(转)KL散度的理解
KL散度(KL divergence)
全称:Kullback-Leibler Divergence。
用途:比较两个概率分布的接近程度。
在统计应用中,我们经常需要用一个简单的,近似的概率分布 f * 来描述。
观察数据 D 或者另一个复杂的概率分布 f 。这个时候,我们需要一个量来衡量我们选择的近似分布 f * 相比原分布 f 究竟损失了多少信息量,这就是KL散度起作用的地方。
熵(entropy)
想要考察信息量的损失,就要先确定一个描述信息量的量纲。
在信息论这门学科中,一个很重要的目标就是量化描述数据中含有多少信息。
为此,提出了熵的概念,记作 H 。
一个概率分布所对应的熵表达如下: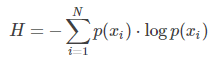
如果我们使用 log 2 作为底,熵可以被理解为:我们编码所有信息所需要的最小位数(minimum numbers of bits)。
需要注意的是:通过计算熵,我们可以知道信息编码需要的最小位数,却不能确定最佳的数据压缩策略。怎样选择最优数据压缩策略,使得数据存储位数与熵计算的位数相同,达到最优压缩,是另一个庞大的课题。
KL散度的计算
现在,我们能够量化数据中的信息量了,就可以来衡量近似分布带来的信息损失了。
KL散度的计算公式其实是熵计算公式的简单变形,在原有概率分布 p 上,加入我们的近似概率分布 q ,计算他们的每个取值对应对数的差:
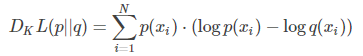
换句话说,KL散度计算的就是数据的原分布与近似分布的概率的对数差的期望值。
在对数以2为底时, log 2 ,可以理解为“我们损失了多少位的信息”。
写成期望形式:
更常见的是以下形式: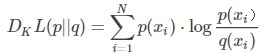
现在,我们就可以使用KL散度衡量我们选择的近似分布与数据原分布有多大差异了。
散度不是距离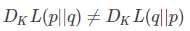
因为KL散度不具有交换性,所以不能理解为“距离”的概念,衡量的并不是两个分布在空间中的远近,更准确的理解还是衡量一个分布相比另一个分布的信息损失(infomation lost)。
使用KL散度进行优化
通过不断改变预估分布的参数,我们可以得到不同的KL散度的值。
在某个变化范围内,KL散度取到最小值的时候,对应的参数是我们想要的最优参数。
这就是使用KL散度优化的过程。
神经网络进行的工作很大程度上就是“函数的近似”(function approximators)。
因此我们可以使用神经网络学习很多复杂函数,学习过程的关键就是设定一个目标函数来衡量学习效果。
也就是通过最小化目标函数的损失来训练网络(minimizing the loss of the objective function)。
而KL散度可以作为正则化项(regularization term)加入损失函数之中,即使用KL散度来最小化我们近似分布时的信息损失,让我们的网络可以学习很多复杂的分布。
一个典型应用是VAE(变分自动编码)。
(转)KL散度的理解的更多相关文章
- KL散度的理解(GAN网络的优化)
原文地址Count Bayesie 这篇文章是博客Count Bayesie上的文章Kullback-Leibler Divergence Explained 的学习笔记,原文对 KL散度 的概念诠释 ...
- KL散度相关理解以及视频推荐
以下内容基于对[中字]信息熵,交叉熵,KL散度介绍||机器学习的信息论基础这个视频的理解,请务必先看几遍这个视频. 假设一个事件可能有多种结果,每一种结果都有其发生的概率,概率总和为1,也即一个数据分 ...
- 【原】浅谈KL散度(相对熵)在用户画像中的应用
最近做用户画像,用到了KL散度,发现效果还是不错的,现跟大家分享一下,为了文章的易读性,不具体讲公式的计算,主要讲应用,不过公式也不复杂,具体可以看链接. 首先先介绍一下KL散度是啥.KL散度全称Ku ...
