元数据主要来源于NameNode磁盘上的元数据文件(它包括元数据镜像fsimage和元数据操作日志edits两个文件)以及各个DataNode的上报信息
参考来源:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://www.cnblogs.com/mediocreWorld/p/10946647.html
http://blog.sina.com.cn/s/blog_a94476040101cco2.html
HDFS写入数据的更多相关文章
- sqoop往远程hdfs写入数据时出现Permission denied 的问题
猜测出现该问题的原因是sqoop工具用的是执行sqoop工具所用的本地用户名. 如果远程hdfs用的用户是hdfs,那么我本地还需要建一个名为hdfs的用户? 其实不需要,只要为用户增加一个环境变量就 ...
- Hadoop源码分析之客户端向HDFS写数据
转自:http://www.tuicool.com/articles/neUrmu 在上一篇博文中分析了客户端从HDFS读取数据的过程,下面来看看客户端是怎么样向HDFS写数据的,下面的代码将本地文件 ...
- spark读取hdfs上的文件和写入数据到hdfs上面
def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.set("spark.master" ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- Hadoop源代码分析:HDFS读取和写入数据流控制(DataTransferThrottler类别)
DataTransferThrottler类别Datanode读取和写入数据时控制传输数据速率.这个类是线程安全的,它可以由多个线程共享. 用途是构建DataTransferThrottler对象,并 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- HDFS写入和读取流程
HDFS写入和读取流程 一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而 ...
- 使用Hadoop的MapReduce与HDFS处理数据
hadoop是一个分布式的基础架构,利用分布式实现高效的计算与储存,最核心的设计在于HDFS与MapReduce,HDFS提供了大量数据的存储,mapReduce提供了大量数据计算的实现,通过Java ...
随机推荐
- mybatis 通过配置父类数据源连接和关闭数据,进行junit单元测试
来源:https://blog.csdn.net/Bigbig_lyx/article/details/80646005 解决问题,单元测试没经过单独配置,每个测试方法中要添加配置数据源 一:配置父类 ...
- [MySQL]mysql binlog回滚数据
1.先开启binlog log-bin = /var/log/mysql/mysql_bin #binlog日志文件,以mysql_bin开头,六个数字结尾的文件:mysql_bin.000001,并 ...
- clr via c# 泛型
1,类型对象,对于应用程序的各种类型创建的对象叫做类型对象:Type object:对于泛型类型参数的类型,CLR同样也会创建内部类型对象,适用于 引用类型 值类型 接口类型 委托类型 具有泛型类型参 ...
- 初学Python,需要装什么软件?
学习Python需要安装什么软件呢?也许你是一位编程小白,还不知道如何如何安装Python软件和开发环境.那么今天我们就来学一下关于Python软件.开发环境的相关知识,希望对你有用. 学Python ...
- javascript中如何使用js脚本模拟"request"获取url后参数值呢?
转自:猫猫小屋--js获取url后参数信息 摘要: 下文讲述javascript中使用js代码获取url地址后面的参数值的方法分享,如下所示: 实现思路: 使用正则表达式对参数值进行匹配,获取参数后的 ...
- AGC018F - Two Trees
题意 有两棵节点数均为 n 的有根树,你需要构造一个序列 \(X_1,X_2,...,X_n\).使得对于每一棵树的每一个节点, 若令它所有的后代(包括它本身)为 \(a_1,a_2,...,a_k\ ...
- Serverless Component 介绍和使用指南
Serverless Component 是什么,我怎样使用它? Serverless Components 的目标是什么? 我们希望通过 Serverless Components 让广大开发者更加 ...
- Transformation HDU - 4578 完全平方公式和立方公式展开,有点麻烦
#include <stdio.h> #include <algorithm> #include <iostream> #include <string.h& ...
- Android_小账本_筛选功能的实现
昨天对小账本的相关功能做了完善,新增了筛选功能. 支持对类型.收支项.日期进行修改. 但暂时尚不完善,只能针对相关小项进行筛选,无法连续对小项的结果进行筛选.这一功能预计在本周三进行完善. 相关代码 ...
- PTA 1005 Spell It Right
题目描述: Given a non-negative integer N, your task is to compute the sum of all the digits of N, and ou ...