- PRML读书会第十章 Approximate Inference(近似推断,变分推断,KL散度,平均场, Mean Field )
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:02:04 我们在前面看到,概率推断的核心任务就是计算某分布下的某个函数的期望.或者计算边缘概率分布.条件 ...
- 浅谈KL散度
一.第一种理解 相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information divergence) ...
- 非负矩阵分解(1):准则函数及KL散度
作者:桂. 时间:2017-04-06 12:29:26 链接:http://www.cnblogs.com/xingshansi/p/6672908.html 声明:欢迎被转载,不过记得注明出处哦 ...
- KL散度、JS散度、Wasserstein距离
1. KL散度 KL散度又称为相对熵,信息散度,信息增益.KL散度是是两个概率分布 $P$ 和 $Q$ 之间差别的非对称性的度量. KL散度是用来 度量使用基于 $Q$ 的编码来编码来自 $P$ 的 ...
- 相对熵(KL散度)
https://blog.csdn.net/weixinhum/article/details/85064685 上一篇文章我们简单介绍了信息熵的概念,知道了信息熵可以表达数据的信息量大小,是信息处理 ...
- ELBO 与 KL散度
浅谈KL散度 一.第一种理解 相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information dive ...
随机推荐
- resin部署安装
Resin是CAUCHO公司的产品,是一个非常流行的application server,对servlet和JSP提供了良好的支持,性能也比较优良,resin自身也是采用JAVA语法开发,功能近似于t ...
- 0003 HTML常用标签(含base、锚点)、路径
学习目标 理解: 相对路径三种形式 应用 排版标签 文本格式化标签 图像标签 链接 相对路径,绝对路径的使用 1. HTML常用标签 首先 HTML和CSS是两种完全不同的语言,我们学的是结构,就只写 ...
- 使用svndumpfilter exclude来清理svn库的废弃文件实现差别备份
先啰嗦下为什么要使用svndumpfilter… svn库用久了以后就会越来越大,进行整体文件打包备份的时候,发现压力山大…尤其是美术团队也在使用svn进行重要美术资源管理的时候…….几百g的资源 ...
- cmake安装mysql及多实例配置方法
一.安装mysql 1. 生产环境如何选择MySQL版本 1. 选择社区版的稳定GA版本2. 可以选择5.1或5.5.互联网公司主流5.5, 其次是5.1和5.63. 选择发布后6个月以上的GA版4. ...
- 机器学习——EM算法与GMM算法
目录 最大似然估计 K-means算法 EM算法 GMM算法(实际是高斯混合聚类) 中心思想:①极大似然估计 ②θ=f(θold) 此算法非常老,几乎不会问到,但思想很重要. EM的原理推导还是蛮复杂 ...
- python django 基本环境配置
创建虚拟环境: python -m venv django启动虚拟环境: .\venv\Scripts\activate下载django: pip install django查看django命令: ...
- 吴恩达机器学习笔记 - cost function and gradient descent
一.简介 cost fuction是用来判断机器预算值和实际值得误差,一般来说训练机器学习的目的就是希望将这个cost function减到最小.本文会介绍如何找到这个最小值. 二.线性回归的cost ...
- python3 三行代码基于HTTP2完美实现APNS推送【详解】
第一次做苹果APNS(Apple Push Notification service)推送,关于APNS推送原理以及证书的获取方式网上已经有许多资料,在此不做过多赘述,需要注意的是证书分为测试证书和正 ...
- 手动滑稽之golang-vmware-driver广告篇
本来在Windows 7 + Tiny Linux 4.19 + XFS + Vmware Workstation 15 (PRO) 下篇dockerの奥义之后的UEFI补完延迟了... 虽然用efi ...
- 在A卡下的 Matlab 运行C/C++混编的GPU程序
首先将你的.MEX文件和matlab脚本放在一个文件夹下开始运行 如果出错查看是那个.MEX文件出错 用depends这个软件查看他的依赖dll文件下载对应文件 放到当前文件夹下,运行成功.